Command Palette
Search for a command to run...
이번 주 논문 보고서 | 마이크로소프트의 MAI-Thinking은 순수 강화 학습의 자체 진화를 탐구하여 97%의 AIME 정확도를 달성했습니다. VLM³는 아키텍처 수정 없이 일반 텍스트 좌표를 사용하여 3D 작업 일반화를 구현했습니다… 이번 주 최첨단 AI 논문에 대한 간략한 개요입니다.

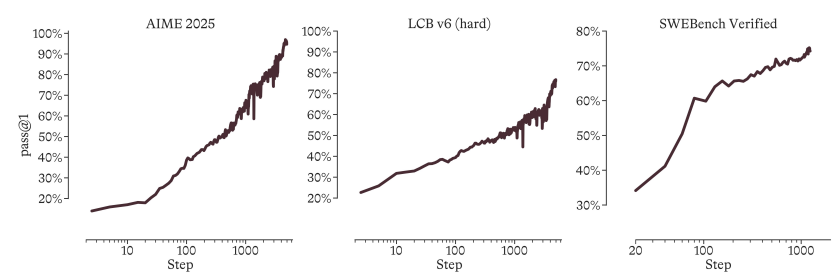
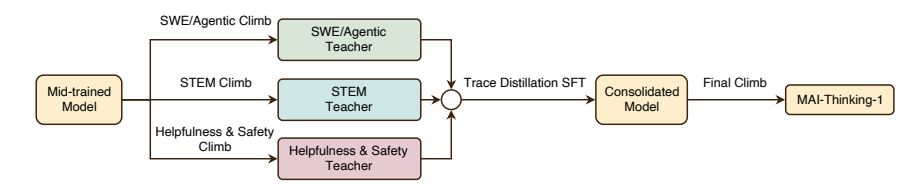
인공지능의 발전은 개별 모델의 획기적인 발전뿐만 아니라, 지속적인 자체 개선이 가능한 시스템 구축에 더욱 중요하게 달려 있습니다. 이를 위해 마이크로소프트의 AI 팀은 모델 개발을 시스템 수준의 최적화 문제로 간주합니다.빠르고 지속적인 성능 향상을 달성하도록 설계된 "언덕 오르기 머신" 프레임워크를 제안합니다."이를 바탕으로 총 파라미터 1T, 활성화 파라미터 35B를 갖는 MoE 추론 모델 MAI-Thinking-1을 처음부터 학습시켰다.
이 모델은 사전 학습 단계에서 타사 모델의 증류 데이터를 완전히 배제하고, 강화 학습(RL) 단계에서 적응형 엔트로피 제어 및 자체 증류 메커니즘을 갖춘 GRPO 알고리즘을 도입합니다.실험 결과에 따르면 MAI-Thinking-1은 사전 추론 궤적 없이 시작하더라도 장기적으로 안정적인 로그 선형 성능 성장을 달성할 수 있습니다.궁극적으로 이 시스템은 AIME 2025(97.0%) 및 SWE-Bench Pro(52.8%)와 같은 핵심 벤치마크에서 최첨단 수준의 복잡한 추론 및 코드 생성 성능을 달성했습니다.
논문 링크:https://go.hyper.ai/QeSWd
최신 AI 논문:https://go.hyper.ai/hzChC
더 많은 사용자들이 학계의 인공지능 분야 최신 동향을 이해할 수 있도록 돕기 위해,HyperAI 웹사이트(hyper.ai)에 최신 AI 연구 논문으로 정기적으로 업데이트되는 "최신 논문" 섹션이 추가되었습니다.추천할 만한 인기 AI 논문 9편을 소개합니다. 이번 주 최신 AI 성과를 간단히 살펴보겠습니다 ⬇️
이번 주 논문 추천
1. MAI 사고방식-1
논문 제목:
MAI 사고방식 1: 언덕 오르기 머신 만들기
마이크로소프트의 AI 팀은 모델 개발을 시스템 수준의 최적화 문제로 간주하는 "언덕 오르기(hill-climbing)" 접근 방식을 제안했습니다. 그들은 총 1조 개의 파라미터와 350억 개의 활성화 파라미터를 사용하여 MoE 추론 모델인 MAI-Thinking-1을 처음부터 학습시켰습니다. 모델의 사전 학습은 제3자로부터 정제된 데이터를 전혀 사용하지 않고 순수 데이터만을 기반으로 이루어졌습니다. 강화 학습 단계에서는 적응형 엔트로피 제어와 자체 증류 메커니즘을 갖춘 GRPO 알고리즘을 사용하여 초기 추론 궤적 없이 안정적이고 장기적인 성능 향상을 달성했습니다. 이 모델은 궁극적으로 STEM, 코드 에이전트, 보안이라는 세 가지 전문 분야의 기능을 통합하여 AIME 2025(97.0%) 및 SWE-Bench Pro(52.8%)와 같은 벤치마크에서 업계 최고 수준의 추론 및 코드 성능을 보여줍니다.
