Command Palette
Search for a command to run...
실무 경험 | HyperAI 클라우드 컴퓨팅 플랫폼 기반 요소별 연산자 최적화 실습
HyperAI 컴퓨팅 플랫폼이 공식 출시되었습니다. 이 플랫폼은 개발자들에게 매우 안정적인 컴퓨팅 서비스를 제공하고, 즉시 사용 가능한 환경, 비용 효율적인 GPU 가격, 풍부한 온사이트 리소스를 통해 아이디어 실현을 가속화합니다.
다음은 HyperAI 사용자들이 플랫폼을 기반으로 Elementwise 연산자를 최적화한 경험을 공유한 내용입니다 ⬇️
행사 관련 간단한 공지입니다!
HyperAI 베타 테스트 프로그램 참가자를 모집 중이며, 최대 $200의 인센티브가 제공됩니다. 프로그램에 대한 자세한 내용은 여기를 클릭하세요.최대 $200을 획득할 수 있습니다! HyperAI 베타 테스트 참가자 모집이 공식적으로 시작되었습니다!
핵심 목표:간단한 요소별 덧셈 연산자(C = A + B)의 기본 구현을 최적화하여 PyTorch의 기본 성능(즉, 하드웨어의 메모리 대역폭 한계)에 근접하도록 합니다.
주요 과제:요소별 연산자는 전형적인 메모리 제약 연산자입니다.
- 컴퓨팅 성능이 병목 현상의 원인은 아닙니다 (GPU는 덧셈을 매우 빠르게 수행합니다).
- 병목 현상은 "명령어 발행단"과 "비디오 메모리 전송단"의 수요와 공급 균형에 있습니다.
- 최적화의 핵심은 최소한의 명령어로 최대한 많은 데이터(바이트)를 전송하는 것입니다.
실험 환경 및 컴퓨팅 성능 준비
Elementwise 연산자의 최적화는 본질적으로 GPU 메모리 대역폭의 물리적 한계를 뛰어넘는 것입니다. 가장 정확한 벤치마크 데이터를 얻기 위해 HyperAI(hyper.ai) 클라우드 컴퓨팅 플랫폼에서 이 실습을 수행했습니다. 특히 연산자의 성능을 최대한 끌어내기 위해 고사양 인스턴스를 선택했습니다.
- GPU: NVIDIA RTX 5090 (32GB VRAM)
- 숫양: 40GB
- 환경: PyTorch 2.8 / CUDA 12.8
보너스 시간: RTX 5090을 직접 경험하고 이 글의 코드를 따라해 보고 싶으시다면, app.hyper.ai에 가입하실 때 제 특별 코드 "EARLY_dnbyl"을 입력하시면 1시간 동안 무료로 5090 컴퓨팅 파워를 이용하실 수 있습니다 (1개월 동안 유효).
RTX 5090 인스턴스를 빠르게 실행하세요
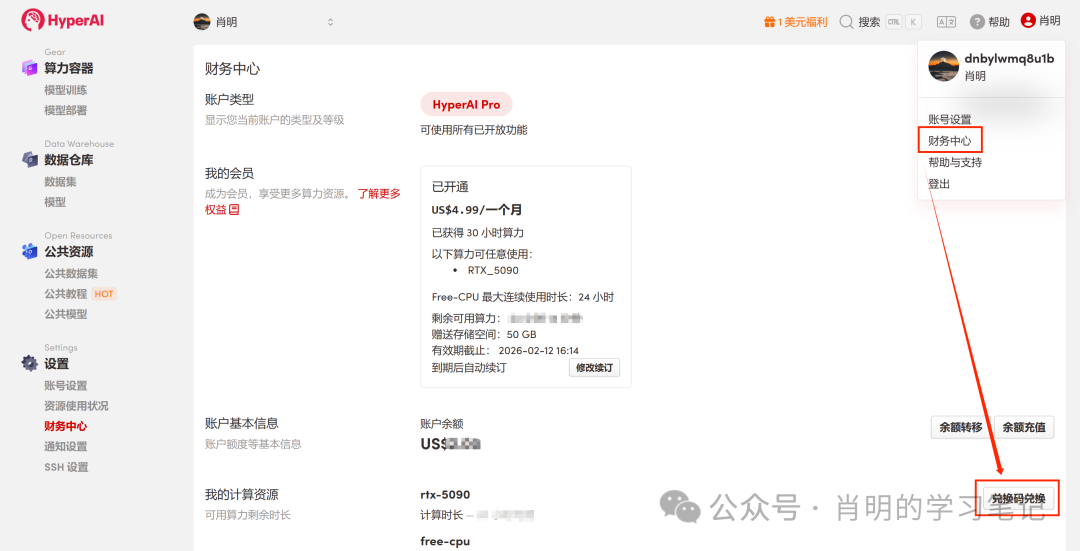
1. 회원가입 및 로그인: app.hyper.ai에서 계정을 등록한 후, 오른쪽 상단의 "금융 센터"를 클릭하고 "코드 사용"을 클릭한 다음 "EARLY_dnbyl"을 입력하여 무료 컴퓨팅 파워를 받으세요.
