Command Palette
Search for a command to run...
心臓モデル全体からLLMベースの疾患ネットワーク分析まで、清華長庚病院のLi Dong氏がデータの観点から医療ビッグモデルの発展動向を分析します。

人工知能技術の成熟に伴い、AIは医療分野にも大きな変化をもたらしました。多様なデータソースとインテリジェントなアルゴリズムを統合することで、医療業界における効率性と診断精度を向上させる新たなソリューションを提供してきました。医療データは、大規模モデルの「燃料」として、また医療判断の中核を担うものとして、極めて重要な役割を果たしています。特に、中国で医療システムのデジタル変革が加速している状況では、データの観点から医療モデルを分析することは、イノベーションへの避けられない道です。
最近、2025年北京知源会議において、清華長庚病院医療データサイエンスセンター所長の李東教授が「AI+科学・医学」フォーラムで講演しました。テーマは「スマートヘルスケア時代に医療データを活用して革新的な研究を行う方法」です。清華長庚記念病院の実践経験と合わせて、データの観点から、ビッグモデルの実装モデル、技術的な制限、リソースの再構築、アプリケーションの探索など、複数の側面が共有されました。

HyperAIは、李東教授の詳細な講演内容を、本来の趣旨を損なうことなく編集・要約しました。以下は講演の書き起こしです。
医療現場における大規模モデルの応用と課題
「ローカル展開 + カスタム開発 + オフライン使用」モードのアプリケーション
DeepSeekは近年非常に人気が高まっている大規模モデルです。医療現場では、モバイル端末での軽量利用モード、クラウドアクセスモード、そして「ローカル展開+カスタマイズ開発+オフライン利用」という3つの主な利用モードがあります。
これら3つのアクセス方法のうち、「ローカル展開 + カスタマイズ開発 + オフライン使用」が、実践上最適なソリューションとなっています。「データは院外に持ち出せない」というポリシー制限により、クラウドモデルは実データを用いてモデルを学習することができず、「静的テンプレート」と化しています。また、軽量モバイルアプリケーションは簡単な診察しかできず、医療の中核ニーズを満たすことができません。「ローカル展開+カスタマイズ開発+オフライン使用」はデータ漏洩や汚染リスク(外部幻覚データの混入など)を回避できますが、病院側が高額なコンピューティングパワーコストを自主的に負担する必要があることも意味します。