논문 및 상세 해석:https://go.hyper.ai/QeSWd
2. VLM³
논문 제목:
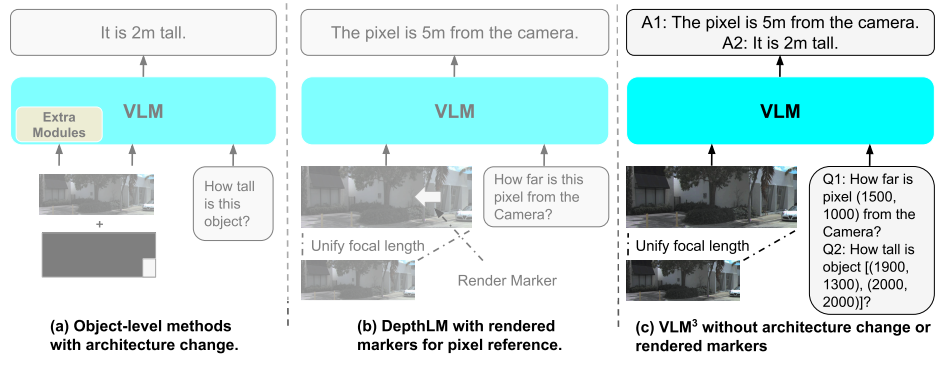
VLM³: 비전 언어 모델은 네이티브 3D 학습자입니다.
메타와 그의 연구팀은 대규모 실험을 통해 VLM이 효율적인 3D 학습을 수행하는 데 복잡한 아키텍처나 특수 설계가 필요하지 않다는 것을 발견했습니다. 필요한 것은 통합된 초점 거리, 텍스트 기반 픽셀 참조 도입, 그리고 적절한 데이터 혼합 및 확장 전략뿐입니다. 이러한 발견을 바탕으로 연구팀은 표준 VLM이 깊이 추정, 픽셀 수준 대응, 카메라 자세 추정, 객체 수준 3D 이해와 같은 작업을 동시에 수행할 수 있도록 하는 최소주의적 설계인 VLM³을 제안했습니다. 기존 아키텍처와 텍스트 기반 학습 방식을 유지하면서도 VLM³의 성능은 전문가 수준의 시각 모델에 근접하거나 심지어 필적하는 수준에 도달하여, 범용 시각 모델이 3D 세계를 학습하는 더 간단하고 확장 가능한 새로운 방법을 제시합니다.
논문 및 상세 해석:https://go.hyper.ai/5ks6r
3. 무엇이든 찾기
논문 제목:
LocateAnything: 병렬 박스 디코딩을 이용한 빠르고 고품질의 시각-언어 접지
기존의 시각 언어 모델은 일반적으로 객체 위치 파악을 좌표 토큰을 단계적으로 생성하는 과정으로 모델링하며, 경계 상자 좌표를 순차적으로 예측해야 합니다. 이는 상자 내부의 기하학적 관계를 무시할 뿐만 아니라 추론 속도를 제한합니다. 이러한 문제를 해결하기 위해 NVIDIA 팀은 경계 상자를 원자 단위로 취급하는 병렬 박스 디코딩(PBD) 메커니즘을 사용하는 LocateAnything을 제안했습니다. 이 메커니즘을 통해 경계 상자의 전체 좌표 세트를 단일 단계에서 병렬로 생성할 수 있습니다. 1억 3,800만 개의 쿼리를 포함하는 대규모 데이터셋과 지능형 오류 대체 기능을 갖춘 하이브리드 추론 모드를 결합하여, 이 모델은 여러 벤치마크에서 더 높은 디코딩 처리량과 높은 IoU(Infrastructure as Unit) 환경에서의 위치 파악 정확도를 달성하며, 통합 시각 위치 파악 및 객체 탐지 작업의 속도와 정확도 한계를 뛰어넘습니다.
