HyperAI
Command Palette
Search for a command to run...
IndexTTS-2: 自己回帰TTSの持続時間と感情制御のボトルネックを突破する
1. チュートリアルの概要

IndexTTS-2は、ビリビリ音声チームによって2025年6月にオープンソース化された、斬新なテキスト読み上げ(TTS)モデルです。感情表現と継続時間制御において飛躍的な進歩を遂げ、高精度な継続時間制御をサポートする初の自己回帰TTSモデルです。ゼロサンプル音声クローニングをサポートし、単一の音声ファイルから音色、リズム、話し方を正確に再現し、複数の言語をサポートしています。IndexTTS-2は感情と音色の分離制御を実装しており、ユーザーは音色と感情のソースを個別に指定できます。このモデルはマルチモーダル感情入力機能を備えており、感情参照音声、感情説明テキスト、感情ベクトルによる感情制御をサポートしています。関連研究論文も入手可能です。 IndexTTS2: 感情表現と持続時間制御を備えた自己回帰ゼロショットテキスト読み上げの画期的進歩 。
このチュートリアルでは、コンピューティング リソースとして単一の RTX 5090 グラフィック カードを使用します。
2. エフェクト表示
音声参照と同じ
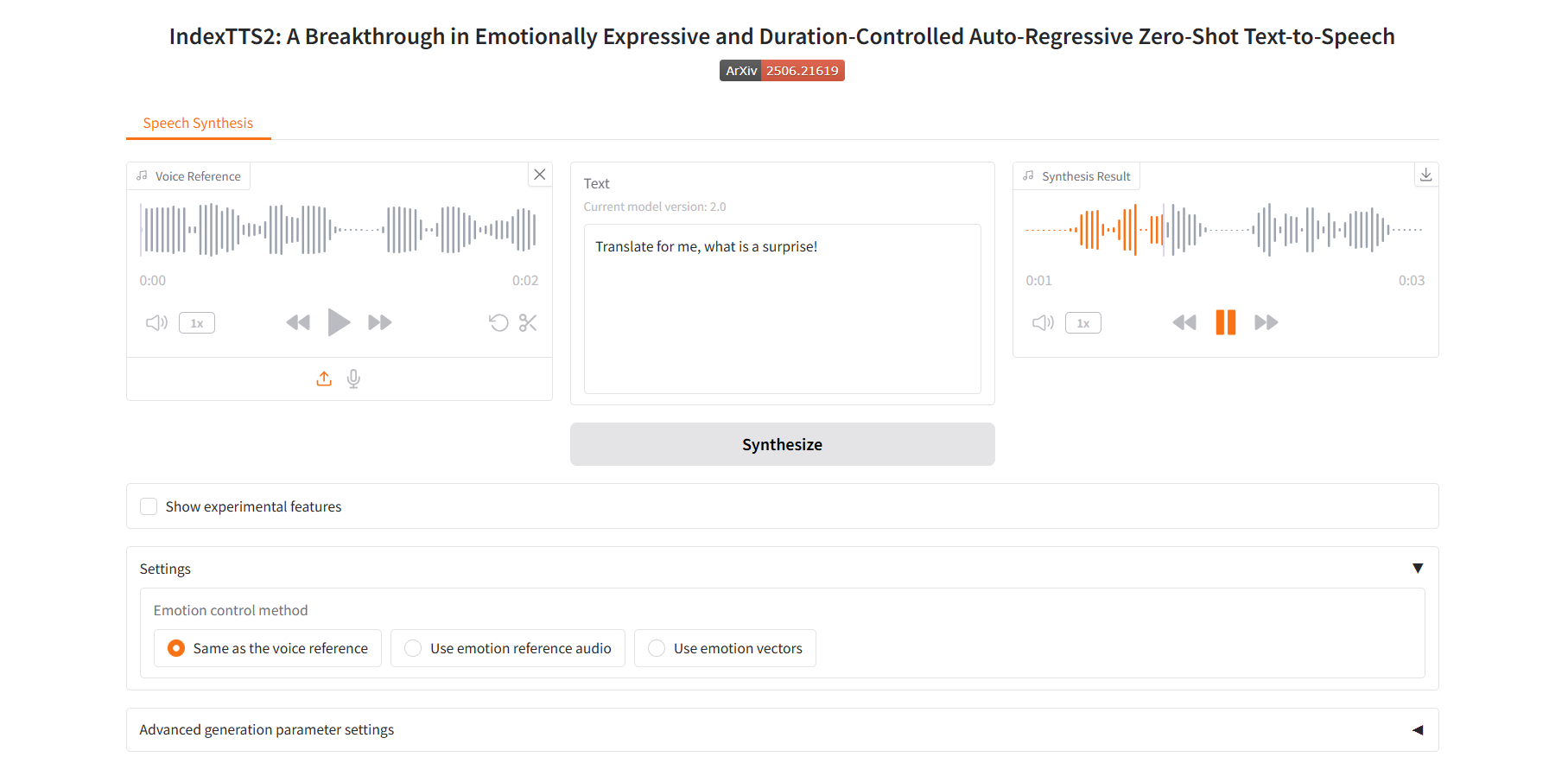
感情参照音声を使用する
感情ベクトルを使う
テキストの説明を使用して感情をコントロールする
3. 操作手順
1. コンテナを起動します
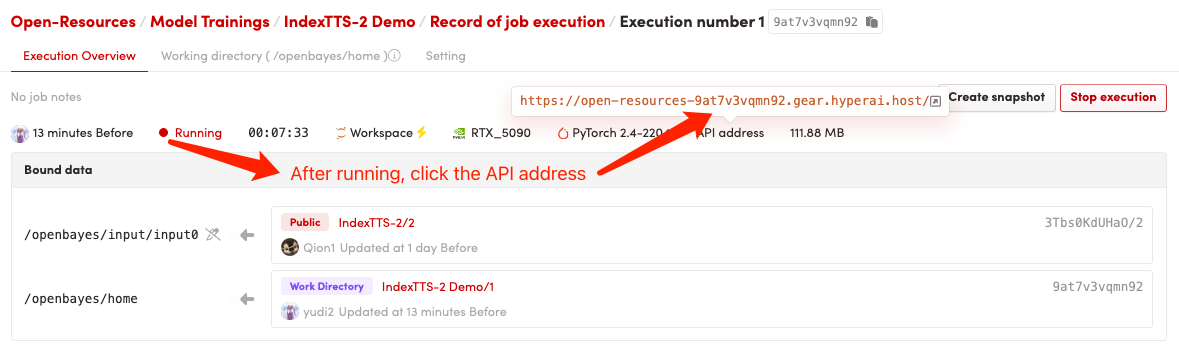
2. 使用手順
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。
Safari ブラウザを使用する場合、オーディオは直接再生されない場合があり、再生する前にダウンロードする必要があります。
