HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

AlayaWorld: 상호작용형 장기 지평 세계 모델링 - 전체 기술 보고서

Mage-Flow: 효율적인 원본 해상도 기반 이미지 생성 및 편집 기초 모델

DataFlow-Harness: 편집 가능한 LLM 데이터 파이프라인 구축을 위한 정박형 코드 에이전트 플랫폼

텍스트 템플릿 토큰은 확산 트랜스포머의 암묵적 의미 레지스터이다

플레이 속도로 동작하는 생성형 월드 렌더러

단일 데스크톱 GPU에서의 무한 인터랙티브 월드 롤아웃

UniMoMo: 신규 결합체 설계를 위한 3차원 분자 통합 생성 모델

대조적 신념 업데이트를 통한 보상 추구 행동 측정

LLM-as-a-Coach: 검증 불가능한 작업을 위한 경험적 학습

Apple-π: 물리 법칙 기반 추론 능력 평가를 위한 비디오 생성 모델 벤치마크

HOMIE: 다중 모드 지능형 향상을 통한 인간-객체 중심 비디오 개인화

SWE-Pruner Pro: 코더 LLM은 이미 무엇을 가지치기할지 알고 있다

DeepSearch-World: 검증 가능한 환경에서의 심층 검색 에이전트를 위한 자기 증류

EvolvingWorld: 상호작용적 문학 세계에서 역할극 에이전트와 세계 모델의 공진화를 위한 개방형 스키마 프레임워크

TimeLens2: 멀티모달 대규모 언어 모델을 활용한 범용 비디오 시간적 근거 추출

사전 학습에서 사후 학습까지의 추론 이해

AI의 재귀적 자기 개선: 제한적 자기 정제에서 자율 연구 루프까지
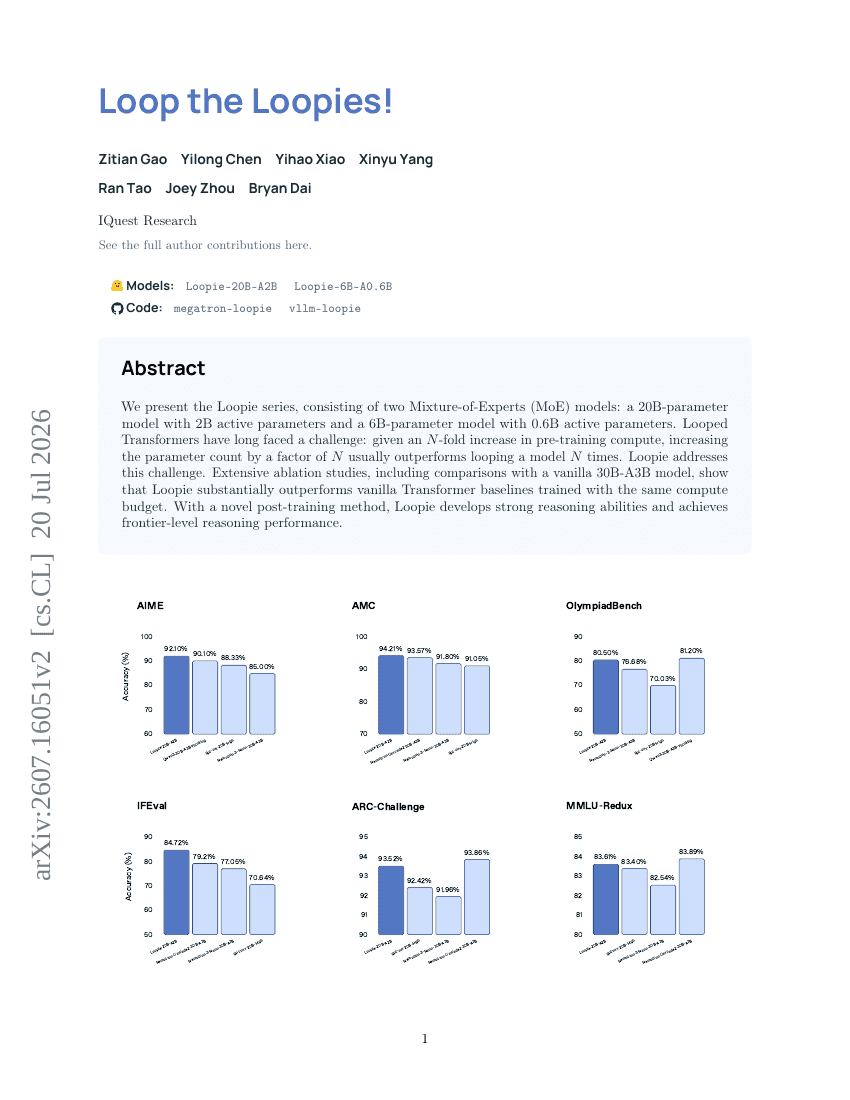
루프 더 루피스!

