Command Palette
Search for a command to run...
온라인 튜토리얼 | NVIDIA 오픈 소스 LocateAnything은 이미지 및 비디오 대상 포인팅, 개방형 어휘 객체 감지, 대상 위치 파악, OCR 텍스트 위치 파악 및 기타 기능을 지원하는 3B 모델입니다.

시각 언어 모델(VLM)이 에이전트, 멀티모달 상호작용, 그리고 실제 작업으로 발전함에 따라, "이미지 이해"는 더 이상 최종 목표가 아닙니다. 더욱 중요한 것은 "목표물의 정확한 위치 파악"입니다. 이는 개방형 어휘 객체 탐지, GUI 에이전트 인터페이스 조작, 문서 이해, 그리고 로봇 공학 및 자율 주행 시스템의 환경 인식에 적용됩니다.이러한 모든 요인들은 시각적 접지 능력에 대한 요구를 점점 더 높이고 있습니다.
하지만 현재 주류 시각 언어 모델들은 일반적으로 지역화 작업을 처리할 때 "좌표 토큰 생성" 방식을 채택하는데, 이는 2차원 경계 상자를 여러 개의 1차원 좌표 토큰으로 분할한 다음, 이들을 하나씩 생성하고 디코딩하는 방식입니다. 이러한 접근 방식은 경계 상자의 내부 기하학적 일관성을 유지하는 데 어려움을 겪을 뿐만 아니라...또한, 엄격한 순차적 생성 메커니즘은 추론 속도를 제한합니다.모델이 많은 수의 목표물을 동시에 처리해야 할 때, 위치 파악 효율성과 정확도 사이의 균형을 맞추기가 어려운 경우가 많습니다.
이러한 오랜 병목 현상에 대응하여,NVIDIA는 최근 Eagle VLM 시리즈의 새로운 구성원인 LocateAnything-3B를 오픈소스로 공개했습니다.이 모델은 30억 개의 파라미터를 가진 시각적 언어 현지화 모델로, 개방형 어휘 객체 감지, 포인터 표현 현지화, OCR 텍스트 현지화, GUI 요소 현지화, 이미지 및 비디오에서의 대상 포인팅 등 다양한 작업을 지원하여 통합된 시각적 현지화 및 감지 프레임워크 구축을 목표로 합니다.
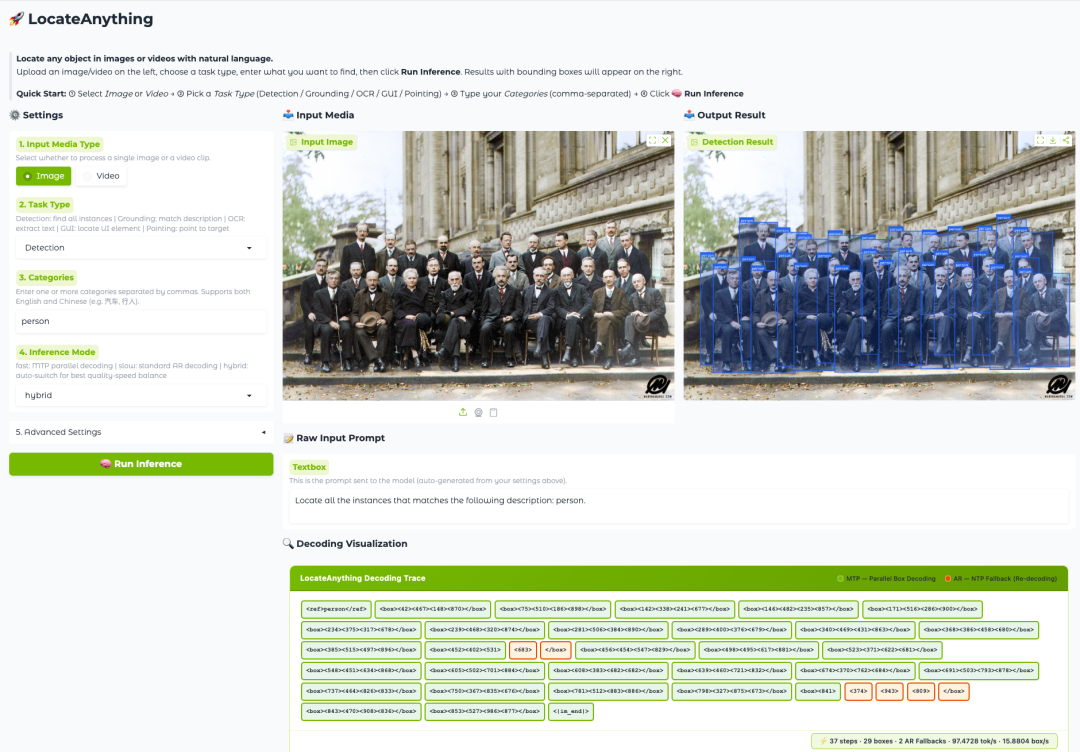