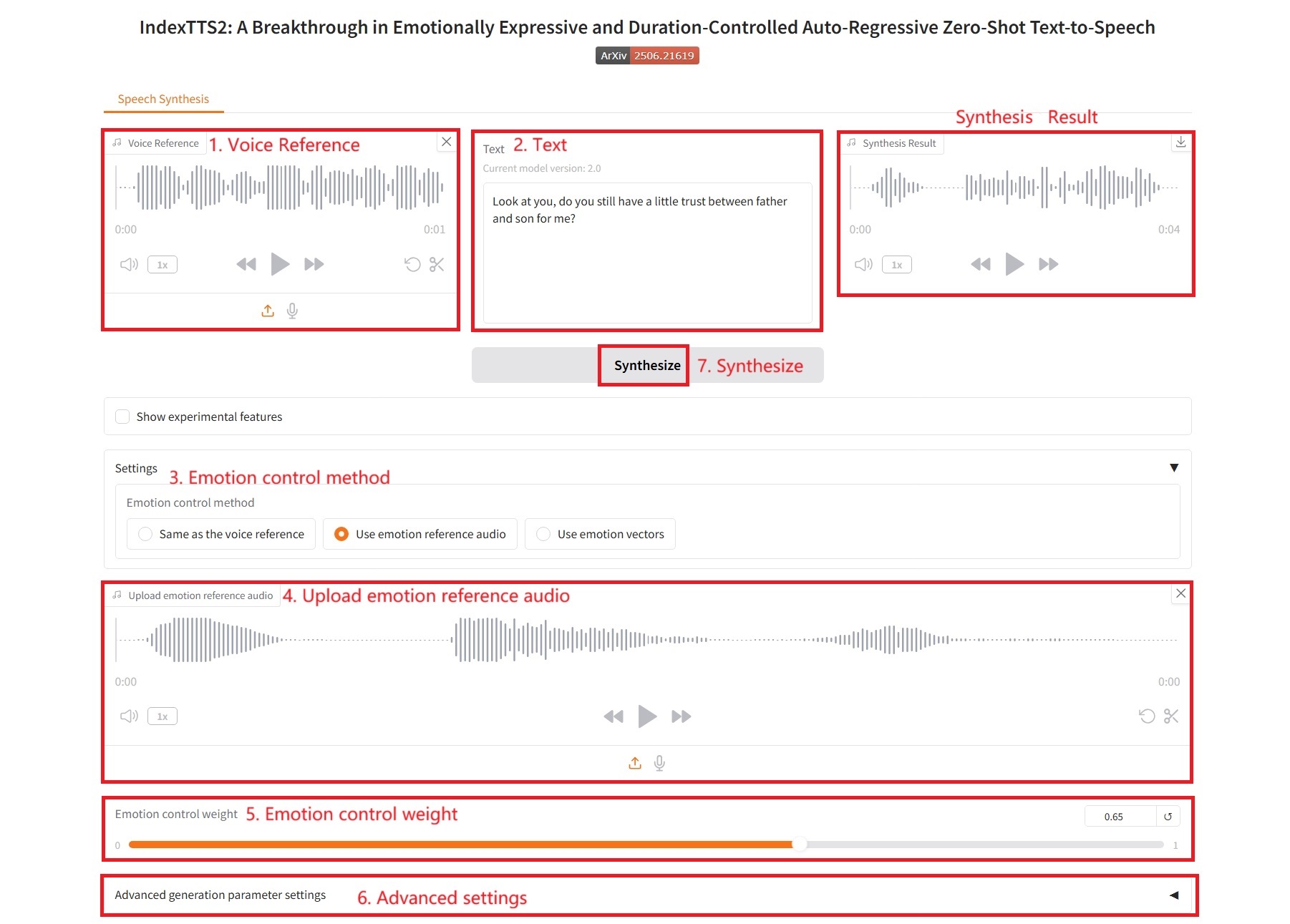
1. 音声参照と同じ

具体的なパラメータ:
- 高度なパラメータ設定:
- do_sample: サンプリングを実行するかどうか。
- 温度: サンプリング中の確率分布の滑らかさを制御します。
- top_p: カーネル サンプリング。
- top_k: 各生成ステップで、最も高い確率を持つ K 個のトークンのみが考慮されます。
- num_beams: ビーム検索幅。
- repetition_penalty: 繰り返しペナルティ。モデルが同じトークンを繰り返し生成する確率を減らします。