온-폴리시 델타 증류
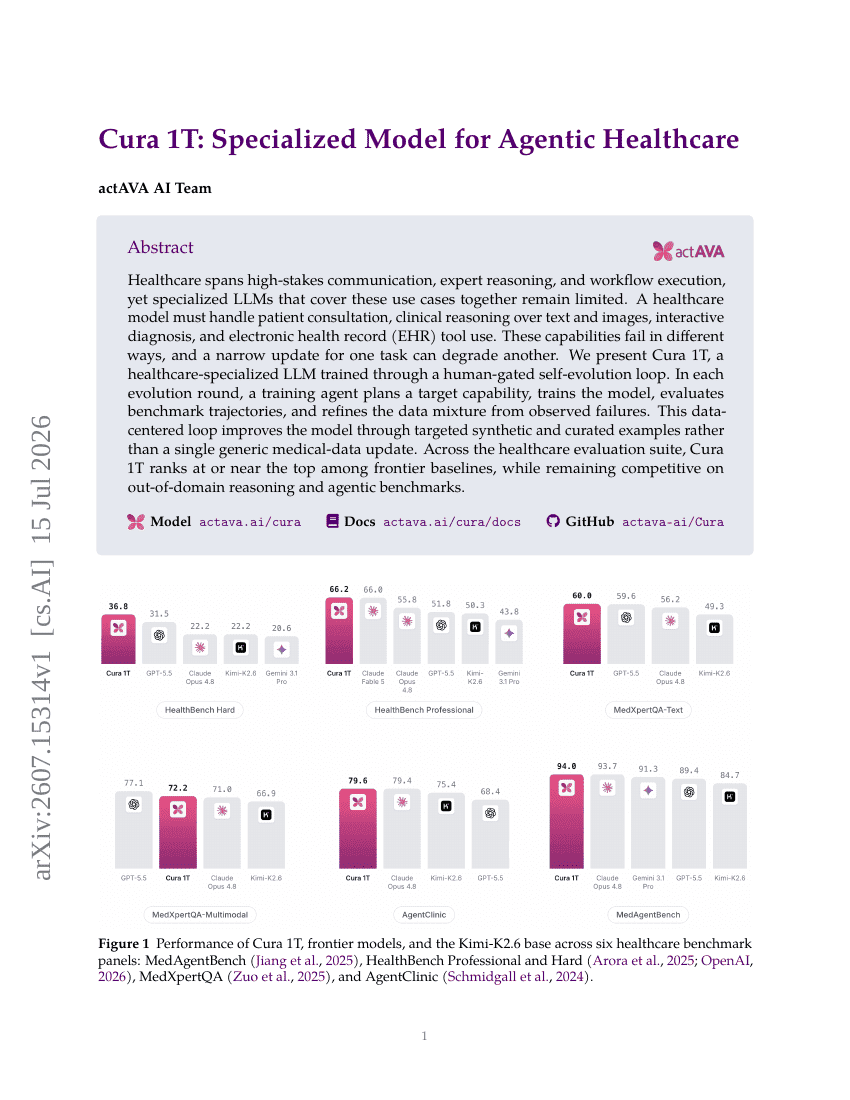
Cura 1T: 인간 개입형 자기 진화 루프를 통해 훈련된 의료 특화 대규모 언어 모델

