Command Palette
Search for a command to run...
香港科技大学などは、75% によってパラメータを簡素化しながらも SOTA 性能を達成した増分天気予報モデル VA-MoE を提案しました。

社会活動や防災上の意思決定に影響を与える重要な分野である気象予報は、複雑で絶えず変化する大気システムによって常に大きな課題に直面してきました。予報能力の向上は、人類の生産と生活に深く根ざしています。数値気象予報(NWP)は、この分野で長年主流のアプローチとなっています。数値気象予報は、大気力学方程式に基づき、偏微分方程式を解くことで気温、気圧、風速などの主要変数の変動をシミュレートし、気象システムの数値的推論を実現します。
近年、人工知能技術の飛躍的な進歩により、ディープラーニングは強力な時空間パターン認識能力を備え、気象モデリングにおいて大きな可能性を示しています。これにより、「気象のための人工知能(AI4Weather)」という新たな学際分野が誕生しました。しかし、既存のAI気象モデルのほとんどは、学習と予測の過程ですべての気象変数を同時に取得できるという理想的な仮定に基づいています。これは、データソースが多様でデータ収集頻度も変動する実際の観測状況とは大きく矛盾しています。例えば、高高度の気温は衛星やラジオゾンデに依存しており、更新が遅いのが現状です。一方、地上降水量や風速は、人口密度の高い観測所でリアルタイムに観測されています。こうしたデータの非同期性により、新しい変数が導入されるたびにモデルを完全に再学習する必要があり、計算コストが非常に高くなります。
この課題に対処するために、香港科技大学、浙江大学などの研究チームは、「増分天気予報(IWF)」の新しいパラダイムを設計し、「可変適応型専門家混合(VA-MoE)」を立ち上げました。このモデルは、段階的な学習と変数インデックス埋め込みメカニズムを用いて、様々なエキスパートモジュールを特定の気象変数に焦点を絞るよう誘導します。新しい変数や観測所が追加されても、モデルは完全な再学習を行うことなく拡張できるため、計算オーバーヘッドを大幅に削減しながら精度を確保できます。
「VA-MoE: 増分天気予報のための変数適応型専門家混合」と題された関連研究成果は、コンピュータービジョン分野の最高峰の国際会議である ICCV25 に採択されました。
研究のハイライト:
* 気象予報における漸進的学習のための新しいパラダイムの初めての体系的な探究であり、モデルの拡張性と一般化能力の定量的な評価のベンチマークを確立する。
* 変数インデックス埋め込みによって駆動されるコンテキスト変数の活性化を通じて専門家の特化を実現する、増分大気モデリング専用に設計された最初のフレームワークであるVA-MoEを提案する。
