Command Palette
Search for a command to run...
ACL 2025: オックスフォード大学などが医療用GraphRAGを提案、質問回答精度の新記録を樹立し、11のデータセットでSOTA結果を達成

医療分野の知識体系は、数千年にわたる発見と蓄積の上に構築されており、膨大な量の原理、概念、そして実践規範を網羅しています。この知識を現在の大規模言語モデルの限られたコンテキストウィンドウに効果的に適応させることは、克服できない技術的障害となります。教師あり微調整(SFT)は代替手段を提供しますが、ほとんどの商用モデルがクローズドソースであるため、このアプローチはコストがかかるだけでなく、実用的には非常に非現実的です。さらに、医療分野では用語の正確さと事実の厳密さに対する要求が非常に高くなっています。専門家以外のユーザーにとって、医療関連の回答に対する大規模モデルの精度を検証すること自体が非常に困難な作業です。そのため、大規模モデルが医療アプリケーションにおける複雑な推論のために大規模な外部データセットを活用し、検証可能なソースに裏付けられた正確で信頼できる回答を生成できるようにする方法は、この分野の現在の研究における中核的な課題となっています。
検索強化生成 (RAG) テクノロジの出現により、上記の問題を解決するための新しいアプローチが提供されます。モデルをさらにトレーニングすることなく、特定のデータセットまたはプライベートデータセットを使用してユーザーのクエリに応答できます。しかし、従来のRAGは、新たな洞察を統合したり、幅広い文書の包括的な理解を必要とするタスクを処理したりするという点では、依然として不十分です。最近提案されたGraphRAGは、LLMを活用して生の文書から知識グラフを構築し、そのグラフに基づいて知識を取得して回答を強化することで、複雑な推論において従来のRAGを大幅に上回ります。しかし、GraphRAGのグラフ構築には、回答の真正性と信頼性を確保するための具体的な設計が欠けており、階層的なコミュニティ構築プロセスは汎用性が高いためコストが高く、医療分野に直接的かつ効果的に適用することは困難です。
この状況に対処するため、オックスフォード大学、カーネギーメロン大学、エディンバラ大学の共同チームが、医療分野に特化したグラフベースのRAG手法、Medical GraphRAG (MedGraphRAG)を提案しました。この方法は、証拠に基づく回答と公式の医学用語の説明を生成することで、医療分野における LLM のパフォーマンスを効果的に向上させ、回答の信頼性を高めるだけでなく、全体的な品質を大幅に向上させます。
「Medical Graph RAG: グラフ検索拡張生成による安全な医療用大規模言語モデルの構築」と題された関連研究成果が ACL 2025 に選出されました。
研究のハイライト:
* この研究では、医療分野に特化したTukey RAGフレームワークを初めて提案しました。
* この研究では、大規模言語モデル (LLM) が RAG データ全体を効率的に活用し、証拠に基づく回答を生成できるように、独自のトリプルグラフ構築と U 検索手法を開発しました。
* MedGraphRAG は、複数の医療質問回答ベンチマークにおいて、他の検索方法や微調整された医療特有の大規模言語モデルよりも優れたパフォーマンスを発揮します。
用紙のアドレス:
AIフロンティアに関するその他の論文:
3種類のデータに基づく研究
この研究で使用されるデータは 3 つのカテゴリに分かれており、各タイプの特徴は研究での役割に応じて異なります。
* RAGデータ
ユーザーは頻繁に更新される個人データ(患者の電子医療記録など)を使用する可能性があることを考慮して、実際のアプリケーションで動的に変化する個人データのシナリオをシミュレートし、方法の実用性を検証するための基礎を提供できる公開電子医療記録データセット MIMIC-IV を選択しました。
