Command Palette
Search for a command to run...
オックスフォード大学などの研究チームは、746万人の成人の健康データを徹底的に調査し、早期スクリーニングアルゴリズムを開発し、血液指標に基づいて15種類の癌の早期予測を実現した。

英国では、がん生存率は長い間厳しい課題に直面しており、臨床結果は先進国の中で最も低い水準にある。この状況の背景には、がん患者の多くが診断時には既に中期または後期にあり、最適な治療時期を逃しているという客観的な現実があります。 2011年、英国国民保健サービス(NHS)はがん戦略を発表し、診断プロセスの最適化により現状の改善を目指し、75%のがんを治癒可能な段階(ステージ1または2)で診断するという目標を明記しました。この戦略は、プライマリケアを突破口として、予測アルゴリズムを通じて早期診断の有効性を高め、がんの診断と治療モデルの革新の方向性を示しています。
このような状況の中で、QCancer スコア モデルなど、大規模なプライマリ ケア電子健康データベースに基づいて開発されたがん予測アルゴリズムが登場しました。個人が未診断の癌に罹患している絶対的な確率は、年齢、性別、貧困状態、喫煙、飲酒、家族歴、症状などの複数の要因を統合して評価されます。国の臨床ガイドラインでは、がんの陽性予測値が特定の閾値(3% など)を超えた場合、臨床医がさらなる検査または紹介を検討することを推奨しています。これらのアルゴリズムはプライマリケアの臨床コンピュータ システムに統合されており、患者が医師の診察を受ける際にリアルタイムでがんリスクを評価し、臨床上の意思決定にデータ サポートを提供します。
2020年現在、イングランドにおけるがんの半数以上がステージ1または2と診断されており、これは2028年までに75%という目標値とは依然として大きな差があります。近年、血液検査技術の進歩により、このボトルネックを打破する新たな方向性が見えてきました。多くの研究により、ヘモグロビン、白血球数、血小板などの血液指標の異常な変化は、臨床症状よりも数年前に現れる可能性があることが示されています。これは、がんの早期警告バイオマーカーとしての可能性を示唆しており、研究者らは、無症状または非定型症状のがんを識別するアルゴリズムの能力を向上させるために、血液検査データを予測モデルに組み込むことを検討している。
これを基に、ロンドン大学クイーン・メアリー校とオックスフォード大学の研究チームが協力し、イングランドの成人746万人の匿名の電子健康記録に基づく2つの新しい癌予測アルゴリズムを開発しました。基本アルゴリズムは従来の臨床因子と症状変数を統合し、高度なアルゴリズムでは全血球算定や肝機能検査などの血液指標がさらに組み込まれています。