* ERA5データセットに基づく大規模実験では、データサイズが半分になり、パラメータ数が25%に削減された場合、VA-MoEは高高度変数の予測において類似のモデルを大幅に上回る性能を示すことが示されています。

用紙のアドレス:
https://arxiv.org/abs/2412.02503
公式アカウントをフォローし、「VA-MoE」と返信すると、PDF全文を入手できます。
AIフロンティアに関するその他の論文:
ERA5データセットにおける上空変数と地上変数の分割
本研究では、欧州中期予報センター(ECMWF)が公開した主流大気再解析データセットERA5を実験基盤として用い、1979年から現在までの連続気象観測データを網羅しています。従来の実験では0.25°の空間解像度(グリッドサイズ721×1440に相当)を使用していますが、アブレーション実験のみ、計算複雑性を抑制するため、1.5°解像度バージョン(グリッドサイズ128×256)を使用し、様々な実験シナリオにおけるデータ適応性と計算効率のバランスを確保しています。
時間の次元から、データセットは実験のさまざまな段階に明確に割り当てられます。
* 初期のトレーニング段階では、1979年から2020年までの40年間のデータを使用して、モデルの基本的な気象知識蓄積の基礎を築きます。
* 増分トレーニングフェーズでは、2000 年から 2020 年までの 20 年間のデータを使用して、新しい変数の導入後のパラメータ最適化要件に適応します。
* テスト段階では、2021 年全体の気象変数データが選択され、独立したデータを使用して、未知のサンプルに対するモデルの一般化能力を検証し、データ漏洩が結果の信頼性に与える影響を回避しました。
* 変数の構成に関しては、下の図に示すように、実験には 5 つの上空変数と 5 つの表面変数が含まれます。
* 上層大気変数:これらには、Z(ジオポテンシャル高度)、Q(比湿)、U(東西風速)、V(南北風速)、T(気温)の5種類が含まれます。各種類は13の異なる気圧層で定義されており、主に初期のモデルトレーニング段階で使用され、大気力学モデリングの中核機能を構築します。
* 地上変数:2メートル気温T2M、10メートル東風速U10、10メートル南風速V10、平均海面気圧MSL、地表気圧SPなどが、モデルの第2段階(増分トレーニング段階)で増分変数として導入され、実際の観測における変数の動的拡大のシナリオをシミュレートします。
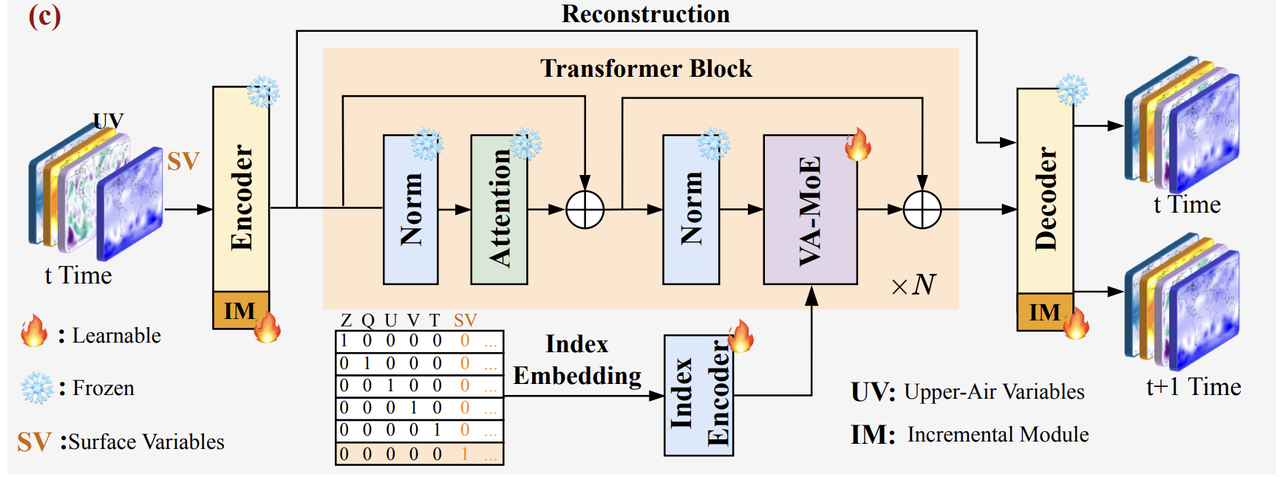
VA-MoE: 増分学習のための可変適応型気象予報モデルアーキテクチャ
