Command Palette
Search for a command to run...
데이터셋 모음 | NVIDIA, OpenAI 및 여러 연구 기관에서 제공하는 오픈 소스 추론 데이터셋을 포함하며, 수학, 파노라마 공간, 위키 질문 답변, 연구 과제, 시각적 상식 등을 다룹니다.

대규모 모델이 단순히 "말하고 쓸 수 있는 능력"에서 "추론하고 생각할 수 있는 능력"으로 발전함에 따라 데이터의 중요성이 재정의되고 있습니다.
과거에는 방대한 범용 코퍼스가 언어 모델의 표현력을 뒷받침했지만, 오늘날 모델의 한계를 결정하는 진정한 관건은 명확한 구조, 엄격한 논리, 그리고 다단계 추론 과정을 갖춘 추론 데이터로 점차 옮겨가고 있습니다. 복잡한 수학 문제, 다양한 분야에 걸친 지식 질의응답, 다단계 의사 결정 및 도구 활용 능력 등 모든 것은 고품질 추론 데이터셋의 지원에 의존합니다.
추론 데이터 세트는 수학 및 논리에 초점을 맞추거나 합성을 통해 복잡한 추론 과정을 구축하는 데 사용될 수 있습니다. 또한 다중 작업 능력 평가, 과학적 벤치마크 및 질의응답 시스템 최적화에도 활용될 수 있습니다. 그러나 이러한 데이터 자원은 종종 다양한 형식으로 존재하며, 파편화되어 있어 통일된 방식으로 사용하기 어렵습니다. 이로 인해 많은 개발자와 연구자들이 "데이터를 찾는 데" 상당한 시간을 허비하게 됩니다.
그러므로,HyperAI는 다중 도메인, 다중 작업 추론, 합성 추론 훈련 데이터, 과학 연구 벤치마크 및 대규모 질의응답 데이터를 포괄하는 고품질 추론 데이터 세트 모음을 구축했습니다.또한 데이터셋을 다운로드하거나 온라인으로 사용할 수 있도록 지원하여 추론 데이터셋 사용에 대한 진입 장벽을 낮춥니다.
더욱 고품질의 데이터 세트:
Open-RL 추론 문제 데이터셋
* 온라인에서 사용하세요:
Open-RL은 Turing에서 2026년에 공개한 다중 영역 추론 문제 데이터셋으로, 물리학, 수학, 생물학, 화학 분야의 독립적이고 검증 가능하며 명시적인 STEM 추론 문제를 포함하고 있습니다.
각 문제는 여러 단계의 추론을 필요로 하며, 기호 연산 및/또는 수치 계산을 포함하고, 객관적으로 검증 가능한 최종 답을 가지고 있습니다. 이 데이터셋은 강화 학습 미세 조정, 보상 모델링, 결과 중심 학습, 그리고 검증 가능한 추론 벤치마킹에 적합합니다.
CHIMERA 일반 추론 합성 데이터 세트
* 온라인에서 사용하세요:
CHIMERA는 추론 훈련을 위해 특별히 설계된 합성 추론 데이터 세트로, 광범위한 STEM 분야를 포괄하며 긴 사고 과정(CoT)을 제공합니다.
이 데이터셋은 수학, 컴퓨터 과학, 화학, 물리학, 문학, 역사, 생물학, 음성학 등 8개 과목에 걸쳐 9,225개의 문항으로 구성되어 있습니다. 모든 예시는 대규모 언어 모델(LLM)을 통해 생성되었으며, 수동 주석 없이 자동으로 검증되었습니다.
과목 분포:
* 수학: 4,452
*컴퓨터 과학: 1,303
*화학: 1,102
*물리학: 742
*문헌: 504
*역사: 422
*생물학: 383
*언어학: 317
Nemotron-Math-v2 수학적 추론 데이터셋
* 온라인에서 사용하세요:
Nemotron-Math-v2는 NVIDIA Corporation에서 공개한 수학적 추론 데이터셋입니다. 주로 LLM(언어 기반 모델)을 훈련시켜 구조화된 수학적 추론을 수행하도록 하거나, 도구를 활용한 추론과 순수 언어 추론의 차이점을 연구하고, 장기 컨텍스트 또는 다중 트랙 추론 시스템을 구축하는 데 사용됩니다.
이 데이터 세트는 약 347,000개의 고품질 수학 문제와 700만 개의 모델 생성 추론 궤적을 포함합니다. 각 문제는 추론 깊이의 높음/중간/낮음, 그리고 Python TIR 사용 여부에 따라 6가지 구성으로 해결되며, 결과는 LLM을 검증 도구로 사용하는 파이프라인을 통해 검증됩니다.