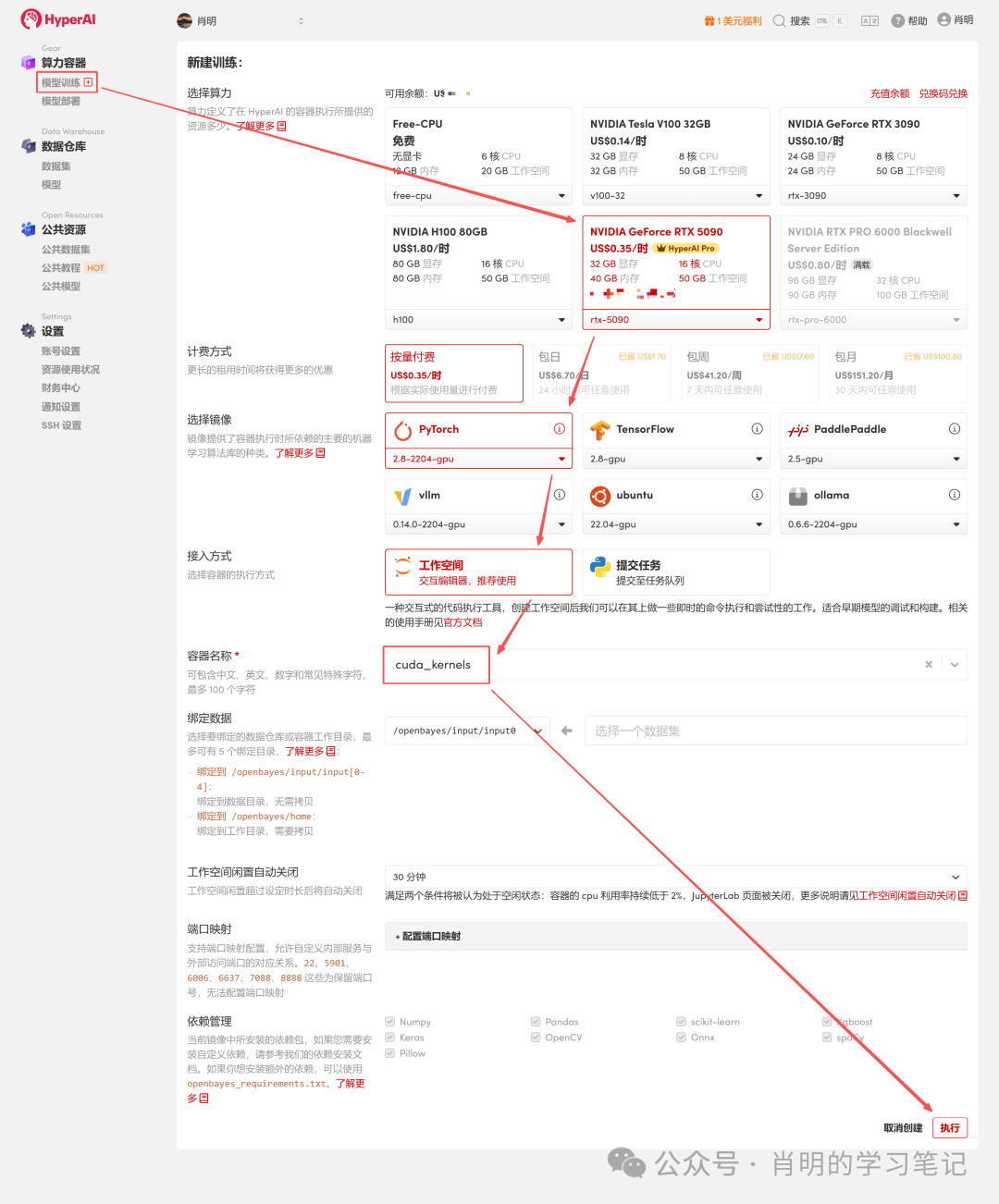
2. 컨테이너 생성: 왼쪽 사이드바에서 "모델 학습"을 클릭 -> "컴퓨팅 성능 선택: 5090" -> "이미지 선택: PyTorch 2.8" -> "접근 방식: Jupyter" -> "컨테이너 이름: cuda_kernels와 같은 아무 이름이나 입력" -> "실행"을 클릭합니다.
3. Jupyter 열기: 인스턴스가 시작되면(상태가 "실행 중"으로 변경됨) "워크스페이스 열기"를 클릭하여 바로 사용할 수 있습니다.
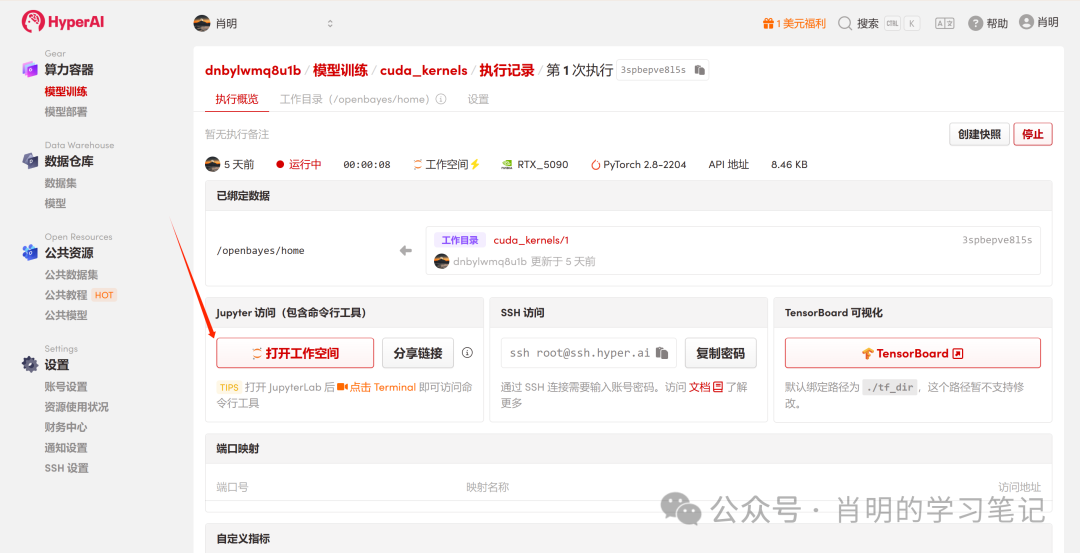
이 플랫폼은 Jupyter 또는 VS Code SSH 원격 연결을 지원합니다. 저는 Jupyter를 사용하고 있으며, 첫 번째 셀에서 다음 명령어를 실행했습니다.
import os
import torch
from torch.utils.cpp_extension import load1단계: FP32 최적화 시리즈
버전 1: FP32 기준선(스칼라 버전)
이것이 가장 직관적인 표현 방식이긴 하지만, GPU 관점에서 보면 효율성은 그다지 좋지 않습니다.