医療における大規模モデルの課題
病院に大規模モデルを導入する過程で、私たちは多くの課題に直面しました。たとえば、アルゴリズムの欠陥、幻覚の問題、計算能力の罠、AI の公平性などです。
* アルゴリズムの欠陥:DeepSeekがこれほど普及した理由は、オープンソースであることと低価格であることに起因しています。DeepSeekが採用している「混合エキスパートモード(MoE)」は、ニューラルネットワークを分割することで計算能力の閾値を下げますが、医療現場では限界があります。第一に、マルチモーダルコンサルテーションをサポートできず、「単一専門家による意思決定」では複雑な症例において診断を見落とす可能性があります。第二に、計算能力を維持するためにデータがランダムにオンラインに公開されるため、アレルギー歴や手術歴などの重要な情報が失われ、診断や治療に潜在的な危険をもたらす可能性があります。
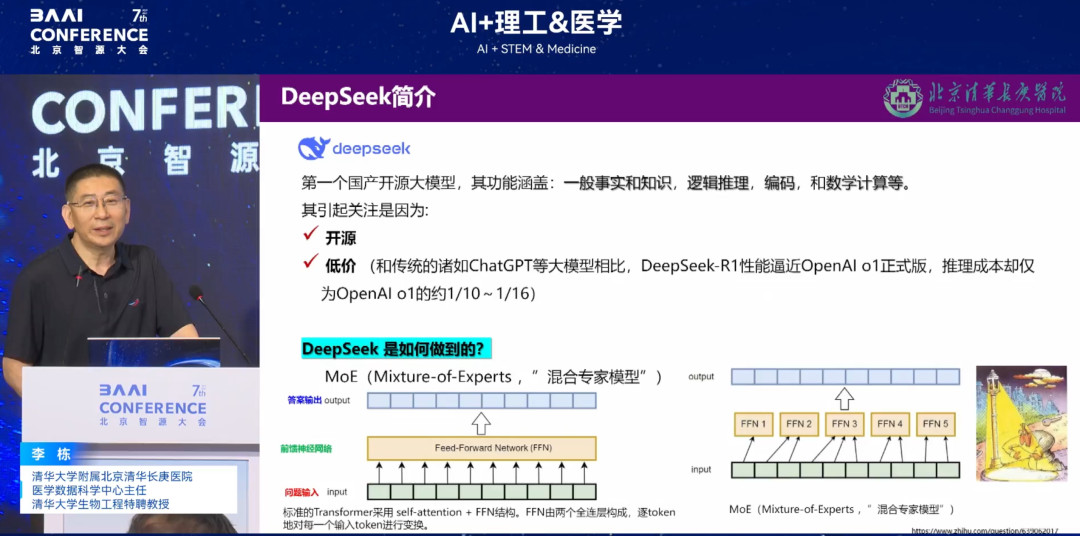
* 幻覚の問題:DeepSeekは、特定の医療シナリオにおいて、一定の割合で幻覚を呈することがあります。リスク軽減のため、「三重検証メカニズム」(アルゴリズムの初期スクリーニング+医師によるレビュー+知識ベースの比較)を採用していますが、診断と治療にかかる時間コストは増加します。
* ハッシュパワートラップ:小規模コンピューティング センターの電力消費はすでに驚異的であり、より複雑な大規模な医療モデルのトレーニングには継続的な投資が必要です。
* AIの公平性:大手病院はリソースの優位性を活用して先進モデルを独占しており、これが「デジタル格差」を悪化させる可能性がある。
医療評価基準の再構築:「3段階基準」から「6要素競争」へ
医療分野への大規模モデルの導入は、予想以上に複雑です。国家衛生健康委員会は当初、AIによって医療資源の不均衡を緩和することを目指していましたが、導入から3か月後、逆効果であることが判明しました。 この大規模モデルは、医療資源の不均衡を改善するどころか、三次医療機関の競争環境を一変させている。
従来の三次病院の評価基準は「名医、設備、ハードウェア環境」でしたが、ビッグモデルの時代には、3つの新たな基準が追加されました。
1 つ目は強力な計算能力です。長庚記念病院はかつて北京の医療機関の中で2番目に大きな計算能力を誇っていましたが、それでも長期研修には対応できませんでした。小規模な計算センターを立ち上げた際には、建物の半分が停電することさえありました。
