Command Palette
Search for a command to run...
مجموعة بيانات التعرف على النصوص CC-OCR
التاريخ
الحجم
المؤسسة
عنوان URL للنشر
رابط الورقة البحثية
الوسوم
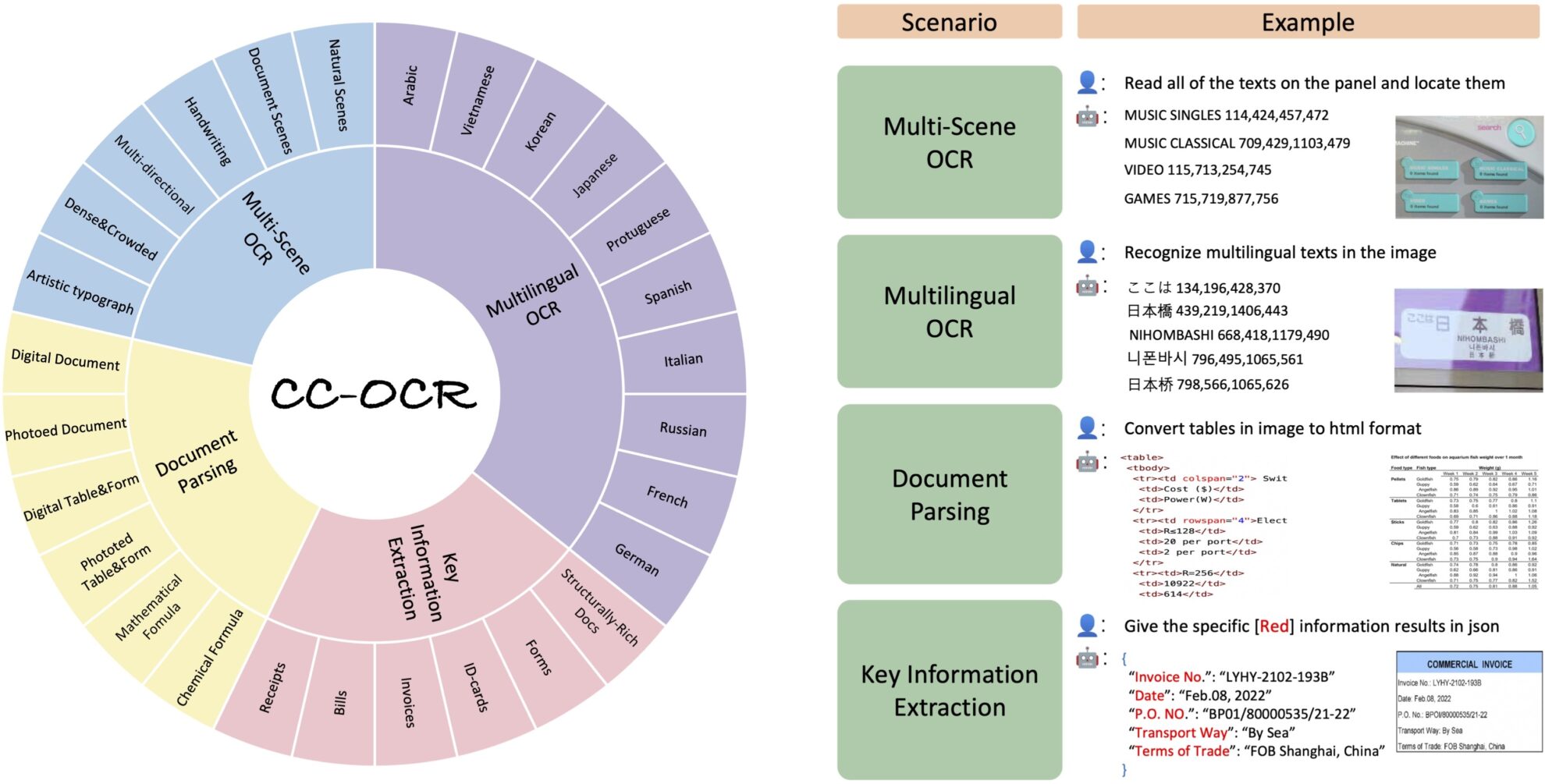
تم تطوير مجموعة بيانات CC-OCR بشكل مشترك من قبل مجموعة Alibaba وجامعة Huazhong للعلوم والتكنولوجيا وجامعة جنوب الصين للتكنولوجيا في عام 2024 لتوفير معيار شامل وتحدي لتقييم أداء النماذج متعددة الوسائط الكبيرة في مهام التعرف على النص (OCR).CC-OCR: معيار OCR شامل وصعب لتقييم النماذج متعددة الوسائط الكبيرة في محو الأمية".
تغطي مجموعة البيانات أربع مهام أساسية: قراءة النصوص متعددة المشاهد، وقراءة النصوص متعددة اللغات، وتحليل المستندات، واستخراج المعلومات الرئيسية، وتحتوي على 39 مجموعة فرعية و7058 صورة موضحة بالكامل. ويساهم إطلاق CC-OCR في سد الفجوة في تقييم النماذج متعددة الوسائط الحالية في الهياكل المعقدة والتحديات البصرية الدقيقة، وهو أمر ذو أهمية كبيرة لتعزيز تقدم النماذج متعددة الوسائط في التطبيقات العملية.
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.