원칙에 대한 심층 분석:
- 명령 계층:스케줄러는 LD.E(32비트 로드) 명령어를 하나 실행합니다.
- 실행 계층(Warp)SIMT 원리에 따르면 워프 내의 32개 스레드 모두가 이 명령어를 동시에 실행합니다.
- 데이터 용량:각 스레드는 4바이트를 이동합니다. 총 데이터 용량 =32개 스레드 × 4바이트 = 128바이트 .
- 메모리 트랜잭션:LSU(Load Store Unit)는 이 128바이트를 하나의 비디오 메모리 트랜잭션으로 결합합니다.
- 병목 현상 분석:메모리 병합이 사용되기는 하지만 명령어 효율성은 낮습니다. 128바이트의 데이터를 이동하려면 SM(스트리밍 멀티프로세서)이 한 번의 명령어 발행 사이클을 소모해야 합니다. 대용량 데이터의 경우, 명령어 발행 장치가 과부하되어 병목 현상이 발생합니다.
코드(v1_f32.cu):
%%writefile v1_f32.cu
#include <torch/extension.h>
#include <cuda_runtime.h>
__global__ void elementwise_add_f32_kernel(float *a, float *b, float *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = a[idx] + b[idx];
}
}
void elementwise_add_f32(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256;
int blocks_per_grid = (N + threads_per_block - 1) / threads_per_block;
elementwise_add_f32_kernel<<<blocks_per_grid, threads_per_block>>>(
a.data_ptr<float>(), b.data_ptr<float>(), c.data_ptr<float>(), N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f32, "FP32 Add");
}버전 2: FP32x4 벡터화
최적화 방법: float4 타입을 사용하여 128비트 로드 명령어 생성을 강제합니다.
핵심 원칙에 대한 심층 분석 (핵심 최적화 포인트):
- 명령 계층:스케줄러는 LD.E.128(128비트 로드) 명령어를 하나 실행합니다.
- 실행 계층(Warp):워프에는 32개의 스레드가 동시에 실행되지만, 이번에는 각 스레드가 16바이트(float4)를 이동합니다.
- 데이터 용량:총 데이터 용량 = 32개 스레드 x 16바이트 = 512바이트.
- 메모리 트랜잭션:LSU는 512바이트의 연속적인 요청을 감지하면 128바이트 크기의 메모리 트랜잭션을 네 번 연속으로 시작합니다.
- 효율성 비교:기본 방식: 명령어 1개 = 128바이트. 벡터화 방식: 명령어 1개 = 512바이트.
- 결론적으로:명령어 효율이 4배 향상되었습니다. SM은 기존 명령어 수의 1/4만 사용해도 동일한 메모리 대역폭을 완벽하게 활용할 수 있습니다. 따라서 명령어 디스패치 장치의 부담이 완전히 줄어들어 병목 현상이 메모리 대역폭으로 옮겨갑니다.
코드(v2_f32x4.cu):
%%writefile v2_f32x4.cu
#include <torch/extension.h>
#include <cuda_runtime.h>
#define FLOAT4(value) (reinterpret_cast<float4 *>(&(value))[0])
__global__ void elementwise_add_f32x4_kernel(float *a, float *b, float *c, int N) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int idx = 4 * tid;
if (idx + 3 < N) {
float4 reg_a = FLOAT4(a[idx]);
float4 reg_b = FLOAT4(b[idx]);
float4 reg_c;
reg_c.x = reg_a.x + reg_b.x;
reg_c.y = reg_a.y + reg_b.y;
reg_c.z = reg_a.z + reg_b.z;
reg_c.w = reg_a.w + reg_b.w;
FLOAT4(c[idx]) = reg_c;
}
else if (idx < N){
for (int i = 0; i < 4; i++){
if (idx + i < N) {
c[idx + i] = a[idx + i] + b[idx + i];
}
}
}
}
void elementwise_add_f32x4(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256 / 4;
int blocks_per_grid = (N + 256 - 1) / 256;
elementwise_add_f32x4_kernel<<<blocks_per_grid, threads_per_block>>>(
a.data_ptr<float>(), b.data_ptr<float>(), c.data_ptr<float>(), N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f32x4, "FP32x4 Add");2단계: FP16 최적화 시리즈
3. 버전 3: FP16 기준선(반정밀도 스칼라)
비디오 메모리를 절약하기 위해 절반(FP16)을 사용하십시오.
근본 원리에 대한 심층 분석 (왜 이렇게 느린가?):
- 메모리 접근 모드:코드에서 idx는 연속적이므로 32개 스레드의 접근이 완전히 병합됩니다.
- 데이터 용량:32개 스레드 × 2바이트 = 64바이트 (하나의 워프에 대한 총 요청량).
- 하드웨어 동작:메모리 컨트롤러(LSU)는 32바이트 메모리 섹터 트랜잭션을 두 개 생성합니다. 참고: 여기서 대역폭 낭비는 없으며, 전송되는 모든 데이터는 유효합니다.
진짜 병목 현상은 다음과 같습니다.
