Command Palette
Search for a command to run...
VIRES: スケッチとテキストのデュアルガイドによるビデオ再描画
1. チュートリアルの概要

VIRESは、スケッチとテキストガイダンスを組み合わせたビデオインスタンスの再描画手法で、2025年に北京大学カメラインテリジェンス研究所(Shi Baixinチーム)がOpenBayesベイジアンコンピューティングおよび北京郵電大学人工知能学院パターン認識研究所のLi Si准教授のチームと共同で提案した。 動画の被写体の再描画、置換、生成、削除など、さまざまな編集操作をサポートしている。 この手法は、テキスト生成動画モデルの事前知識を利用して時間的な一貫性を確保している。 また、標準化された適応型スケーリングメカニズムを備えたSequential ControlNetを提案しており、構造レイアウトを効果的に抽出し、高コントラストのスケッチの詳細を適応的に捉えることができる。 さらに、研究チームはDiT(拡散変換器)バックボーンにスケッチアテンションメカニズムを導入し、きめ細かなスケッチセマンティクスを解釈・注入している。実験結果では、VIRES がビデオ品質、時間的一貫性、条件付きアライメント、ユーザー評価など多くの面で既存の SOTA モデルよりも優れていることが示されています。
関連研究 VIRES: スケッチとテキストによるガイド生成によるビデオインスタンスの再描画 このトピックはCVPR 2025に選ばれました。
このチュートリアルでは、単一カード A6000 のリソースを使用します。
2. プロジェクト例

