Command Palette
Search for a command to run...
스탠포드 대학교는 25,000건의 임상 데이터를 기반으로 최초의 네이티브 3D 복부 CT 시각 언어 모델인 멀린(Merlin)을 출시했으며, 이 모델은 752개 작업에서 선두를 달리고 있습니다.
컴퓨터 단층촬영(CT)은 임상 진단 및 치료에 흔히 사용되는 영상 기법으로, 신체 여러 부위의 질병 진단에 널리 활용되고 있습니다. 통계에 따르면 전 세계적으로 매년 약 3억 건의 CT 촬영이 시행되며, 그중 복부 CT 촬영이 약 4분의 1을 차지합니다. 의료 진단 및 치료가 영상 기술에 점점 더 의존하게 되면서 영상 진단에 대한 수요는 지속적으로 증가하고 있습니다. 그러나 영상의학과 전문의가 복부 CT 영상 한 장을 판독하는 데 일반적으로 20분이 소요되며, 진단 효율성은 급증하는 임상 수요를 따라가지 못하고 있습니다. 더욱 심각한 문제는 영상의학과 전문의 부족 현상입니다. 예측 데이터에 따르면…2036년까지 일부 지역에서는 19,000명 이상의 영상의학과 전문의 부족 현상이 나타날 것으로 예상되며, 이는 해당 산업의 공급과 수요 불균형이 심화되고 있음을 보여줍니다.
머신러닝은 정교한 데이터 처리 및 고처리량 분석 기능을 통해 방대한 양의 의료 영상에서 특징을 신속하게 추출하고 지능적으로 식별하여, 낮은 효율성과 인력 부족과 같은 기존 수동 영상 해석의 문제점을 효과적으로 해결할 수 있습니다. 특히, 대조적 언어-이미지 사전학습(CLIP) 기술을 기반으로 하는 비전-언어 모델(VLM)은 텍스트 표현과 시각적 표현을 공유 임베딩 공간에 정렬하여 자연어를 이용한 시각 모델 감독을 지원합니다.이러한 유형의 모델은 기초 모델로서 제로샷 학습을 달성할 수 있을 뿐만 아니라, 대규모 언어 모델과 결합하고 임상 데이터로 학습시킨 후에는 방사선 영상 및 보고서 분석에 신속하게 적용할 수 있습니다.
이론적, 기술적 발전 외에도 현재의 VLM 기반 방법들은 BiomedCLIP, LLaVA-Rad, Med-PaLMM과 같은 모델들이 성공적으로 구현되면서 방사선학 분야에서 엄청난 응용 가능성을 보여주고 있습니다. 그러나 기술 발전과 모델 구현이 곧 성숙한 응용을 의미하는 것은 아닙니다. VLM은 여전히 실제 적용에서 여러 가지 핵심적인 과제에 직면해 있으며, 이는 임상 현장에서의 광범위한 도입과 신뢰할 수 있는 사용을 저해하고 있습니다.
첫 번째,기존 방법들은 주로 X선 필름과 같은 2차원 영상에 초점을 맞추고 있어 복부 CT 스캔과 같은 3차원 영상을 효율적으로 처리하기 어렵습니다. 슬라이스들을 합쳐서 전체 볼륨을 분석하는 방식은 매우 비효율적입니다.둘째,현재 VLM(Visual Lifecycle Model)의 학습 및 평가에 사용할 수 있는 공개 복부 CT 데이터셋은 없습니다. 기존 모델들은 진단 코드 및 영상의학과 보고서와 같은 다중 모달 임상 데이터를 충분히 통합하지 못했고, 통일된 3차원 복부 CT 작업 벤치마크도 부족하여 관련 기본 모델의 학습 및 평가 시스템에 상당한 격차가 존재합니다.
위의 과제를 고려하여,스탠포드 대학교의 연구팀이 복부 CT 스캔을 위한 최초의 네이티브 3D 시각 언어 모델인 멀린(Merlin)을 제안했으며, 25,494쌍의 복부 CT 스캔과 방사선 보고서가 포함된 데이터 세트를 함께 공개했습니다. Merlin은 실제 병원에서 수집한 정형 및 비정형 데이터(CT 스캔 이미지, 전자 건강 기록(EHR) 진단 코드, 방사선 보고서 등)를 사용하여 단일 NVIDIA A6000 GPU에서 학습되었습니다. 연구팀은 5,137개의 CT 스캔 이미지를 사용하여 내부 검증을 수행했고, 44,098개의 CT 스캔 이미지와 복부 CT 스캔에 초점을 맞춘 두 개의 공개 데이터셋(VerSe 및 TotalSegmentator)을 사용하여 외부 검증을 수행했습니다. 검증 결과는 Merlin이 벤치마크 작업에서 특정 벤치마크 모델보다 전반적으로 우수한 성능을 보임을 보여줍니다.