1. 지침 바인딩:
이것이 핵심적인 이유입니다. 비디오 메모리 대역폭을 모두 채우려면 데이터를 지속적으로 이동시켜야 합니다.이 버전에서는 한 명령어로 최대 64바이트까지만 이동할 수 있습니다.float4 버전(명령어당 512바이트를 이동)과 비교하면 이 버전의 명령어 효율은 1/8에 불과합니다.
~의 결과로SM의 명령어 전달기가 최대 속도로 작동할 때조차도, 발행된 명령어가 전달하는 데이터 양은 엄청난 비디오 메모리 대역폭을 완전히 활용할 수 없습니다. 마치 작업반장이 목이 쉬도록 소리를 질러도(지시를 내려도) 작업자들이 충분한 벽돌(데이터)을 옮길 수 없는 것과 같습니다.
2. 메모리 트랜잭션의 세분성이 너무 작습니다.
* 물리 계층:비디오 메모리 전송의 최소 단위는 32바이트 섹터이며, 캐시 계층은 일반적으로 128바이트 캐시 라인 단위로 관리됩니다.
* 현상 유지:워프가 요청한 64B의 데이터는 두 개의 섹터를 채웠지만, 128B 캐시 라인의 절반만 사용했습니다.
* ~의 결과로:이러한 "소매 방식"의 소형 패킷 데이터 전송은 float4에서처럼 4개의 캐시 라인(512B) 전체를 한 번에 전송하는 "도매 방식"에 비해 처리량이 매우 낮으며, 비디오 메모리의 높은 지연 시간을 감출 수 없습니다. 비디오 메모리 대역폭을 최대한 활용하려면 데이터를 지속적으로 전송해야 합니다.
코드(v3_f16.cu):
%%writefile v3_f16.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
__global__ void elementwise_add_f16_kernel(half *a, half *b, half *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = __hadd(a[idx], b[idx]);
}
}
void elementwise_add_f16(torch::Tensor a, torch::Tensor b, torch::Tensor c) { int N = a.numel();
int threads_per_block = 256;
int blocks_per_grid = (N + threads_per_block - 1) / threads_per_block;
elementwise_add_f16_kernel<<<blocks_per_grid, threads_per_block>>>( reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16, "FP16 Add");
}4. 버전 4: FP16 벡터화(Half2)
half2를 소개합니다.
원칙에 대한 심층 분석:
- 데이터:half2(4바이트).
- 명령 계층:32비트 로드 명령을 실행합니다.
- 컴퓨팅 계층:__hadd2(SIMD)를 사용하면 단일 명령어로 두 개의 덧셈을 동시에 수행할 수 있습니다.
- 현상 유지:메모리 접근 효율은 FP32 기준선과 동일합니다.(1 명령어 = 128바이트). V3보다 빠르지만 float4의 명령어당 512바이트라는 최대치에는 아직 미치지 못합니다.
코드(v4_f16x2.cu):
%%writefile v3_f16.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
__global__ void elementwise_add_f16_kernel(half *a, half *b, half *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = __hadd(a[idx], b[idx]);
}
}
void elementwise_add_f16(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256;
int blocks_per_grid = (N + threads_per_block - 1) / threads_per_block;
elementwise_add_f16_kernel<<<blocks_per_grid, threads_per_block>>>(
reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16, "FP16 Add");
}Hyper Jupyter 실행 예시는 부록을 참조하십시오.
5. 버전 5: FP16x8 펼침(수동 루프 펼침)
성능을 더 자세히 살펴보기 위해 하나의 스레드가 8개의 절반(즉, 4개의 half2)을 처리하도록 시도했습니다.
기본 원리에 대한 심층 분석 (V4 대비 개선 사항은 무엇인가?):
- 관행:코드에 half2 읽기 작업에 대한 네 줄을 연속으로 수동으로 작성하세요.
- 효과:스케줄러는 32비트 로드 명령을 네 번 연속으로 실행합니다.
- 소득:ILP(명령 수준 병렬 처리) 및 지연 시간 마스킹. V4(FP16x2) 관련 문제점:명령어 하나를 실행하고 -> 데이터가 반환될 때까지 대기(스톨)한 후 -> 계산을 수행합니다. 대기 시간 동안 GPU는 아무 작업도 하지 않습니다. V5의 개선 사항:이 방식은 네 개의 명령어를 빠르게 연속해서 실행합니다. GPU가 메모리에서 첫 번째 데이터가 반환되기를 기다리는 동안 이미 두 번째, 세 번째, 네 번째 명령어를 실행합니다. 이는 명령어 파이프라인의 빈틈을 최대한 활용하여 값비싼 메모리 지연 시간을 감춥니다.
- 제한 사항:명령어 밀도는 여전히 매우 높습니다.ILP가 사용되었음에도 불구하고, 본질적으로는 여전히 32비트 "카트 전송"을 네 번 수행해야 했습니다. 128비트의 데이터를 이동하기 위해 SM은 여전히 네 번의 명령어 발행 사이클을 소모했습니다. 명령어 발행기는 매우 바쁜 상태를 유지하며 "한 번의 명령어로 산을 옮기는" 효과를 달성하지 못했습니다.
