HyperAI
Command Palette
Search for a command to run...
Moondream3-preview: モジュラー視覚言語理解モデル
1. チュートリアルの概要
Moondream3は、Moondreamチームが2025年9月に提案したハイブリッドエキスパートアーキテクチャに基づく視覚言語モデルであり、90億個のパラメータ(うち20億個は活性化パラメータ)を誇ります。このモデルは最先端の視覚推論機能を提供し、最大32Kのコンテキスト長をサポートし、高解像度画像を効率的に処理できます。Moondream3は革新的なMoE FFNおよびSigLIPビジュアルエンコーダを採用しており、画像質問応答、画像アノテーション、物体検出などのタスクに適しています。関連技術文献には以下が含まれます… ムーンドリーム3 プレビュー: 驚異的なスピードで展開するフロンティアレベルの推理 。
このチュートリアルでは、リソースとして単一の RTX 5090 グラフィック カードを使用し、プロジェクト出力は英語のみをサポートします。
2. プロジェクト例
3. 操作手順
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
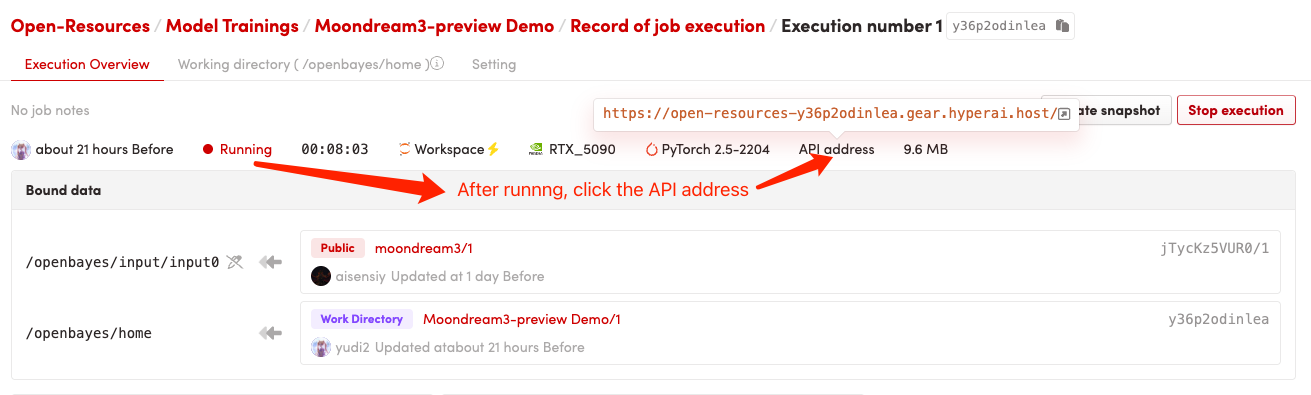
2. ウェブページに入ると、モデルを使用できます
「Bad Gateway」と表示される場合は、コードがバックグラウンドで実行されていることを意味します。2~3分ほどお待ちいただき、ページを更新してください。
