Command Palette
Search for a command to run...
GPT-5 がリリースされました。Sam Altman 氏: プログラミング、ライティング、健康に関する重要なアップグレードがあり、博士号を持つ専門家と話しているような感じです。

「GPT-3 は高校生と話しているような感覚、GPT-4 は大学生と話しているような感覚、そして GPT-5 は博士レベルの専門家と話しているような感覚です。」先ほど終了した記者会見で、サム・アルトマン氏は冒頭の発言で GPT-5 を高く評価し、「GPT-5 はプログラミングとライティングのための世界で最も強力なモデルです」と述べました。
統一システムの構築
GPT-5 は、ほとんどの質問に答えるためのインテリジェントで効率的なモデル (GPT-5-main) を含む統合システムです。より複雑な問題を解決するための深い推論モデル(GPT-5思考)リアルタイムルーターは、会話の種類、質問の複雑さ、必要なツール、そしてユーザーの意図に基づいて、どのモデルを使用するかを迅速に決定します。ルーターは、モデル間のユーザー行動の切り替え、回答の好み、回答精度の評価など、現実世界のシグナルを用いて継続的にトレーニングされ、継続的な最適化を実現します。
公式文書によると、gpt-5-thinking、gpt-5-thinking-mini、gpt-5-thinking-nanoを含む推論モデルは、強化学習によって学習され、推論能力が向上しています。これらのモデルは、質問に答える前に「考える」ようになり、ユーザーに応答する前に思考の連鎖全体を内部で生成します。学習を通じて、これらのモデルは、思考プロセスを最適化し、さまざまな戦略を試し、自分の間違いを認識することを学びました。