논문 및 상세 해석:https://go.hyper.ai/C8jXC
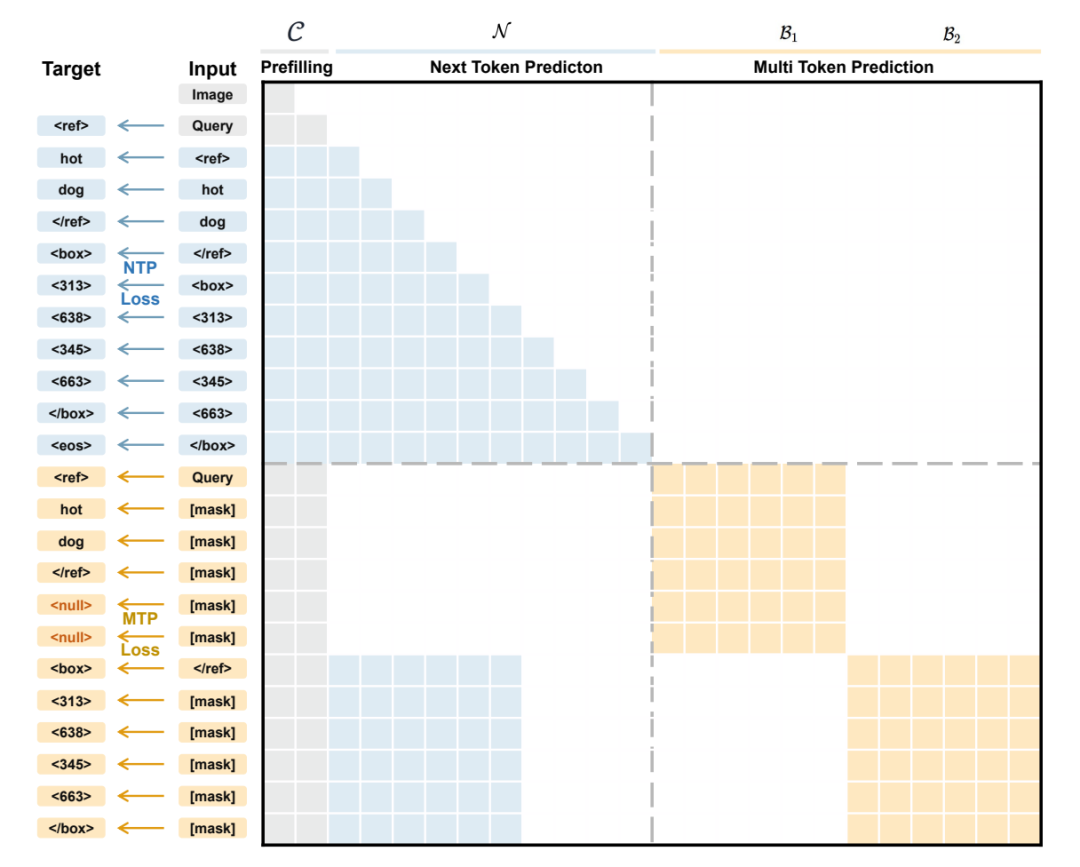
데이터셋 구성 및 출처: 연구팀은 1,200만 개의 고유 이미지, 1억 3,800만 개의 자연어 질의, 그리고 7억 8,500만 개의 레이블이 지정된 경계 상자를 포함하는 대규모 데이터셋인 LocateAnything-Data를 구축했습니다.

4. 퀘인-VLA
논문 제목:
Qwen-VLA: 다양한 작업, 환경 및 로봇 형태에 걸쳐 비전-언어-행동 모델링을 통합합니다.