"Merlin: 컴퓨터 단층 촬영 기반 시각-언어 기초 모델 및 데이터 세트"라는 제목의 관련 연구 결과는 네이처(Nature)에 게재되었습니다.
연구 하이라이트:
* 본 연구는 복부 CT 스캔을 위한 최초의 네이티브 3D 시각 언어 기반 모델인 Merlin을 제안하며, 2D 이미지에만 초점을 맞췄던 기존 모델의 한계를 극복합니다.
* 이번 연구는 25,494쌍의 복부 CT 스캔 이미지와 영상의학과 보고서로 구성된 대규모 데이터 세트를 공개하여, 데이터 세트 분야의 공백을 메웠습니다.
* 본 연구는 구조화된 EHR 데이터와 비구조화된 영상의학과 보고서를 감독 신호로 혁신적으로 통합하고, 다중 작업 학습과 단계별 훈련을 결합한 다단계 사전 훈련 프레임워크를 제안합니다.

서류 주소:
https://www.nature.com/articles/s41586-026-10181-8
저희 공식 위챗 계정을 팔로우하고 백그라운드에서 "멀린"이라고 답장하시면 전체 PDF 파일을 받으실 수 있습니다.
VLM의 훈련 및 평가를 위한 데이터 격차 해소
3D VLM을 훈련하고 평가하는 데 사용할 수 있는 공개적으로 이용 가능한 복부 CT 데이터 세트가 부족한 문제를 해결하기 위해 연구팀은 실제 의료 센터에서 수집한 대량의 규정을 준수하는 데이터를 활용했습니다.결과적으로, 18,321명의 환자를 포함하는 고품질 임상 데이터 세트가 공개되었으며, 여기에는 쌍을 이루는 CT 스캔, 비정형 방사선 보고서 및 정형화된 전자 건강 기록(EHR)이 포함됩니다.안에:
* CT 스캔 데이터:
데이터는 여러 시퀀스를 포함하는 전체 복부 CT 스캔에서 추출되었습니다. 정보량을 극대화하기 위해 가장 많은 축 방향 단면을 포함하는 시퀀스를 선택했습니다. 이 과정을 통해 25,528개의 CT 스캔에서 10,628,509개의 2차원 이미지를 얻었습니다.
* 방사선 검사 보고서:
본 연구에서는 각 CT 스캔에 해당하는 영상의학과 보고서를 수집했습니다. 이 보고서는 여러 부분으로 구성되어 있으며, 그중 가장 중요한 부분은 "소견"과 "평가"입니다. 소견에는 각 장기 계통에 대한 자세한 관찰 내용이 포함되고, 평가에는 주요 임상 소견이 요약되어 있습니다. 특히, 제공된 정보의 세부적인 내용과 기존 연구의 타당성을 고려하여, 본 연구에서는 "소견" 부분만을 활용했으며, 그 결과 총 10,051,571개의 토큰이 생성되었습니다.
* 전자건강기록(EHR):
이 데이터는 국제 질병 분류(ICD) 코드 형태의 진단 정보를 사용하여 모델을 학습하는 데 사용되었으며, 이 코드는 해당 환자의 CT 스캔 기록과 연관되어 있습니다. 데이터 세트에는 총 954,013개의 ICD9 코드(고유 코드 5,686개 포함)와 2,041,280개의 ICD10 코드(고유 코드 10,867개 포함)가 포함되어 있습니다.
데이터 분할 측면에서, 사전 학습 데이터셋은 60%(CT 스캔 15,331개), 20%(CT 스캔 5,060개), 20%(CT 스캔 5,137개)의 세 가지 하위 데이터베이스로 나누어 각각 학습, 검증 및 테스트에 사용되었습니다. 예방 조치로, 한 환자의 여러 CT 스캔은 동일한 하위 데이터베이스에 포함되지 않도록 했습니다.
또한,이 실험에서는 외부 검증을 위해 세 곳의 독립 기관에서 제공한 44,098개의 데이터 포인트를 사용했으며, 이 모든 데이터가 테스트에 활용되었습니다.자세한 내용은 다음과 같습니다.
* 외부 데이터 세트 1: 복부 CT 스캔 6,997개 포함
* 외부 데이터 세트 2: 복부 CT 스캔 25,986개 포함
* 외부 데이터 세트 3: 복부 CT 스캔 4,872개와 흉부 CT 스캔 6,243개를 포함합니다.