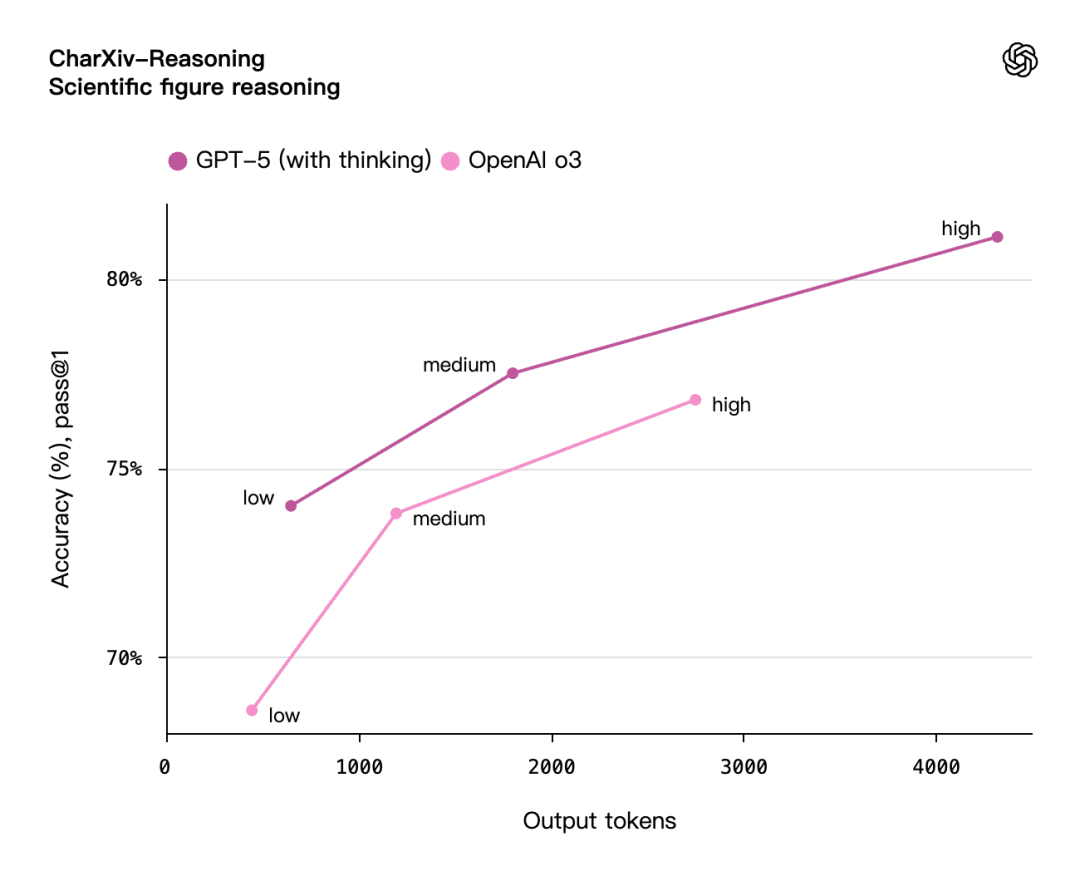
OpenAIの評価によると、GPT-5(推論モードが有効)は、視覚的推論、エージェントコーディング、大学院レベルの科学的問題解決などの機能においてOpenAI o3よりも優れたパフォーマンスを発揮します。そして出力トークンの数は50%から80%に減少しました。
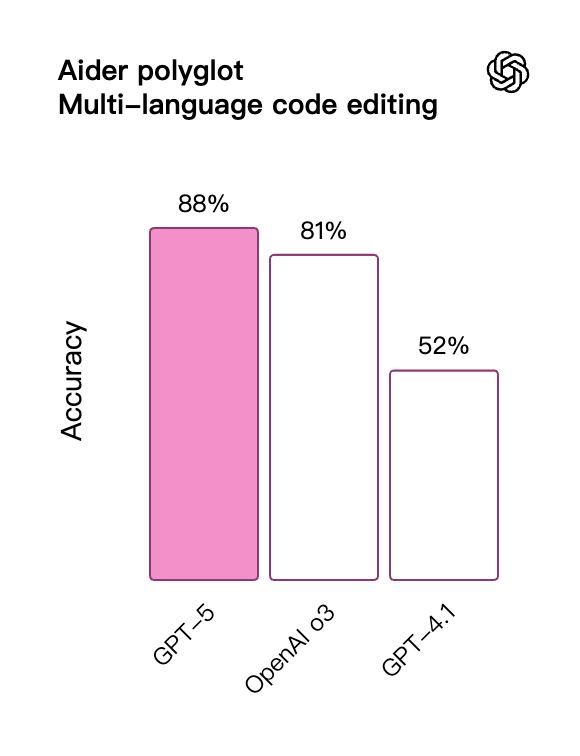
同時に、コーディング能力を評価するAider多言語テストでは、GPT-5は88%のスコアで記録を更新しました。o3 と比較してエラー率が 3 分の 2 減少します。
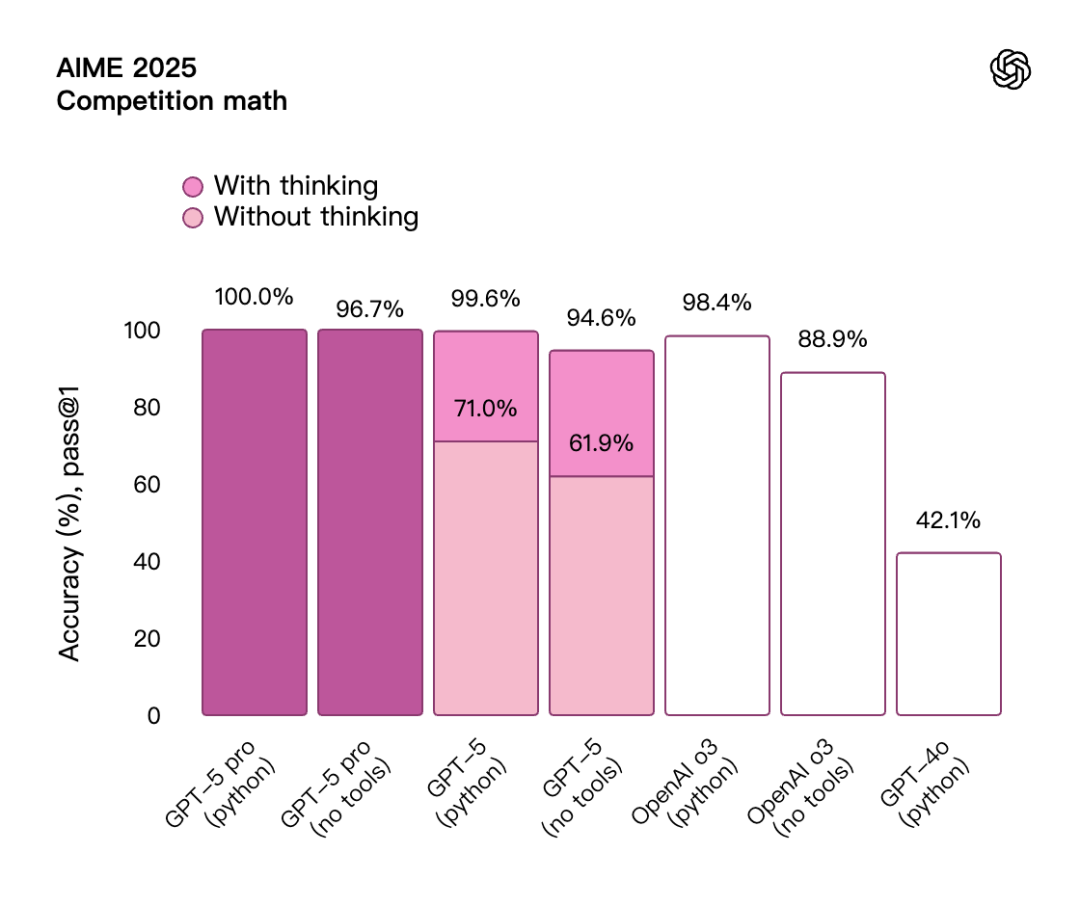
GPT-5は、AIME 2025テストで94.61 TP3T、実世界コーディングタスクSWE-bench Verifiedで74.91 TP3T、MMMUで84.21 TP3Tというスコアなど、複数の分野で現在の最先端技術を上回っています。GPT-5 Proの強化された推論機能により、このモデルはGPQA(汎用質問応答)タスクでも88.41 TP3Tというスコアを達成し、こちらも現在の最先端技術に到達しました。
ライティング、プログラミング、健康相談という3つの主要シナリオの改善に焦点を当てます。
OpenAI の ChatGPT における最も一般的な 3 つのアプリケーション シナリオは次のとおりであると報告されています。執筆、プログラミング、そして健康。GPT-5 のパフォーマンスがさらに向上しました。