체화된 지능 연구는 오랫동안 단일 작업에 특화된 모델에 의존해 왔기 때문에 기능이 단편화되고 일반화 능력이 제한적이었습니다. 첸원(Qianwen) 연구팀은 통합된 시각-언어-행동 기반 모델인 Qwen-VLA를 제안합니다. 이 모델은 DiT 기반 행동 디코더를 통해 시각-언어 인식, 이해 및 추론을 연속적인 행동 및 궤적 생성으로 확장합니다. Qwen-VLA는 로봇 작동 궤적, 인간 1인칭 시연, 시뮬레이션 데이터, 내비게이션 작업 및 보조 시각-언어 신호를 포함하는 대규모 공동 사전 학습을 활용합니다. 또한 체화된 인식 단서 조건화 메커니즘을 통해 다양한 로봇 플랫폼에 적응합니다. Qwen-VLA는 작동, 내비게이션 및 궤적 예측을 통합 프레임워크로 통합하여 작업, 환경 및 로봇 형태 전반에 걸쳐 전이성을 달성합니다. 실험 결과, 이 모델은 다양한 작동 및 내비게이션 벤치마크에서 안정적인 다중 작업 성능과 분포 외 일반화 능력을 보여줍니다.
논문 및 상세 해석:https://go.hyper.ai/5x2Tj
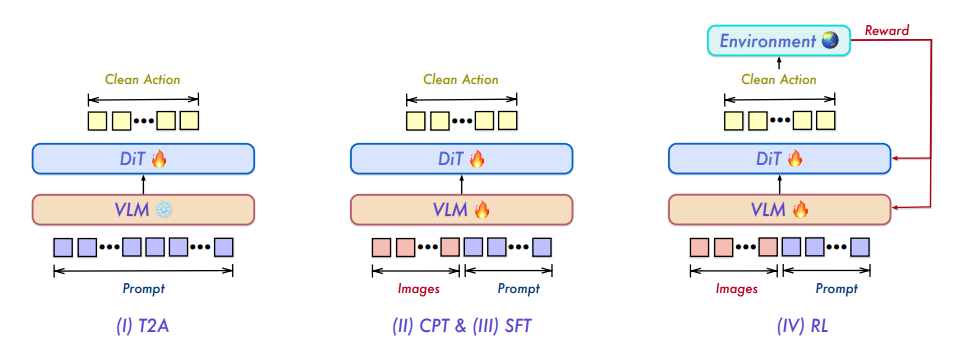
데이터셋 구성 및 출처: 연구팀은 시각, 언어 및 동작 모델링을 통합하기 위해 대규모의 이종 사전 학습 코퍼스를 구축했습니다. 데이터 출처에는 10개 이상의 공개 로봇 벤치마크, 대규모 인간 비디오 코퍼스, 자체 수집 데이터 및 자체 개발 시뮬레이션 파이프라인이 포함됩니다.

5. SDPG
논문 제목:
자체 증류 정책 경사
정책 기반 자기 증류(SDPG)는 모델의 특권적 맥락을 활용하여 자체적으로 생성된 결과를 감독함으로써, 희소 보상 강화 학습에 더욱 조밀한 학습 신호를 제공합니다. 이는 전체 어휘에 대한 역 KL 학생-교사 손실 함수로 공식화할 수 있습니다. 이를 바탕으로 UCLA와 프린스턴 대학교 연구진은 그룹 상대 검증자 이점(RLVR), 표준 편차 정규화, 온라인 전체 어휘 자기 증류, 참조 정책 KL 정규화를 결합한 SDPG 프레임워크를 공동으로 제안했습니다. 실험 결과, SDPG는 RLVR 및 기존 자기 증류 방법보다 안정성과 성능이 향상됨을 보여줍니다.