LocateAnything-3B의 핵심 혁신은 Parallel Box Decoding(PBD)이라는 새로운 메커니즘에 있습니다. 좌표 토큰을 하나씩 생성하는 기존 방식과는 달리,PBD는 경계 상자 및 키포인트와 같은 기하학적 요소를 단일 병렬 프로세스에서 완전한 구조로 예측할 수 있습니다.이 설계는 경계 상자 내의 기하학적 일관성을 유지할 뿐만 아니라 디코딩 처리량을 크게 향상시켜 모델이 높은 정밀도의 위치 파악 기능을 유지하면서 더 빠른 추론 속도를 달성할 수 있도록 합니다.
NVIDIA는 아키텍처 혁신 외에도 이 모델을 기반으로 대규모 학습 시스템을 구축했습니다. 연구팀은 확장 가능한 데이터 엔진을 개발하고 1억 3,800만 개 이상의 학습 샘플을 포함하는 LocateAnything-Data 데이터셋을 출시했습니다. 이 데이터셋은 자연 풍경, 로봇 공학, 자율 주행, GUI 상호 작용, 문서 이해 및 OCR과 같은 다양한 분야를 포괄하며, 복잡한 시나리오에서 모델의 일반화 능력을 크게 향상시킵니다.
실험 결과에 따르면 LocateAnything은 여러 시각적 위치 추정 벤치마크에서 더 높은 위치 추정 품질과 더 빠른 디코딩 속도를 모두 달성하여, 통합 시각적 위치 추정 모델이 속도와 정확도 사이의 기존 상충 관계를 뛰어넘도록 발전시켰습니다. 빠르게 발전하는 GUI 에이전트, 자동 주석 시스템 및 차세대 멀티모달 에이전트에게 있어 이러한 효율적이고 정확한 공간 이해 능력은 필수적인 인프라 수준의 역량이 되고 있습니다.
현재 HyperAI 공식 웹사이트(hyper.ai)의 튜토리얼 섹션에서 "LocateAnything-3B: 빠르고 고품질의 시각적 언어 현지화 모델"을 노트북 형태로 제공하여 배포 진입 장벽을 낮췄습니다.
온라인으로 실행:https://go.hyper.ai/4l9jB
더 많은 온라인 튜토리얼:
더 자세한 정보를 원하시면 저희 공식 웹사이트를 방문해 주세요.