OpenAIは、GPT-5 は、これまでで最も強力なプログラミング モデルです。複雑なフロントエンド生成と大規模コードベースのデバッグにおいて、GPT-5は大幅な改善を実現しました。たった一つの指示で、美しくレスポンシブなウェブサイト、アプリケーション、ゲームを生成でき、高い美的感覚を備えています。さらに、GPT-5はコードベースの詳細な分析にも優れており、コードモジュールの動作メカニズムや相互運用性に関する質問に正確に答えます。
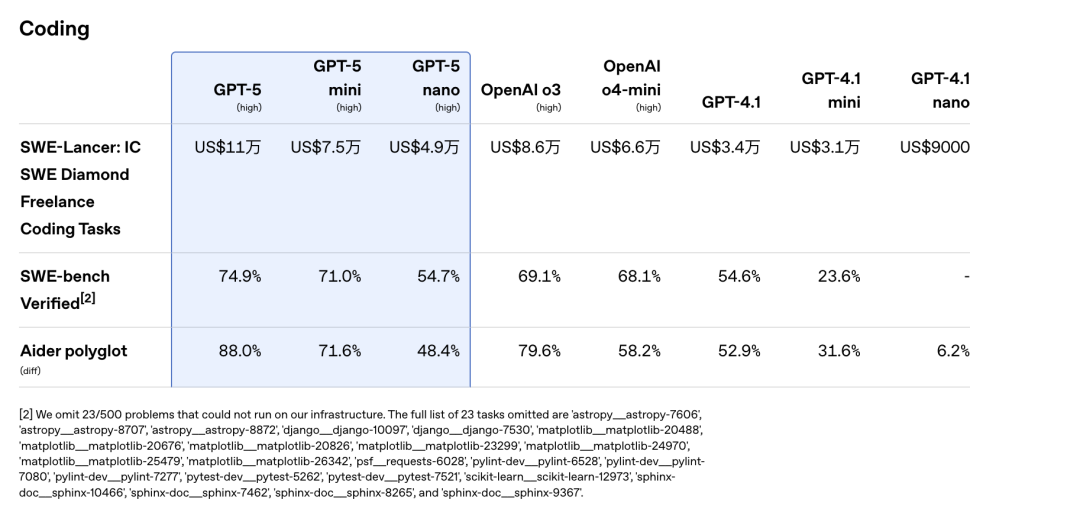
GPT-5はプログラミングに加えて、さまざまなエージェントタスクでも非常に優れたパフォーマンスを発揮し、命令実行(Scale MultiChallengeで69.6%を記録)やツール呼び出し(τ(2)-bench telecomで96.7%を記録)のベンチマークで新記録を樹立しました。
LongFactとFactScoreのベンチマークでは、GPT-5の実際のエラー率はo3よりも約80%低くなります。これにより、GPT-5は、コード生成、データ処理、意思決定サポートなどの重要な分野において、高い正確性が求められるエージェントタスクのシナリオに特に適しています。
クリエイティブライティングの観点では、GPT-5は文学的な深み、リズム、そして響きのある文章を作成できます。弱強韻律の一貫性維持といった構造的に曖昧なライティングタスクにおいて、GPT-5はより信頼性の高い対応力を発揮し、文体を尊重しつつ明確で力強い表現を実現できるため、報告書の草稿作成、メール、メモの作成といった場面において、よりリアルな文章作成を可能にします。