VA-MoE のコアとなる動作ロジックは、「2 段階トレーニングパラダイム」を中心に展開されます。下図に示すように、実際の観測における「データの段階的な拡張」シナリオを完全にシミュレートします。第 1 段階は「初期段階」であり、高高度変数のみを使用してモデルをトレーニングし、モデルがまず上層大気の中核となる力学法則を把握できるようにします。第 2 段階は「増分段階」であり、第 1 段階でトレーニングされたパラメータを固定したまま地上ベースの変数を追加し、新しい変数に対して新たに追加されたモジュールのみをトレーニングして、最終的に完全なモデルを形成します。

アーキテクチャの観点から見ると、下の図に示すように、VA-MoE は Transformer をコアバックボーンとして使用していますが、気象データのマルチスケールおよび強い相関特性に対して重要な最適化を行っています。モデルが入力データを処理する際、エンコーダによって抽出された入力特徴は、まず正規化層と自己注意層を通過します。自己注意層の出力は残差接続と融合され、さらに別の正規化層を通過した後、VA-MoEコアモジュールに入力され、変数適応計算が行われます。深層ネットワークの学習中に「勾配消失」によって生じる知識ギャップを回避するため、このフレームワークは「残差接続」メカニズムも統合しています。各計算ステップの後に、一部の元の特徴が保持されるため、高レベルネットワークは下位層で抽出された基本的な気象情報(地形が地表付近の風速に与える影響など)を効果的に継承することができ、長期気象系列のモデリング安定性を大幅に向上させます。
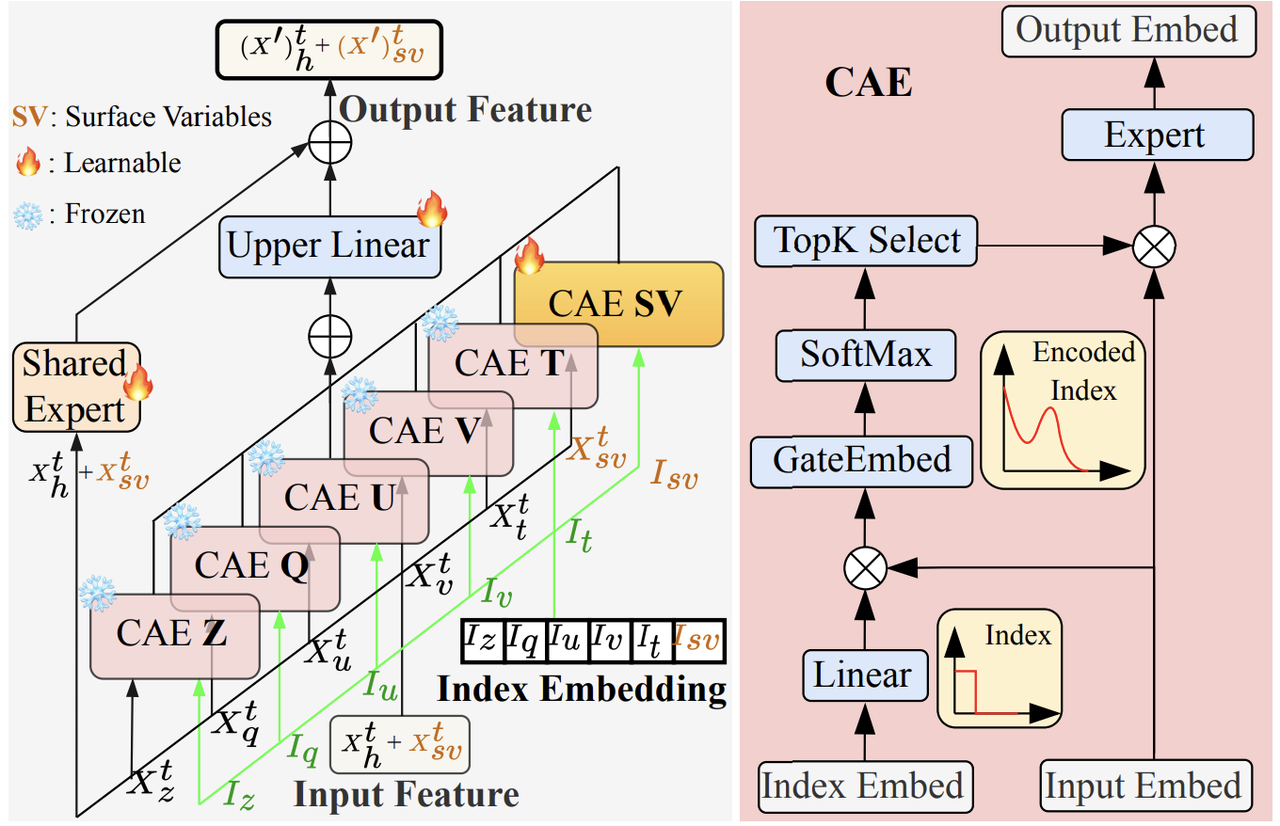
トレーニング最適化レベルでは、VA-MoE は予測精度と物理的な一貫性のバランスをとるために「マルチタスクジョイントロス」メカニズムを採用しています。このメカニズムは、2つのコアコンポーネントで構成されています。1つは動的予測損失で、変数の物理的特性に基づいて重みを最適化します。気温や風速など、変化の速い変数には高い重みが与えられ、過渡的な変化を捉える能力が向上します。一方、ジオポテンシャル高度など、変化の遅い変数については、長期的な予測の安定性を維持するために、重みを段階的に調整することで、従来のモデルにしばしば伴う重要な動的特性の損失を克服します。さらに、このモデルは、補助タスクとして再構成損失を導入します。エンコーダー・デコーダー構造を通じて、モデルは予測タスクを実行する前に、まず元の気象場を正確に復元し、その過程で大気のエネルギーと質量の保存則などの重要な特性を学習する必要があります。