OmniSpatial 파노라마 공간 추론 벤치마크 데이터 세트
* 온라인에서 사용하세요:
OmniSpatial은 칭화대학교가 상하이 우주기술고등연구소, 상하이 인공지능연구소 등과 협력하여 2025년에 발표한 파노라마 공간 추론 벤치마크 데이터셋입니다. 관련 논문은 "OmniSpatial: 시각-언어 모델을 위한 포괄적인 공간 추론 벤치마크 구축"이라는 제목으로, 시각-언어 모델의 공간 이해도 평가에 있어 부족한 부분을 보완하는 것을 목표로 합니다.
이 데이터셋은 공간 추론 과제의 네 가지 주요 범주(동적 추론, 복잡한 공간 논리, 공간 상호작용, 관점 수용)에 걸쳐 총 50개의 하위 과제를 포함하는 약 1,533개의 이미지-질문-답변 샘플로 구성되어 있습니다. 데이터 소스는 인터넷 이미지, 심리 테스트, 운전면허 시험 문제 등 다양합니다. 주석은 품질과 다양성을 보장하기 위해 여러 차례 검토 과정을 거쳤습니다. 기존 벤치마크와 달리 OmniSpatial은 템플릿 기반 구성을 지양하여 실제 복잡한 시나리오를 더욱 유사하게 구현합니다. 기본적인 공간 관계(예: 앞/뒤, 좌/우, 거리)뿐만 아니라 다중 객체 상호작용, 장면 변화, 다양한 관점을 고려한 추론 능력까지 평가합니다.
이 데이터셋은 특히 지능형 내비게이션, 증강/가상 현실, 복잡한 장면 이해와 같은 응용 분야에서 대규모 멀티모달 모델의 공간 추론 능력을 훈련하고 평가하는 데 적합합니다. 포괄적이고 도전적인 표준화된 벤치마크 데이터셋입니다.
FrontierScience 추론 연구 과제 평가 데이터 세트
* 온라인에서 사용하세요:
프론티어사이언스(FrontierScience)는 추론 및 과학 연구 과제 평가를 위한 데이터셋으로, 오픈AI에서 2025년에 공개했습니다. 이 데이터셋은 전문가 수준의 과학적 추론 및 과학 연구 하위 과제에서 대규모 모델의 역량을 체계적으로 평가하는 것을 목표로 합니다.
본 데이터셋은 "전문가 제작 + 2단계 과제 구조 + 자동 채점 메커니즘"이라는 설계 메커니즘을 채택하고 있으며, 폐쇄형 정밀 추론과 개방형 과학 연구 추론이라는 두 가지 유형의 능력에 해당하는 두 개의 하위 집합으로 나뉩니다.
올림피아드 데이터셋
원래 국제 물리, 화학, 생물 올림피아드 메달 수상자와 국가대표팀 코치들이 설계한 이 문제들은 IPhO, IChO, IBO와 같은 최고 수준의 국제 대회와 비슷한 난이도를 가지고 있습니다. 단답형 추론 문제에 초점을 맞춘 이 모델은 결과의 검증 가능성과 자동 평가의 안정성을 보장하기 위해 퍼지 매칭이 가능한 단일 수치 값, 대수 표현식 또는 생물학 용어를 출력해야 합니다.
연구 데이터 세트
박사 과정 학생, 박사 후 연구원, 교수들이 작성한 이 문제들은 물리학, 화학, 생물학의 세 가지 주요 분야를 아우르며 실제 과학 연구에서 접할 수 있는 하위 문제들을 시뮬레이션합니다. 각 문제에는 모델의 성능을 평가하기 위한 세밀한 10점 척도 시스템이 함께 제공되며, 정답 여부뿐만 아니라 모델링 가정의 완성도, 추론 과정, 중간 결론 도출 등 여러 핵심 측면에서 평가가 이루어집니다.
HotpotQA 질문 답변 데이터 세트
* 온라인에서 사용하세요:
HotpotQA 데이터셋은 영어 위키백과에서 수집한 113,000개의 크라우드소싱 질문으로 구성된 대규모 질문-답변 데이터셋입니다. 이 질문들에 답하려면 두 개의 위키백과 문서의 서두 부분을 참조해야 합니다.
각 질문에는 두 개의 정답 단락과 해당 단락에서 발췌한 문장 목록이 포함되어 있으며, 이 문장들은 질문에 답하는 데 필요하다고 판단되는 뒷받침 사실들을 제공합니다. 이 데이터 세트는 다음과 같은 특징을 가지고 있습니다.
이 질문에 답하려면 여러 관련 문서를 검색하고 추론해야 합니다.
