Command Palette
Search for a command to run...
Gemma 4 31Bは、最大256Kのコンテキストに対応し、ワンクリックでデプロイ可能。Qwen 3.5 397Bと同等の機能を備えています。

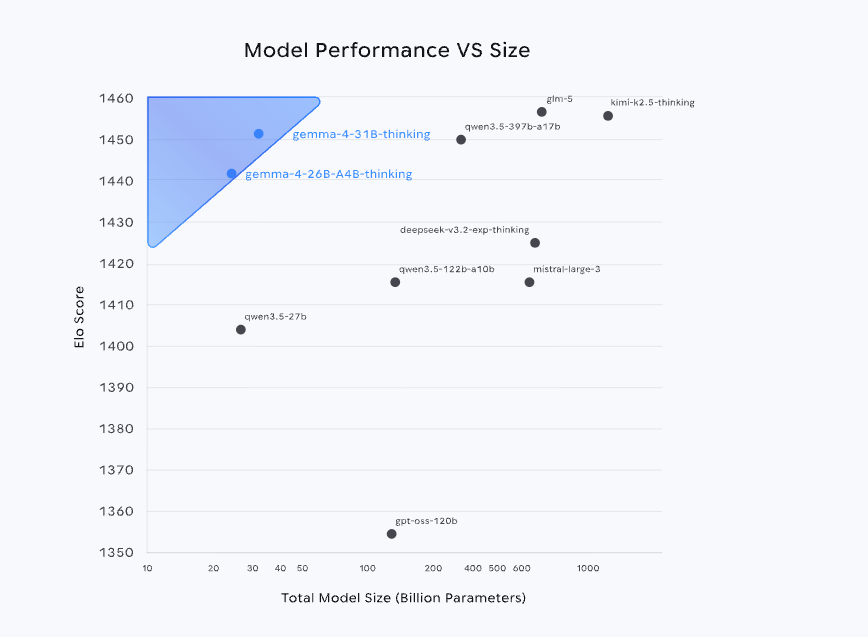
最近、Google DeepMindは、Gemma 4シリーズのモデルをオープンソース化した。