この研究では、男性と女性のグループを別々にモデル化する多項ロジスティック回帰モデルを使用し、がんの全体的な確率を予測するだけでなく、また、肝臓がんや口腔がんなど15種類のがんについて、初めて個別のリスク評価が可能になりました。500 万回の独立した検証において、新しいアルゴリズムは既存のモデルよりも優れた識別力、較正、感度を示し、臨床意思決定プロセスを最適化し、早期の癌診断を促進するための科学的根拠を提供しました。さらに、研究チームは、この方法が、現在診断されていない肝臓がんの確率を推定するためにプライマリケアで使用される最初のアルゴリズムであると主張している。
関連する研究成果は、「がんの早期診断を改善するための予測アルゴリズムの開発と外部検証」というタイトルで、国際的に著名な科学誌「ネイチャー・コミュニケーションズ」に掲載されました。

用紙のアドレス:
オープンソース プロジェクト「awesome-ai4s」は、100 を超える AI4S 論文の解釈をまとめ、大規模なデータ セットとツールを提供します。
https://github.com/hyperai/awesome-ai4s
デュアルデータベースとマルチコホート研究:サンプル数は100万を超え、あらゆる面でデータサポートを構築
この研究のデータは、QResearch (バージョン 48) と Clinical Practice Research Datalink (CPRD Gold) の 2 つの電子医療記録データベースから取得されました。前者はEMISシステムに基づいてイングランドをカバーし、後者はVisionシステムに基づいて北アイルランド、スコットランド、ウェールズのクリニックデータを含み、データの多様性と代表性を確保するために地理的に独立した外部検証コホートを形成します。
研究対象集団については、以下の図に示すように、英国の QResearch クリニックのデータが、7,464,507 人 (新規がん症例 129,715 件を含む) の開発コホート、2,637,184 人 (新規がん症例 44,984 件を含む) の検証コホート、および 2,736,726 人 (新規がん症例 32,328 件を含む) の CPRD 検証コホートにランダムに分割されました。