これを踏まえて、下の図に示すように、このモデルは、「専門化 + コラボレーション」のエキスパート システムを構築します。トレーニングフェーズにおける5つのコア変数(Z500、気温、風速など)については、変数ごとに独立した「チャネル適応型エキスパート(CAE)」が設定されます。例えば、気温CAEは気温の時空間的変化にのみ焦点を当て、気温の「アイデンティティタグ」を主要な特徴(日内気温差や前線通過時の急激な気温変化など)のスクリーニングに活用することで、特化型モデリングによって単変数予測の精度を向上させます。さらに、「共有エキスパート」モジュールは、すべてのCAEから出力されるローカル情報を統合し、複数の変数間のシステムレベルの相関関係(気温上昇→気圧低下→風速上昇の連鎖反応など)を捉えます。これにより、過度な特化による「木を見て森を見ず」を回避し、モデルが大気システム全体の動的挙動を復元できるようになります。
VA-MoE パフォーマンス検証: 主流モデルに匹敵する精度と、大幅な増分学習の利点
研究チームは、VA-MoE の天気予報における実際の有効性を体系的に評価するために、「精度、効率、拡張性」という 3 つの側面に重点を置き、実際の気象データに基づく完全な実験システムを構築しました。
実験の核心は、VA-MoEを現在主流の9つの気象AIモデル(Pangu-Weather、GraphCast、ClimaXなどを含む)と比較することです。これらのモデルには、500hPaジオポテンシャル高度Z500、10メートル東風速度U10、850hPa気温T850、2メートル気温T2Mなどが含まれており、5日間の予測性能を評価することに重点を置いています。主な違いはトレーニングロジックにあります。比較対象モデルは主に、「高高度変数と地上変数の1回限りの共同トレーニング」という従来の手法を採用しています。VA-MoEは「まず高高度、次に地上」という2段階の漸進戦略を採用し、可変拡張における優位性を強調しています。
予測精度に関しては、下図に示すように、VA-MoEは地上および高層気象の両方で優れた予測性能を示しています。T2MやU10などの主要な地上気象変数については、VA-MoEの予測精度はStormerやGraphCastに匹敵し、ClimaXやFourCastNetなどのモデルを大幅に上回り、短期予測と長期予測の両方で安定性を維持しています。V10や海面気圧(MSL)などの変数に拡張すると、VA-MoEの優位性はさらに顕著になり、T2MのみGraphCastにわずかに遅れをとり、FengWuやFuXiなどの主流モデルと同等の精度となっています。
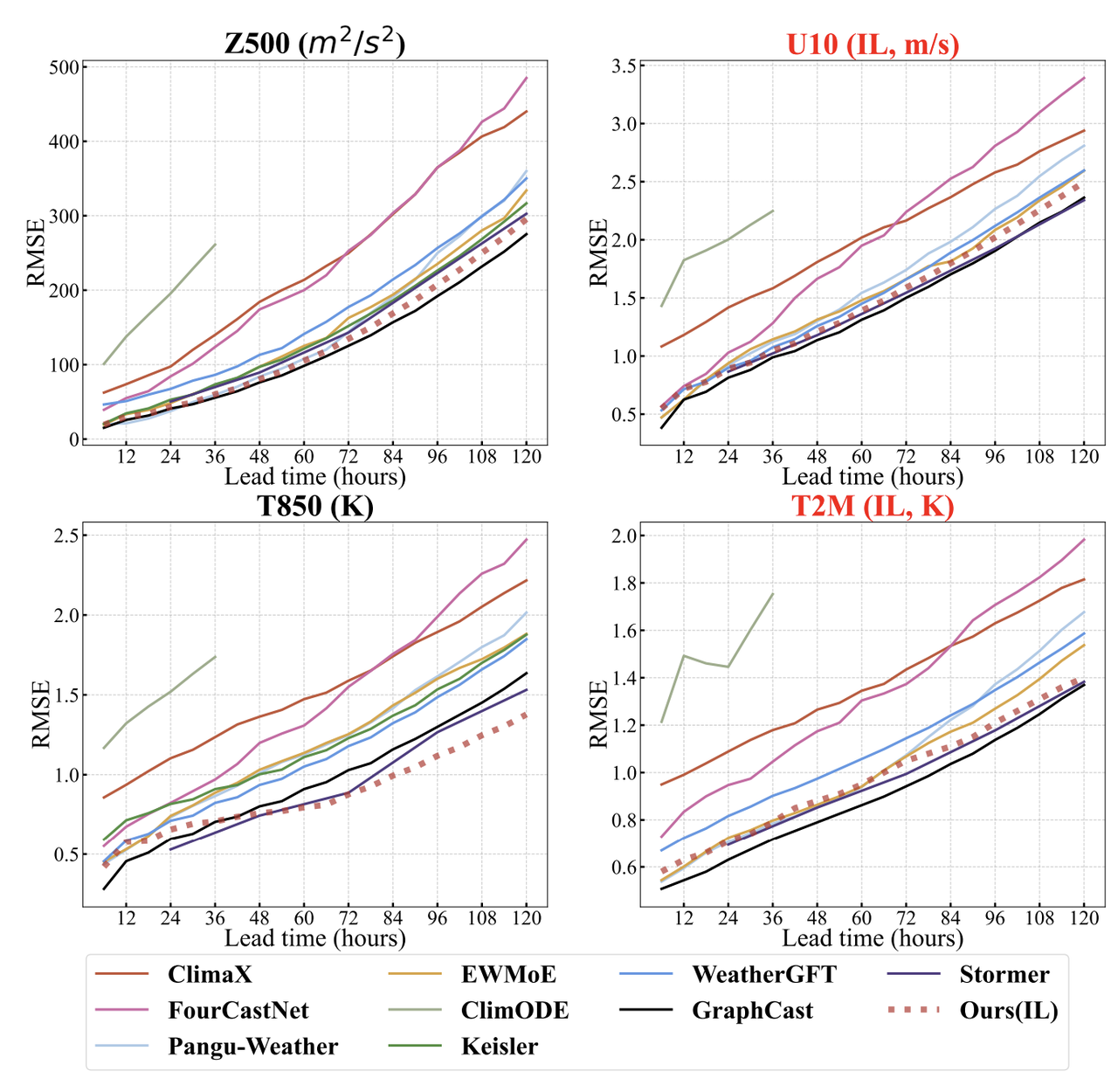