Gemini 3と同じ技術システムを活用することで、Arena AIのランキングで世界トップ3に入るだけでなく、競合製品よりもはるかに少ないパラメータ規模で、より大規模なモデルに匹敵、あるいはそれを上回る性能を実現しています。さらに、Apache 2.0ライセンスに基づくオープンソース戦略により、導入のハードルがさらに下がり、実際の運用環境への展開可能性が大幅に向上しています。
製品形態の観点からGemma 4は単一モデルではなく、E2B、E4B、26B、A4Bから31Bまでの複数のサイズをカバーするマルチサイズシステムです。これらのモデルは、モバイルデバイス、ローカル展開、高性能コンピューティング環境など、さまざまなシナリオに対応できるように設計されています。この階層型設計の中核となる考え方は、「規模、性能、コスト」のバランスを取り、多様なニーズを満たすことです。小規模モデルは軽量性とリアルタイム性能を重視し、大規模モデルは複雑な推論と高精度タスクに重点を置いています。
中でも、現行シリーズの性能上限であるバージョン31Bは、Qwen 3.5 397Bに匹敵する能力を備えています。アプリケーションシナリオの観点からは、バージョン31Bは、画像とテキストの入出力に対応し、最大256Kトークンのコンテキストウィンドウを備え、推論、関数呼び出し、システムプロンプトをネイティブにサポートしています。また、140以上の言語に対応しているため、高品質な質問応答、コード支援、エージェントサービスなどのシナリオに最適です。
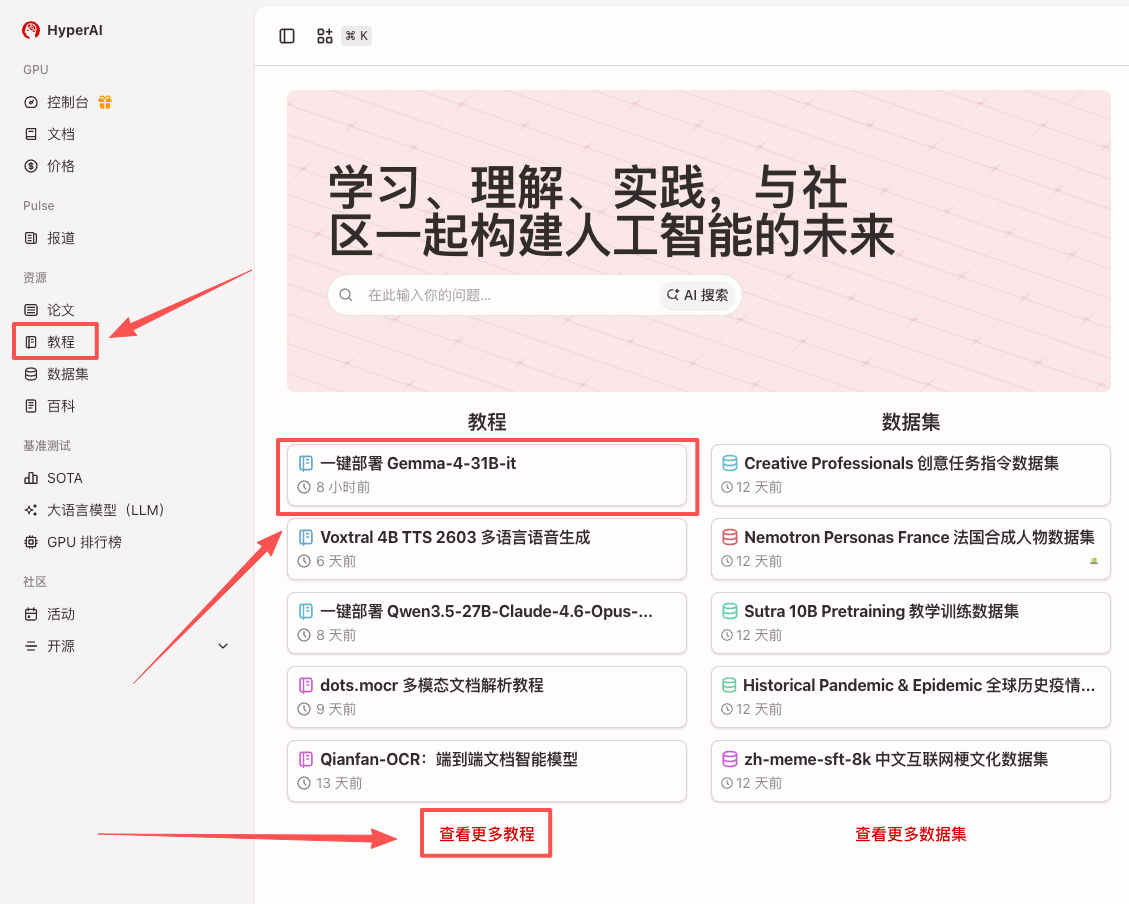
現在、HyperAIの公式サイト(hyper.ai)のチュートリアルセクションでは、開発者が低い参