* 문제는 다양하며 기존의 지식 기반이나 지식 모델에 국한되지 않습니다.
이 데이터 세트는 추론에 필요한 문장 수준의 뒷받침 사실을 제공하여 QA 시스템이 강력한 지도 학습 하에서 예측을 추론하고 해석할 수 있도록 합니다.
이 데이터셋은 QA 시스템이 관련 사실을 추출하고 필요한 비교를 수행하는 능력을 테스트하기 위한 새로운 사실 비교 문제를 제시합니다.
VCR 시각적 상식 추론 데이터 세트
* 온라인에서 사용하세요:
VCR은 Visual Commonsense Reasoning의 약자로, 시각적 상식 추론을 위한 대규모 데이터 세트입니다. 데이터 세트는 이미지에 대한 까다로운 질문을 제기하며, 기계는 두 가지 하위 작업을 완료해야 합니다. 질문에 올바르게 답하고 답변을 정당화하는 이유를 제공해야 합니다.
VCR 데이터 세트에는 많은 수의 질문이 포함되어 있으며, 그 중 212,000개는 학습에, 26,000개는 검증에, 25,000개는 테스트에 사용됩니다. 11만 개가 넘는 독특한 영화 장면에서 정답과 이유가 도출되었습니다.

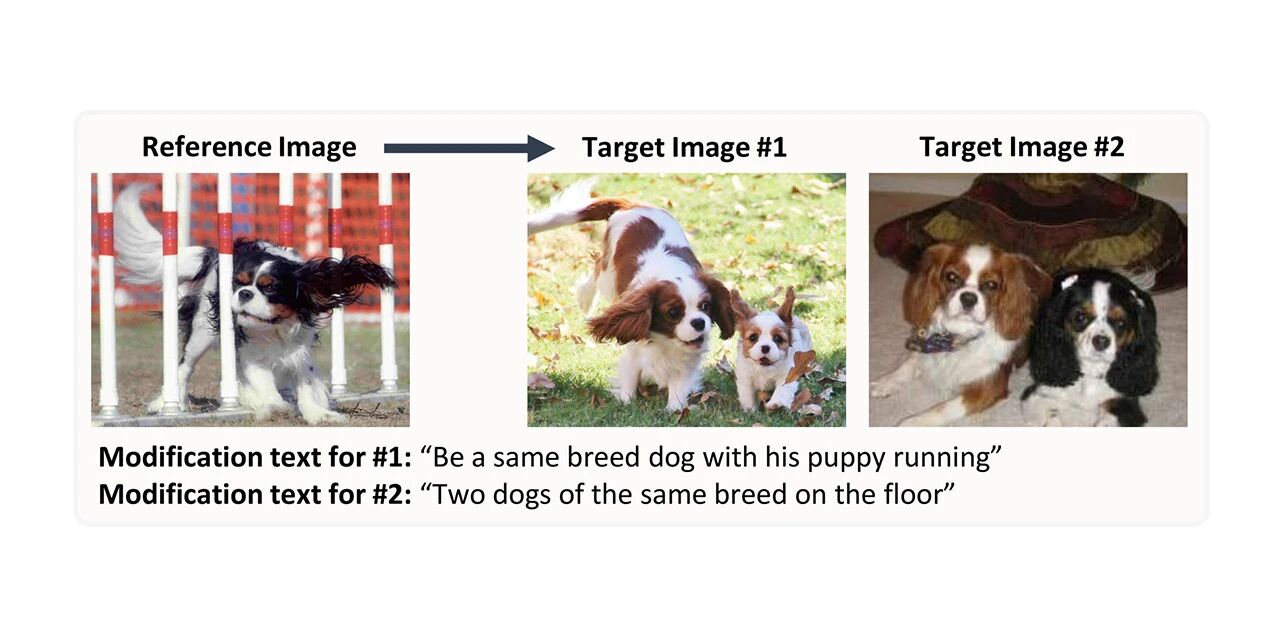
CIRR 이미지 합성 검색 데이터셋
* 온라인에서 사용하세요:
CIRR은 실제 이미지에 대한 이미지 검색 구성(Compose Image Retrieval on Real-life images)의 약자로, 크라우드소싱, 오픈 도메인 이미지와 수동으로 생성하고 수정한 텍스트로 구성된 36,000쌍이 포함되어 있습니다. 이 데이터 세트는 시각적 언어 개념에 대한 미묘한 추론과 대화를 통한 반복적 검색에 대한 향후 연구를 용이하게 하는 것을 목표로 하며, 시각적으로 유사한 오픈 도메인 이미지를 구별하는 데 더 큰 중점을 두어 기존 데이터 세트의 단점을 해결합니다.