데모 실행
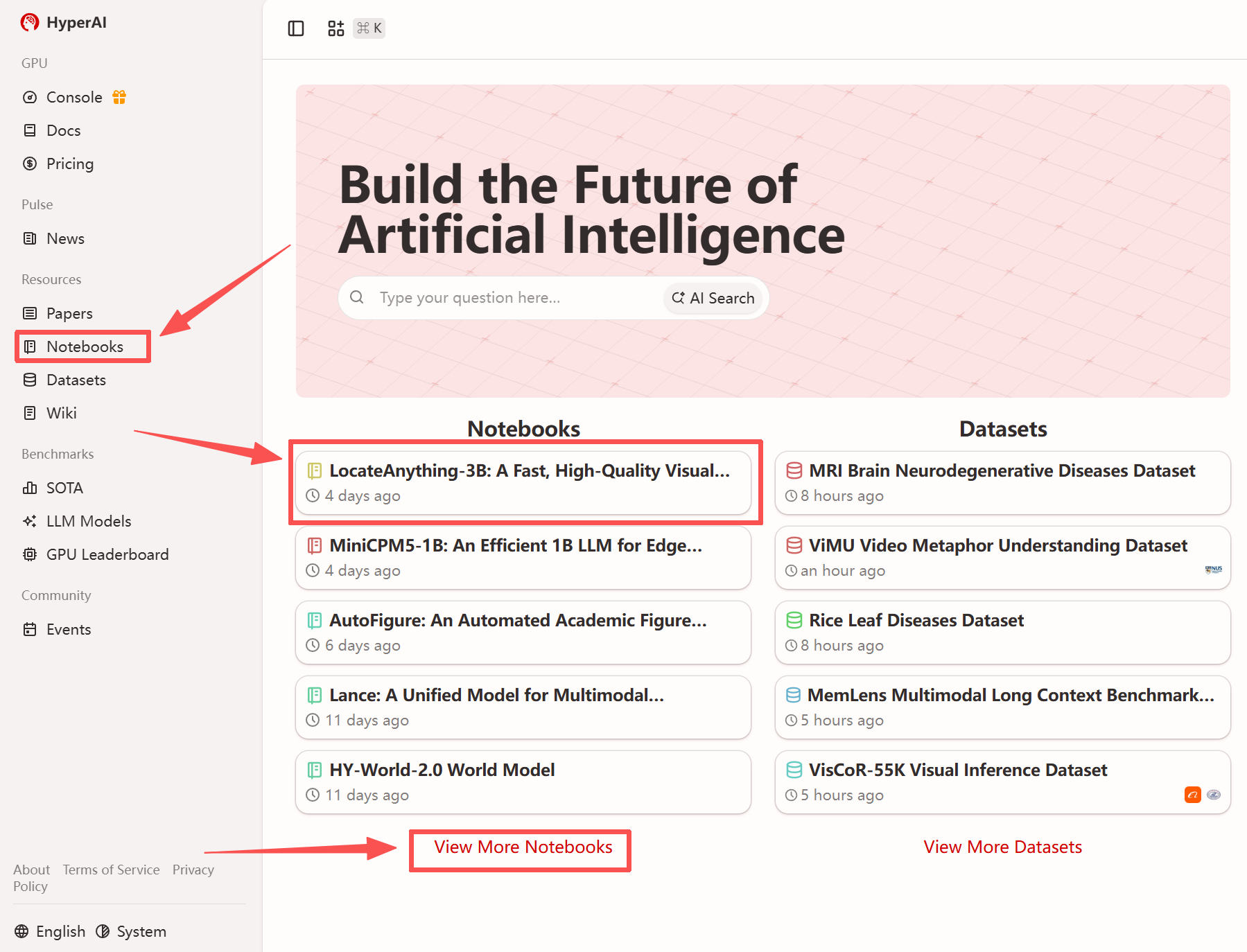
1. hyper.ai 홈페이지에 접속한 후 "튜토리얼" 페이지를 선택하거나 "더 많은 튜토리얼 보기"를 클릭하고 "LocateAnything-3B: 빠르고 고품질의 시각적 언어 현지화 모델"을 선택한 다음 "이 튜토리얼 실행"을 클릭합니다.