入障壁で高度なモデルを体験できるように、「Gemma-4-31B-itのワンクリック展開」を公開しています。
オンラインで実行:
デモの実行
1. hyper.ai ホームページにアクセスした後、「チュートリアル」ページを選択するか、「その他のチュートリアルを表示」をクリックし、「Gemma-4-31B-it のワンクリック展開」を選択して、「このチュートリアルを実行」をクリックします。
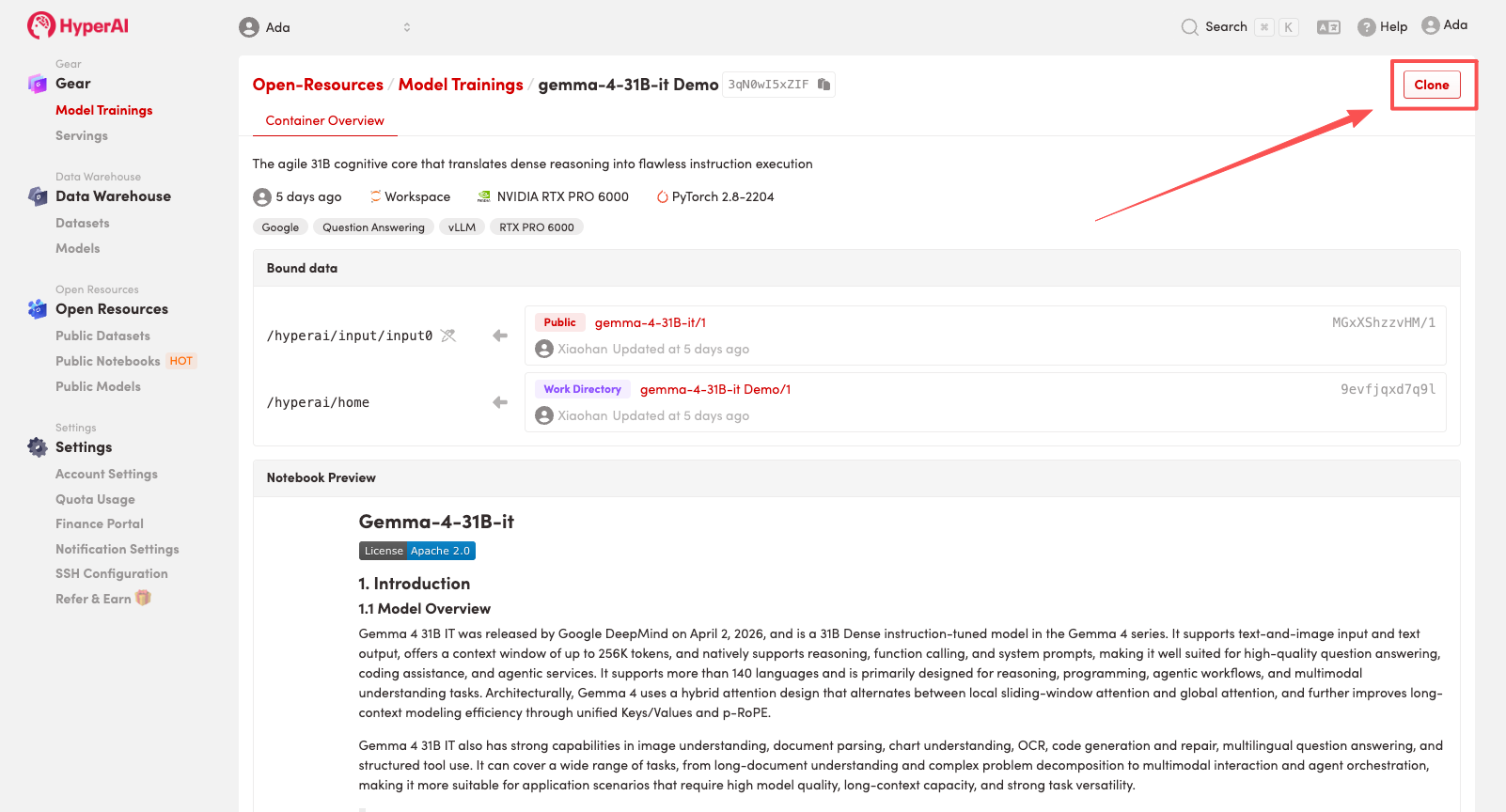