인간 중심에서 에이전트 코드 리뷰로: 다양한 세대의 생성형 AI 기술이 리뷰 품질에 미치는 영향
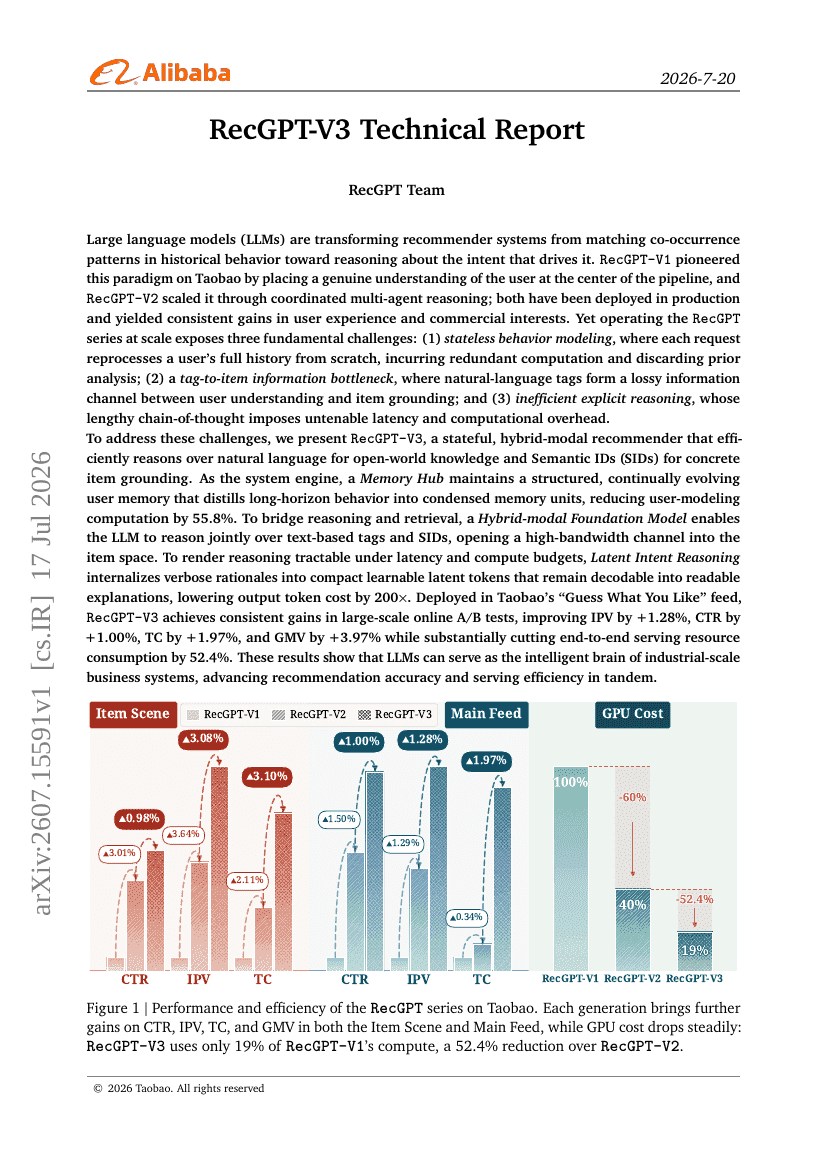
RecGPT-V3 기술 보고서
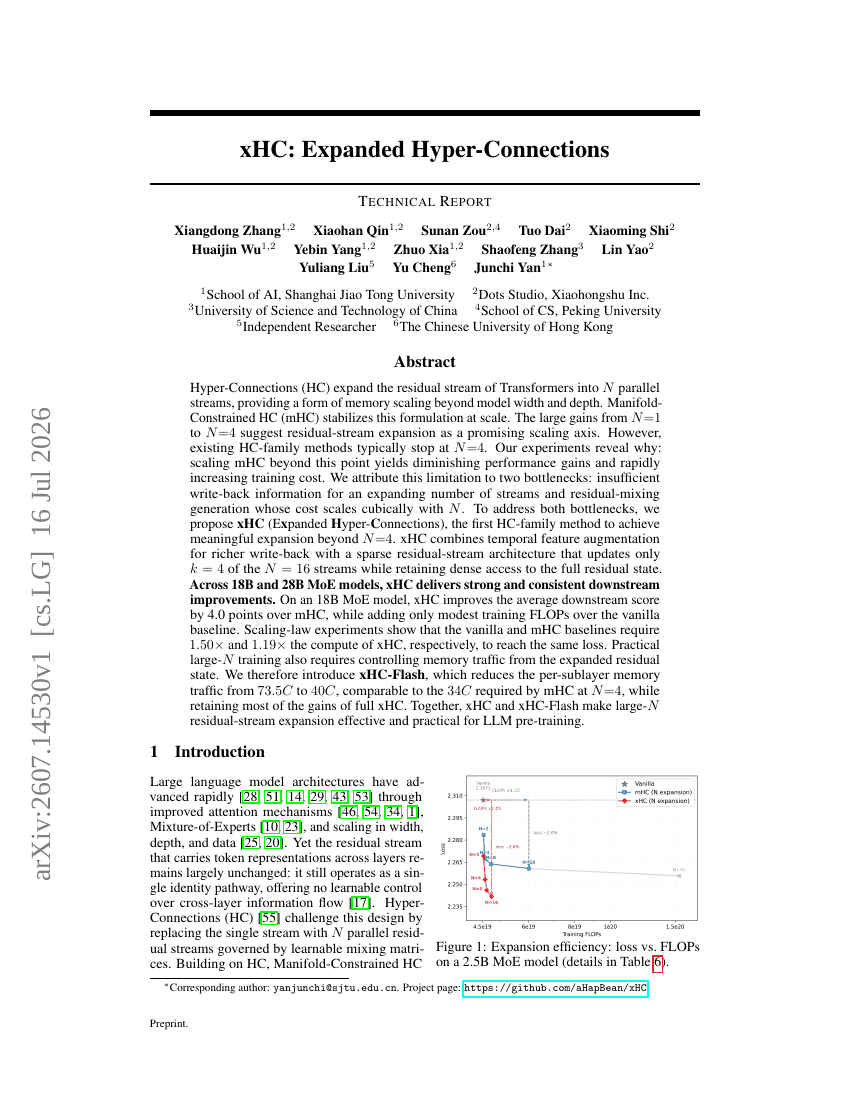
xHC: 확장된 하이퍼-커넥션

