Command Palette
Search for a command to run...
AI 논문 주간 보고서 | 구조적 희소성, 메모리 메커니즘 및 추론 조직화 분야의 최신 발전을 분석하는 최첨단 Transformer 연구에 대한 특별 보고서입니다.

지난 8년 동안 트랜스포머는 인공지능 연구의 지형을 거의 완전히 바꿔놓았습니다. 구글이 2017년 "어텐션이 전부다(Attention Is All You Need)"에서 이 아키텍처를 제안한 이후, "어텐션 메커니즘"은 엔지니어링 기법에서 점차 딥러닝의 일반적인 패러다임으로 발전해 왔습니다. 자연어 처리부터 컴퓨터 비전, 음성 및 멀티모달 컴퓨팅, 과학 컴퓨팅에 이르기까지, 트랜스포머는 사실상 기본 모델 프레임워크로 자리 잡고 있습니다.
구글, 오픈AI, 메타, 마이크로소프트와 같은 업계 주요 기업들은 규모와 엔지니어링의 한계를 끊임없이 확장하고 있으며, 스탠포드, MIT, 버클리와 같은 대학들은 이론적 분석, 구조적 개선, 새로운 패러다임 탐구 분야에서 꾸준히 중요한 연구 성과를 내고 있습니다. 모델 규모, 훈련 패러다임, 응용 범위가 지속적으로 확장됨에 따라 트랜스포머 분야 연구 또한 고도의 차별화와 빠른 진화를 보이고 있어, 대표적인 논문들을 체계적으로 검토하고 선정하는 것이 특히 중요합니다.
더 많은 사용자에게 학계 인공지능 분야의 최신 동향을 알리기 위해 HyperAI 공식 웹사이트(hyper.ai)에 "최신 논문" 섹션이 개설되었습니다. 이 섹션에서는 매일 최첨단 AI 연구 논문을 업데이트합니다.
* 최신 AI 논문:https://go.hyper.ai/hzChC이번 주에는 트랜스포머 관련 인기 논문 5편을 엄선하여 소개해 드립니다.베이징대학교, DeepSeek, ByteDance Seed, Meta AI 등 여러 팀이 참여합니다. 함께 배워봐요! ⬇️
이번 주 논문 추천
- 확장 가능한 조회를 통한 조건부 메모리: 대규모 언어 모델을 위한 새로운 희소성 축
베이징대학교와 DeepSeek-AI의 연구진은 O(1) 조회 복잡도를 갖는 확장 가능한 조건부 메모리 모듈인 Engram을 제안했습니다. 정적 지식 검색 Transformer의 초기 레이어에서 Engram을 추출하고 MoE와 함께 사용함으로써 초기 레이어를 더 깊은 추론 계산에 활용할 수 있게 되었습니다. 이를 통해 추론 작업(BBH +5.0, ARC-Challenge +3.7), 코드 및 수학 작업(HumanEval +3.0, MATH +2.4), 그리고 긴 컨텍스트 작업(Multi-Query NIAH: 84.2 → 97.0)에서 상당한 성능 향상을 달성했으며, 매개변수 개수와 FLOPs는 동일하게 유지되었습니다.