2. ページがリダイレクトされたら、右上隅の「複製」をクリックして、チュートリアルを独自のコンテナーに複製します。
注:ページの右上で言語を切り替えることができます。現在、中国語と英語が利用可能です。このチュートリアルでは英語で手順を説明します。
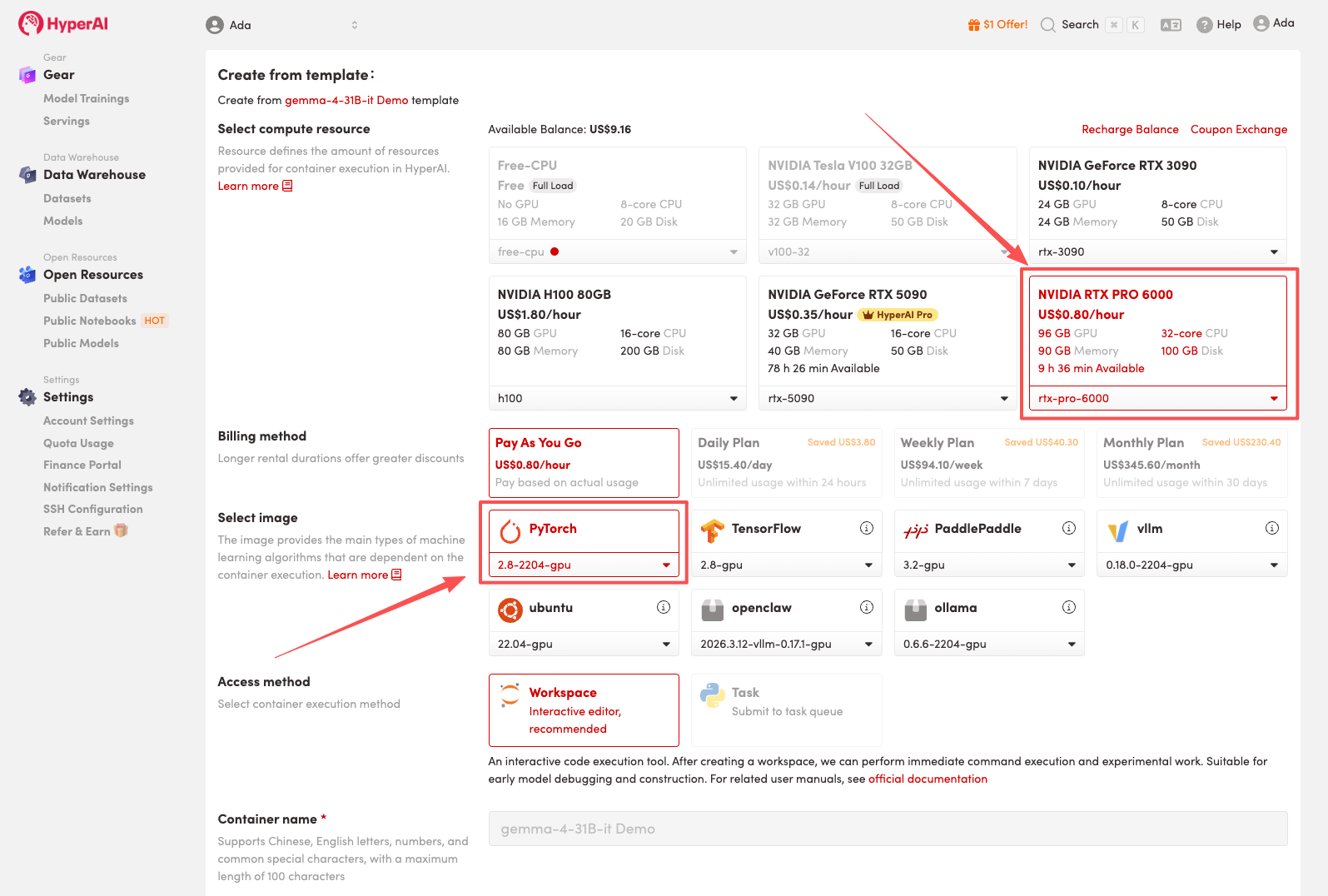
3. 「NVIDIA RTX PRO 6000」と「PyTorch」のイメージを選択し、「ジョブの実行を続行」をクリックします。