코드(v5_f16x8.cu):
%%writefile v5_f16x8.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
#define HALF2(value) (reinterpret_cast<half2 *>(&(value))[0])
__global__ void elementwise_add_f16x8_kernel(half *a, half *b, half *c, int N) {
int idx = 8 * (blockIdx.x * blockDim.x + threadIdx.x);
if (idx + 7 < N) {
half2 ra0 = HALF2(a[idx + 0]);
half2 ra1 = HALF2(a[idx + 2]);
half2 ra2 = HALF2(a[idx + 4]);
half2 ra3 = HALF2(a[idx + 6]);
half2 rb0 = HALF2(b[idx + 0]);
half2 rb1 = HALF2(b[idx + 2]);
half2 rb2 = HALF2(b[idx + 4]);
half2 rb3 = HALF2(b[idx + 6]);
HALF2(c[idx + 0]) = __hadd2(ra0, rb0);
HALF2(c[idx + 2]) = __hadd2(ra1, rb1);
HALF2(c[idx + 4]) = __hadd2(ra2, rb2);
HALF2(c[idx + 6]) = __hadd2(ra3, rb3);
}
else if (idx < N) {
for(int i = 0; i < 8; i++){
if (idx + i < N) {
c[idx + i] = __hadd(a[idx + i], b[idx + i]);
}
}
}
}
void elementwise_add_f16x8(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256 / 8;
int blocks_per_grid = (N + 256 - 1) / 256;
elementwise_add_f16x8_kernel<<<blocks_per_grid, threads_per_block>>>(
reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16x8, "FP16x8 Add");
}Hyper Jupyter 실행 예시는 부록을 참조하십시오.
버전 6: FP16x8 팩(최적 최적화)
이는 요소별 연산자 최적화의 한계입니다. V2의 "광대역 갭 전송"과 V5의 "명령어 수준 병렬 처리"를 결합하고 레지스터 캐싱 기술을 도입했습니다.
핵심 마법에 대한 심층 분석:
1. 주소 위조:
* 질문:저희 데이터는 half 타입인데, GPU에는 기본적으로 load_8_halfs 명령어가 없습니다.
* 대응책: float4 타입은 정확히 128비트(16바이트)를 차지하며, 8개의 절반도 128비트를 차지합니다.
* 작동하다:우리는 절반 배열의 주소를 강제로 float4*로 형변환합니다(reinterpret_cast).
* 효과:컴파일러가 `float4*`를 만나면 한 줄의 코드를 생성합니다. LD.E.128 지침. 비디오 메모리 컨트롤러는 어떤 데이터를 이동하는지 신경 쓰지 않습니다. 한 번에 128비트 바이너리 스트림만 이동합니다.
2. 배열 등록:
half pack_a[8]: 이 배열은 커널에 정의되어 있지만 크기가 고정되어 있고 매우 작기 때문에 컴파일러는 느린 로컬 메모리 대신 GPU 레지스터 파일에 직접 매핑합니다. 이는 "즉시 사용 가능한" 고속 캐시를 여는 것과 같습니다.
3. 기억의 재해석:
매크로 정의 LDST128BITS:이것이 코드의 핵심입니다. 어떤 변수의 주소든 float4* 형식으로 형변환하고 그 값을 가져옵니다.
LDST128BITS(pack_a[0])=LDST128BITS(a[idx]);
* 오른쪽:전역 메모리 a[idx]로 이동하여 128비트 데이터를 검색합니다.
* 왼쪽이 128비트 데이터를 pack_a 배열에 직접 기록합니다(0번째 요소부터 시작하여 8개 요소를 즉시 채웁니다).
* 결과:단 한 번의 명령으로 8개의 데이터 항목 전송이 즉시 완료됩니다.
코드(v6_f16x8_pack.cu):
%%writefile v6_f16x8_pack.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
#define LDST128BITS(value) (reinterpret_cast<float4 *>(&(value))[0])
#define HALF2(value) (reinterpret_cast<half2 *>(&(value))[0])
__global__ void elementwise_add_f16x8_pack_kernel(half *a, half *b, half *c, int N) {
int idx = 8 * (blockIdx.x * blockDim.x + threadIdx.x);
half pack_a[8], pack_b[8], pack_c[8];
if ((idx + 7) < N) {
LDST128BITS(pack_a[0]) = LDST128BITS(a[idx]);
LDST128BITS(pack_b[0]) = LDST128BITS(b[idx]);
#pragma unroll
for (int i = 0; i < 8; i += 2) {
HALF2(pack_c[i]) = __hadd2(HALF2(pack_a[i]), HALF2(pack_b[i]));
}
LDST128BITS(c[idx]) = LDST128BITS(pack_c[0]);
}
else if (idx < N) {
for (int i = 0; i < 8; i++) {
if (idx + i < N) {
c[idx + i] = __hadd(a[idx + i], b[idx + i]);
}
}
}
}
void elementwise_add_f16x8_pack(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256 / 8;
int blocks_per_grid = (N + 256 - 1) / 256;
elementwise_add_f16x8_pack_kernel<<<blocks_per_grid, threads_per_block>>>(
reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16x8_pack, "FP16x8 Pack Add");
}3단계: 벤치마크와 시각적 분석 결합
최적화 효과를 종합적으로 평가하기 위해 지연 시간에 민감한 시나리오(소규모 데이터)부터 대역폭에 민감한 시나리오(대규모 데이터)까지 포괄하는 전체 시나리오 테스트 계획을 설계했습니다.
1. 테스트 전략 설계
GPU 메모리 수준에서 서로 다른 병목 현상에 해당하는 세 가지 대표적인 데이터 세트를 선정했습니다.
- 캐시 지연 시간(100만 개 요소):데이터 크기가 매우 작고(4MB), L2 캐시가 완전히 활용되고 있습니다.이 테스트의 핵심은 커널 실행 오버헤드와 명령 실행 효율성입니다.
- L2 처리량(1600만 요소):데이터 크기는 적당한 수준(64MB)으로, L2 캐시 용량 한계에 근접합니다.이 테스트의 핵심은 L2 캐시의 읽기 및 쓰기 처리량입니다.