3. 操作手順
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります

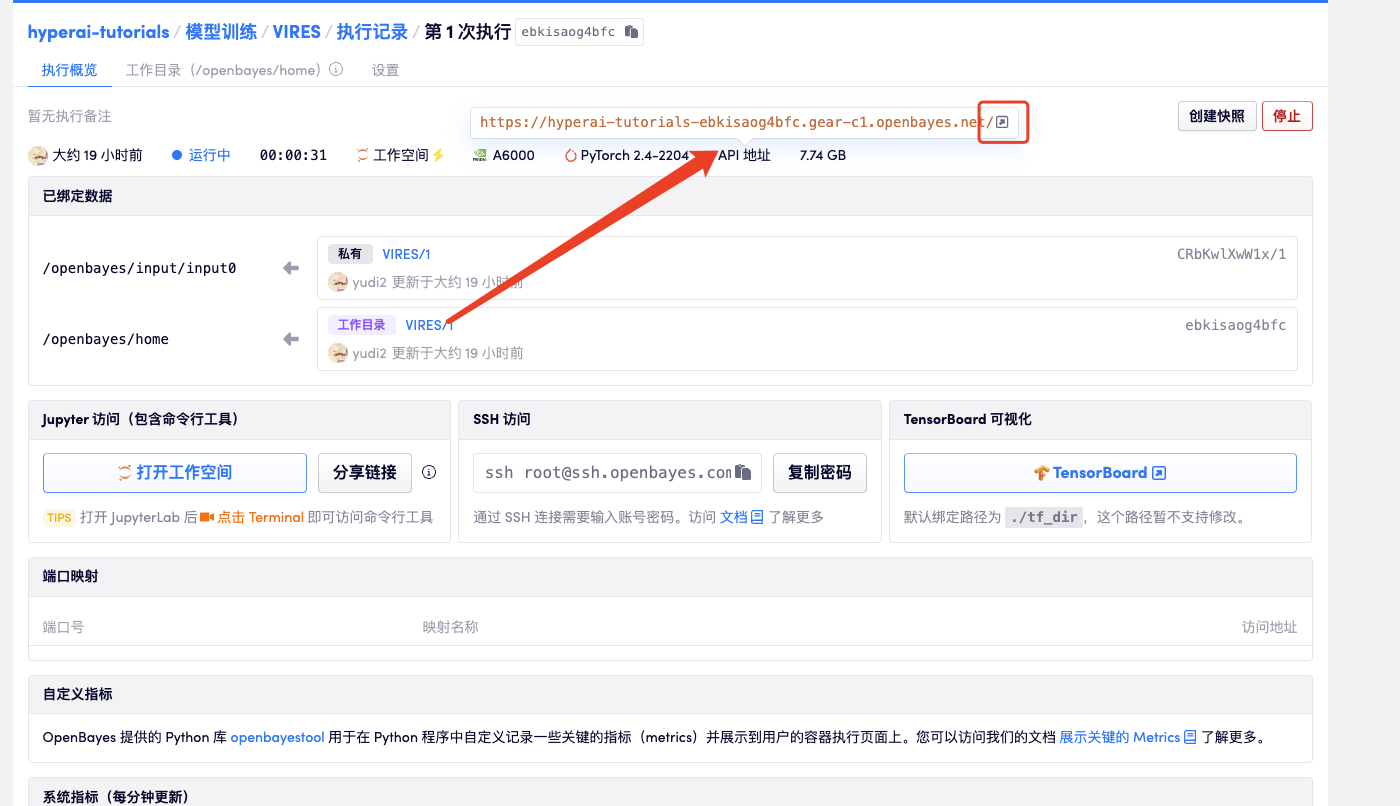
2. ウェブページに入ると、モデルを使用できます
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。
利用手順
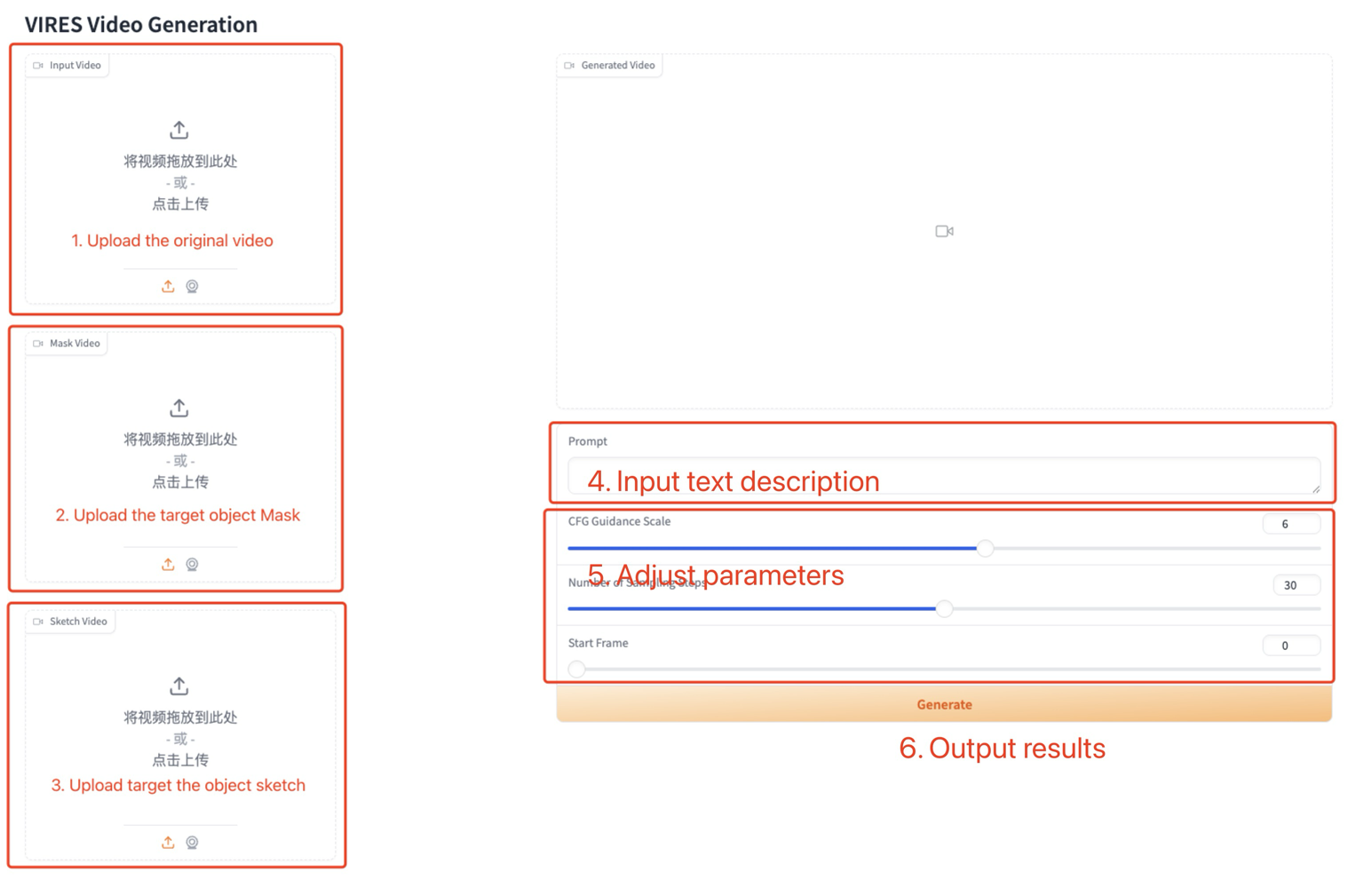
パラメータの説明:
- CFG ガイダンス スケール: 無条件ガイダンスの強さ。
- サンプリング ステップ数: サンプリング ステップの数。
- 開始フレーム: 開始フレームを編集します。
引用情報
@article{vires,
title={VIRES: Video Instance Repainting via Sketch and Text Guided Generation},
author={Weng, Shuchen and Zheng, Haojie and Zhang, Peixuan and Hong, Yuchen and Jiang, Han and Li, Si and Shi, Boxin},
booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference},
pages={28416--28425},
year={2025}
}