2 番目は、一流のデータ ガバナンス エンジニアです。医療データには、電子カルテ、画像、検査結果など、様々な種類のデータが含まれており、クレンジング、ラベル付け、構造化が必要です。データガバナンスの一環に500万元を投資しましたが、効果は顕著ではありませんでした。
ついに一流のアルゴリズムエンジニアが誕生しました。「ブラックボックス」問題や「幻覚」認識を解決するには、医療シナリオに応じてアルゴリズムをカスタマイズする必要があります。
スマートヘルスケア:ヘルスケアモデルにおけるデータ主導のイノベーション
下の図に示すように、1950年以降、研究開発投資10億ドルあたりの新薬承認数は、ほぼ9年ごとに半減しています。この傾向は過去60年間非常に安定しており、製薬業界では反ムーアの法則として知られています。新薬の開発コストはますます高くなり、医薬品の研究開発は深刻な生産性危機に直面しています。
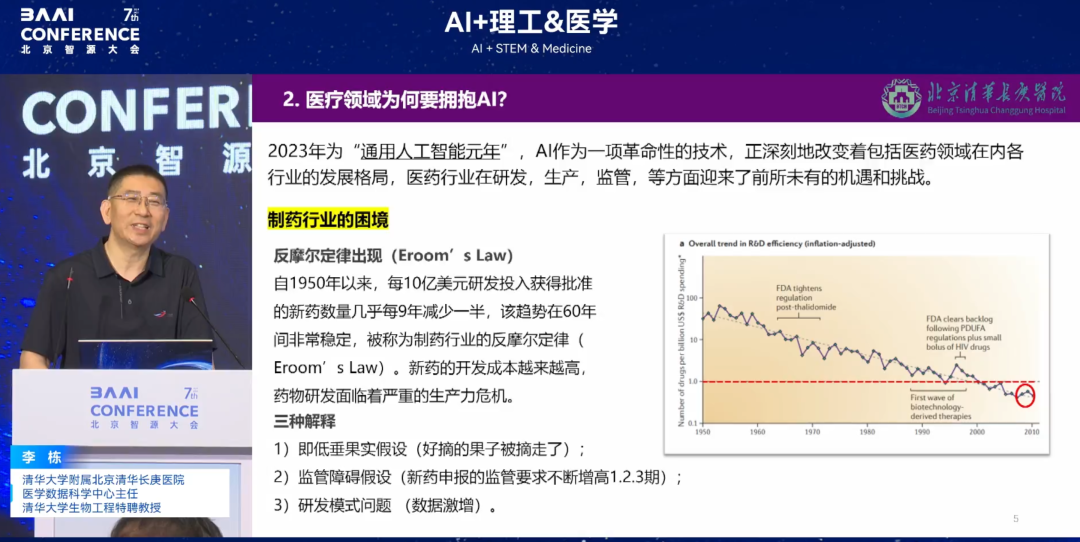
これは製薬業界だけでなく、医療業界全体に当てはまります。下の図に示すように、2018年の統計によると、中国の三級病院の数は全国の7.63%を占め、全国の外来患者数の50.97%を占めている。医療資源の偏在、診断・治療効率の低下、高齢化に伴う疾患スペクトラムの変化など、様々な問題が顕在化しています。スマートヘルスケア時代において、AIを活用した医療変革の加速は不可欠です。
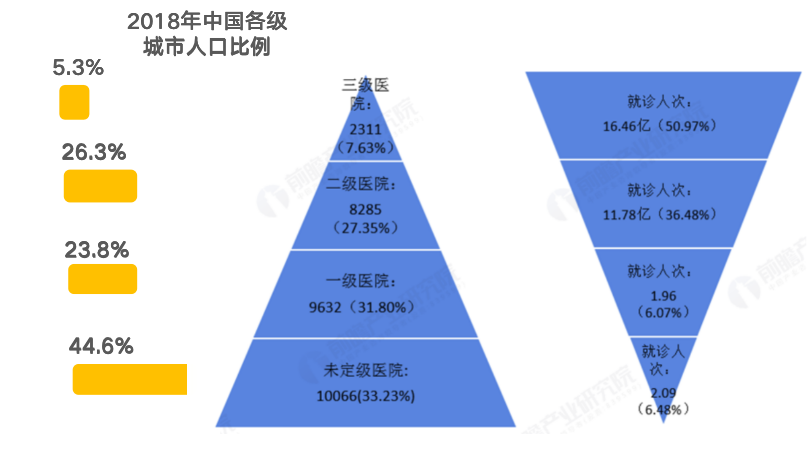
(単位:世帯、億人、%)、出典:国家衛生健康委員会(未来産業研究所主催)
ベンチマークとしての従来のロジスティック回帰ステアリングアルゴリズム
臨床・医薬分野がAIの潮流に乗るにつれ、従来のロジスティック回帰分析は臨床研究に活用できるようになっていますが、大きな欠点があります。長期的な大気汚染と心筋線維症の相関関係を定量的に評価する研究を例に挙げると、従来の手法では通常、社会人口学的特性、バイオマーカー、画像レポート(非画像オミクス)を収集し、PM2.5やPM10などの変数をモデルに組み込み、疾患(例えば体線維症)との相関関係を分析します。
しかし、1970年代以降のこの種の相関分析には根本的な欠陥がある。医学研究では因果関係を探求する必要があるが、従来の手法では事前に設定された変数間の相関関係しか発見できず、モデルに事前に組み込まれていない新たなリスク要因を発見することができず、「鶏が先か卵が先か」というサイクルのパラドックスに陥ってしまう。さらに、従来の相関分析では、変数間の相互作用を扱うことが難しく、通常は2~3因子間の相互作用しか分析できません。数百、数千もの変数を扱うことはできず、画像データに直接アクセスすることもできません。