利用手順
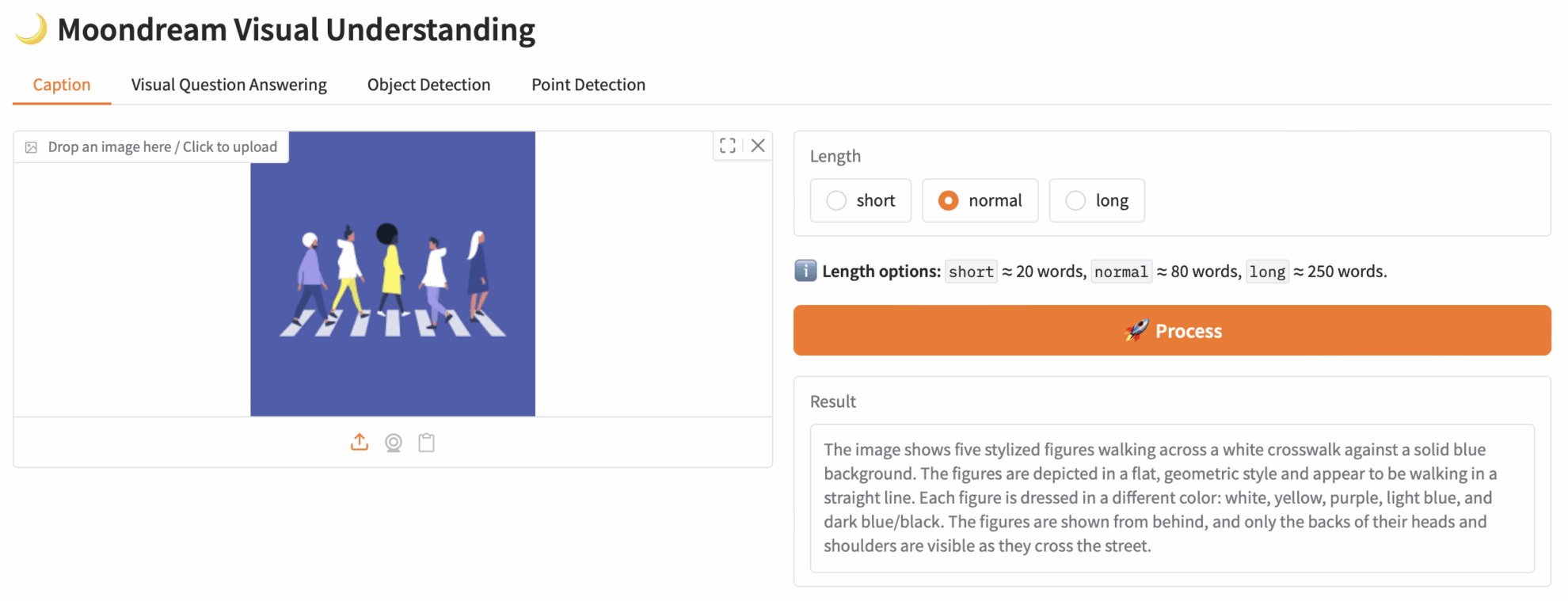
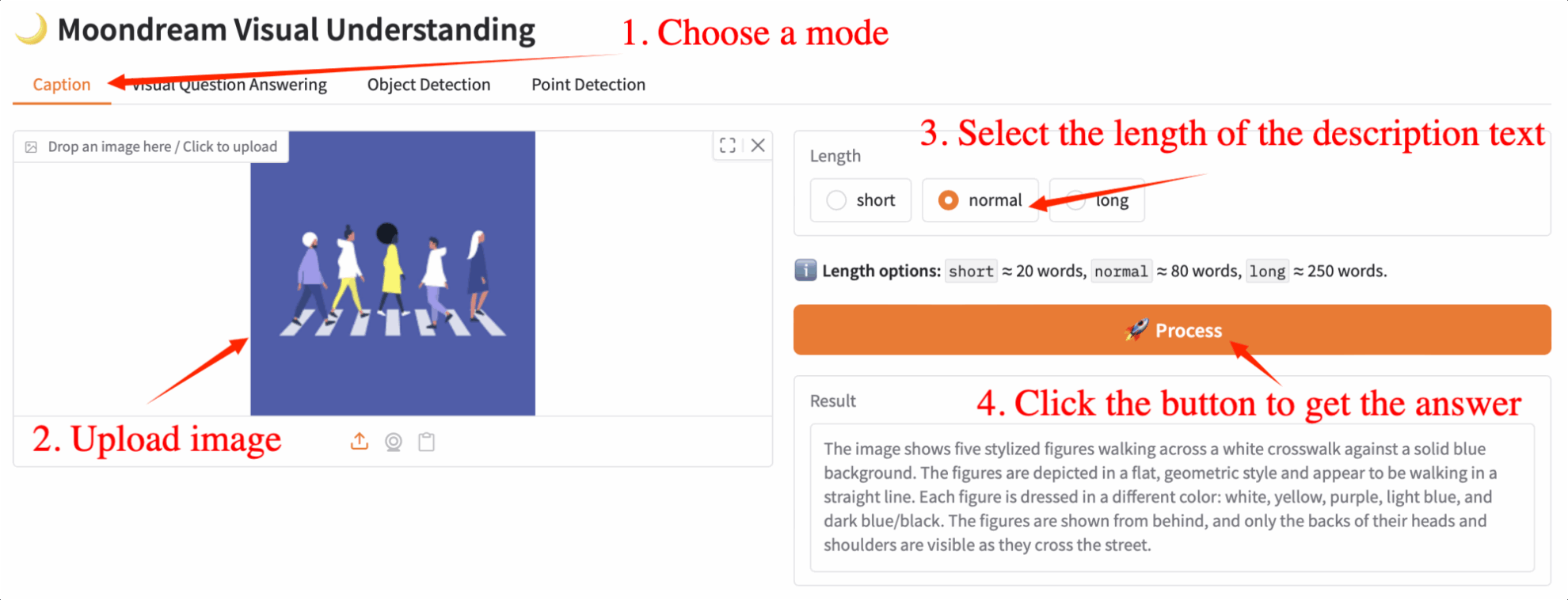
1. キャプション
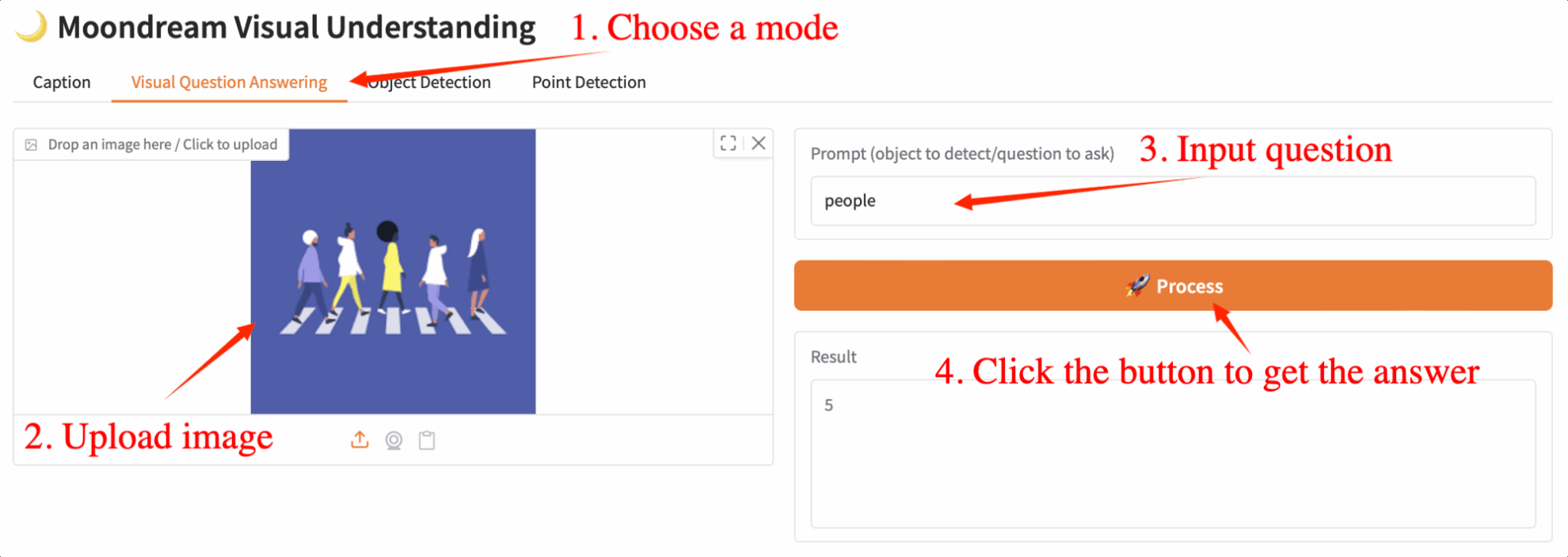
2. 視覚的な質問応答
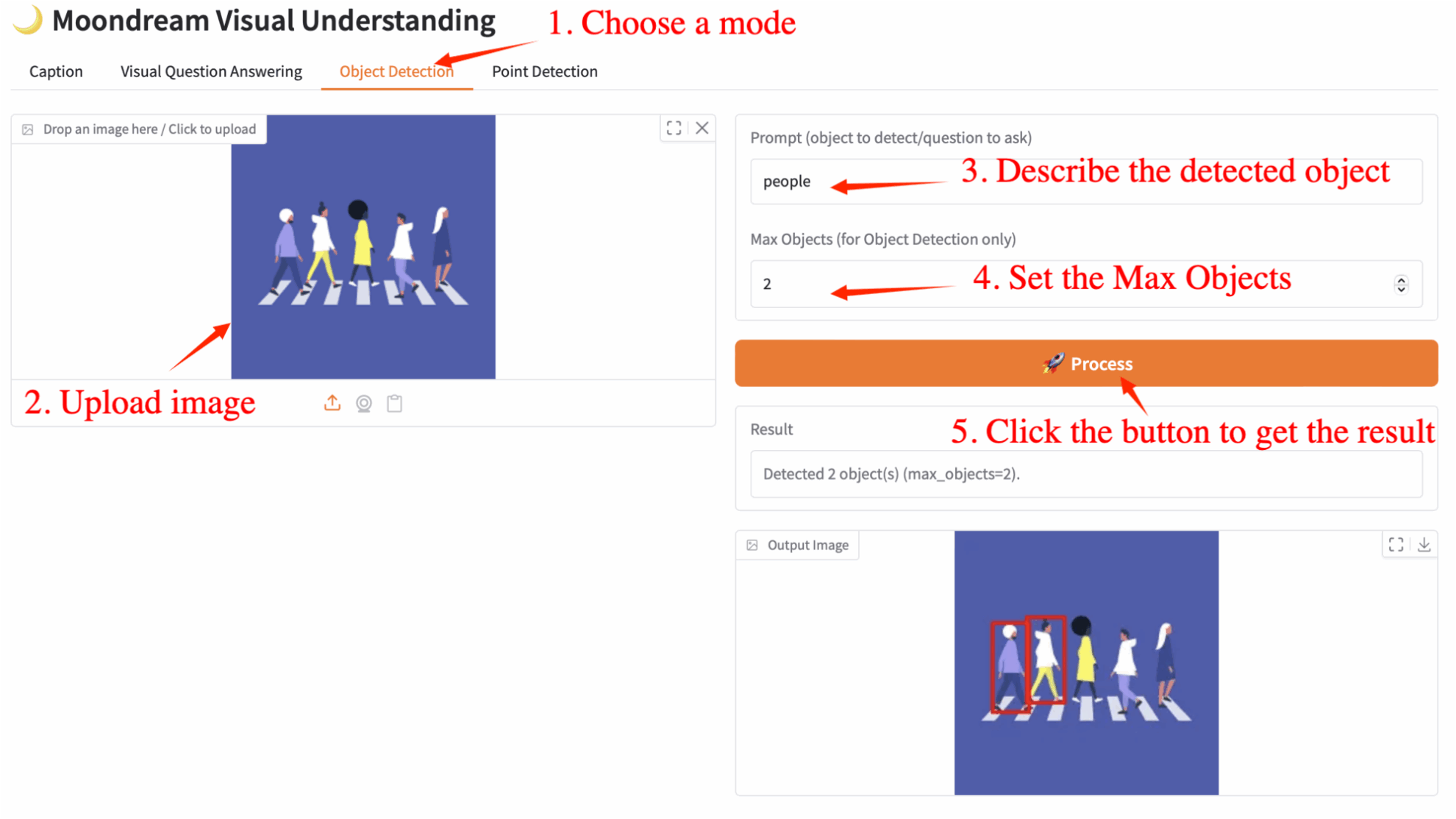
3. 物体検出