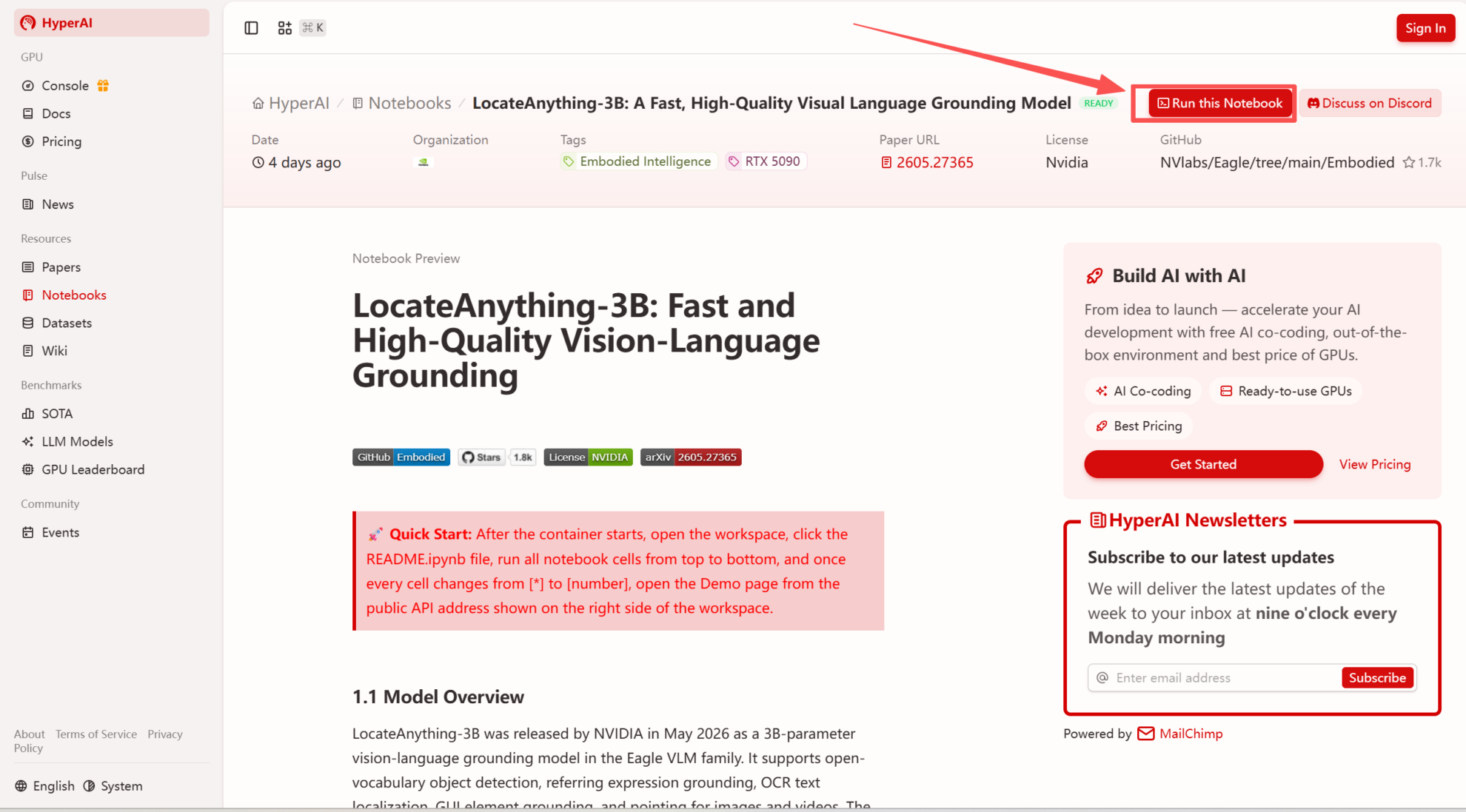
2. 페이지가 리디렉션된 후 오른쪽 상단의 "복제"를 클릭하여 튜토리얼을 자신의 컨테이너로 복제합니다.
참고: 페이지 오른쪽 상단에서 언어를 변경할 수 있습니다. 현재 중국어와 영어로만 제공됩니다. 이 튜토리얼에서는 영어로 된 단계를 안내합니다.