対照的に、アルゴリズム分析には大きな利点があります。多変量相互作用を処理でき、大量のデータ(画像を含む)を組み込むことができ、トークンを繰り返しトレーニング(1万回または1億回実行)することで、リスク要因が持続する場合は、医学研究に必要な因果関係に近い「因果関係」とみなすことができます。
医療AIの4つの要素の再構築:シナリオ優先のリソース配分
スマートヘルスケアとは、現代の情報技術を活用して医療サービスと医療管理を改善・強化し、医療効率の向上、医療費の削減、そして患者の医療体験の向上を目指す新たな医療モデルです。その中核となる基盤は、ビッグデータ、クラウドコンピューティング、IoT、AIです。
従来の認識では、人工知能の 3 つの要素はアルゴリズム、計算能力、データです。しかし、医療シナリオでは、アルゴリズム、コンピューティング能力、データ、アプリケーションシナリオの「4要素理論」を提案し、それぞれの割合は10%、30%、40%、20%となります。国内外のアルゴリズムに大きな差がなく、多くがオープンソースであるため、医療AI要素に占める割合は最も低く、クラウドコンピューティングのリースによってコンピューティング能力を緩和でき、アプリケーションシナリオはセマンティクスを提供するための補助として活用され、臨床ニーズをモデルが理解できる「タスク」に変換します。このことから、「データ」が決定的な要因であることがわかりました。中国は医療データ量で世界をリードしていますが、電子化率の低さから「未採掘の金鉱」となっています。2028年までに、世界の伝統的な構造化医療データの増加は大規模モデルのニーズを満たすのが困難になると予測されています(データ収集は1550年に開始)。また、中国の歴史データの情報化が不十分なため、世界の医療研究開発の中核データベースとなるでしょう。
医療データトレーニングへの2つのアプローチ
大規模モデルの学習については、病院データを直接学習に使用できるかどうかなど、疑問視する声が多く聞かれます。しかし、経験上、このアプローチは実現不可能です。大規模モデルをトレーニングするには 2 つのアプローチがあります。