3つのコホートのサンプルサイズはすべて100万人を超え、18歳から84歳までの人々をカバーしています。これには、若者に多い血液悪性腫瘍、乳がん、中高年に多いがん種が含まれます。期間は2015年1月1日から2023年3月31日までで、追跡期間は2年間です。この研究は、登録時にがんと診断されていなかった患者に焦点を当て、登録前12か月以内に「危険信号症状」があった患者を除外することで、新しいがんデータの正確性を確保します。データには、年齢、性別、貧困状態、喫煙、飲酒、家族歴、症状、血液検査(全血球数、肝機能検査)などの側面が含まれます。自己申告による人種、喫煙、飲酒、BMI データの完全性がわずかに高かったイングランドのコホートを除き、各コホートのベースライン特性は概ね一貫しており、モデル開発のためのバランスの取れたデータ基盤を提供しました。
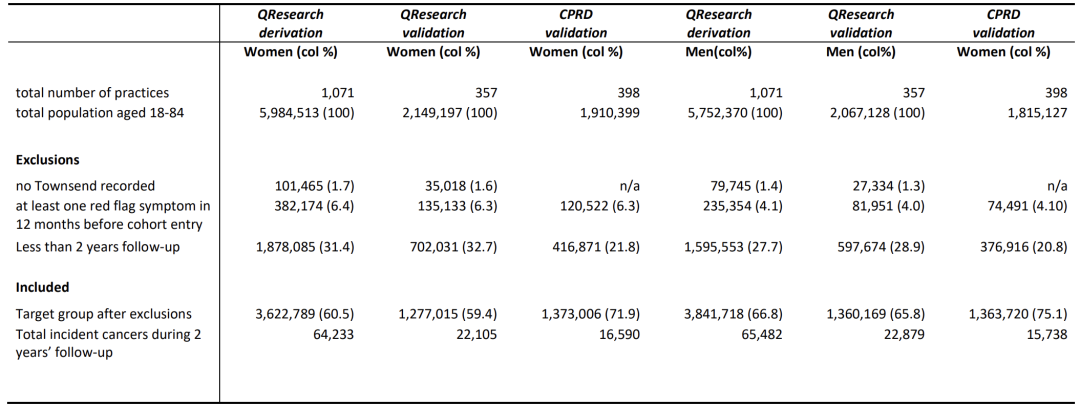
この研究は、一般開業医、病院、死亡率、がん登録という 4 つの主要なデータ ソースに基づいています。すでにQCancerに含まれている13種類のがん(肺がん、大腸がんなど)と、新たに追加された肝臓がん、口腔咽頭がんなど、合計15種類のがんを診断します。CPRD コホートは、データの制限により一般開業医によって記録された診断のみに基づいており、階層化された検証システムが採用されています。これらのデータは、サンプルサイズが大きく、地理的範囲が広く、期間が長く、予測因子が複数あり、臨床的関連性が高いという特徴があります。予測モデルを構築するためのコホートを開発し、さまざまな地域やシステムの検証コホート(特に CPRD 外部コホート)を使用してモデルの普遍性と信頼性を評価することで、実際の臨床シナリオにおけるアルゴリズムの有効性と安定性を確保し、がんの早期診断のためのデータサポートを提供できます。
がん予測モデルの開発:多項ロジスティック回帰モデリングと多次元検証
モデル開発においては、既存のアルゴリズムと文献に基づき、人口統計学的特徴、喫煙や飲酒の習慣、がんの家族歴、併存疾患、症状、血液検査結果などを含む候補予測変数を選別しました。症状は「危険信号症状(がんとの強い関連性、臨床ガイドラインによれば緊急紹介の根拠)」と非特異的症状に細分化され、血液検査には過去 2 年間のコホートの記録が含まれ、潜在的なシグナルを捉えました。
モデルの科学性と正確性を確保するために、モデル化では、研究者らは多項ロジスティック回帰を使用して各がん種の予測変数の係数を推定し、男性と女性のモデルを当てはめました。飲酒、喫煙状況、血液指標の欠損値は連鎖方程式多重代入(男性と女性それぞれ5回の代入+ルビンルールマージ)によって補完され、バイナリ変数は一般開業医の診断記録に従って二値カテゴリにコード化されました。モデルを適合する際、有意水準が 0.01 以下の変数は保持され、ハザード比が 0.80 ~ 1.20 で有意でない係数はゼロに設定されました。統計的有意性のみに基づく自動変数選択を回避し、臨床的関連性を確保するために、P 値と効果サイズを組み合わせて簡潔なモデルが構築されました。