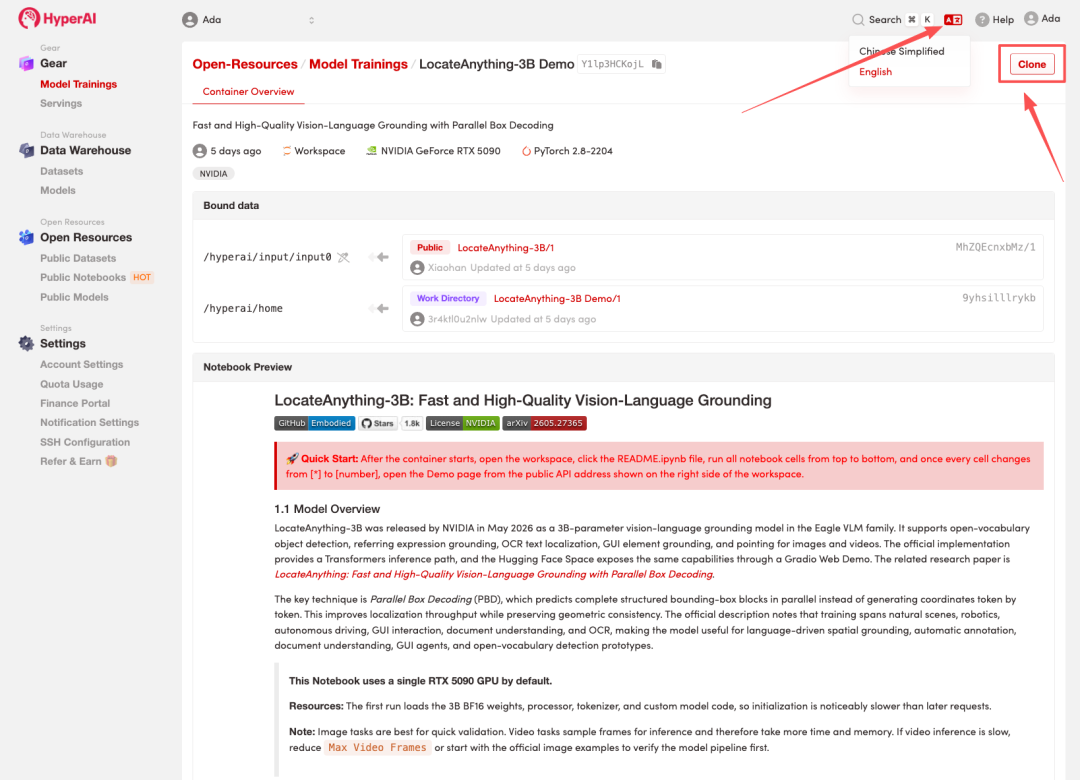
3. "NVIDIA RTX 5090" 및 "PyTorch" 이미지를 선택하고 "작업 실행 계속"을 클릭합니다.
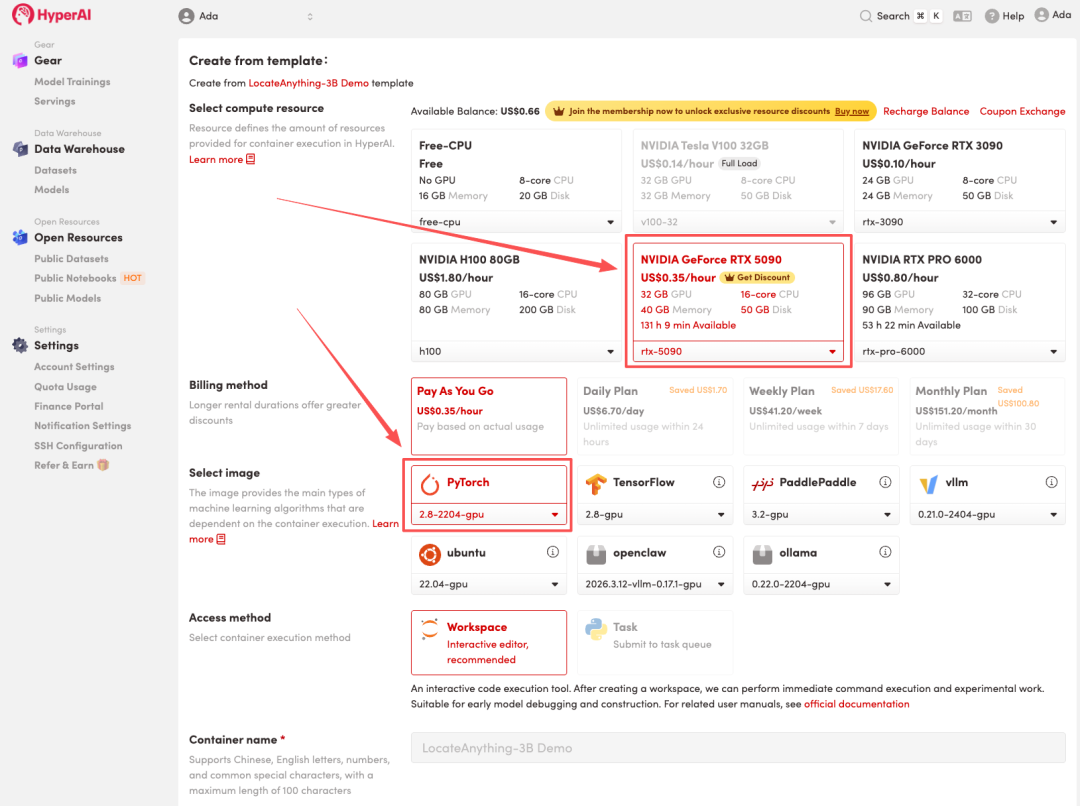