복부 CT 스캔 전용 공개 데이터셋으로는 VerSe와 TotalSegmentator가 있습니다. VerSe 데이터셋에는 160개의 CT 스캔이, TotalSegmentator 데이터셋에는 401개의 CT 스캔이 포함되어 있습니다. 이 중 34개의 스캔을 선별하여 다중 작업, 다중 질병 예측의 사전 학습 및 테스트에 사용했으며, 나머지 367개의 스캔은 80%(293개 스캔)와 20%(74개 스캔)로 나누어 각각 학습과 검증에 사용했습니다.
다중 작업 학습 및 단계별 교육 전략, 차별화된 솔루션은 멀린의 높은 효율성을 보장합니다.
모델 아키텍처 측면에서 보면,Merlin은 이미지 인코더와 텍스트 인코더로 구성된 이중 인코더 아키텍처를 사용하여 이미지-텍스트 정렬을 구현합니다.이미지 인코더는 I3D ResNet152를 사용하는데, 이는 "팽창(inflation)" 과정을 통해 2차원 사전 학습 모델의 가중치를 재사용하고 이를 3차원 컨볼루션 커널의 세 번째 차원에 복사합니다. 본 논문에서 사용된 인코더는 Clinical Longformer로, 다른 생의학 사전 학습 모델 및 일반 CLIP 인코더보다 긴 텍스트 처리 능력을 갖추고 있으며, 4,096개의 긴 컨텍스트를 지원하여 긴 텍스트 보고서의 요구 사항에 적합합니다.
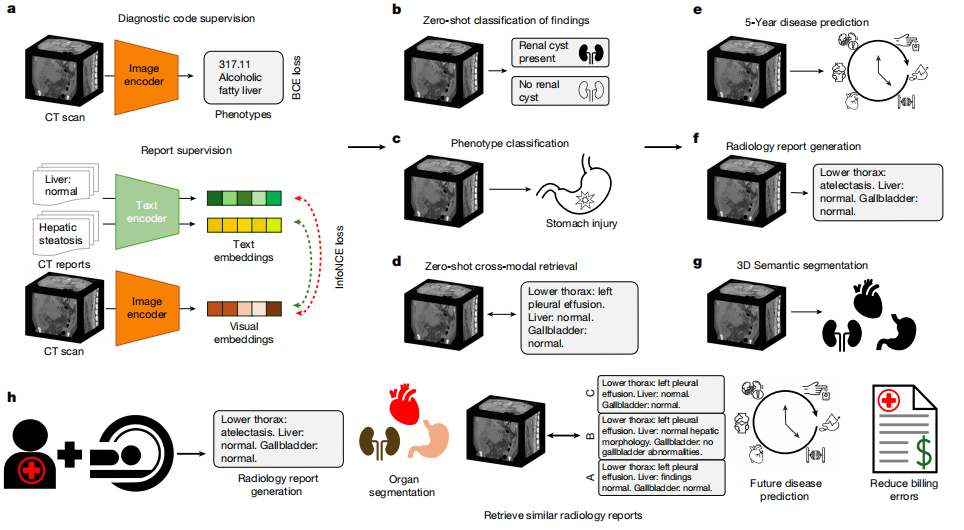
모델 학습을 위해 Merlin은 표현형 분류와 방사선 보고서를 각각 처리하기 위해 두 가지 손실 함수를 사용합니다.표현형 분류에는 이진 교차 엔트로피 손실 함수를 사용했고, 방사선 보고서 대비 학습에는 InfoNCE 손실 함수를 사용했습니다.이미지와 텍스트 모두에 대한 임베딩 차원은 OpenCLIP 실험에서 사용된 ViT-Base 모델의 임베딩 차원과 동일하게 512로 설정되었습니다. 이후, 학습 전략에서 시각 인코더와 텍스트 인코더 모두에 대해 그래디언트 체크포인팅을 활성화하고 FP16 혼합 정밀도 학습을 적용했습니다.
사용된 최적화 알고리즘은 AdamW였으며, 초기 학습률은 1 x 10⁻⁵, β 값은 (0.9, 0.999)였습니다. 코사인 학습률 스케줄러를 사용하여 학습률이 0에서 300까지 감소하는 학습 에포크 수를 설정했습니다. 하드웨어는 48GB A6000 GPU 하나로 구성되었으며, 최대 배치 크기는 18이었습니다.