- VRAM 대역폭(256M 요소):데이터 용량이 엄청나게 커서(1GB) L2 캐시 용량을 훨씬 초과합니다. 따라서 비디오 메모리(VRAM)에서 데이터를 옮겨야 합니다.이것이 바로 대규모 운영업체들의 진정한 격전지이며, 핵심적인 시험대는 물리적 메모리 대역폭을 최대한 활용하는지 여부에 달려 있습니다.
2. 벤치마크 스크립트(파이썬)
이 스크립트는 위에 정의된 .cu 파일을 직접 불러와 대역폭(GB/s)과 시간(ms)을 자동으로 계산합니다.
import torch
from torch.utils.cpp_extension import load
import time
import os
# ==========================================
# 0. 准备工作
# ==========================================
# 确保你的文件路径和笔记里写的一致
kernel_dir = "."
flags = ["-O3", "--use_fast_math", "-U__CUDA_NO_HALF_OPERATORS__"]
print(f"Loading kernels from {kernel_dir}...")
# ==========================================
# 1. 分别加载 6 个模块
# ==========================================
# 我们分别编译加载,确保每个模块有独立的命名空间,避免符号冲突
try:
mod_v1 = load(name="v1_lib", sources=[os.path.join(kernel_dir, "v1_f32.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v2 = load(name="v2_lib", sources=[os.path.join(kernel_dir, "v2_f32x4.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v3 = load(name="v3_lib", sources=[os.path.join(kernel_dir, "v3_f16.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v4 = load(name="v4_lib", sources=[os.path.join(kernel_dir, "v4_f16x2.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v5 = load(name="v5_lib", sources=[os.path.join(kernel_dir, "v5_f16x8.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v6 = load(name="v6_lib", sources=[os.path.join(kernel_dir, "v6_f16x8_pack.cu")], extra_cuda_cflags=flags, verbose=False)
print("All Kernels Loaded Successfully!\n")
except Exception as e:
print("\n[Error] 加载失败!请检查目录下是否有这 6 个 .cu 文件,且代码已修正语法错误。")
print(f"详细报错: {e}")
raise e
# ==========================================
# 2. Benchmark 工具函数
# ==========================================
def run_benchmark(func, a, b, tag, out, warmup=10, iters=1000):
# 重置输出
out.fill_(0)
# Warmup (预热,让 GPU 进入高性能状态)
for _ in range(warmup):
func(a, b, out)
torch.cuda.synchronize()
# Timing (计时)
start = time.time()
for _ in range(iters):
func(a, b, out)
torch.cuda.synchronize()
end = time.time()
# Metrics (指标计算)
avg_time_ms = (end - start) * 1000 / iters
# Bandwidth Calculation: (Read A + Read B + Write C)
element_size = a.element_size() # float=4, half=2
total_bytes = 3 * a.numel() * element_size
bandwidth_gbs = total_bytes / (avg_time_ms / 1000) / 1e9
# Check Result (打印前 2 个元素用于验证正确性)
# 取数据回 CPU 检查
out_val = out.flatten()[:2].cpu().float().tolist()
out_val = [round(v, 4) for v in out_val]
print(f"{tag:<20} | Time: {avg_time_ms:.4f} ms | BW: {bandwidth_gbs:>7.1f} GB/s | Check: {out_val}")
# ==========================================
# 3. 运行测试 (从小到大)
# ==========================================
# 1M = 2^20
shapes = [
(1024, 1024), # 1M elems (Cache Latency)
(4096, 4096), # 16M elems (L2 Cache 吞吐)
(16384, 16384), # 256M elems (显存带宽压测)
]
print(f"{'='*90}")
print(f"Running Benchmark on {torch.cuda.get_device_name(0)}")
print(f"{'='*90}\n")
for S, K in shapes:
N = S * K
print(f"--- Data Size: {N/1e6:.1f} M Elements ({N*4/1024/1024:.0f} MB FP32) ---")
# --- FP32 测试 ---
a_f32 = torch.randn((S, K), device="cuda", dtype=torch.float32)
b_f32 = torch.randn((S, K), device="cuda", dtype=torch.float32)
c_f32 = torch.empty_like(a_f32)
# 注意:这里调用的是 .add 方法,因为你在 PYBIND11 里面定义的名字是 "add"
run_benchmark(mod_v1.add, a_f32, b_f32, "V1 (FP32 Base)", c_f32)
run_benchmark(mod_v2.add, a_f32, b_f32, "V2 (FP32 Vec)", c_f32)
# PyTorch 原生对照
run_benchmark(lambda a,b,c: torch.add(a,b,out=c), a_f32, b_f32, "PyTorch (FP32)", c_f32)
# --- FP16 测试 ---
print("-" * 60)
a_f16 = a_f32.half()
b_f16 = b_f32.half()
c_f16 = c_f32.half()
run_benchmark(mod_v3.add, a_f16, b_f16, "V3 (FP16 Base)", c_f16)
run_benchmark(mod_v4.add, a_f16, b_f16, "V4 (FP16 Half2)", c_f16)
run_benchmark(mod_v5.add, a_f16, b_f16, "V5 (FP16 Unroll)", c_f16)
run_benchmark(mod_v6.add, a_f16, b_f16, "V6 (FP16 Pack)", c_f16)
# PyTorch 原生对照
run_benchmark(lambda a,b,c: torch.add(a,b,out=c), a_f16, b_f16, "PyTorch (FP16)", c_f16)
print("\n")
3. 실제 데이터: RTX 5090 성능
다음은 NVIDIA GeForce RTX 5090에서 위 코드를 실행하여 얻은 실제 데이터입니다.