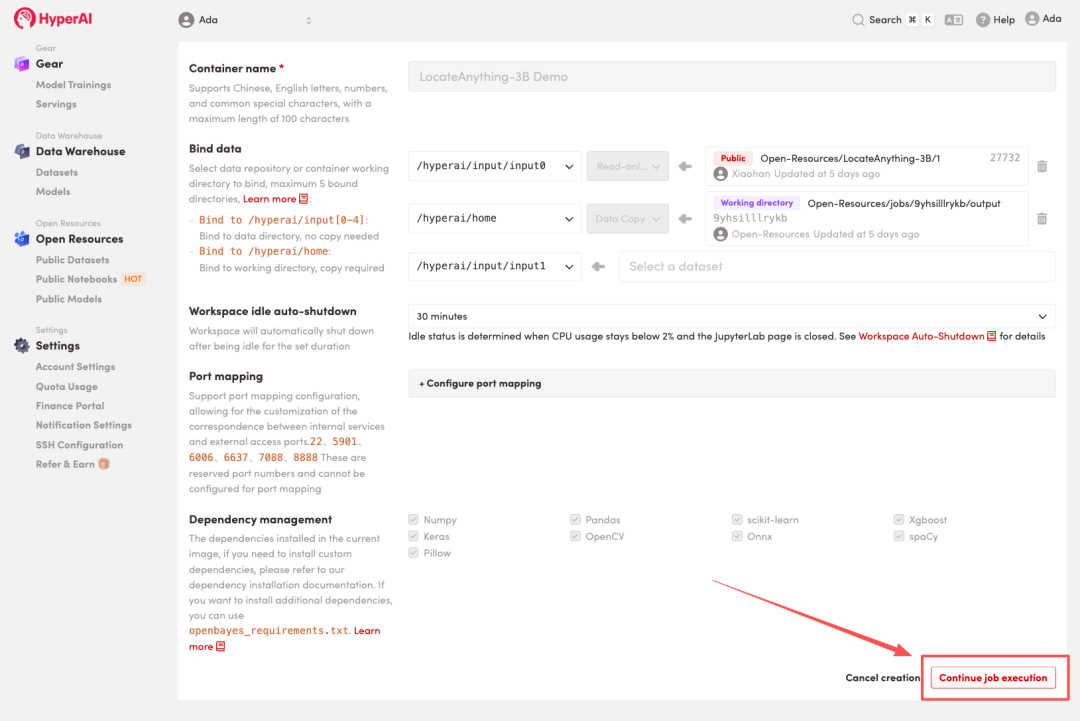
4. 리소스 할당이 완료될 때까지 기다립니다. 상태가 "실행 중"으로 변경되면 "워크스페이스 열기"를 클릭하여 Jupyter 워크스페이스에 들어갑니다.