言及する価値があるのは、GPT-5の回答のデフォルトの長さを制御するために、OpenAIは新しいVerbosity APIパラメータも追加しました。このパラメータは、 low 、 medium 、 high の3つのオプション値をサポートします。明示的な指示が冗長なパラメータと競合する場合、明示的な指示が優先されます。例えば、ユーザーがGPT-5に「5段落のエッセイを書いてください」と指示した場合、モデルの応答には常に5つの段落が含まれる必要があります。
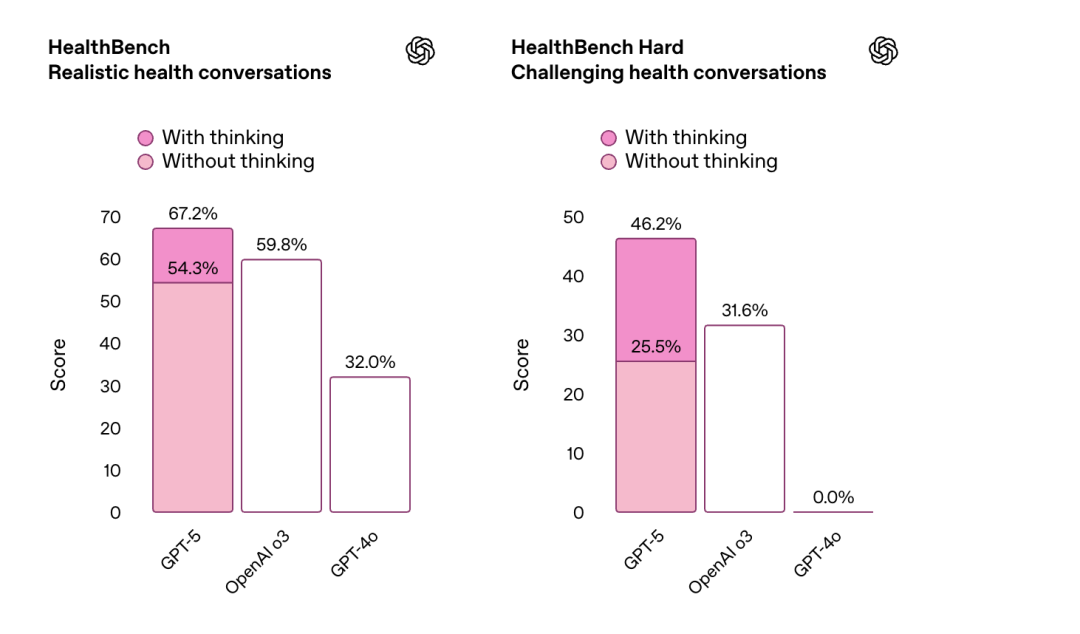
健康関連の問題については、GPT-5はHealthBenchベンチマークで46.2%という最高スコアを達成しました。潜在的な健康問題を事前に特定し、ユーザーの背景知識と地理的な位置に基づいて正確な推奨事項を提供できます。
OpenAIは最近、活発な動きを見せています。gpt-ossでオープンソース分野における新たなSOTAポジションを獲得したばかりで、待望のGPT-5をリリースしました。複数の製品を同時にリリースしたことは、その技術力の高さを証明しています。しかし、このモデルがパフォーマンスとセキュリティの面でどのように機能するかについては、「しばらく様子を見て」市場テストを待つのが賢明でしょう。
参考文献:
1.https://www.theverge.com/openai/748017/gpt-5-chatgpt-openai-release
2.https://cdn.openai.com/pdf/8124a3ce-ab78-4f06-96eb-49ea29ffb52f/gpt5-system-card-aug7.pdf