- length_penalty: 長さペナルティ。モデルが長いシーケンスまたは短いシーケンスを生成することを推奨または抑制します。これは主に、num_beams > 1 が使用されている場合に有効です。
- max_mel_tokens: 生成されるトークンの最大数。
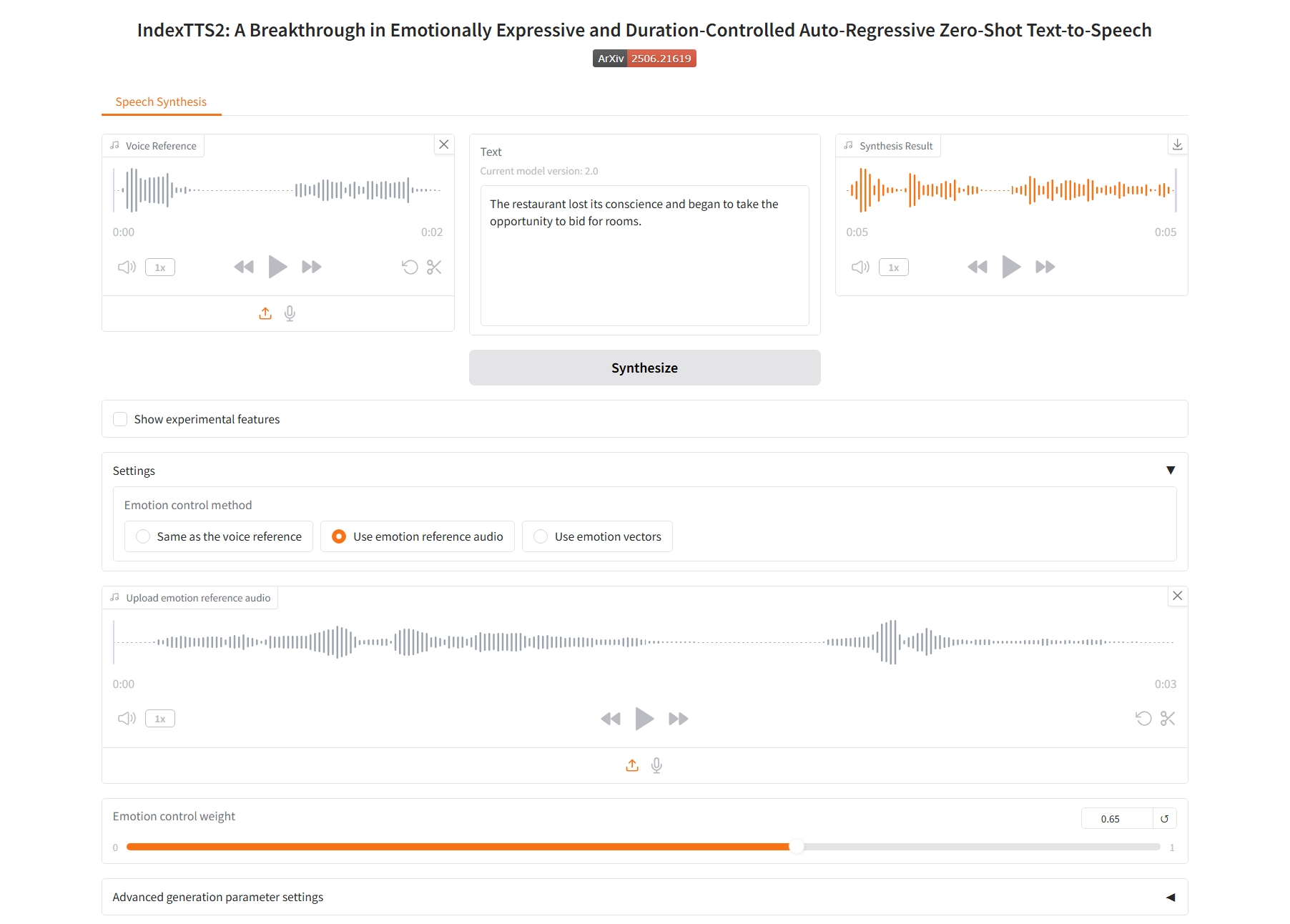
2. 感情参照音声を使用する
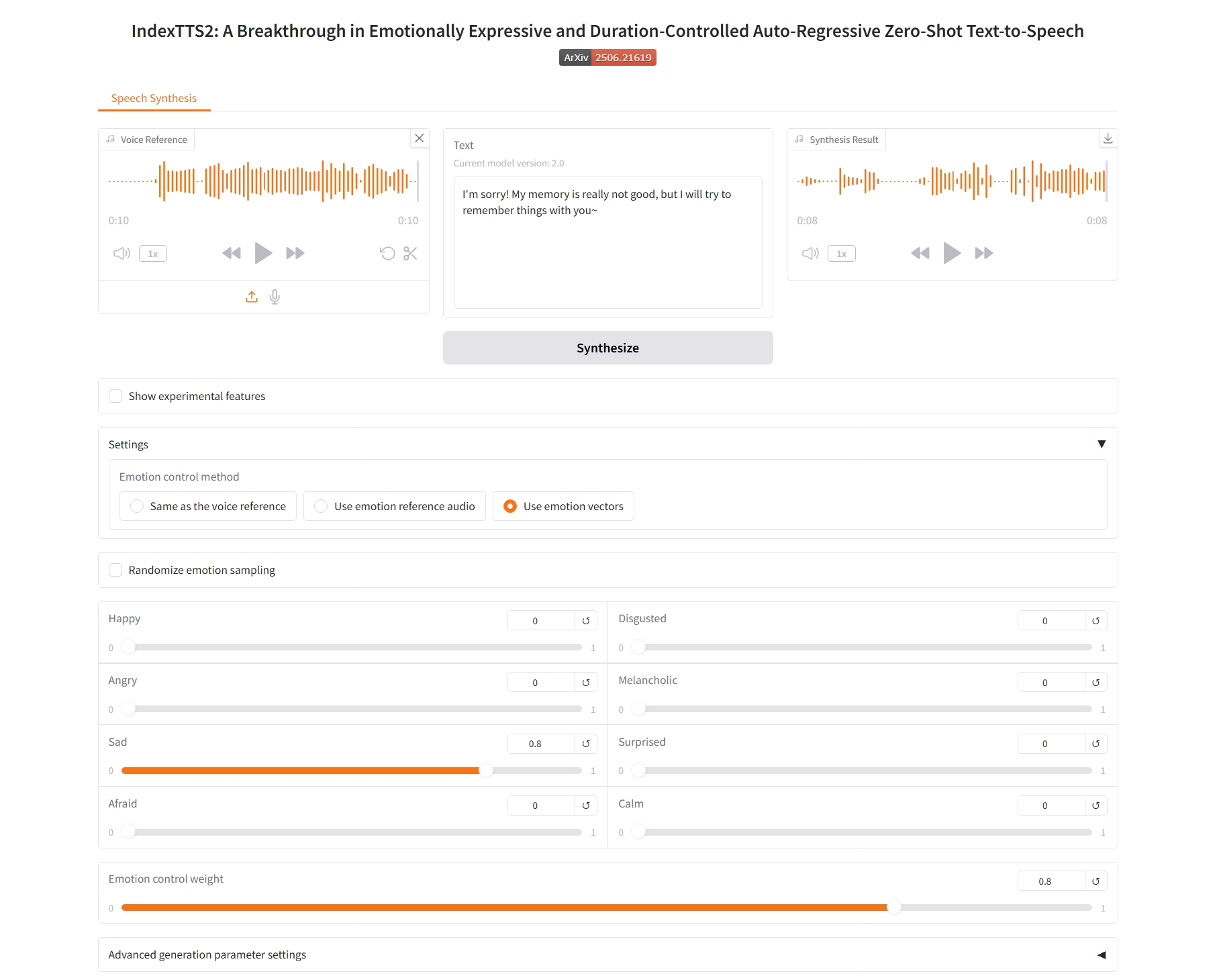
3. 感情ベクトルを使う
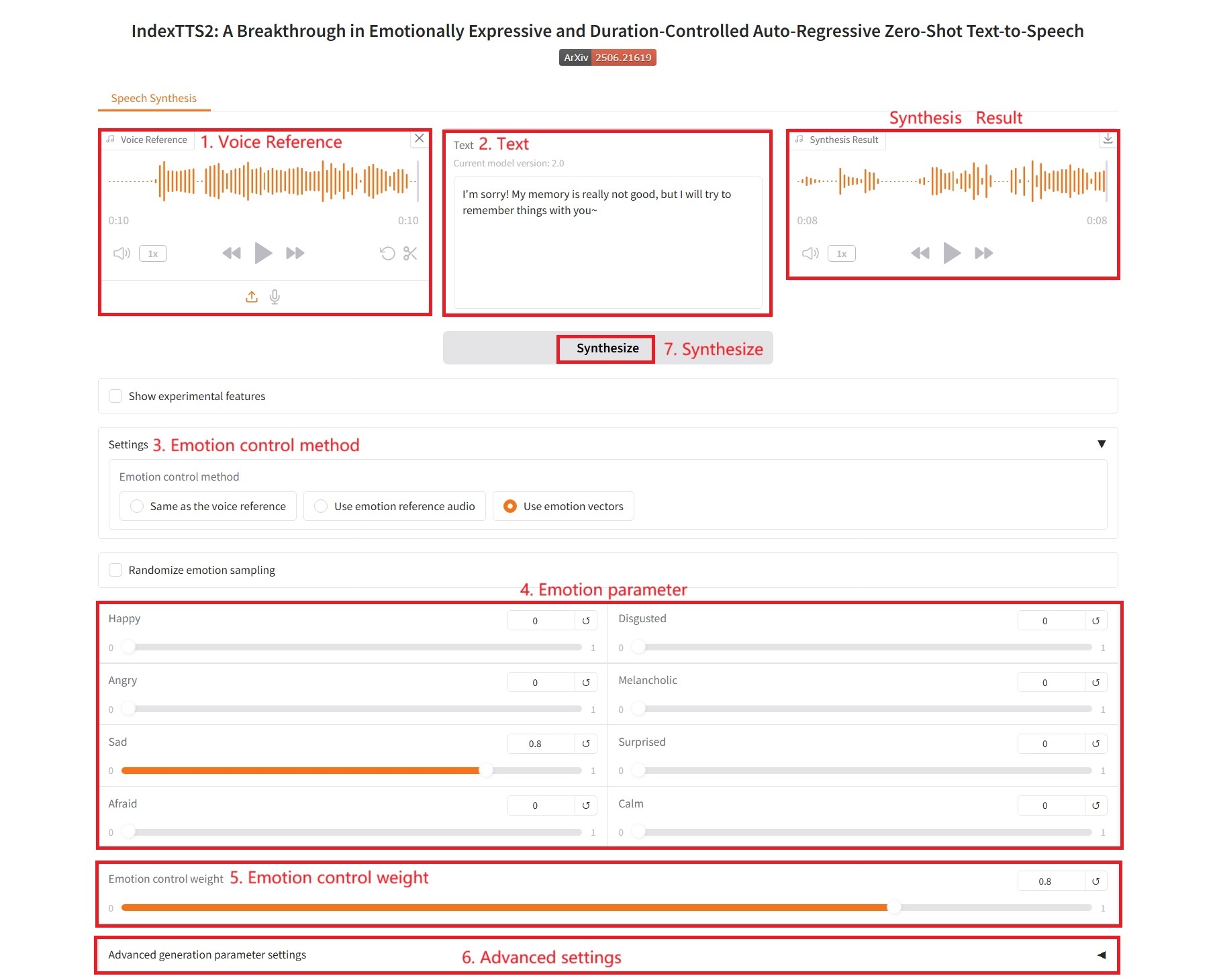