HyperAI は新規ユーザー向けに登録ボーナスを提供しています。わずか $1 で、RTX 5090 のコンピューティング パワー (元の価格は $7) を 20 時間利用でき、リソースは無期限に有効です。
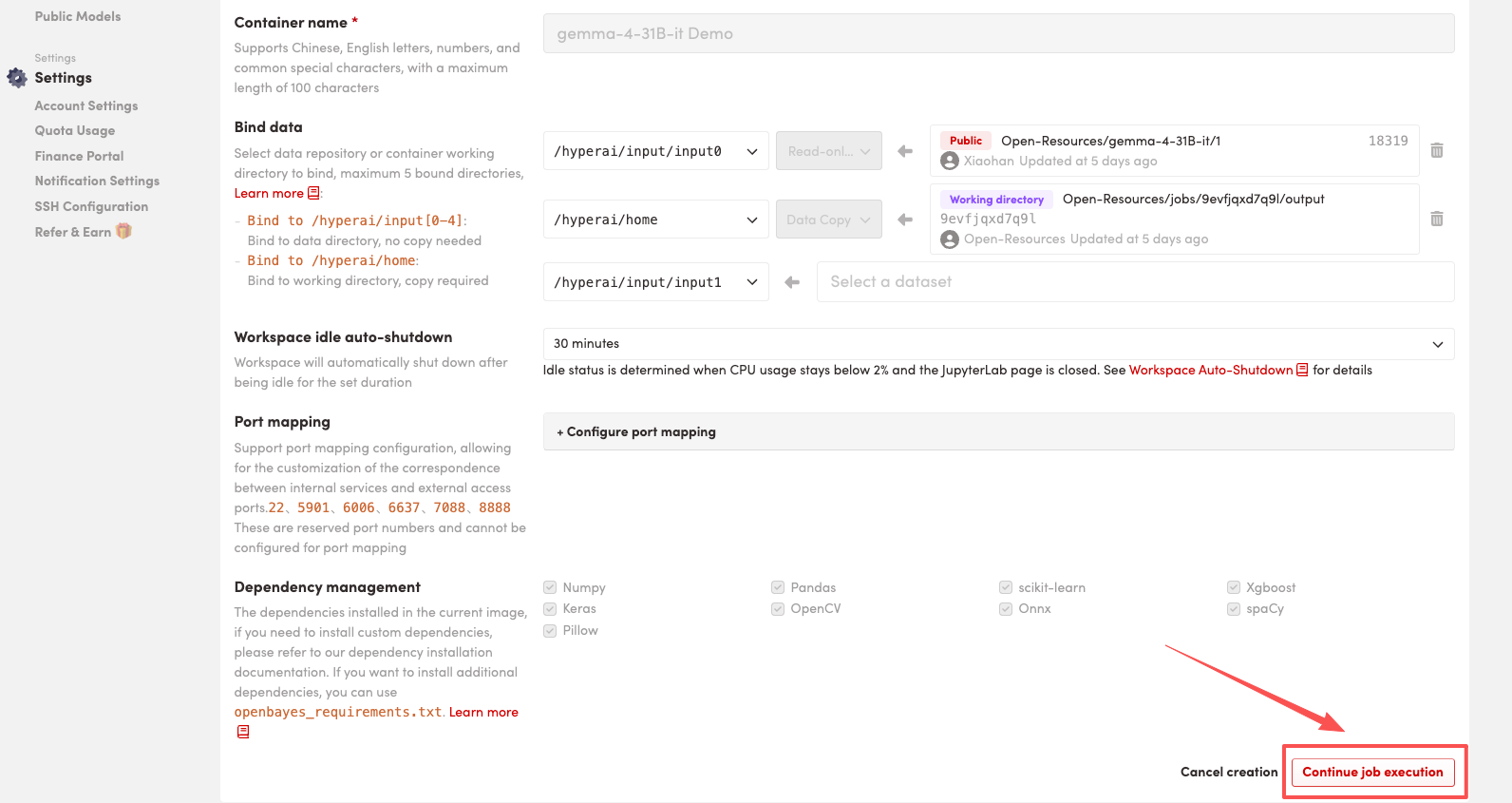
4. リソースが割り当てられるのを待ちます。ステータスが「実行中」に変わったら、「ワークスペースを開く」をクリックしてJupyterワークスペースに入ります。
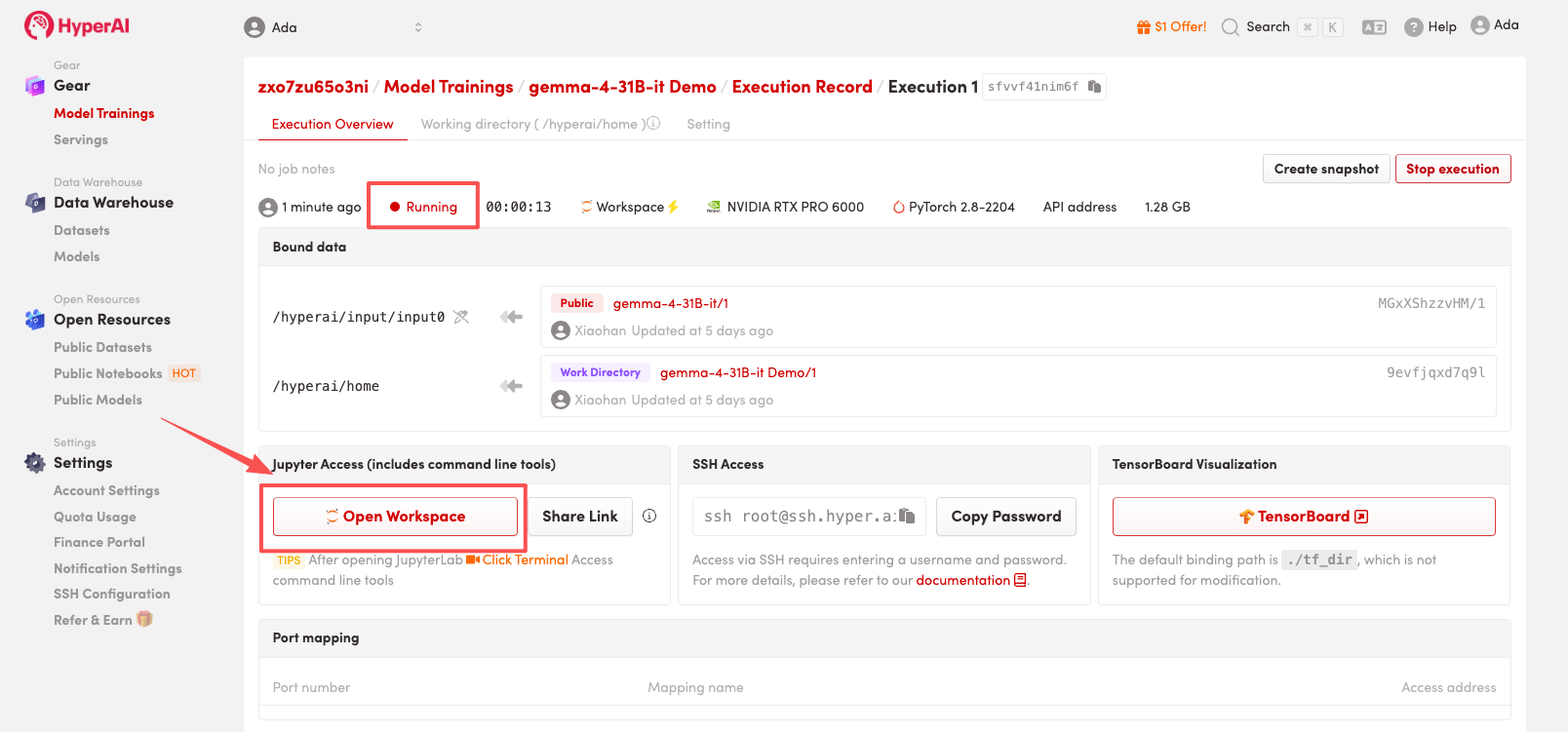