EHR 표현형 및 방사선 보고서를 활용한 다중 작업 교육 외에도,이 연구에서는 단계별 교육 프로그램도 고려했습니다.구체적으로, Merlin 이미지 인코더는 1단계에서 EHR 진단 코드를 사용하여 먼저 학습되고, 2단계에서 방사선 보고서를 사용하여 비교 학습됩니다. 1단계에서 학습된 EHR 정보가 손실되는 것을 방지하기 위해, 2단계 학습에서는 표현형 손실 함수를 낮은 가중치로 적용합니다.
첫 번째 단계에서는 AdamW 옵티마이저를 사용하며, 초기 학습률은 1 x 10⁻⁴, β = (0.9, 0.999), 지수 학습률 스케줄러(γ = 0.99), 그리고 배치 크기 22의 단일 A6000 GPU를 사용합니다. 두 번째 단계에서 사용되는 하이퍼파라미터는 멀티태스킹 학습에서 사용된 것과 동일합니다.
요약하자면, 다중 작업 학습과 단계별 훈련은 두 가지 전략에 대해 차별화된 설계를 구현했으며, 연구팀은 단계별 훈련에 대한 망각 방지 기능을 개선했습니다. 이러한 차별화된 훈련 전략은 멀린의 효율성과 정확성을 보장하는 핵심 설계이며, 후속적인 제거 실험을 통해 추가적으로 검증되었습니다.
752개 작업 범주에 대한 종합적인 평가 결과, 멀린이 다른 모든 제품보다 우수한 성능을 보였습니다.
실험 과정에서 연구팀은 5,137개의 CT 스캔을 기반으로 내부 검증을 수행했고, 44,098개의 CT 스캔과 두 개의 공개 데이터셋(VerSe 및 TotalSegmentator)을 기반으로 외부 검증을 수행했으며, 특히 복부 CT 스캔에 초점을 맞췄습니다.평가 과제는 총 6개의 주요 범주로 나뉘며, 752개의 세부 하위 과제로 구성됩니다.주요 작업 범주에는 제로샷 분류(하위 작업 31개), 표현형 분류(하위 작업 692개), 제로샷 교차 모달 검색(하위 작업 23개), 5년 질병 예측(하위 작업 6개), 방사선 보고서 생성 및 3D 분할이 포함됩니다.