* リポジトリデータ
このデータセットは、大規模モデルの回答に信頼できる情報源と権威ある語彙定義を提供するために使用されます。上位レベルのリポジトリデータはMedC-Kで、480万件の生物医学学術論文、3万冊の教科書、そしてFakeHealthとPubHealthのすべてのエビデンス出版物が含まれています。その内容は広範囲にわたり、学術的に権威があります。基盤となるリポジトリデータはUMLSグラフで、医学用語の正確性を確保するための権威ある医学語彙と意味関係が含まれています。
* テストデータ
このデータセットは、MedGraphRAG法のパフォーマンスを評価するために使用され、MultiMedQA(MedQA、MedMCQA、PubMedQA、MMLU臨床トピックなどを含む)の9つの多肢選択式バイオメディカルデータセットのテスト部分を含み、日常的な医学的質問への回答におけるこの方法のパフォーマンスをテストするために使用されます。2つの公衆衛生事実検証データセットFakeHealthとPubHealthは、この方法のエビデンスに基づく回答能力を評価するために使用されます。さらに、この研究では、希少疾患や少数民族の健康など、幅広いトピックを網羅し、健康の公平性に焦点を当てた50の実際の臨床質問を含むDiverseHealthテストセットも収集し、評価の側面をさらに豊かにすることができます。
MedGraphRAG: スライディングウィンドウ分割、ラベルクラスタリング、U検索に基づく
以下の図に示すように、MedGraphRAG の全体的なワークフローには、主に次の 3 つのコアリンクが含まれます。ドキュメントに基づいてナレッジ グラフを構築し、検索をサポートするためにグラフを整理して要約し、データを取得してユーザーのクエリに応答します。
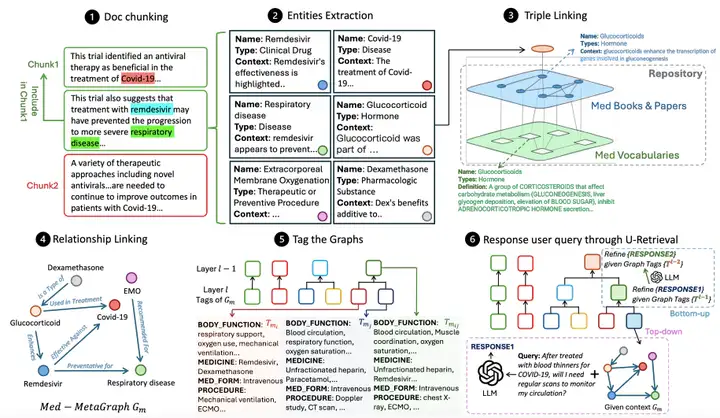
Medical Graph Construction では、まずセマンティック ドキュメント チャンクを実行し、ドキュメントを LLM コンテキスト制約に準拠するデータ チャンクに分割します。この研究では、文字の分離とトピックの意味的セグメンテーションを組み合わせたハイブリッド手法を採用しています。つまり、最初に改行によって段落を分離し、次にグラフを通じて LLM LG を構築して段落と現在のブロック間のトピックの関連性を判断し、ブロックを分割するかどうかを決定します。同時に、ノイズを減らすために 5 セグメントのスライディング ウィンドウが導入され、セマンティック ロジックとモデル コンテキスト制約の両方を考慮して、LG タグ制限がブロック分割のハードしきい値として使用されます。
ブロック分割後、エンティティ抽出プロセスに入ります。LGのエンティティ抽出プロンプトの助けを借りて、各ブロックから関連するエンティティが識別され、名前、タイプ、コンテキストの説明を含む構造化された出力が生成され、後続のエンティティリンクの作成準備が整います。トリプルリンクは正確性を保証する鍵です。リポジトリ グラフ (RepoGraph) は、ユーザーの RAG ドキュメントを信頼できるソースにリンクするために構築されます。最下層は、医学用語と関係性を含む UMLS グラフ (Med Vocabularies) で、上層は医学の教科書と学術論文 (Med Books & Papers) から構築されます。次に、研究者は RAG ドキュメントから抽出したエンティティを E1 として定義します。エンティティ間の相関関係に基づいて、これらのエンティティは、医学書または論文から抽出されたエンティティ E2 にリンクされます。E2 はさらに UMLS エンティティ E3 にリンクされ、[RAG エンティティ、ソース、定義] の 3 重構造が形成され、各エンティティが明確なソースと標準的な定義にまで遡ることができるようになります。次に、関係性のリンクが実行されます。関係性認識ヒントを含む LG は、エンティティの内容と参照に基づいて RAG エンティティ間の関係性を識別し、ソース エンティティ、ターゲット エンティティ、および関係性の説明を含むフレーズを生成します。最後に、各データ ブロックに対して有向メタ医療グラフが生成されます。