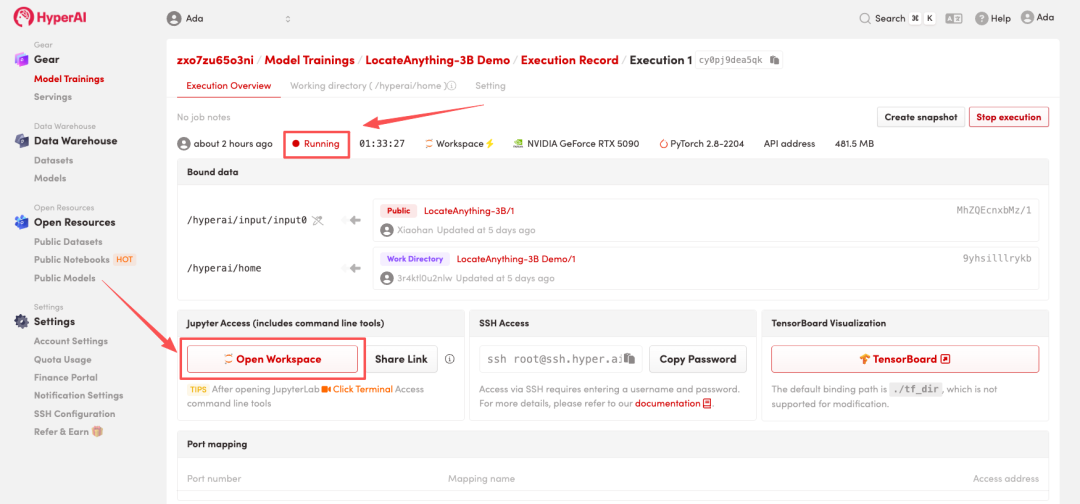
효과 표시
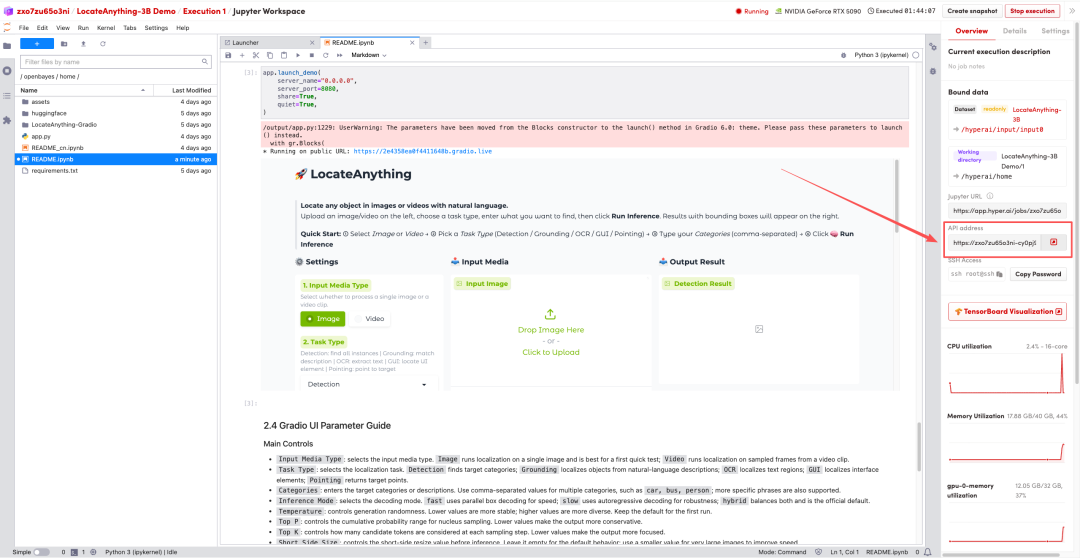
1. 페이지가 리디렉션된 후 왼쪽에 있는 README 파일을 클릭하고 상단의 실행을 클릭합니다.