まず第一に、大規模モデルのデータ要件は臨床研究の要件をはるかに超えます。病院が臨床研究に活用できるレベルのデータを管理するのは容易ではありませんが、大規模モデルのトレーニングにはより高いデータ要件が求められます。大規模モデルは教師なし学習機能を備えているものの、教師なし学習だけに頼るのは、医師が自然に主治医へと成長していくようなもので、時間がかかりすぎて実際のニーズに対応できないためです。トレーニングを高速化するには、医師の決定木を装備する必要があり、大規模モデルにデータをそのまま入力するのではなく、より深くデータを処理・最適化する必要があります。
第二に、病院がトレーニングに大規模モデルを直接使用したい場合は、「ライブラリ + 専門ライブラリ + 特殊疾患ライブラリ + 特別プロジェクトライブラリ」というデータガバナンスモデルを採用する必要があります。このモデルは、天壇病院をはじめとする複数の病院における実践的な調査を統合して開発されたもので、現在、大規模モデルの学習により適したデータモデルと考えられています。この階層的なデータガバナンス構造により、大規模モデルに高品質かつ体系的なデータをより的確に提供することができ、大規模モデルの学習効果と効率性を向上させることができます。

心臓血管および糖尿病研究:データ駆動型イノベーションのモデル
最後に、スマートヘルスケアに基づいて実施した2つの研究について簡単に説明します。
心臓血管AI:「ウェアラブルデバイス」から「心臓全体モデル」へ
Statistaによる2025年の世界スマートヘルスケア市場規模予測によると、心血管疾患分野は市場の4分の1を占め、最大の市場セグメントとなります。デジタル化は、心血管疾患の急性期から回復期まで一貫して進行しています。
初代Apple Watchの発売後、1本のリードで12本のリードよりも正確な予測が可能になり、装着者の心房細動(AFib)やその他の不整脈を特定できるようになり、プライマリケアに革新をもたらしました。この発想に基づき、私たちのチームは、「ウェアラブルデバイスに基づく心電図(ECG)波形は不整脈を早期に予測できるため、ECG機能のない他のウェアラブルデバイスでも心拍数のみで同様の効果が得られるのではないか?」という仮説を提唱しました。一連の検証の結果、他のデバイスでも最大99.67%の精度で同様の効果が得られることがわかりました。私たちのチームは、一般的なスポーツブレスレットの1分あたりの心拍数を24時間以内に収集し、不整脈の持続時間を予測しました。
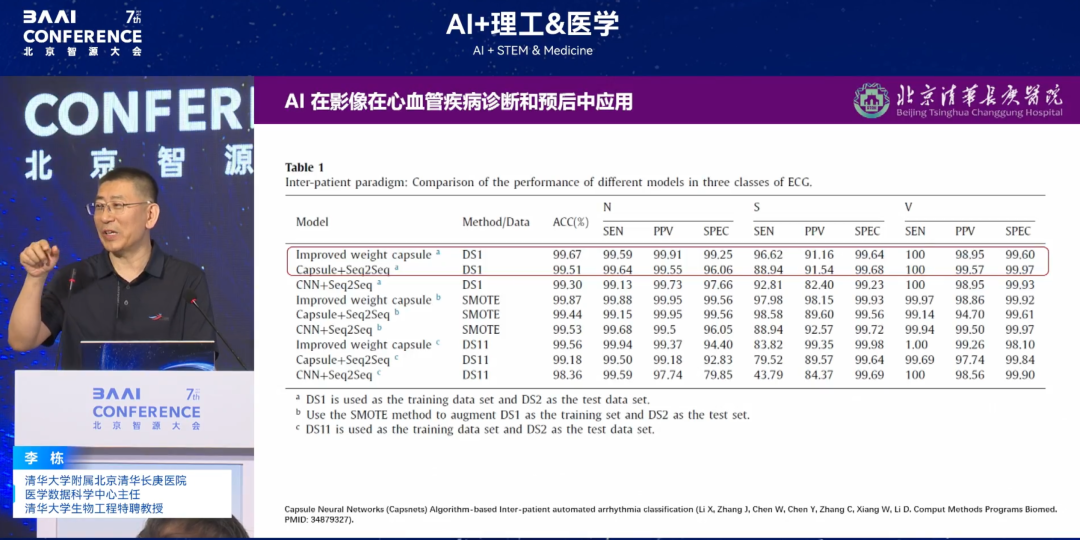
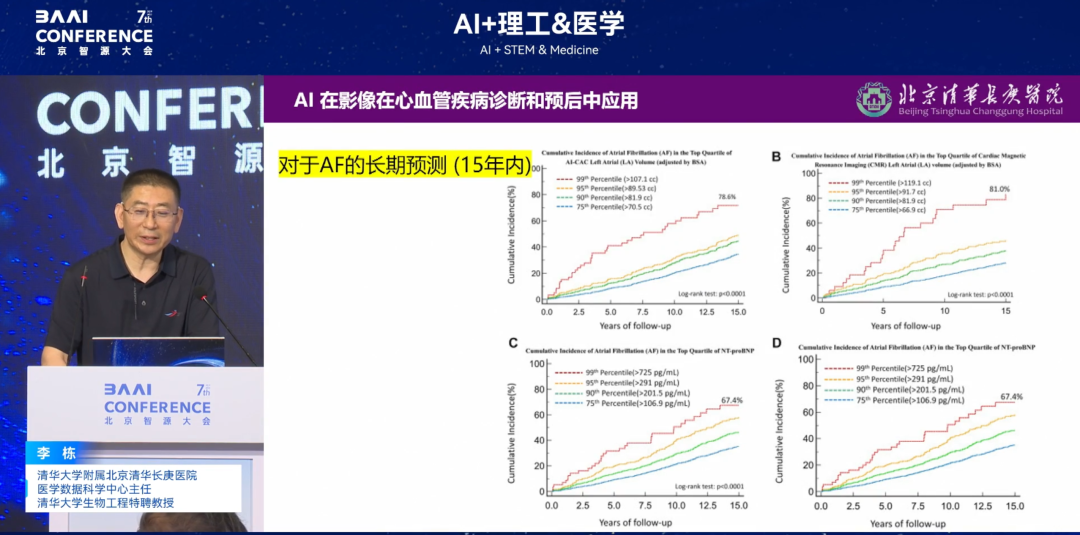