예측적, 정렬된, 확장 가능한 로봇 학습을 향하여

확률적 세계 모델링을 위한 특징 공간에서의 플로우 매칭

MiMo-V2.5 시리즈를 위한 전체 파이프라인 추론 최적화: 하이브리드 SWA 효율성을 극한으로 끌어올리다

TRACE: 장기 에이전트를 위한 크레딧 추정 기반 턴 단위 보상 할당

KeyFrame-Compass: 키프레임 조건 비디오 생성의 종합적 평가를 향하여

BadWAM: 세계-행동 모델이 올바르게 상상하지만 잘못 행동할 때

SearchOS-V1: 강건한 개방형 도메인 정보 탐색 에이전트 협업을 향하여

SEED: 에이전트 강화 학습을 위한 자기 진화형 온폴리시 증류

VideoChat3: 효율적이고 범용적인 비디오 이해를 위한 완전 개방형 비디오 MLLM
AlayaWorld: 상호작용형 장기 지평 세계 모델링 - 전체 기술 보고서
Mage-Flow: 효율적인 원본 해상도 기반 이미지 생성 및 편집 기초 모델
DataFlow-Harness: 편집 가능한 LLM 데이터 파이프라인 구축을 위한 정박형 코드 에이전트 플랫폼
텍스트 템플릿 토큰은 확산 트랜스포머의 암묵적 의미 레지스터이다
플레이 속도로 동작하는 생성형 월드 렌더러
단일 데스크톱 GPU에서의 무한 인터랙티브 월드 롤아웃
UniMoMo: 신규 결합체 설계를 위한 3차원 분자 통합 생성 모델
대조적 신념 업데이트를 통한 보상 추구 행동 측정
LLM-as-a-Coach: 검증 불가능한 작업을 위한 경험적 학습
Apple-π: 물리 법칙 기반 추론 능력 평가를 위한 비디오 생성 모델 벤치마크
HOMIE: 다중 모드 지능형 향상을 통한 인간-객체 중심 비디오 개인화
SWE-Pruner Pro: 코더 LLM은 이미 무엇을 가지치기할지 알고 있다
DeepSearch-World: 검증 가능한 환경에서의 심층 검색 에이전트를 위한 자기 증류
EvolvingWorld: 상호작용적 문학 세계에서 역할극 에이전트와 세계 모델의 공진화를 위한 개방형 스키마 프레임워크
TimeLens2: 멀티모달 대규모 언어 모델을 활용한 범용 비디오 시간적 근거 추출
사전 학습에서 사후 학습까지의 추론 이해
AI의 재귀적 자기 개선: 제한적 자기 정제에서 자율 연구 루프까지
루프 더 루피스!
온-폴리시 델타 증류
Cura 1T: 인간 개입형 자기 진화 루프를 통해 훈련된 의료 특화 대규모 언어 모델
인간 중심에서 에이전트 코드 리뷰로: 다양한 세대의 생성형 AI 기술이 리뷰 품질에 미치는 영향
RecGPT-V3 기술 보고서
xHC: 확장된 하이퍼-커넥션
예측적, 정렬된, 확장 가능한 로봇 학습을 향하여
확률적 세계 모델링을 위한 특징 공간에서의 플로우 매칭
MiMo-V2.5 시리즈를 위한 전체 파이프라인 추론 최적화: 하이브리드 SWA 효율성을 극한으로 끌어올리다
TRACE: 장기 에이전트를 위한 크레딧 추정 기반 턴 단위 보상 할당
KeyFrame-Compass: 키프레임 조건 비디오 생성의 종합적 평가를 향하여
BadWAM: 세계-행동 모델이 올바르게 상상하지만 잘못 행동할 때
SearchOS-V1: 강건한 개방형 도메인 정보 탐색 에이전트 협업을 향하여
SEED: 에이전트 강화 학습을 위한 자기 진화형 온폴리시 증류
VideoChat3: 효율적이고 범용적인 비디오 이해를 위한 완전 개방형 비디오 MLLM