논문 및 상세 해석:https://go.hyper.ai/p5irp
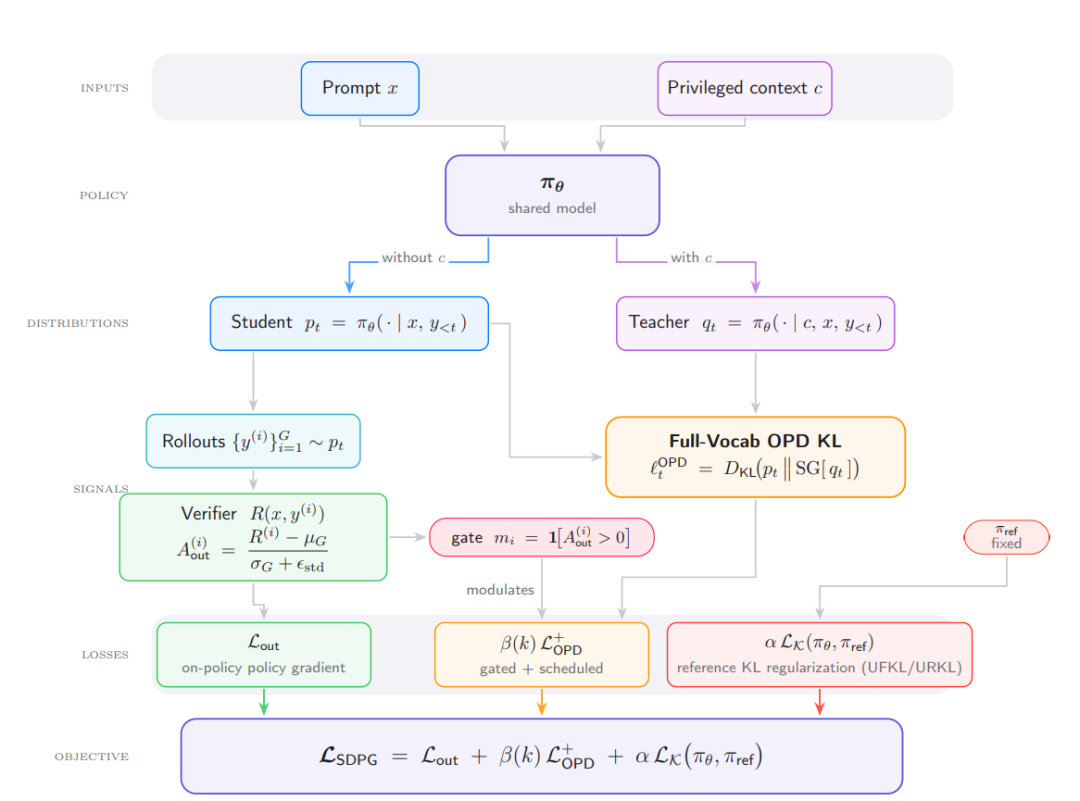
6. GSM-심볼릭
논문 제목:
GSM-Symbolic: 대규모 언어 모델에서 수학적 추론의 한계 이해하기
연구 결과에 따르면 기존의 GSM8K 벤치마크는 모델의 실제 성능을 정확하게 반영하기에 불충분합니다. 이에 애플 연구팀은 기호 템플릿 기반의 제어 가능한 벤치마크인 GSM-Symbolic을 개발했습니다. 실험 결과, 질문에서 숫자나 개체 이름을 변경하는 것만으로도 대규모 모델의 성능에 상당한 변동이 발생하며, 관련 없는 방해 요소를 추가하면 정확도가 급격히 떨어지는 것으로 나타났습니다. 연구팀은 현재의 논리 학습 모델(LLM)이 진정한 논리적 추론 능력을 갖춘 것이 아니라, 훈련 데이터에서 관찰된 추론 단계를 재현하려고 시도하는 것에 불과하다고 추측합니다.
논문 및 상세 해석:https://go.hyper.ai/n3UfJ
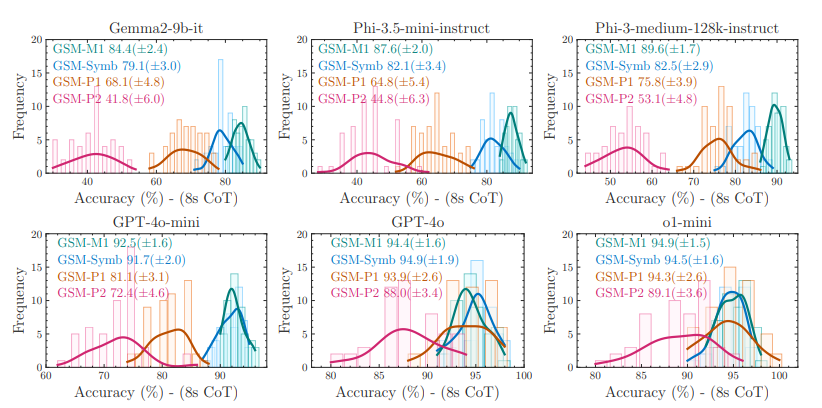
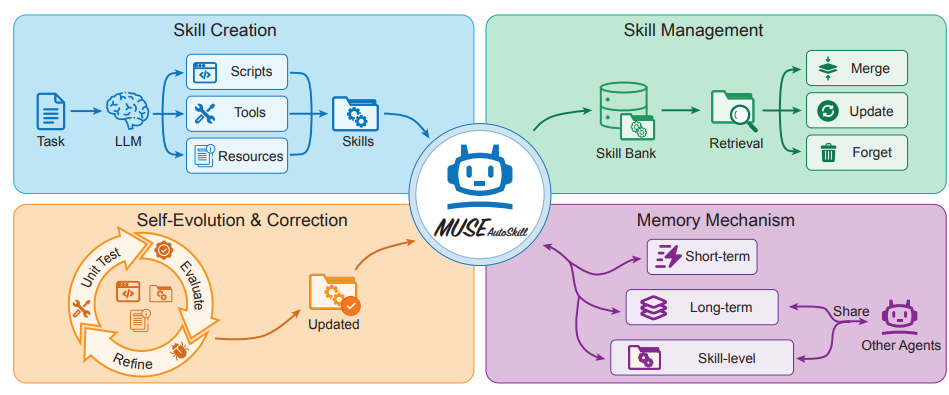
7. MUSE-Autoskill
논문 제목:
MUSE-Autoskill: 스킬 생성, 기억, 관리 및 평가를 통한 자기 진화형 에이전트
ByteDance를 포함한 여러 팀은 스킬의 생성, 기억, 관리, 평가 및 최적화를 하나의 완전한 라이프사이클로 통합하는 지능형 에이전트 프레임워크인 MUSE-Autoskill을 제안했습니다. 