제로샷 분류 기법을 이용한 결과 분류 작업에서는 내부 및 외부 임상 데이터에서 얻은 복부 CT 스캔 30개를 분석했습니다.Merlin은 내부 검증 데이터 세트에서 0.741의 F1 점수(95% 신뢰 구간, 0.727~0.755)를, 외부 검증 데이터 세트에서 평균 0.647의 F1 점수(95% 신뢰 구간, 0.607~0.678)를 달성했습니다.이러한 점수는 k=1 풀링을 사용한 2D OpenCLIP 모델과 평균 풀링을 사용한 정밀 조정된 2D BioMedCLIP 모델보다 유의미하게 높았습니다(P < 0.001). 아래 그림을 참조하십시오.
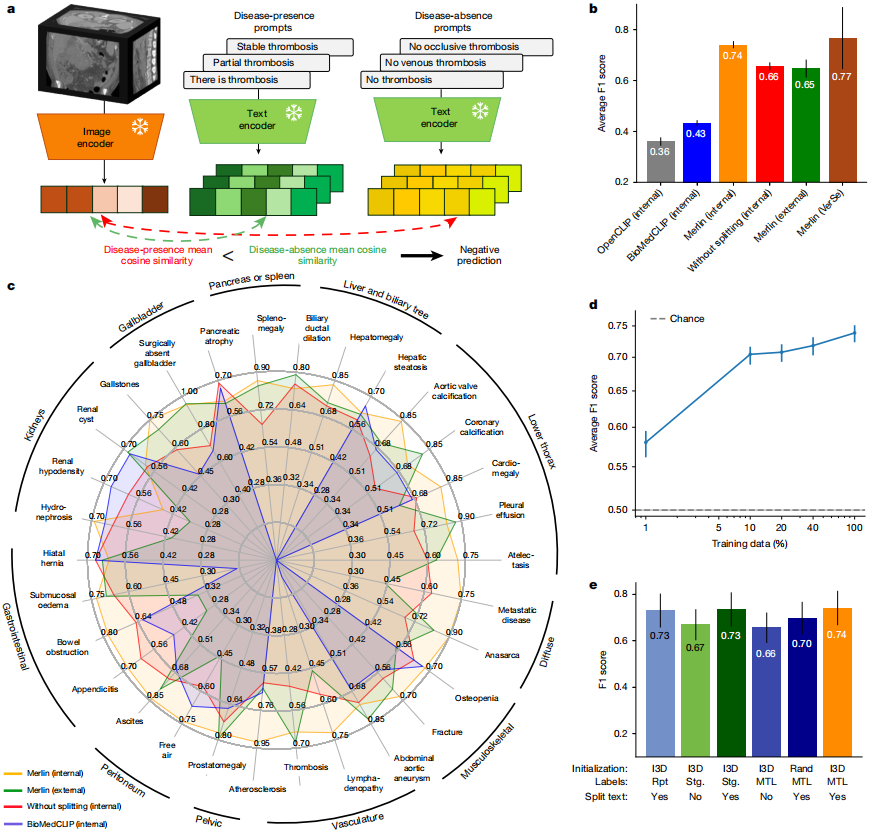
질적 관점에서 보면,Merlin은 흉막 삼출 및 복수와 같이 특징이 뚜렷한 질병에 대한 외부 데이터 세트에서 높은 성능을 유지합니다.하지만 맹장염이나 림프절 비대와 같은 세밀한 특징을 탐지할 때는 성능이 다소 저하됩니다. 또한, 방사선 보고서 분할을 사용하지 않은 경우, Merlin은 외부 평가 데이터 세트에서 평균 F1 점수 0.656(95% 신뢰 구간)을 달성했습니다.
절제 실험 비교에서확장된 3D 네트워크로 초기화된 멀린 모델이 가장 우수한 성능을 보인다.F1 점수는 0.741(95% 신뢰구간: 0.727~0.755)이었습니다. 영상의학과 보고서를 분할했을 때, EHR과 영상의학과 보고서를 결합한 모델의 점수는 0.735(95% 신뢰구간: 0.719~0.748)였습니다. 영상의학과 보고서만 사용하고 보고서 분할을 적용한 방식은 F1 점수 0.730(95% 신뢰구간: 0.714~0.744)으로 세 번째로 우수한 성능을 보였습니다. 영상의학과 보고서 분할 여부가 모델 성능에 가장 큰 영향을 미쳤으며, 보고서 분할을 적용하지 않은 경우 Merlin 모델의 F1 점수는 평균 7.9점 감소했습니다(P < 0.01).
또한 언급할 가치가 있는 것은 다음과 같습니다.제로샷 멀린은 10% 및 100% 훈련 데이터 모두에서 지도 학습 실험에서 모든 지도 학습 기준 모델보다 우수한 성능을 보였습니다.100% 훈련 데이터를 사용했을 때 F1 점수는 29% 향상되었지만, 10% 훈련 데이터를 사용했을 때는 무려 45%나 향상되었습니다. 실험 결과, 100% 훈련 데이터를 사용했을 때 제로샷 멀린이 지도 학습 멀린보다 F1 점수를 16% 향상시키며 훨씬 뛰어난 성능을 보였습니다.
