Command Palette
Search for a command to run...
Chatterbox TTS: 音声合成デモ
1. チュートリアルの概要

Chatterboxのコア機能の一つは、ゼロサンプル音声クローニングです。複雑な学習プロセスを必要とせず、わずか5秒間のリファレンス音声から、非常にリアルなパーソナライズ音声を生成できます。さらに、感情表現の誇張制御もサポートしており、ユーザーは感情の強さ、話す速度、声のイントネーションを調整することで、より表現力豊かな音声を作成できます。Chatterboxは、200ミリ秒未満の超低遅延リアルタイム合成機能を備えており、バーチャルアシスタントやリアルタイムダビングなどのインタラクティブアプリケーションに最適です。コンテンツのセキュリティとトレーサビリティを確保するため、Chatterboxで生成された音声には、Resemble AIのPerthニューラルウォーターマーキング技術が埋め込まれており、不正使用を防止しています。
主な革新は次のとおりです。
- 感情の誇張のコントロール: パラメータを調整することで (例: exaggeration = 0.7 + cfg = 0.3)、当たり障りのないスピーチスタイルからドラマチックなスピーチスタイルまで実現できます。
- リアルタイム合成機能: 推論遅延 < 200 ms、リアルタイムインタラクティブシナリオに最適
このチュートリアルのコンピューティングリソースには、RTX 4090カード1枚を使用します。このモデルのプロンプトワードは英語のみに対応しています。
2. 操作手順
1. コンテナを起動します
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。
2. 使用手順
Safari ブラウザを使用する場合、オーディオは直接再生されない場合があり、再生する前にダウンロードする必要があります。
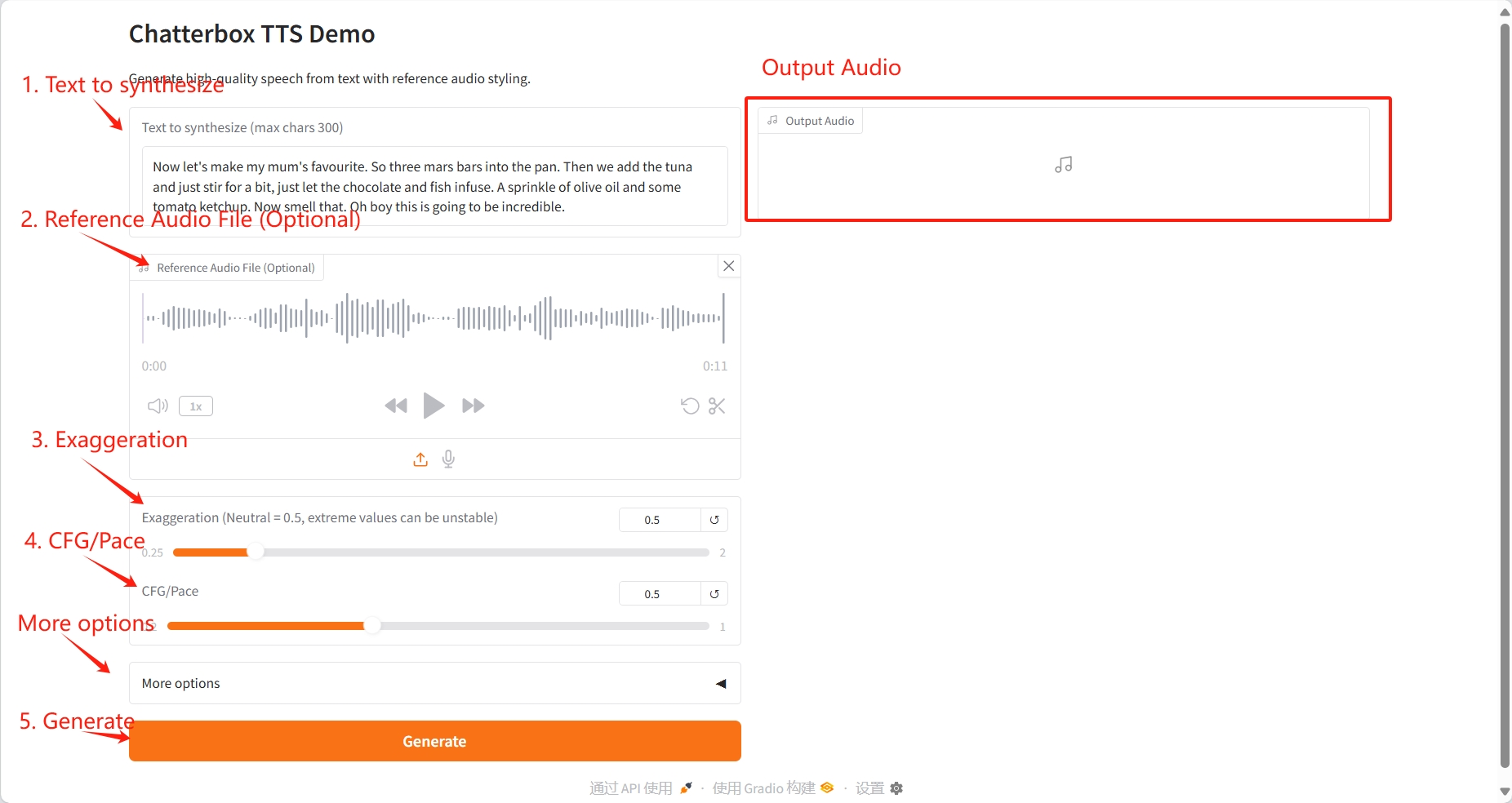
1. テキスト生成
具体的なパラメータ:
- 合成テキスト: 音声に変換するテキストを入力します。最大300文字まで入力できます(長すぎるテキストは自動的に切り捨てられます)。
- 参照オーディオ ファイル (オプション): システムが話者の声のスタイル、イントネーション、リズムを模倣できるようにするための参照オーディオ ファイルを提供します。
- 誇張(ニュートラル = 0.5):感情表現と声のトーンの誇張を制御します。
- CFG/ペース: スピーチのリズムと速度を制御します。
- ランダム シード (ランダムの場合は 0): ランダム シードを設定します。
- 温度: 音声表現のランダム性と多様性を制御します。
結果 
3. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。
