HyperAI
Command Palette
Search for a command to run...
Orpheus TTS: 多言語テキスト読み上げモデル
1. チュートリアルの概要

このチュートリアルでは、単一の RTX 4090 カードのリソースを使用します。
2. プロジェクト例
3. 操作手順
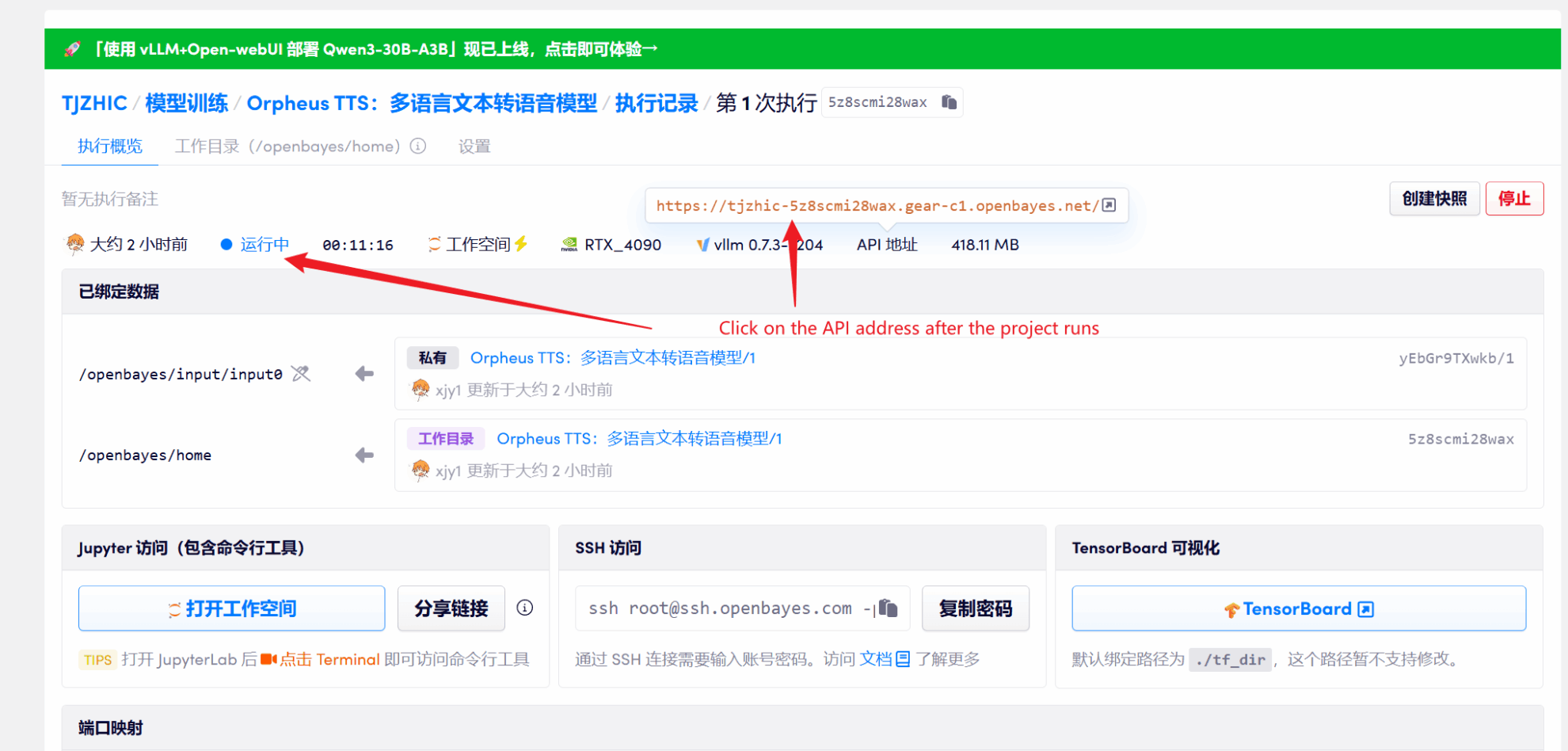
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、1〜2分ほど待ってページを更新してください。
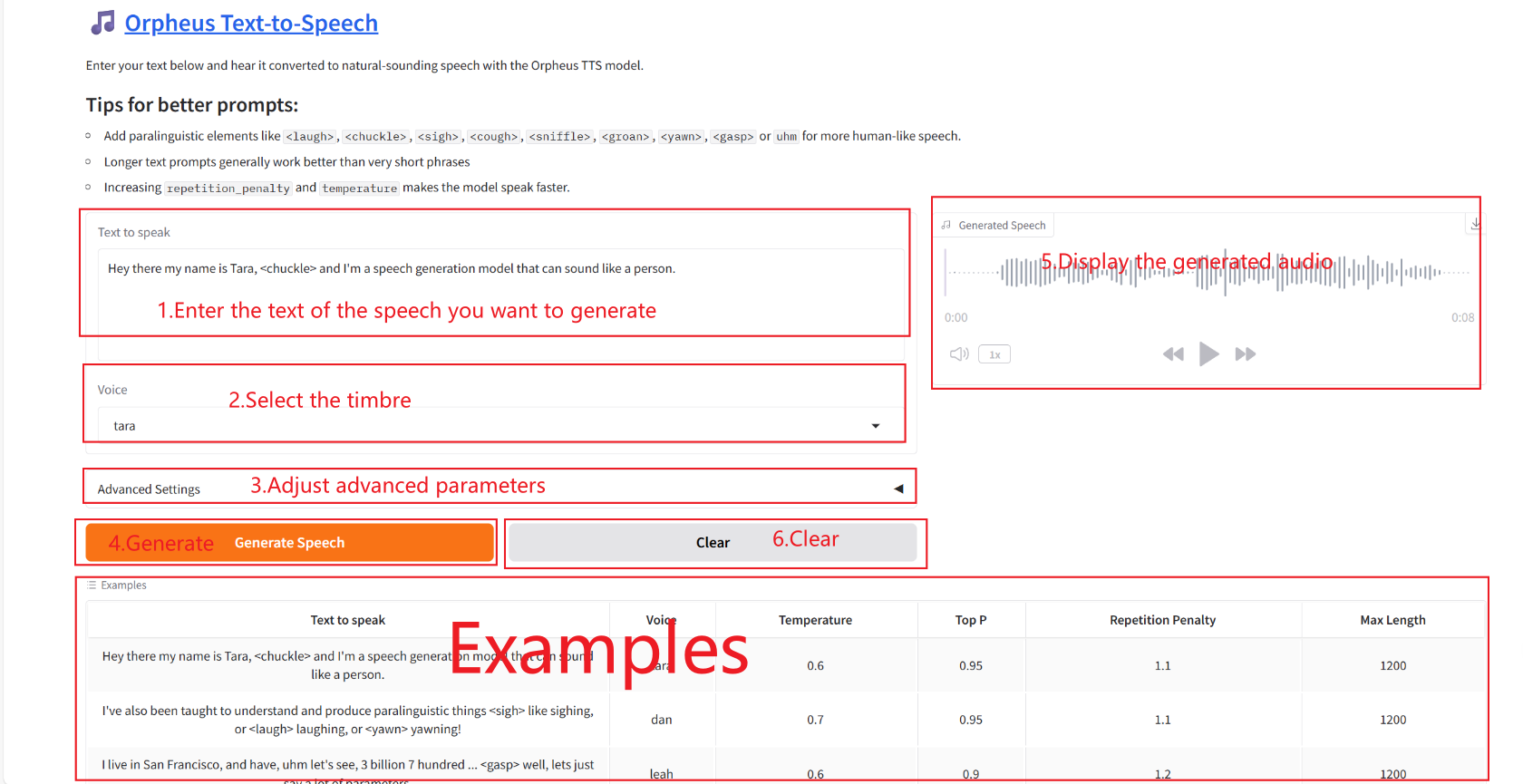
2. Web ページに入ると、モデルと会話を開始できます。
❗️重要な使用上のヒント:
- 温度: 生成のランダム性と創造性を制御します。
- トップP: 候補トークンの選択範囲を制御します。
- 繰り返しペナルティ: スピーチにおける反復的なパターンを抑制します。
- 最大長: 生成されたオーディオの継続時間を制御します。
利用手順
Safari ブラウザを使用する場合、オーディオは直接再生されない場合があり、再生する前にダウンロードする必要があります。英語の効果は中国語の効果よりも優れています。
4. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

プロジェクトサポート
Githubユーザーに感謝 xxxjjjyyy1 このチュートリアルの展開。
このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。