표현형 분류 과제에서, PheWAS로 정의된 692개의 임상 표현형을 예측하는 Merlin의 성능을 평가한 결과, 수신자 작동 특성 곡선(AUROC)의 평균값은 0.812(95% 신뢰구간, 0.808–0.816)를 달성했습니다. 총 258개의 표현형에서 AUROC 값이 0.85를 초과했고, 102개의 표현형에서 AUROC 값이 0.9를 초과했습니다. (아래 그림 참조)
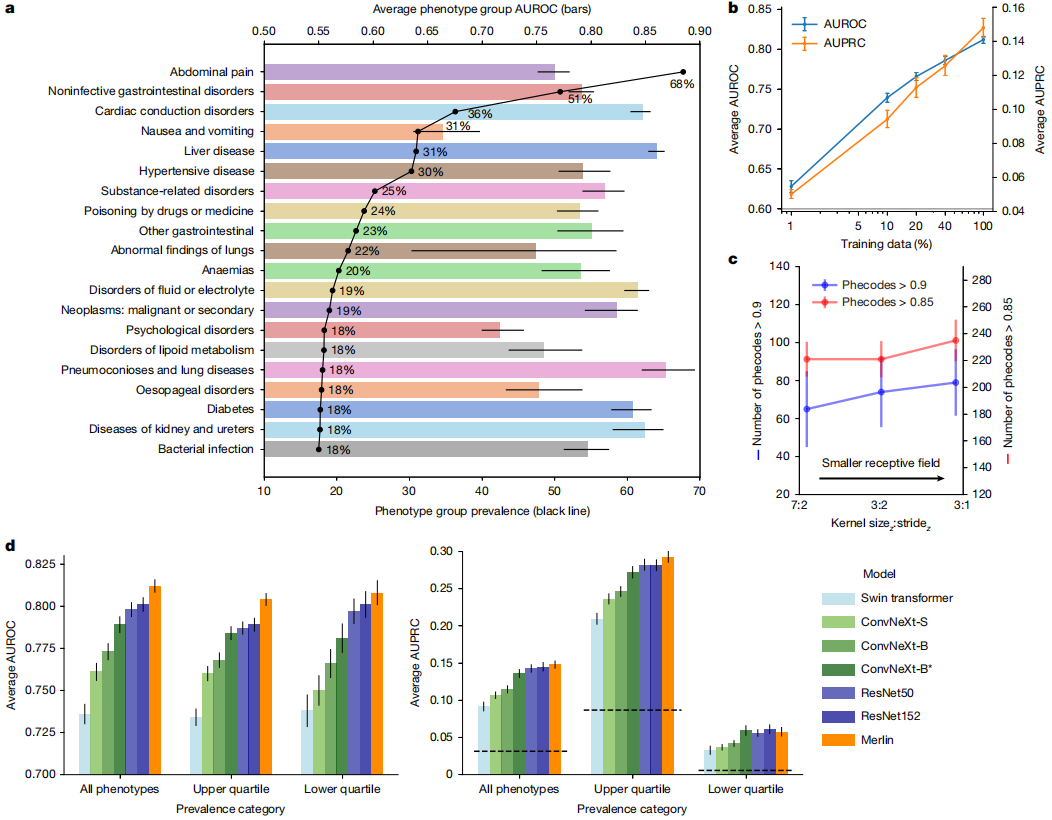
내부 테스트에서 발생률이 가장 높은 상위 20개 표현형을 분석했을 때,멀린은 간, 신장, 요관 및 위장관을 포함한 여러 장기 계통의 질병을 탐지하는 데 탁월합니다.
제로샷 크로스 모델 검색 작업에서 첫 번째 단계는 64개의 사례를 기반으로 하는 "이미지 탐색" 검색 작업입니다.Merlin은 OpenCLIP 및 BioMedCLIP에 비해 상당한 이점을 보여줍니다.이는 Merlin이 사용하는 Clinical Longformer 텍스트 인코더 덕분이며, OpenCLIP과 BioMedCLIP은 각각 최대 토큰 길이를 77과 256으로 제한합니다. 반대로, Merlin의 뛰어난 성능은 64개 사례를 기반으로 한 "발견 이미지" 검색 작업에서도 재현되었습니다. 아래 그림을 참조하십시오.
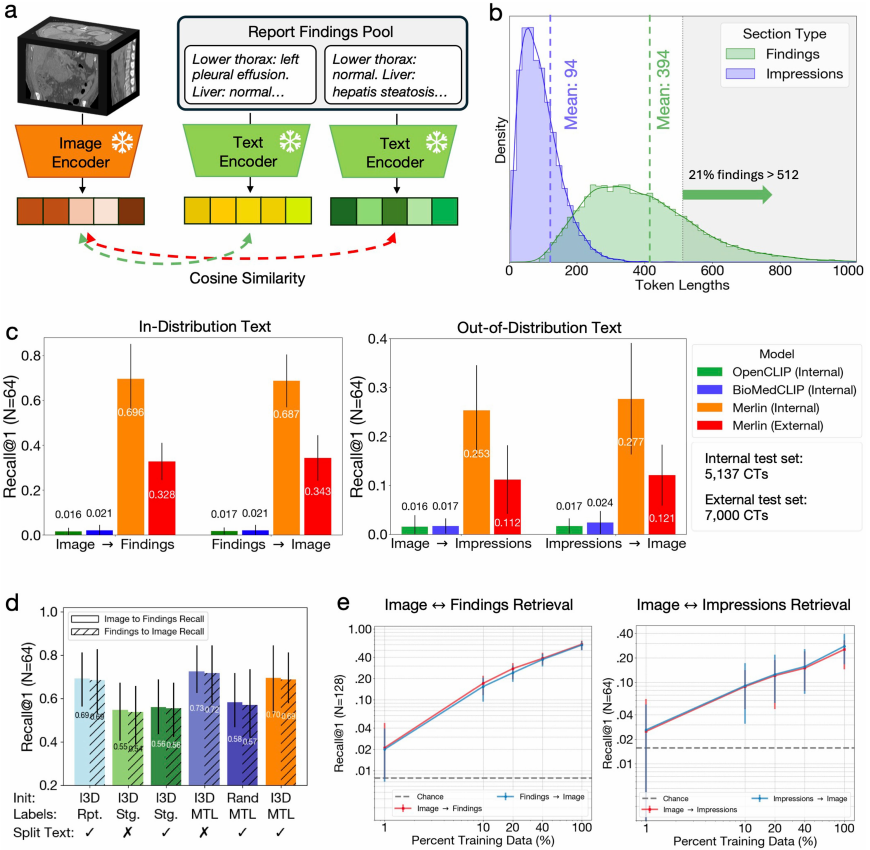
더욱 중요한 증거는 멀린이 시각-언어 정렬 훈련에 대한 보고서에서 객관적으로 기술된 "결과"만을 사용했을 때조차도,매우 일반화된 보고서 "인상"을 다룰 때조차도, 이는 여전히 높은 수준의 영역 간 일반화 능력을 보여줍니다.그 결과는 역공학 작업을 통해 다시 한번 검증되었습니다. 또한, Merlin의 외부 테스트 데이터셋에 대한 검색 성능은 내부 테스트 데이터셋에 비해 저하되었지만, 다른 외부 기준 데이터셋보다 여전히 5~7배 우수했습니다.