トレーニングの効率性に関しては、40 年分のデータに基づいて増分モードでトレーニングされた VA-MoE は、標準的な反復回数の半分だけで同様の精度を達成できます。データが 20 年に短縮され、反復回数が 4 分の 1 に削減された場合でも、モデルはビジネスで使用可能な精度を維持でき、変数の拡張によって発生する計算コストが大幅に削減されます。
上空変数予測により、VA-MoE の増分的利点がさらに検証されます。本研究では、3つのトレーニング戦略を比較しました。すなわち、上空変数のみをトレーニングしたVA-MoE、地上変数(IL)を段階的に組み込んだVA-MoE、そして従来の統合トレーニングモデルです。その結果、上空変数のみをトレーニングしたVA-MoEはGraphCastに匹敵する精度を達成し、IFSおよびPangu-Weatherよりも優れた結果を示しました。さらに、段階的VA-MoEは地上変数を組み込んだ後も上空変数の予測性能に低下は見られず、500hPaジオポテンシャル高度(Z500)の長期予報においても精度が向上し、「古い情報を失うことなく新しい情報を学ぶ」能力を示しました。
モデル構造の有効性をさらに検証するため、研究チームはVA-MoEとVisual Transformer(ViT)およびそのエキスパートベース拡張(ViT+MoE)を比較するアブレーション実験を実施しました。ViT+MoEはVA-MoEの約2倍のパラメータ数を持つにもかかわらず、6時間、3日、5日の予測間隔においてVA-MoEは大幅に高い予測精度を達成しました。これは、パラメータ制約のあるシナリオにおいても「チャネル適応型エキスパート」メカニズムの利点を示しており、変数が動的に拡張されるビジネス環境に特に適しています。
AIは気象予報の革新を推進し、従来の数値モデルの限界を押し広げている
VA-MoE が「複数の変数に効率的に適応し、更新コストを削減し、予測精度を向上させる」ことに重点を置く方向で、世界中の学術界とビジネス界が協力して、気象モデリングパラダイムの徹底的なイノベーションを継続的に推進しています。
学術界は、コア技術のボトルネックに焦点を当てることで、モデルアーキテクチャの革新とデータ利用効率において重要な進歩を遂げてきました。ケンブリッジ大学、アラン・チューリング研究所、マイクロソフト・リサーチが共同で開発した Aardvark Weather は、従来の数値フレームワークから完全に解放された初のエンドツーエンド AI システムです。マルチソースの観測データから高解像度の予測への直接マッピングを実現し、スーパーコンピューティングリソースへの依存を大幅に削減しただけでなく、特殊モデルの開発サイクルを数か月から数週間に短縮し、純粋なデータ駆動型パスのビジネス実現可能性を完全に検証しました。
論文のタイトル:エンドツーエンドのデータ駆動型天気予報