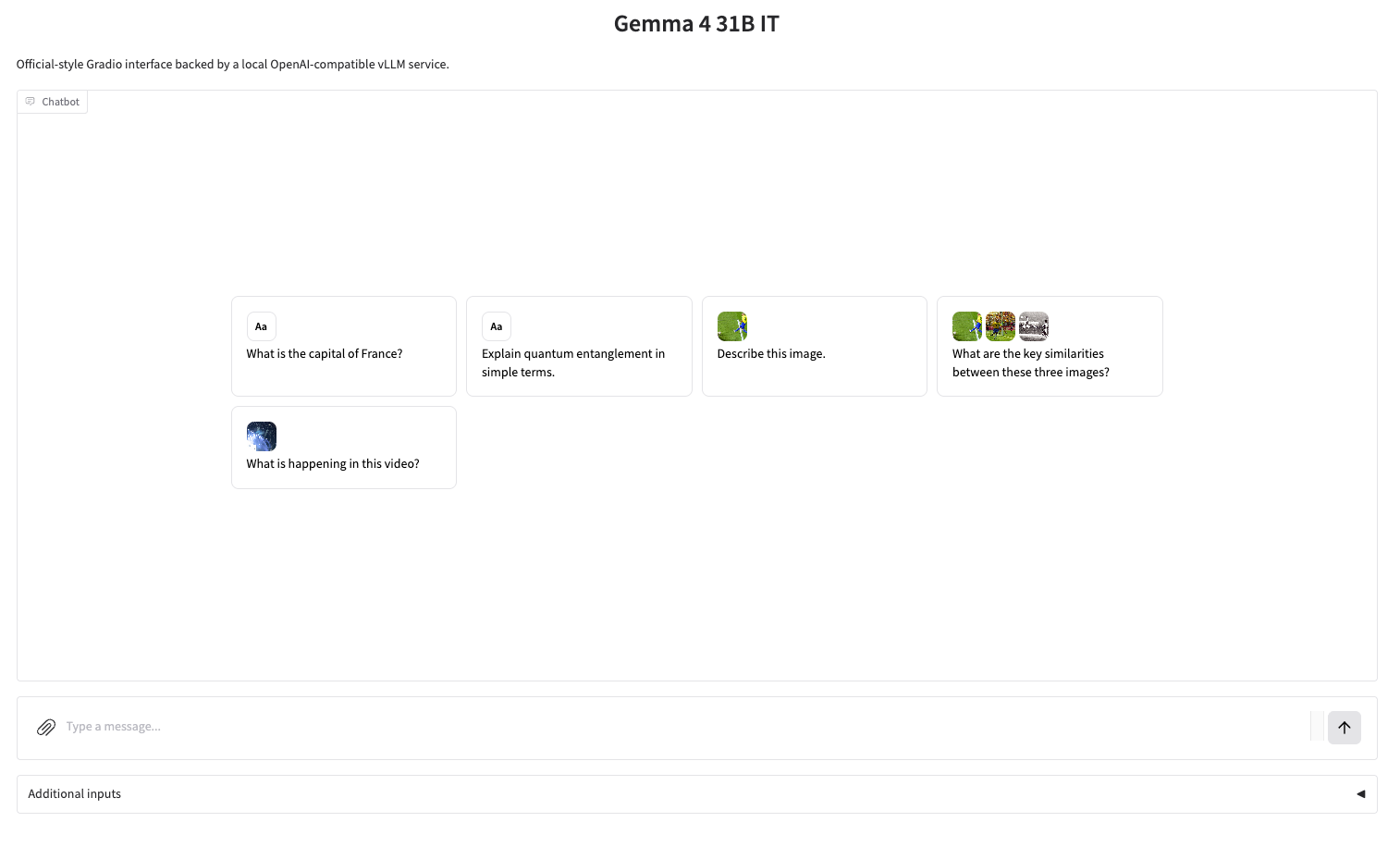
エフェクト表示
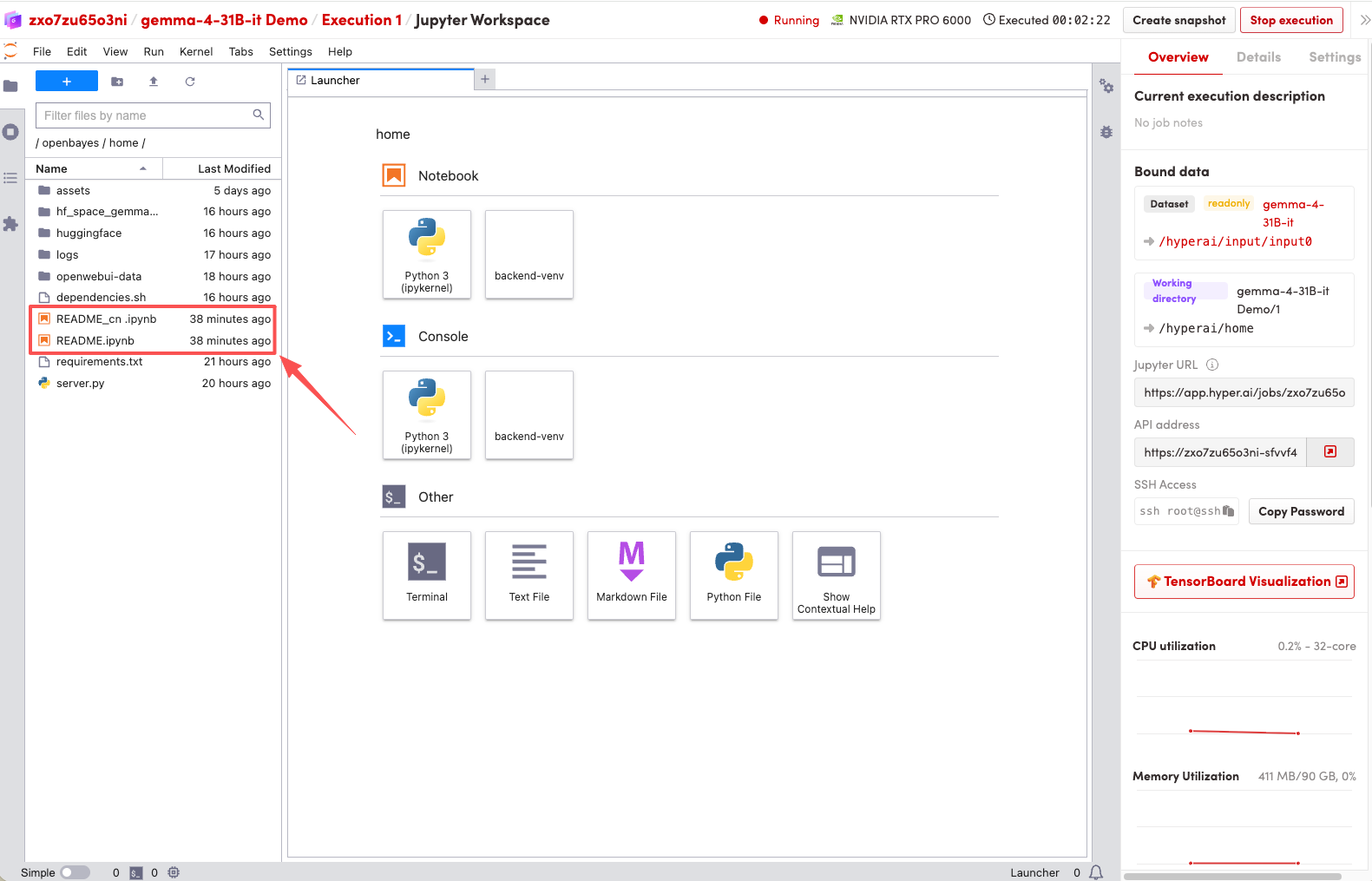
1. ページがリダイレクトされたら、左側のREADMEファイルをクリックし、上部の「実行」をクリックします。
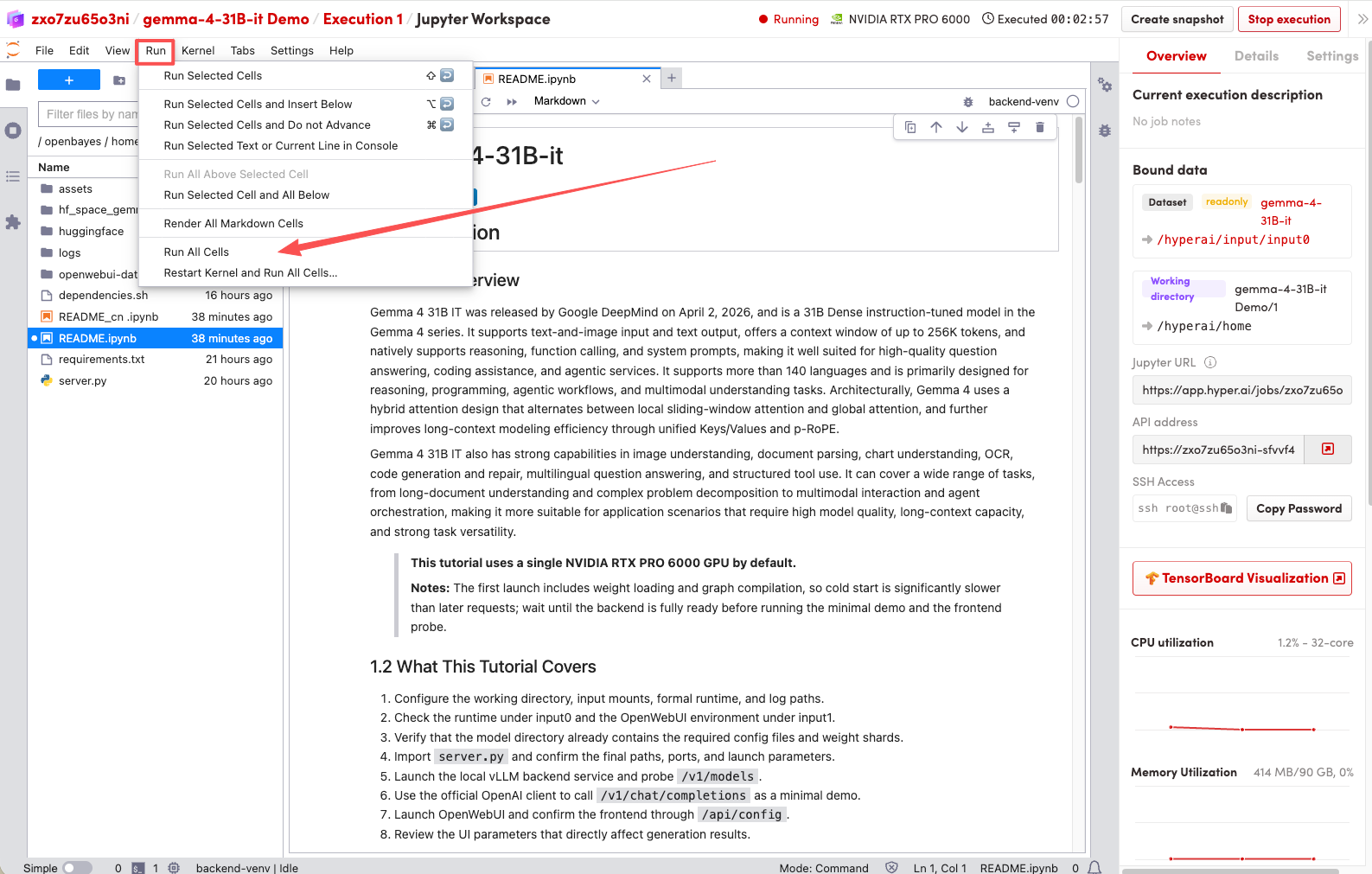
2. プロセスが完了したら、右側の API アドレスをクリックしてデモ ページに移動します。