さらに、私たちは2つ目の仮説を提唱しました。「心電図の波形と心拍数に加えて、不整脈を早期に予測することはできるだろうか?心臓の4つの部屋の収縮/弛緩は不整脈に関係しているだろうか?もしそうなら、それを予測することはできるだろうか?」私たちによるさらなる検証の結果、心血管、神経、筋肉などの多次元データを統合する「心臓全体モデル」は、アルゴリズムを用いて心臓を「パッケージ化」することが可能となりました。最終結果は、すべての心機能データを統合して不整脈リスクを予測することで、最大15年間の疾患リスクを正確に予測できることを示しました。関連結果はJACCサブジャーナル(インパクトファクター24+)に掲載されました。
* 論文タイトル:AIを活用したCT心室容積測定はMRIと同等の精度で心房細動と脳卒中を予測
* 用紙のアドレス:https://www.jacc.org/doi/abs/10.1016/j.jacadv.2024.101300
糖尿病研究:「合併症スペクトラム」から「原因メカニズム」へ
もう一つの研究は、大規模モデルに基づく疾患ネットワーク解析です。これまで、早発型糖尿病(40歳未満で発症)は、通常型糖尿病よりも軽症であると考えられていました。例えば、20歳で糖尿病を発症した人は、30歳では血圧や血中脂質は正常で合併症もありませんが、40歳で糖尿病を発症した人は、50歳になると指標に異常が見られ、他の疾患も併発している可能性があります。しかし、全身における糖尿病合併症のスペクトルを研究することで、早期発症糖尿病の合併症のシステム相互作用はより激しく、ベクトル経路の関連性があり、これは人間の本来の認識とは異なります。
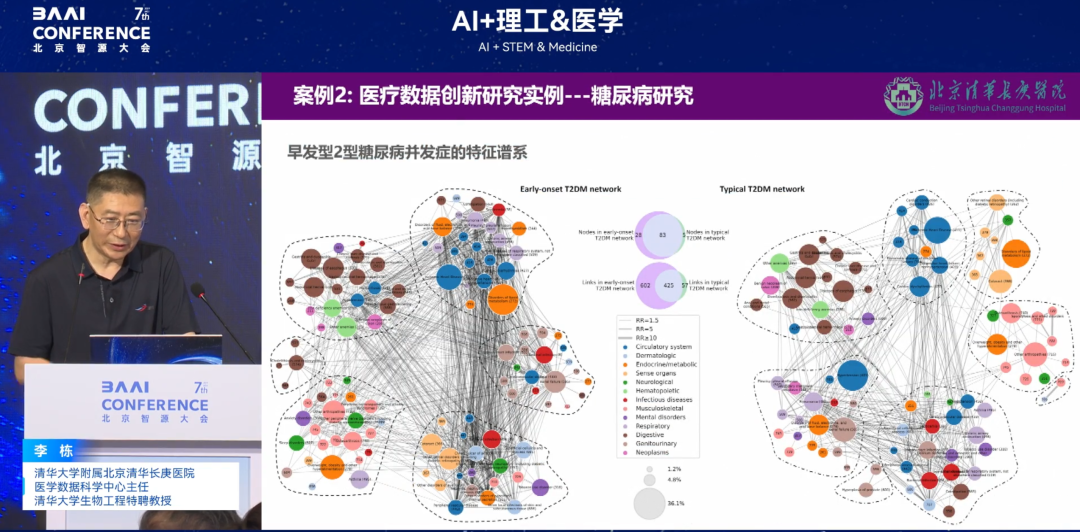
(左:早期発症糖尿病、右:通常診断された糖尿病、異なる色の円はそれぞれ異なるシステムを表します)
将来展望:データインテリジェンス時代のヘルスケアの新たなパラダイム
近年、中国の医療AIは加速している。李国傑院士は「人類は今、情報化時代の知能化段階にあり、知能化時代へと向かっている。知能化科学研究パラダイムが出現し、『第五の科学研究パラダイム』となる可能性がある。時代認識を誤ってはならない。時代の転換期を逃せば、歴史的な次元縮小の打撃を受けることになるだろう」と述べた。
今後は、以下の分野に取り組む必要があります。
* 医師レベル:データは今後の必然的な流れであり、データを利用した革新的な研究を行うためには、学際的な連携(医学と工学の融合)が必須条件です。「医療+データ」の水陸両用人材の育成が最優先課題です。医師は、アルゴリズムエンジニアやデータサイエンティストとより効果的に連携し、医療における AI の応用効果を高めるために、特定の AI 知識(モデル評価やデータ解釈など)を習得する必要があります。