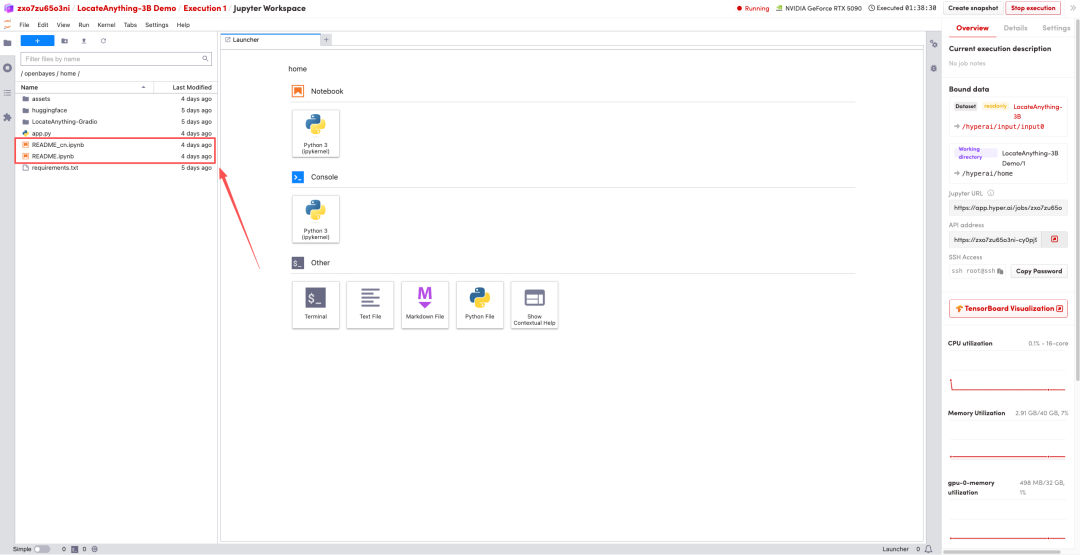
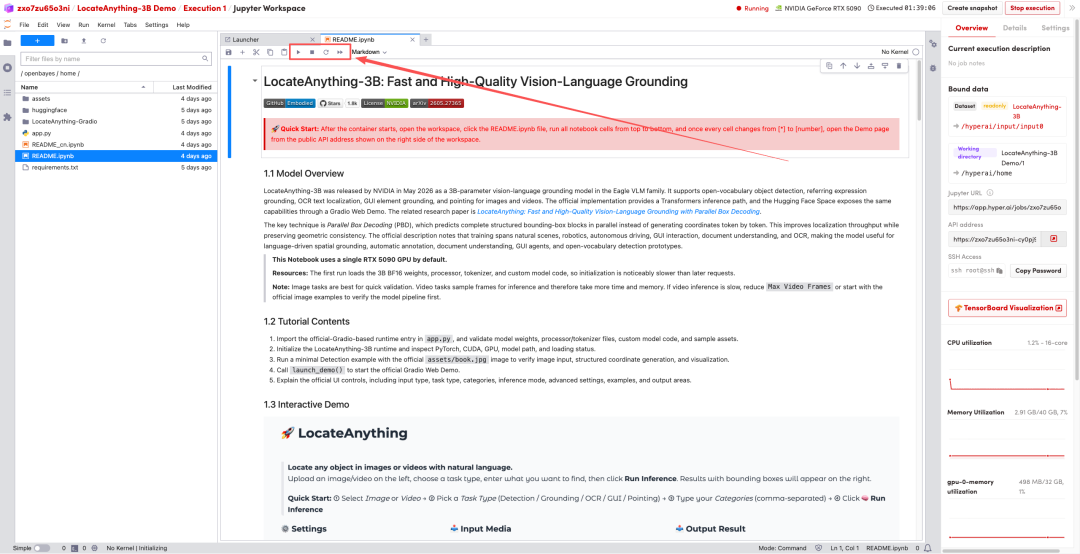
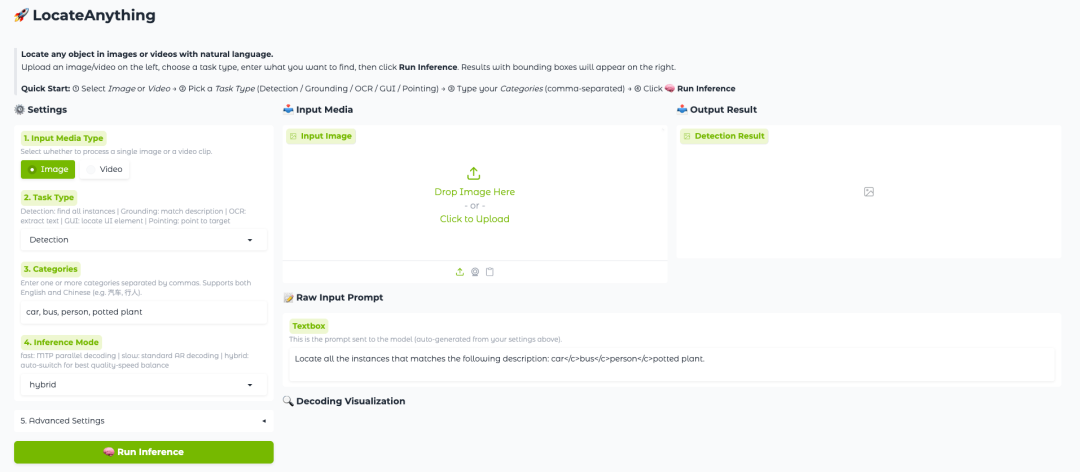
2. 과정이 완료되면 오른쪽에 있는 API 주소를 클릭하여 데모 페이지로 이동하세요.