이 프레임워크는 스킬 수준의 메모리를 도입하여 다양한 작업에 걸쳐 경험을 축적함으로써 기존의 정적이고 독립적인 스킬의 한계를 극복합니다. SkillsBench에서 수행된 실험 결과는 라이프사이클 관리형 스킬이 작업 성공률, 실행 효율성, 재사용성 및 에이전트 간 전이성을 향상시킬 수 있음을 보여주는 예비 증거를 제공하며, 스킬을 장기적인 라이프사이클을 가진 경험 기반 자산으로 취급하고 테스트하는 것이 중요하다는 점을 강조합니다.
논문 및 상세 해석:https://go.hyper.ai/mdgB2
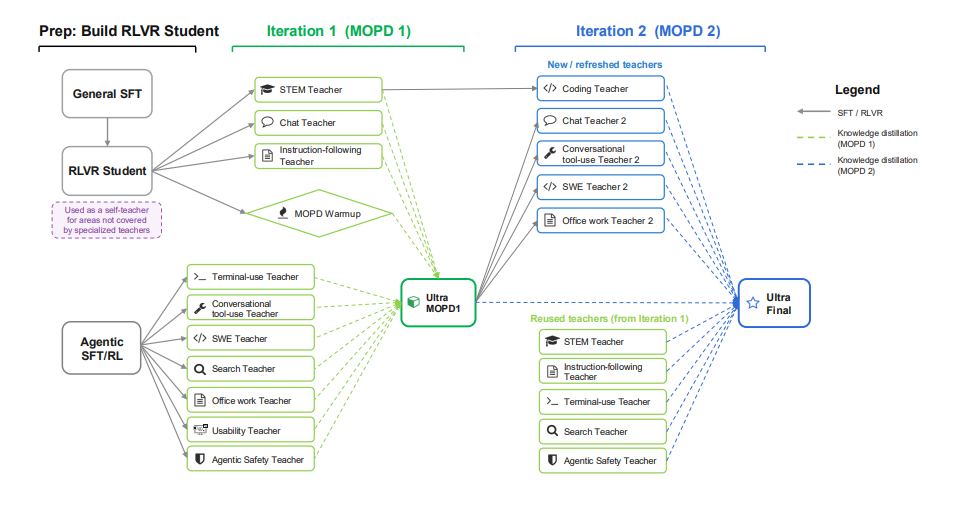
8. 네모트론 3 울트라
논문 제목:
Nemotron 3 Ultra: 에이전트 추론을 위한 개방적이고 효율적인 전문가 혼합형 하이브리드 Mamba-Transformer 모델
NVIDIA는 5,500억 개의 파라미터와 550억 개의 활성화 파라미터를 갖춘 Mamba-Attention MoE 언어 모델인 Nemotron 3 Ultra를 출시했습니다. 이 모델은 20조 개의 토큰으로 사전 학습되었고, 컨텍스트 길이는 100만 개의 토큰으로 확장되었으며, SFT, 강화 학습(RL), 그리고 다중 교사 온라인 정책 증류(MOPD)를 사용하여 사후 학습되었습니다. LatentMoE, 다중 토큰 예측, NVFP4, RLVR, MOPD, 추론 예산 제어와 같은 기술을 활용하여 Nemotron 3 Ultra는 높은 정확도를 유지하면서 기존 공개 LLM보다 약 6배 높은 추론 처리량을 달성하여 장기적인 자율 에이전트 작업에 적합합니다.