논문 및 상세 해석:https://go.hyper.ai/SlcId
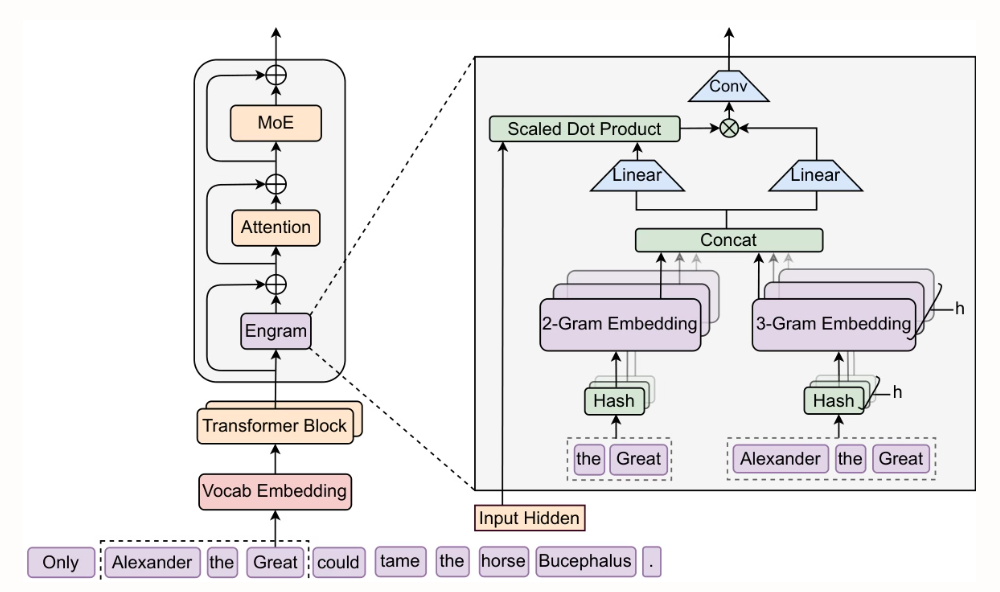
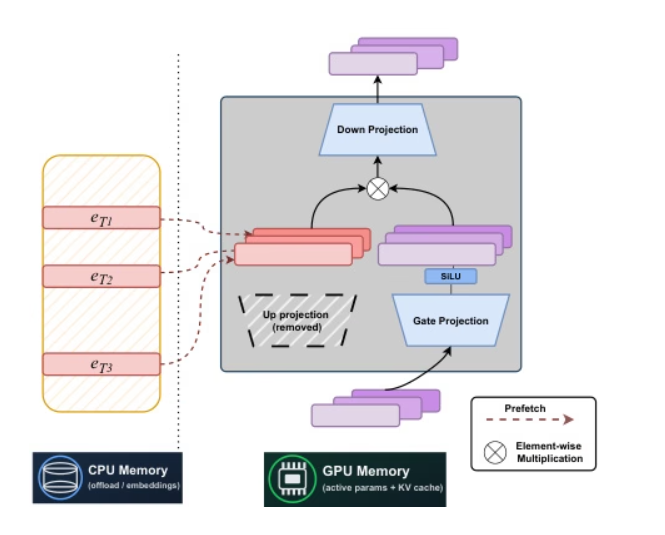
2. STEM: 임베디드 모듈을 활용한 트랜스포머 확장
카네기멜론 대학교와 Meta AI의 연구진은 정적 레이블 인덱스 기반 희소 아키텍처인 STEM을 공동으로 제안했습니다. FFN의 업프로젝션을 레이어 내 임베딩 조회로 대체함으로써 안정적인 학습이 가능하며, 레이블별 FLOPs와 파라미터 접근 횟수를 약 3분의 1로 줄이고, 확장 가능한 파라미터 활성화를 통해 장문 컨텍스트 성능을 향상시켰습니다. STEM은 용량과 연산 및 통신을 분리하여 CPU 오프로딩을 위한 비동기 프리페칭을 지원하고, 넓은 각도 분포를 가진 임베딩을 활용하여 더 높은 지식 저장 용량을 달성하며, 입력 텍스트를 수정하지 않고도 해석 및 편집 가능한 지식 주입을 가능하게 합니다. 지식 및 추론 벤치마크에서 STEM은 밀집형 기준선 대비 최대 약 3~41 TP3T의 성능 향상을 달성했습니다.
논문 및 상세 해석:https://go.hyper.ai/NPuoj
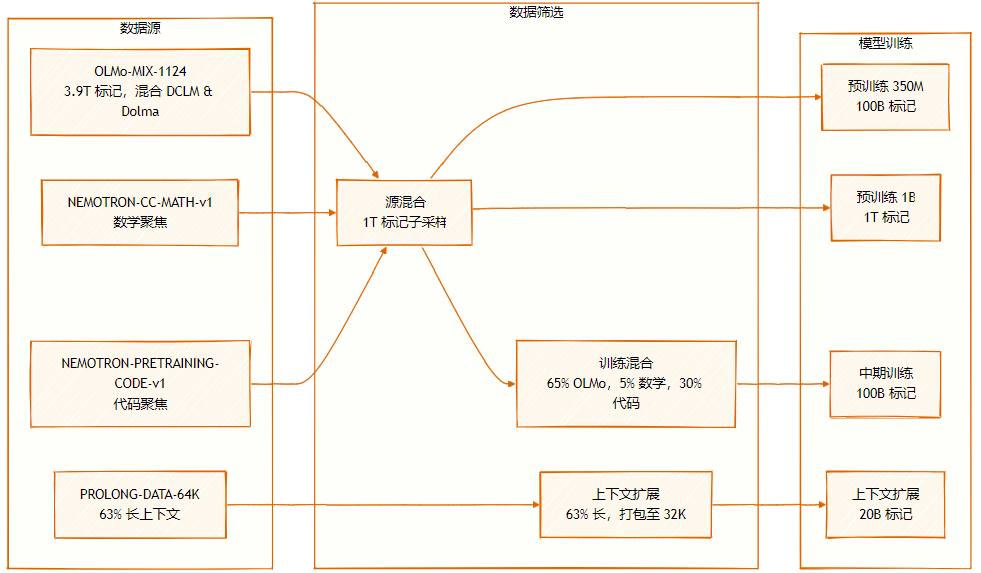
이 데이터셋은 OLMo-MIX-1124(3.9T 레이블링됨, DCLM과 Dolma1.7의 혼합), NEMOTRON-CC-MATH-v1(수학 중심), NEMOTRON-PRETRAINING-CODE-v1(코드 중심) 등 여러 소스로 구성됩니다.