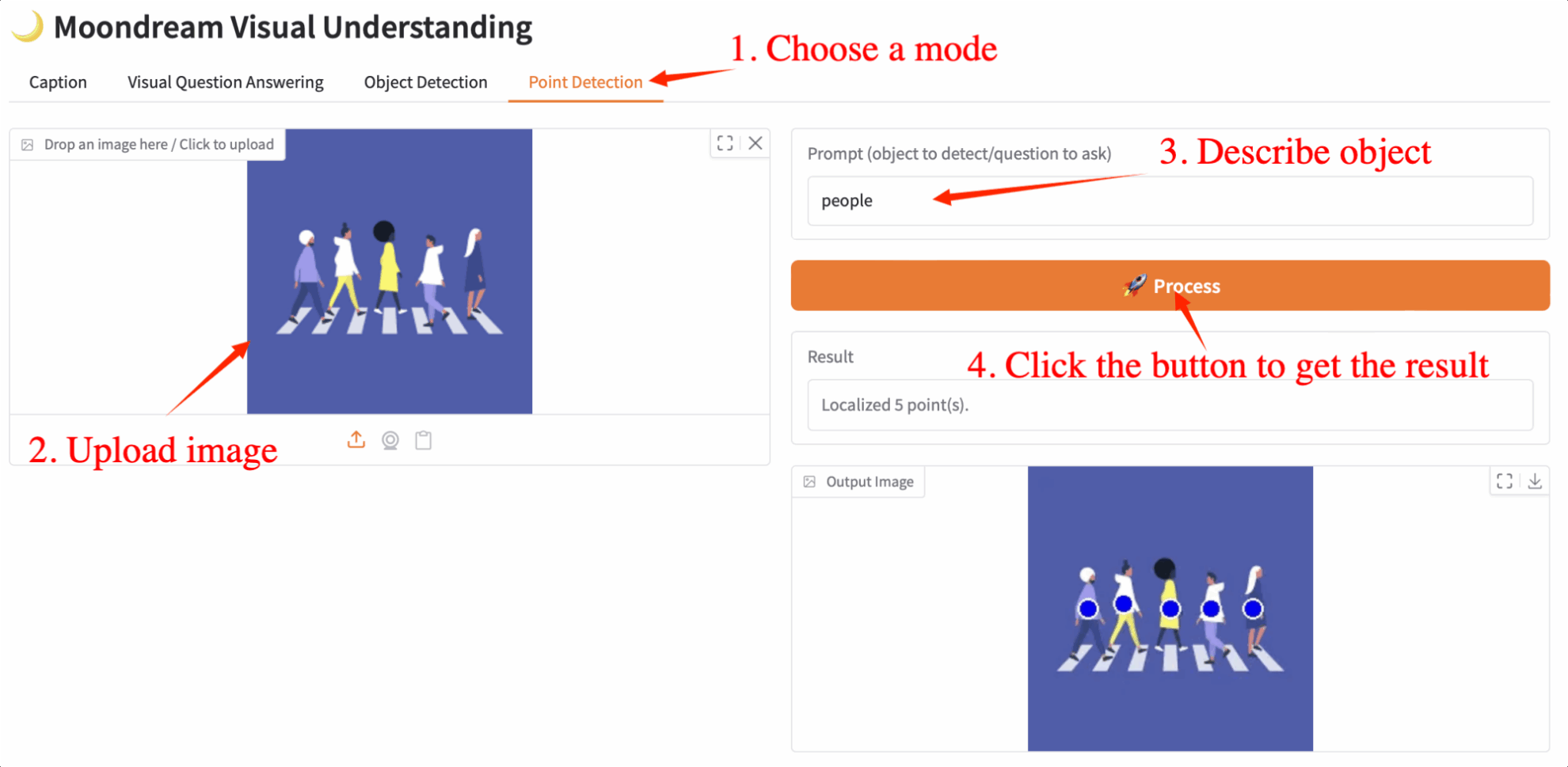
4. ポイント検出
このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。
Notebook の概要
レベル
入門
HyperAI Newsletters
最新情報を購読する
北京時間 毎週月曜日の午前9時 に、その週の最新情報をメールでお届けします
メール配信サービスは MailChimp によって提供されています