用紙のアドレス:https://www.nature.com/articles/s41586-025-08897-0
FuXi-Weatherシステムは、復旦大学が上海科学知能技術研究所、中国気象局などの機関と共同で開発した。従来の数値モデルにおける初期場への依存を打破し、衛星輝度温度から予測結果に至るまでの包括的なエンドツーエンドモデリングの実現を先導しました。アフリカなどの観測密度の低い地域においても、その予測精度は欧州中期予報センター(ECME)のHRESシステムを着実に上回っています。
論文のタイトル:地球規模の気象を予測するデータ機械学習システム
用紙のアドレス:https://www.nature.com/articles/s41467-025-62024-1
ビジネスコミュニティは、テクノロジーの実装とシナリオの適応に重点を置いており、優れたエンジニアリング能力を発揮しています。Google DeepMind が立ち上げた GraphCast は、高度なグラフ ニューラル ネットワーク アーキテクチャに基づいています。ERA5再解析データを用いた学習により、今後10日間の世界天気予報を1分以内に完了できます。指標精度は1,380のテスト変数の中で90%を超え、HRESシステムの精度を上回っています。また、サイクロンや大気河川などの異常気象シグナルを3日前に効果的に識別できます。オープンソース戦略により、技術の普及がさらに促進されています。
論文のタイトル:UT-GraphCast Hindcastデータセット:UTオースティンの気象・気候アプリケーション向けグローバルAI予報アーカイブ
用紙のアドレス:https://arxiv.org/abs/2506.17453
Microsoft が開発した Aurora 大規模モデルは、「事前トレーニング - 微調整」という 2 段階の戦略を採用しています。13億個のパラメータからなる柔軟なアーキテクチャにより、気象、大気質、波浪予測といった複数のタスクにおいて、89%の総合精度を実現します。計算速度は従来の数値モデルに比べて5,000倍高速で、わずかな微調整で様々なビジネスシナリオに迅速に適応できます。
論文のタイトル:地球システムの基礎モデル
用紙のアドレス:https://www.nature.com/articles/s41586-025-09005-y
今後、多元観測データの継続的な充実と基本モデルの継続的な進化により、気象AIは異常気象警報、気候変動評価、専門的な産業サービスにおいてより大きな役割を果たし、「補助的な予報」から「意思決定の推進」へと徐々に役割を転換し、人類社会が気象や気候の課題に対処するためのよりインテリジェントな技術サポートを提供することが期待されます。