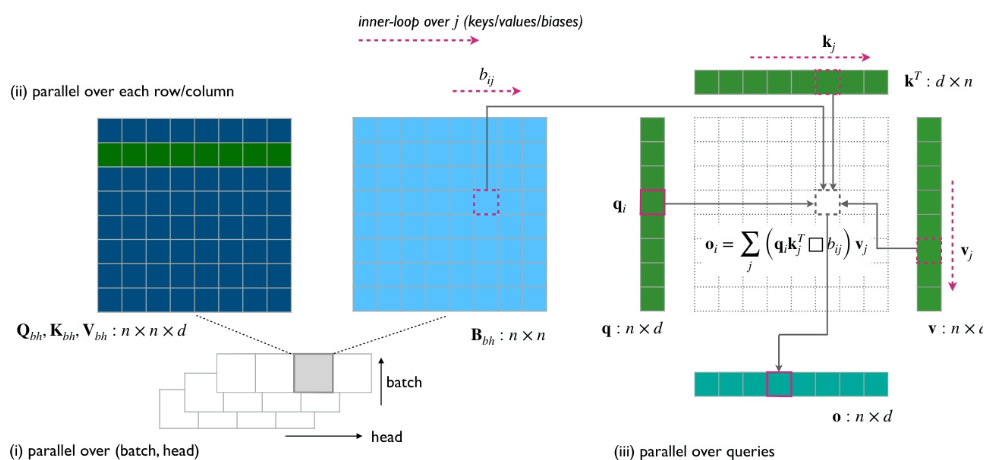
3. SeedFold: 생체 분자 구조 예측의 확장성 향상
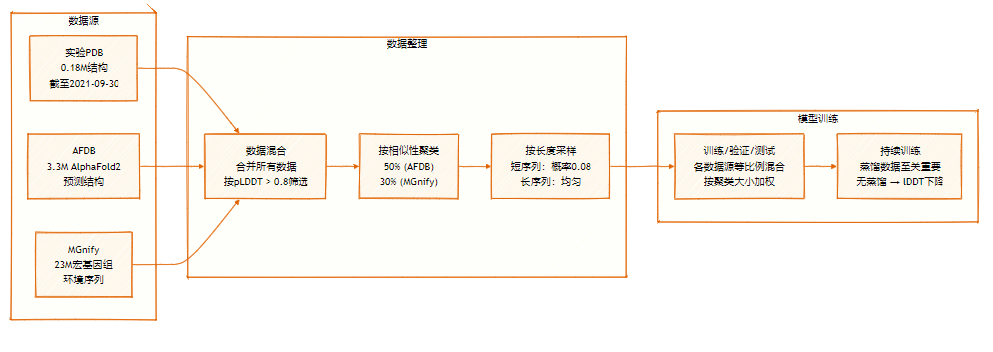
바이트댄스의 Seed 팀은 확장 가능한 생체 분자 구조 예측 모델인 SeedFold를 제안했습니다. SeedFold는 Pairformer의 폭을 넓혀 모델 용량을 증가시키고, 선형 삼각형 어텐션 메커니즘을 사용하여 계산 복잡성을 줄이며, 2,650만 개의 샘플이 포함된 증류 데이터셋을 사용하여 FoldBench에서 최첨단 성능을 달성하는 동시에 단백질 관련 작업에서 AlphaFold3를 능가합니다.