感情制御パラメータ:
- 幸せ、嫌悪、怒り、憂鬱、悲しみ、驚き、恐怖、落ち着き:これらは8つの基本的な感情の次元に対応しています。各スライダーの値(通常は0.0~1.0)は、最終的なスピーチに反映させたい感情の強さを示します。
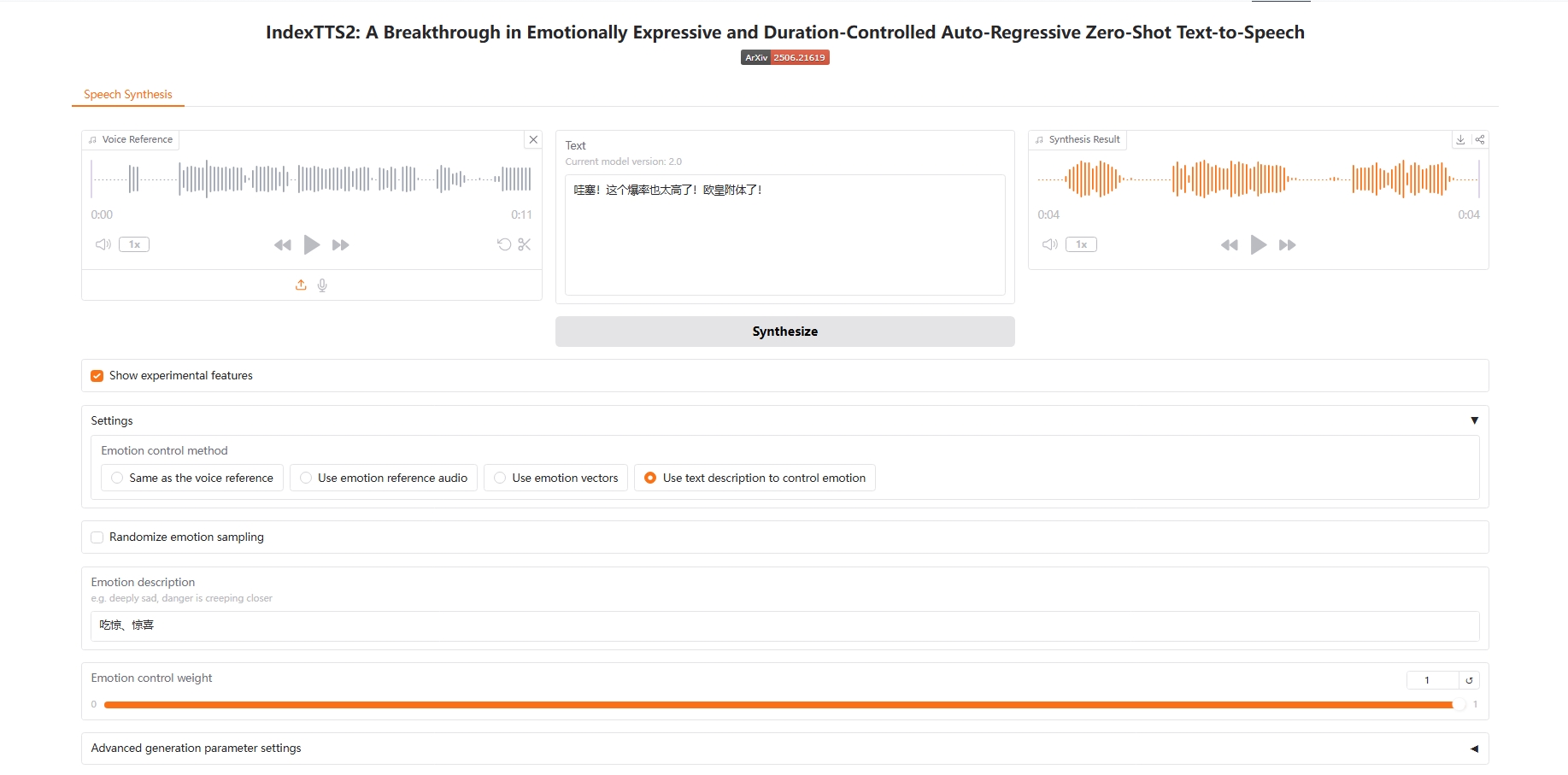
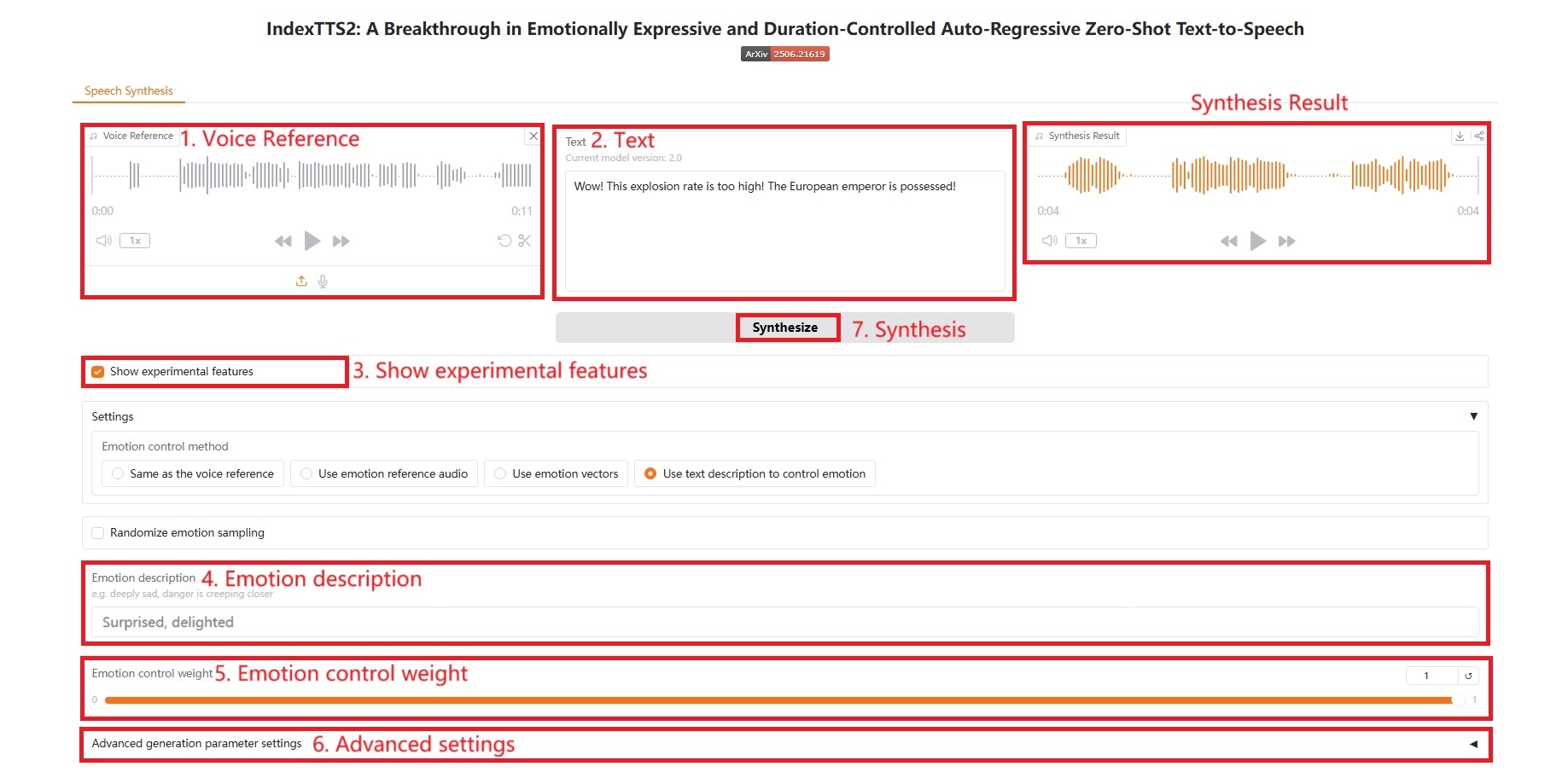
4. テキストの説明で感情をコントロールする
引用情報
このプロジェクトの引用情報は次のとおりです。
@article{zhou2025indextts2,
title={IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech},
author={Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, Jingchen Shu},
journal={arXiv preprint arXiv:2506.21619},
year={2025}
}
@article{deng2025indextts,
title={IndexTTS: An Industrial-Level Controllable and Efficient Zero-Shot Text-To-Speech System},
author={Wei Deng, Siyi Zhou, Jingchen Shu, Jinchao Wang, Lu Wang},
journal={arXiv preprint arXiv:2502.05512},
year={2025},
doi={10.48550/arXiv.2502.05512},
url={https://arxiv.org/abs/2502.05512}
}このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。