Command Palette
Search for a command to run...
مجموعة بيانات معيارية لتوليد فهم الكلام من WildSpeech-Bench
التاريخ
الحجم
المؤسسة
رابط الورقة البحثية
الترخيص
CC BY 4.0
الوسوم
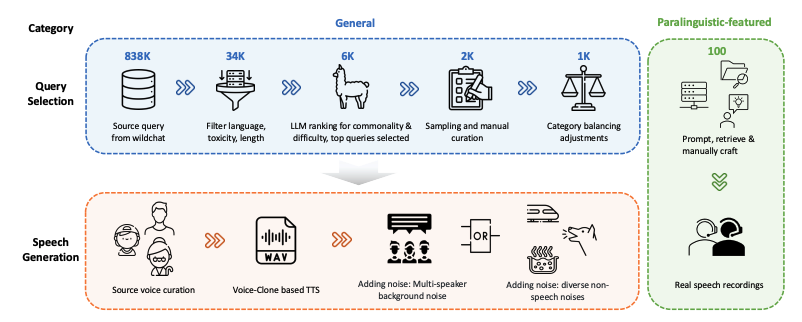
WildSpeech-Bench هو أول معيار لتقييم قدرات تحويل الكلام إلى كلام في SpeechLLM، والذي أصدرته Tencent في عام 2025. نتائج الورقة البحثية ذات الصلة هي "WildSpeech-Bench: تقييم شامل لبرامج ماجستير الخطابة في البرية"، والذي يهدف إلى قياس قدرة النموذج على فهم وتوليد تحويل الكلام الكامل من مدخل إلى مخرج (كلام إلى كلام، S2S) في سيناريوهات التفاعل الصوتي الحقيقي. تحتوي مجموعة البيانات على 1100 استعلام موزعة على خمس فئات رئيسية: استعلامات المعلومات، وطلبات الحلول، وتبادل الآراء، وإنشاء النصوص، والتعبيرات شبه الصوتية. تتوافق كل فئة مع نية مستخدم شائعة. 1000 من هذه الاستعلامات مستمدة من سيناريوهات تفاعل صوتي عامة (بما في ذلك استعلامات المعلومات، وطلبات الحلول، وتبادل الآراء، وإنشاء النصوص)، بينما تتميز 100 استعلام أخرى بخصائص شبه صوتية مثل التوقفات، والتجويد، والتلعثم، والتعرف على الكلمات شبه الصوتية. يُرفق بكل استعلام أمثلة متنوعة لمخرجات الكلام، تشمل مجموعة واسعة من سمات المتحدث (الجنس، والعمر، وتنوعات الصوت)، والظروف الصوتية، وإعدادات بيئة الضوضاء، لمحاكاة تنوع وتحديات التفاعل الصوتي الطبيعي بشكل أكثر واقعية.
الاستشهاد
@misc{zhang2025wildspeechbenchbenchmarkingendtoendspeechllms, title={WildSpeech-Bench: Benchmarking End-to-End SpeechLLMs in the Wild}, المؤلف={Linhao Zhang وJian Zhang وBokai Lei وChuhan Wu وAiwei Liu وWei Jia وXiao Zhou}، year={2025}, eprint={2506.21875}, archivePrefix={arXiv}, primaryClass={cs.CL}, }
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.