논문 및 상세 해석:https://go.hyper.ai/9zAID
SeedFold 데이터 세트는 2,650만 개의 샘플을 포함하고 있으며, 두 가지 주요 소스(실험 데이터 세트(0.18백만 개)와 AFDB 및 MGnify에서 가져온 정제된 데이터 세트)에서 대규모 데이터 정제를 통해 확장되었습니다.
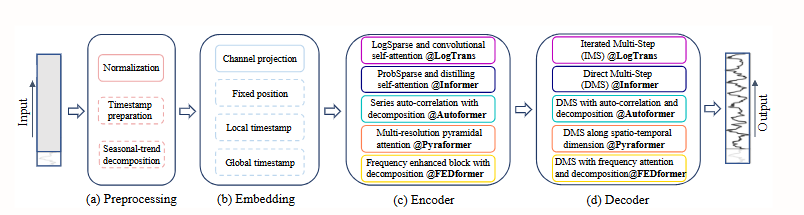
4. 트랜스포머는 시계열 예측에 효과적인가?
본 논문은 시계열 예측 분야에서 트랜스포머(Transformer) 모델의 인기가 급증하고 있음에도 불구하고, 자체 어텐션 메커니즘의 순열 불변성으로 인해 중요한 시간적 정보가 손실된다는 점을 밝혀냈습니다. 비교 실험을 통해, 단순한 단일 레이어 선형 모델이 여러 실제 데이터셋에서 복잡한 트랜스포머 모델보다 훨씬 우수한 성능을 보였습니다. 이러한 결과는 기존 연구 방향에 의문을 제기하며, 시계열 예측 작업에서 트랜스포머 모델의 효과성에 대한 재평가를 촉구합니다.
논문 및 상세 해석:https://go.hyper.ai/Hk05h
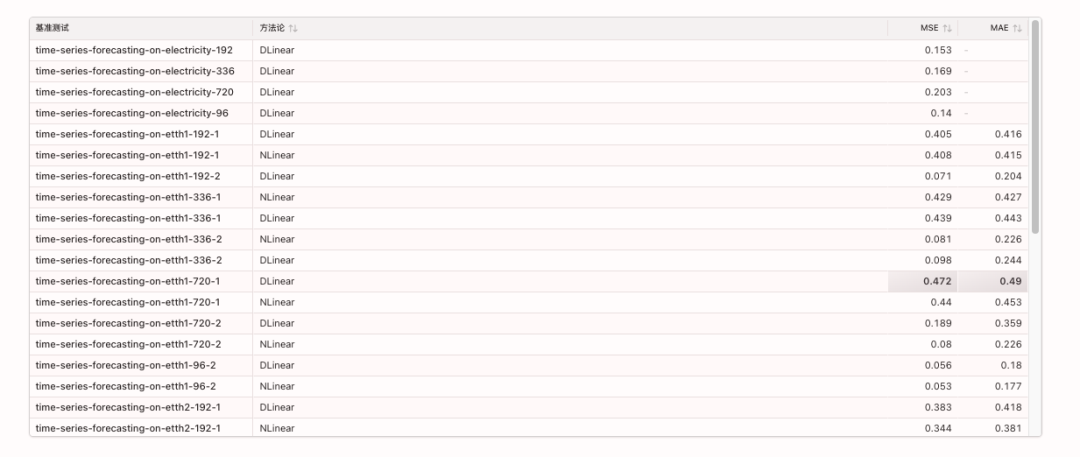
관련 벤치마크는 다음과 같습니다.
5. 추론 모델은 사고의 사회를 만들어낸다
구글, 시카고 대학교, 산타페 연구소의 연구진은 DeepSeek-R1과 QwQ-32B 같은 고급 추론 모델의 뛰어난 성능이 단순히 사고 과정이 길기 때문이 아니라, 모델 내에서 다양한 관점과 성격, 전문성을 가진 주체들이 서로 대화하는 다중 에이전트와 같은 "사고의 사회"를 암묵적으로 시뮬레이션하기 때문이라고 주장합니다. 이들은 기계론적 해석 가능성과 제어된 강화 학습을 통해, 질문, 갈등, 화해와 같은 대화 행동과 관점의 다양성 사이에 정확도 측면에서 인과 관계가 있음을 보여주었으며, "놀라움"이라는 발화 마커를 활용하면 추론 성능이 두 배로 향상된다는 것을 밝혀냈습니다. 이러한 사고의 사회적 조직화는 해법 공간에 대한 체계적인 탐색을 가능하게 하며, 집단 지능의 원칙인 다양성, 토론, 역할 조정이 효과적인 인공 추론의 핵심 기반임을 시사합니다.