==========================================================================================
Running Benchmark on NVIDIA GeForce RTX 5090
==========================================================================================---
Data Size: 1.0 M Elements (4 MB FP32) ---
V1 (FP32 Base) | Time: 0.0041 ms | BW: 3063.1 GB/s | Check: [0.8656, 1.9516]
V2 (FP32 Vec) | Time: 0.0041 ms | BW: 3066.1 GB/s | Check: [0.8656, 1.9516]
PyTorch (FP32) | Time: 0.0044 ms | BW: 2868.9 GB/s | Check: [0.8656, 1.9516]
------------------------------------------------------------
V3 (FP16 Base) | Time: 0.0041 ms | BW: 1531.9 GB/s | Check: [0.8657, 1.9512]
V4 (FP16 Half2) | Time: 0.0041 ms | BW: 1531.9 GB/s | Check: [0.8657, 1.9512]
V5 (FP16 Unroll) | Time: 0.0041 ms | BW: 1533.5 GB/s | Check: [0.8657, 1.9512]
V6 (FP16 Pack) | Time: 0.0041 ms | BW: 1533.6 GB/s | Check: [0.8657, 1.9512]
PyTorch (FP16) | Time: 0.0044 ms | BW: 1431.6 GB/s | Check: [0.8657, 1.9512]
--- Data Size: 16.8 M Elements (64 MB FP32) ---
V1 (FP32 Base) | Time: 0.1183 ms | BW: 1702.2 GB/s | Check: [-3.2359, -0.1663]
V2 (FP32 Vec) | Time: 0.1186 ms | BW: 1698.1 GB/s | Check: [-3.2359, -0.1663]
PyTorch (FP32) | Time: 0.1176 ms | BW: 1711.8 GB/s | Check: [-3.2359, -0.1663]
------------------------------------------------------------
V3 (FP16 Base) | Time: 0.0348 ms | BW: 2891.3 GB/s | Check: [-3.2363, -0.1664]
V4 (FP16 Half2) | Time: 0.0348 ms | BW: 2891.3 GB/s | Check: [-3.2363, -0.1664]
V5 (FP16 Unroll) | Time: 0.0348 ms | BW: 2892.8 GB/s | Check: [-3.2363, -0.1664]
V6 (FP16 Pack) | Time: 0.0348 ms | BW: 2892.6 GB/s | Check: [-3.2363, -0.1664]
PyTorch (FP16) | Time: 0.0148 ms | BW: 6815.7 GB/s | Check: [-3.2363, -0.1664]
--- Data Size: 268.4 M Elements (1024 MB FP32) ---
V1 (FP32 Base) | Time: 2.0432 ms | BW: 1576.5 GB/s | Check: [0.4839, -2.6795]
V2 (FP32 Vec) | Time: 2.0450 ms | BW: 1575.2 GB/s | Check: [0.4839, -2.6795]
PyTorch (FP32) | Time: 2.0462 ms | BW: 1574.3 GB/s | Check: [0.4839, -2.6795]
------------------------------------------------------------
V3 (FP16 Base) | Time: 1.0173 ms | BW: 1583.2 GB/s | Check: [0.4839, -2.6797]
V4 (FP16 Half2) | Time: 1.0249 ms | BW: 1571.5 GB/s | Check: [0.4839, -2.6797]
V5 (FP16 Unroll) | Time: 1.0235 ms | BW: 1573.6 GB/s | Check: [0.4839, -2.6797]
V6 (FP16 Pack) | Time: 1.0236 ms | BW: 1573.4 GB/s | Check: [0.4839, -2.6797]
PyTorch (FP16) | Time: 1.0251 ms | BW: 1571.2 GB/s | Check: [0.4839, -2.6797]
4. 데이터 해석
이 데이터는 다양한 부하 조건에서 RTX 5090의 물리적 특성을 명확하게 보여줍니다.
1단계: 매우 작은 규모 (100만 개 요소 / 4MB)
- 현상:모든 버전에서 실행 시간이 0.0041ms로 놀랍도록 일관적이었습니다.
- 진실:이는 지연 시간에 따라 결과가 달라지는 상황입니다. 데이터 크기에 관계없이 GPU가 커널을 시작하는 데 필요한 고정된 실행 오버헤드는 약 4마이크로초입니다. 이러한 시간 제약 때문에 FP16의 데이터 용량은 FP32의 절반에 불과하므로 계산된 대역폭도 자연스럽게 절반이 됩니다. 여기서 측정하는 것은 전송 속도가 아니라 "실행 속도"입니다.
2단계: 중간 크기 (1600만 요소 / 64MB 대 32MB)
이 영역은 L2 캐시의 기능을 가장 잘 보여주는 곳입니다.
- FP32(64MB):총 데이터 용량 A+B+C는 약 192MB입니다. 이는 RTX 5090의 L2 캐시 용량(약 128MB)을 초과합니다. 데이터 오버플로로 인해 시스템은 VRAM에서 읽고 쓰기 작업을 수행해야 했고, 이로 인해 대역폭이 1700GB/s(비디오 메모리의 물리적 대역폭에 근접)까지 떨어졌습니다.
- FP16 (32MB):총 데이터 용량.L2 캐시에 딱 맞네요! 데이터가 캐시 내에서 순환하면서 대역폭이 2890GB/s까지 급증합니다.
- PyTorch의 어둠의 마법:PyTorch는 FP16에서 6815GB/s의 성능을 달성했습니다. 이는 순수 캐시 환경에서 JIT 컴파일러의 명령어 파이프라인 최적화가 간단한 수동 커널보다 여전히 우수함을 보여줍니다.
3단계: 대규모 (2억 6,800만 개 요소 / 1024MB)
이는 대규모 모델(메모리 제약)을 사용한 학습/추론에 대한 실제 시나리오입니다.