논문 및 상세 해석:https://go.hyper.ai/lm6S1
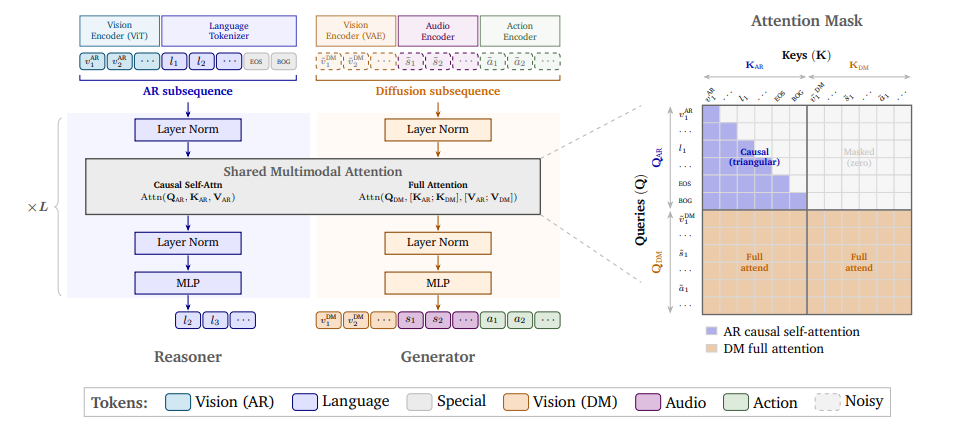
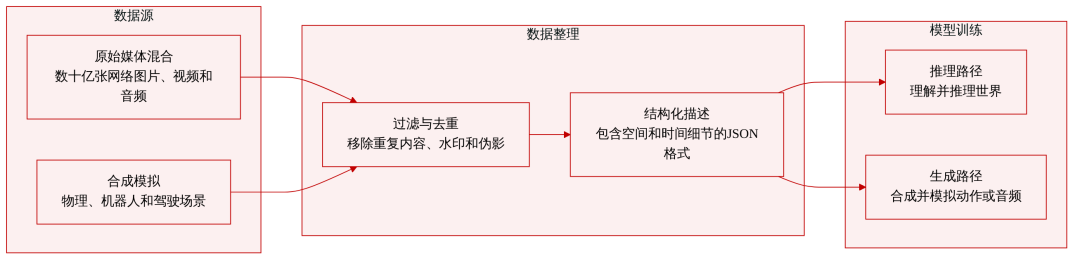
9. 코스모스 3
논문 제목:
코스모스 3: 물리적 AI를 위한 옴니모달 세계 모델
NVIDIA는 언어, 이미지, 비디오, 오디오 및 동작 시퀀스를 통합된 하이브리드 Transformer 아키텍처 내에서 처리하고 생성하는 멀티모달 월드 모델 제품군인 Cosmos 3를 출시했습니다. Cosmos 3는 시각적 언어 모델, 비디오 생성기, 월드 시뮬레이터 및 동작 모델을 단일 프레임워크에 통합하여 매우 유연한 입력/출력 구성을 지원합니다. 평가 결과, 다양한 이해 및 생성 작업에서 최첨단 성능을 달성하여 멀티모달 월드 모델이 실체화된 에이전트를 위한 일반적인 백본 네트워크로서 적합함을 입증했습니다. 학습된 모델은 최고의 오픈 소스 텍스트-이미지/이미지-비디오 모델 및 최고의 정책 모델로 평가되었습니다.
논문 및 상세 해석:https://go.hyper.ai/RoY2u
이번 주 논문 추천 내용은 여기까지입니다. 더 많은 최첨단 AI 연구 논문을 보시려면 hyper.ai 공식 웹사이트의 "최신 논문" 섹션을 방문하세요.
또한, 연구팀의 고품질 연구 결과와 논문 제출을 환영합니다. 관심 있는 분은 NeuroStar WeChat(WeChat ID: Hyperai01)을 추가해 주세요.
다음주에 뵙겠습니다!