다중 질환 5년 예측 과제에서, 본 실험은 건강한 환자가 만성 신장 질환, 골다공증, 심혈관 질환, 허혈성 심장 질환, 고혈압 및 당뇨병을 포함한 여러 주요 만성 질환에 향후 5년 동안 걸릴 위험을 멀린이 얼마나 잘 예측하는지 평가했습니다.
Merlin을 미세 조정하고 100% 다운스트림 레이블을 사용한 결과, 5년 이내 질병 발생률 예측에 대한 AUROC 값은 0.757에 도달했습니다(95%의 신뢰 구간: 0.743-0.772).이 성능은 이미지만 사용하는 ImageNet 사전 학습(I3D) 모델보다 TP3T 값이 71점 더 높습니다.단 101개의 TP3T 레이블만 사용하더라도, Merlin의 5년 이내 질병 발생률 예측 AUROC는 여전히 0.708(951개의 TP3T에 대한 신뢰 구간: 0.692-0.723)에 도달하여 ImageNet 사전 학습 모델의 4.41개의 TP3T보다 우수한 성능을 보입니다. 아래 그림을 참조하십시오.
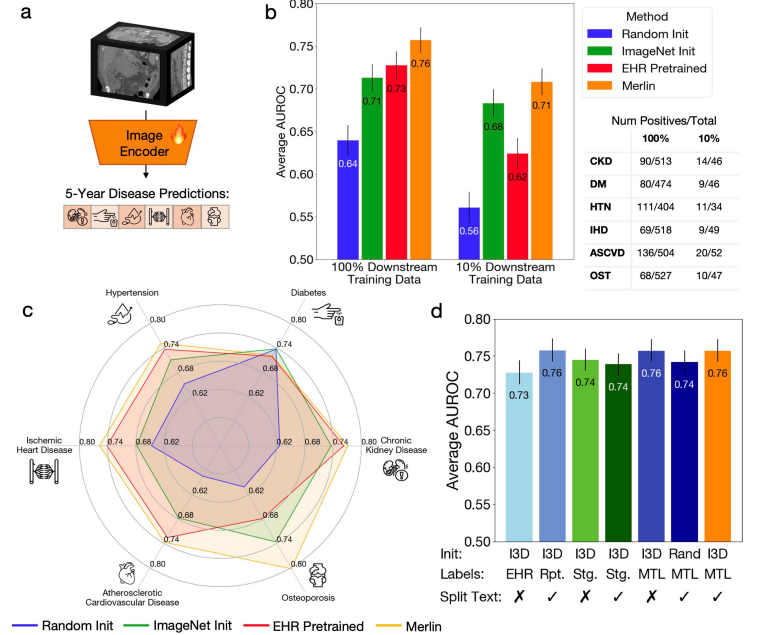
게다가,Merlin은 훈련 데이터의 1/10만 사용하더라도 100%의 데이터로 훈련된 ImageNet 모델의 예측 성능과 유사한 수준을 보여줍니다.이는 멀린의 무사고 운전 능력과 강력한 데이터 전송 능력을 여실히 보여줍니다.
방사선 보고서 생성 작업에서, 기준 모델인 RadFM과 비교했을 때, RadGraph-F1, BERT 점수, ROUGE-2, BLEU와 같은 정량적 지표를 기반으로 한 테스트에서,Merlin은 해부학적 논리적 구조 및 완전한 보고 결과의 모든 측면에서 이전 버전을 능가합니다.