グラフを構築した後、検索効率を向上させるためにグラフにタグを付ける必要があります。GraphRAGのコストのかかるグラフコミュニティ構築アプローチとは異なり、この手法は医療テキストの構造化特性を活用し、各メタ医療グラフを定義済みラベル(症状、病歴、身体機能、投薬など)を用いて要約し、構造化されたラベルサマリーを生成します。次に、ラベルの類似性に基づく動的閾値凝集型階層的クラスタリングを用いてグラフをグループ化し、より抽象的で包括的なラベルサマリーを生成します。まず、各グラフは独立したグループとして扱われます。クラスターペア間のラベル類似性は反復的に計算され、最も類似性の高い上位20%のクラスターペアがマージされて、新しいラベルサマリーレイヤーが生成されます。このプロセスは12レイヤーに制限されており、精度と効率性のバランスが取れています。
最後の U 検索ステージでは、LLM LR に応答することで効率的なクエリ応答を実現します。まず、LRはユーザークエリのラベルサマリーを生成します。トップダウンの精度検索により、最上位ラベルから順に、最も類似するラベルをレイヤーごとに照合し、対象となるメタメディカルグラフを特定します。クエリとエンティティコンテンツ間の埋め込み類似性に基づいて、上位ランクのエンティティとその最も近いトリプレットを取得し、これらのエンティティと関係性を用いて初期回答を生成します。次に、ボトムアップの回答精緻化フェーズが開始されます。LRは、前のレイヤーのラベルサマリーに基づいて回答を調整します。このプロセスは、ターゲットレベル(通常4~6レイヤー)に到達するまで繰り返され、最終的にグローバルコンテキスト認識と検索効率のバランスが取れた回答を生成します。
MedGraphRAG: 6つのモデルと11のデータセットで検証され、SOTAを達成
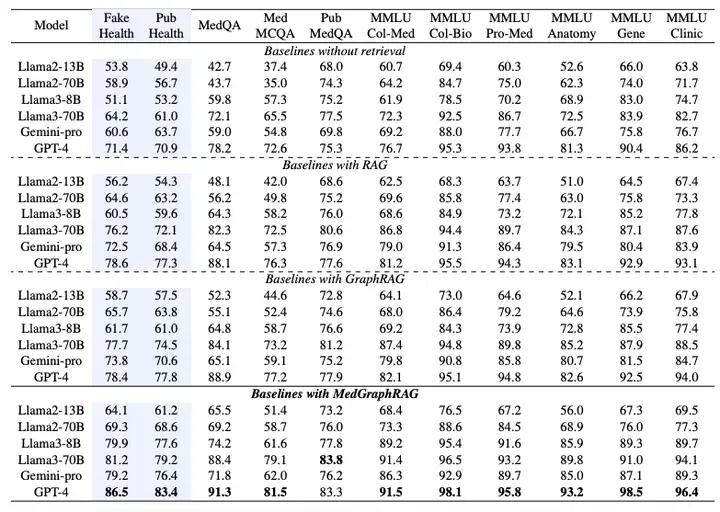
MedGraphRAG のパフォーマンスを検証するために、この研究では 6 つの大規模言語モデルを選択し、Llama2 (13B、70B)、Llama3 (8B、70B)、Gemini-pro、GPT-4 を含む複数の実験セットを設計しました。主な比較は、LangChain によって実装された標準 RAG と、Microsoft Azure によって実装された GraphRAG との比較です。すべてのメソッドは同じ RAG データとテスト データで実行されます。
下の表に示すように、多肢選択評価のパフォーマンスは、正しい選択肢を選択する正確さによって測定されます。実験結果では、MedGraphRAG が、検索機能のないベースライン、標準 RAG、GraphRAG よりも大幅に優れていることが示されています。検索なしのベースラインと比較すると、ファクトチェックで平均約101 TP3T、医療質問回答で約81 TP3Tの改善を達成しました。GraphRAGと比較すると、ファクトチェックで約81 TP3T、医療質問回答で約51 TP3Tの改善を達成しました。この改善は、Llama2 13Bなどの小規模モデルではさらに顕著であり、モデルの推論機能と外部知識の効果的な統合を示しています。Llama70BやGPT-4などの大規模モデルに適用した場合、11のデータセットで最先端のパフォーマンスを達成し、Med-PaLM 2やMed-Geminiなどの医療コーパスで微調整されたモデルを凌駕し、医療LLMリーダーボードで新たな最先端のパフォーマンスを確立しました。
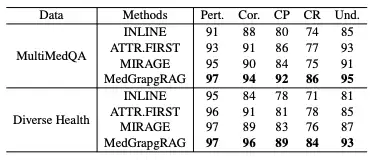