- 모든 존재는 평등하다.FP32든 FP16이든, 기본 모드든 최적화 모드든 대역폭은 모두 1570~1580GB/s로 고정됩니다.
- 물리적 벽:RTX 5090의 GDDR7 메모리 대역폭이 물리적 한계에 도달했습니다. 대역폭은 제한되어 있으며, 더 이상 늘릴 수 없습니다.
- 최적화의 가치:대역폭은 동일하게 유지되었지만.하지만 FP16의 소요 시간(1.02ms)은 FP32의 소요 시간(2.04ms)의 절반에 불과한 것으로 나타났습니다.데이터 용량을 절반으로 줄이면서 대역폭을 최대화함으로써 종단 간 속도가 두 배 향상됩니다. V6 vs V3V3 버전이 최대 성능으로 실행되는 것처럼 보이는 것은 NVCC 컴파일러의 자동 최적화와 GPU 하드웨어 지연 시간 마스킹 때문입니다. 하지만 FlashAttention과 같은 더욱 복잡한 연산자에서는 V6 구현이 성능을 보장합니다.
핵심 FAQ: 파라미터 설계의 심층 도출
이 실험의 모든 커널에서 우리는 threads_per_block = 256이라는 매개변수를 만장일치로 설정했습니다. 이 숫자는 임의로 선택된 것이 아니라 하드웨어 제약과 스케줄링 효율성 사이에서 수학적으로 최적의 해를 찾은 것입니다.
Q: threads_per_block이 항상 128 또는 256으로 설정되는 이유는 무엇입니까?
A: 이것은 4단계 선별 과정을 거쳐 얻은 "황금 범위"입니다.
우리는 block_size 선택 과정을 깔때기로 보고, 층별로 필터링하는 방식을 택합니다.
1. 워프 정렬 -> 32의 배수여야 합니다.
GPU에서 가장 작은 실행 단위는 워프(스레드 묶음)이며, 이는 32개의 연속된 스레드로 구성됩니다(SIMT 아키텍처, 단일 명령어 멀티스레딩).
- 엄격한 제한 사항:31개의 스레드를 요청하더라도 하드웨어는 여전히 하나의 완전한 워프를 스케줄링합니다. 나머지 스레드 위치는 유휴 상태이지만, 동일한 하드웨어 리소스를 계속 차지합니다.
- 결론적으로: 블록 크기는 컴퓨팅 성능 낭비를 방지하기 위해 이상적으로는 32의 배수여야 합니다.
2. 점유층 -> 96층 이상이어야 함
점유율 = SM에서 현재 실행 중인 동시 스레드 수 / SM에서 지원하는 최대 스레드 수.
- 배경:메모리 지연 시간을 숨기려면 충분한 수의 활성 워프가 필요합니다. 블록 크기가 너무 작으면 SM의 "최대 블록" 제한에 "최대 스레드" 제한보다 먼저 도달하게 됩니다.
- 견적:튜링/암페어/에이다와 같은 주류 아키텍처는 일반적으로 `block_size > (SM의 최대 스레드 수 / SM의 최대 블록 수)` 조건을 요구합니다. 일반적인 비율은 64 또는 96입니다.
- 결론적으로:이론적으로 100%의 점유율을 달성하려면 블록 크기는 96 이상이어야 합니다.
3. 스케줄링 원자성 -> 락킹 128, 256, 512
블록은 SM(소프트웨어 마스터)에 스케줄링되는 가장 작은 원자 단위입니다. SM은 정수 개의 블록을 완전히 소비할 수 있어야 합니다.
- 정제:SM의 용량 낭비를 방지하려면 block_size는 이상적으로 SM의 최대 스레드 용량으로 나누어 떨어져야 합니다.
- 필터:주류 아키텍처 SM의 최대 용량은 일반적으로 1024, 1536, 2048 등입니다. 이들의 공약수는 보통 512입니다. 이전 두 단계(>=96 및 32의 배수)를 결합하면 후보 목록은 128, 192, 256, 384, 512로 좁혀집니다.
4. 압력 등록 -> 512+ 제외
이것이 최종적인 "한계"입니다.
- 엄격한 제한 사항:각 블록에 사용할 수 있는 레지스터의 총 개수는 제한되어 있습니다(SM의 전체 레지스터 수는 일반적으로 64K 32비트입니다).
- 위험:block_size가 크고(예: 512), 커널이 약간 더 복잡하면(각 스레드가 여러 레지스터를 사용하는 경우), 512 * 스레드당 레지스터 수 > 블록당 최대 레지스터 수라는 상황이 발생합니다.
- 그 결과로:시작 실패: 직접적인 오류 메시지. 레지스터 오버플로: 레지스터가 속도가 느린 로컬 메모리로 넘쳐 성능 저하를 초래합니다.
- 결론적으로:안전상의 이유로, 저희는 일반적으로 512 또는 1024의 사용을 지양합니다. 128번과 256번 도로는 가장 안전한 "사막 지역"입니다.
요약하다
네 번의 탈락 과정을 거친 후, 단 두 명의 참가자만 남았습니다.
- 128이 제품은 최고의 활용성을 자랑합니다.복잡한 커널(많은 레지스터를 사용하는)을 사용하더라도 성공적인 시작과 높은 사용률을 보장할 수 있습니다.
- 256:요소별 연산자 선호요소별 연산과 같이 논리적으로 간단한 연산자의 경우 레지스터 부하가 최소화됩니다. 256은 128보다 메모리 병합 가능성이 더 높고 블록 스케줄링 오버헤드를 줄입니다.
이는 단순한 구현에서 threads_per_block = 256으로 결정되면 grid_size도 결정되는 이유(총량이 N을 포함하는 한)를 설명합니다.
부록: Jupyter 실행 예제