Merlin은 품질 면에서 매우 정확한 진단, 병변 위치 파악 및 증상 설명을 제공하는 우수한 보고서를 생성합니다. 그러나 Merlin은 때때로 보수적인 판단을 내리기도 하는데, 예를 들어 수동으로 생성된 보고서와 CT 보고서 모두에서 발견되는 문제를 과소 보고하는 경우가 있습니다. 이는 CT 스캔을 기반으로 생성된 영상의학 보고서의 초기 시연 단계에서 나타나는 현상이며, 보고서 품질이 향상됨에 따라 점차 개선될 것입니다.
3D 의미 분할 작업에서 Merlin은 101 TP3T의 훈련 데이터만 사용할 경우 매크로 평균 Dice 점수에서 nnUNet 프레임워크보다 4.71 TP3T 높은 성능을 보였습니다. 1001 TP3T의 훈련 데이터를 사용할 경우 nnUNet 프레임워크가 Merlin의 초기 모델보다 약간 더 나은 성능을 보였지만, Dice 점수 차이는 0.006에 불과했습니다.
테스트 세트에 포함된 20개 장기 중, Merlin은 10% 데이터로 학습했을 때 12개 장기에서 nnUNet 프레임워크보다 더 높은 Dice 계수를 달성했으며, 전립선 분할에서는 최대 41%까지 개선되었습니다.
또한, 외부 검증 시험에서 연구팀은 10만 건 이상의 외부 CT 스캔 데이터 세트를 사용하여 총 44,098건의 외부 CT 스캔에 대해 멀린을 평가했습니다.이 모델은 다양한 사이트와 해부학적 위치에서 안정적이고 정확한 성능을 보여주며, 훈련 데이터셋과 외부 테스트 데이터셋 간의 분포 차이를 극복합니다.또한, 해당 모델의 성능은 다른 기준 모델들을 일관되게 능가했으며, 흉부 관련 작업에서는 특수 흉부 CT 기준 모델보다도 뛰어났습니다.
시각적 언어 모델은 대규모 다중 모드 의료 데이터의 잠재적 가치를 실현시켜 줍니다.
본 연구 외에도 의학 분야의 시각 언어 모델 관련 연구 성과가 잇따라 발표되고 있습니다. 예를 들어, 스탠포드 대학교 연구팀은 대규모의 레이블이 지정되지 않고 쌍을 이루지 않는 이미지와 텍스트 데이터를 통합하는 것을 목표로 하는 시각 언어의 기본 모델인 MUSK(통합 마스크 모델링을 적용한 멀티모달 트랜스포머)를 제안했습니다.
논문 제목: 정밀 종양학을 위한 비전-언어 기반 모델
서류 주소:
https://www.nature.com/articles/s41586-024-08378-w
상하이 자오퉁 대학 등이 제안한 지식 강화 사례 기반 모델 KEEP는 기존 모델들이 주로 데이터 중심 접근 방식에 의존하고 의학 지식을 명시적으로 통합하지 못하는 문제를 해결합니다. 이 모델은 11,454개의 질병과 139,143개의 속성으로 구성된 포괄적인 질병 지식 그래프를 활용하여 수백만 개의 병리학적 이미지-텍스트 쌍을 질병 온톨로지 계층 구조에 맞춰 143,000개의 의미론적으로 구조화된 그룹으로 재구성합니다. 이러한 지식 강화 사전 학습 방법은 시각적 표현과 텍스트 표현을 계층적 의미 공간에 정렬함으로써 질병 간의 관계와 형태학적 패턴에 대한 심층적인 이해를 가능하게 합니다.
논문 제목: 암 진단을 위한 시각-언어 병리학 기초 모델의 지식 강화 사전 훈련
서류 주소:
https://www.sciencedirect.com/science/article/pii/S1535610826000589
요약하자면, 다양한 감각 정보를 통합적으로 이해하는 시각 언어 모델은 의학 및 영상의학 분야에서 엄청난 잠재력을 보여주고 있습니다. 이러한 모델은 의료 영상, 진료 기록, 임상 지침을 통합하여 지능적인 병변 식별, 사례 분석 지원, 진단 보고서 자동 생성 등을 가능하게 합니다. 이는 의사에게 효율적인 보조 도구를 제공할 뿐만 아니라 질병 예측에 대한 새로운 통찰력을 제공하여 현대 의학이 "경험 중심"에서 "데이터 중심"으로 전환되는 속도를 가속화합니다.