논문 및 상세 해석:https://go.hyper.ai/0oXCC
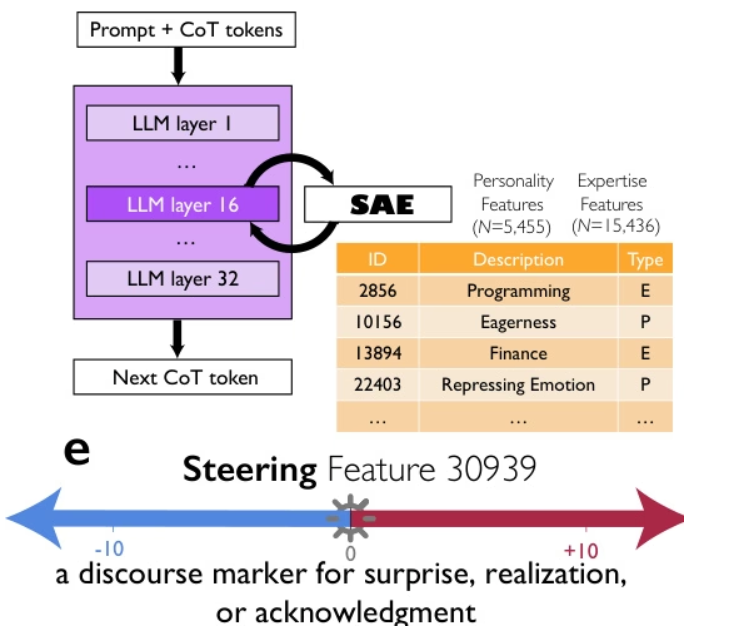
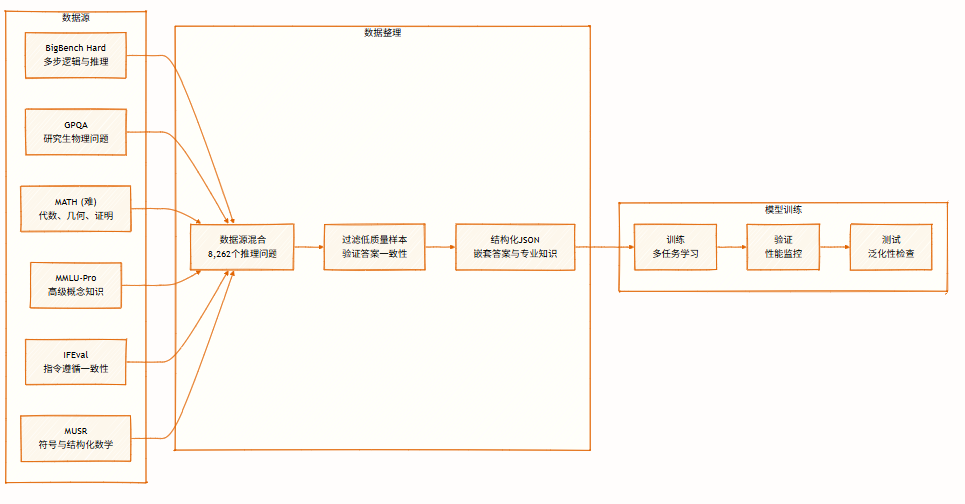
이 데이터셋은 기호 논리, 수학적 문제 해결, 과학적 추론, 지시 따르기, 다중 에이전트 추론 등 다양한 영역을 포괄하는 8,262개의 추론 문제를 포함합니다. 다중 관점 추론을 지원하며 모델 학습 및 평가에 사용됩니다.
이번 주 논문 추천 내용은 여기까지입니다. 더 많은 최첨단 AI 연구 논문을 보시려면 hyper.ai 공식 웹사이트의 "최신 논문" 섹션을 방문하세요.
또한, 연구팀의 고품질 연구 결과와 논문 제출을 환영합니다. 관심 있는 분은 NeuroStar WeChat(WeChat ID: Hyperai01)을 추가해 주세요.
다음주에 뵙겠습니다!