長編世代評価では、この研究では、関連性、正確性、引用精度、引用再現率、MultiMedQA および DiverseHealth ベンチマークにおける理解可能性という 5 つの側面で MedGraphRAG を Inline Search や ATTR-FIRST などのモデルと比較しました。結果は以下の表に示されています。MedGraphRAGは、エビデンスに基づいた回答と医学用語の明確な説明により、すべての指標、特に引用精度、再現率、理解度において高いスコアを獲得しました。
ケーススタディでは、慢性閉塞性肺疾患(COPD)と心不全という複雑な症例に直面しましたが、GraphRAGの推奨は薬剤が心不全に与える影響を無視していました。一方、MedGraphRAGは安全な薬剤を推奨することができました。これは、GraphRAGのエンティティと参照が直接リンクされているためであり、GraphRAG内で情報が複雑に絡み合うことで生じる重要な情報の欠落を回避できました。
ナレッジグラフと大規模言語モデルの統合
医療と人工知能の交差点において、ナレッジグラフと大規模言語モデルの統合は、技術革新を促進するための重要な方向性となり、医療分野の複雑な問題を解決するための新しいアイデアを提供しています。
例えば、ケンブリッジ大学とオックスフォード大学の共同チームが提案したKG4Diagnosisフレームワークでは、階層型マルチエージェントアーキテクチャを通じて現実世界の医療システムをシミュレートし、知識グラフを組み合わせて診断推論機能を強化し、362 種類の一般的な疾患の自動診断と治療計画をカバーします。復旦大学の研究チームは、ヒトの健康と疾患に関わるプロテオームを包括的にマッピングしました。53,026人の血漿プロテオームデータを、平均14.8年間の追跡期間にわたって詳細に解析した結果、2,920種類の血漿タンパク質、406種類の既存疾患、追跡期間中に新たに発現した660種類の疾患、そして986種類の健康関連表現型が網羅されました。数多くのタンパク質と疾患、タンパク質と表現型の関連性を発見し、精密医療と新薬開発のための重要な基盤を提供します。
Google DeepMindが立ち上げたAMIEシステムジェミニ大規模モデルの長期文脈推論機能を知識グラフと統合し、臨床ガイドラインと薬剤知識ベースを動的に検索することで、複数の診断事例にわたって一貫した管理計画を作成できます。例えば、慢性閉塞性肺疾患(COPD)と心不全を併発している患者には、心臓選択性β遮断薬を正確に推奨することで、従来のAIシステムに伴う薬物相互作用のリスクを回避できます。
アストラゼネカが構築したバイオメディカルナレッジグラフは、300万件の文書と社内研究データを統合し、薬剤-標的-疾患関連ネットワークを分析することで新薬候補のスクリーニングを加速します。このマップには、承認された医薬品の適応症だけでなく、臨床試験における「適応外使用」データも含まれています。既存薬の転用に関する意思決定支援を提供します。さらに、IBM Watson Healthのナレッジグラフ・プラットフォームは、10億件の患者データとエビデンスに基づくガイドラインを統合し、遺伝子検査、薬剤感受性予測、フォローアップ計画を含む個別化された肺がん治療計画を作成し、患者の生存率の予測誤差を±2.3か月にまで低減します。
これらの革新的な実践は、医療AI技術の反復的なアップグレードを推進するだけでなく、診断精度の向上、医薬品開発の加速、臨床意思決定の最適化において大きな可能性を示しています。技術が成熟するにつれて、ナレッジグラフと大規模言語モデルの統合は医療分野における情報障壁をさらに打ち破り、世界のヘルスケアの発展に持続的な推進力をもたらすでしょう。
参考記事:
1.https://mp.weixin.qq.com/s/WhVbnoso2Jf2PyZQwV93Rw
2.https://mp.weixin.qq.com/s/RWy4taiJCu3kMPfTzOWYSQ
3.https://mp.weixin.qq.com/s/lMLk