* アルゴリズムレベル:現在、データ駆動型モデルは学習コストの高さという問題に直面しています。将来的には、医療シナリオにより適した軽量モデルの開発を目指しています。計算能力の閾値を下げ、アルゴリズムの臨床応用の解釈可能性と信頼性を向上させます。特に、医師と患者の間での AI の受容度が高まり、AI が医療に統合されます。
* 病院レベル:優れた研究アイデアが浮かばず、イノベーションに迷っているなら、まずはデータから始め、最新の情報科学研究手法を駆使するのが良いでしょう。そのため、病院はこれを奨励し、強力に支援すべきです。科学研究データルームには、データレベルでの医療イノベーションに不可欠なサービスを提供するために、コンピューティング、ストレージ、ネットワーク、セキュリティなどのインフラを整備する必要があります。
ビッグモデルは万能薬ではありませんが、その背後にあるデータ思考は医療の本質を根本から変革しつつあります。データで物語を語り、アルゴリズムで答えを見つける方法を真に習得すれば、「データインテリジェンス+医療の本質」を深く融合させ、医療イノベーションの主導権を握り、スマート医療を真に患者に役立て、社会に貢献できるようになります。
李東教授について
医学博士の李東教授は、医療データサイエンスの分野で国際的に著名な専門家です。清華大学付属北京清華長庚病院医療データサイエンスセンターのセンター長を務め、清華大学バイオエンジニアリングの特別教授でもあります。李東教授は、カリフォルニア大学ロサンゼルス校ハーバーメディカルセンター臨床研究センターの初の中国人センター長を務め、四川大学華西病院の特別教授にも就任しました。

李東教授は、過去5年間で100本以上のSCI論文を国際トップ学術誌に発表し、その引用数は4,000回近くに達しています。また、220本以上の学術会議抄録を発表しています。さらに、40回以上の学術講演に招待され、4本の学術論文の執筆に携わり、2件の発明特許を取得しています。
彼の研究は、臨床研究の設計、測定と評価、モデリング分析、医療データマイニング、そして医療における人工知能の応用など、幅広い分野を網羅しています。彼は、臨床研究チームを率いて医療ビッグデータマイニングを実施し、インテリジェントな医療意思決定分析システムを開発してきた豊富な経験を有し、この分野の権威として認められています。