分数多項式は、連続変数間の非線形関係をモデル化し、予測変数と年齢間の相互作用をテストするために使用されました。研究者らはモデルの楽観性を評価する際に、ヒューリスティックな収縮係数を使用し、両方のモデルの収縮値は 0.99 を超えており、過剰適合がないことを確認しました。最終的にモデルA(臨床因子+症状)とモデルB(モデルA+血液検査結果)が導き出されました。後者は、新たな癌関連シグナルを追加することで予測精度を向上させることを目指しています。
モデル評価は 2 つの独立した検証コホートで実施されました。識別能力を評価するためにAUROCを計算することに加えて、研究者らは、全体的な分類性能を測定するために、マルチカテゴリー識別指数(PDI、男性12カテゴリー/女性14カテゴリー、がんのないカテゴリーを含む)を導入した(PDIが1に近いほど、識別の精度が増す)。予測確率と実際の値の間の一貫性は、較正曲線、傾き、切片によってテストされました。早期がんの特別分析では、2015年から2020年の症例に焦点を当て、ステージ1/ステージ2を早期定義として、地理的地域、人種、年齢層などのサブグループを層別化して評価し、異なる集団におけるモデルの普遍性を検証します。
がん予測モデルの応用:肝臓がんと口腔がんを初めて対象とし、血液指標とがんリスクの関係を分析した。
モデルの適用と実験検証の段階では、この研究では、新しい予測モデルの変数の関連性、識別能力、較正効果、臨床的価値について多次元検証を実施しました。既存のQCancerアルゴリズムと比較して、新しいモデルは、肝硬変、B型肝炎、C型肝炎(肝臓がんに関連)、エイズ(血液がんおよび腎臓がんに関連)の4つの新しい病状を追加し、肺がん/血液がんの家族歴との関連性、かゆみ、あざ、腹部のしこりなどの7つのがん横断的症状を補完します。
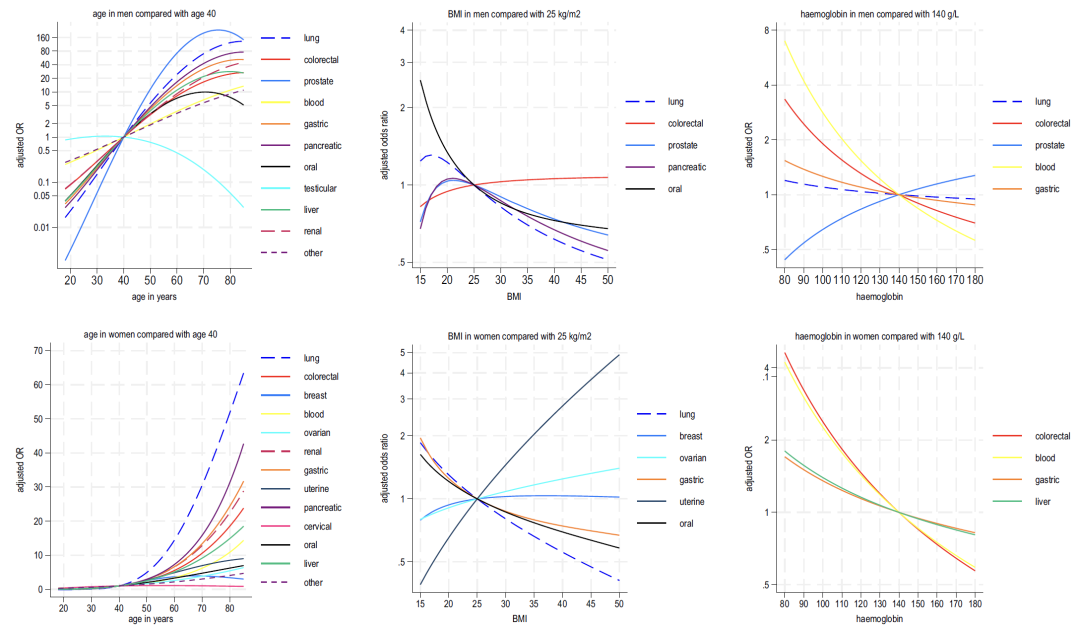
年齢と症状の相互作用には男女差がありました。ほとんどのがんのリスクは、男性では若い年齢でより高くなりますが、女性の場合はその逆になります。年齢と BMI を分析すると、精巣がんと子宮頸がんを除き、すべてのがん種のリスクは年齢とともに増加することがわかりました。 BMIが低いことは複数の種類のがんと正の相関関係にあり、女性ではBMIが高いほど子宮がんや卵巣がんのリスクが上昇した。
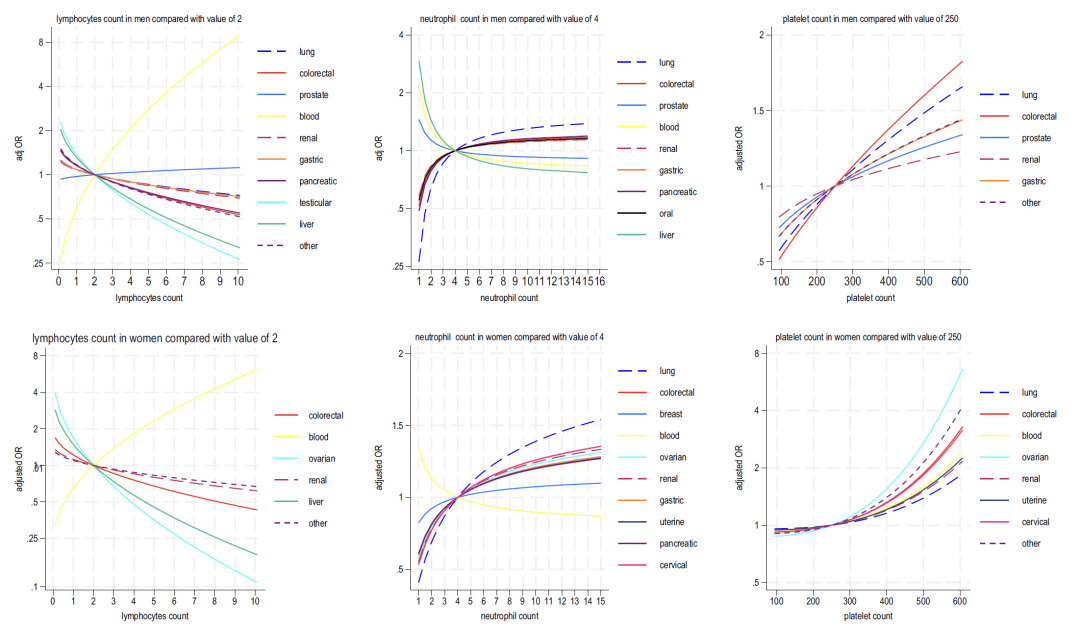
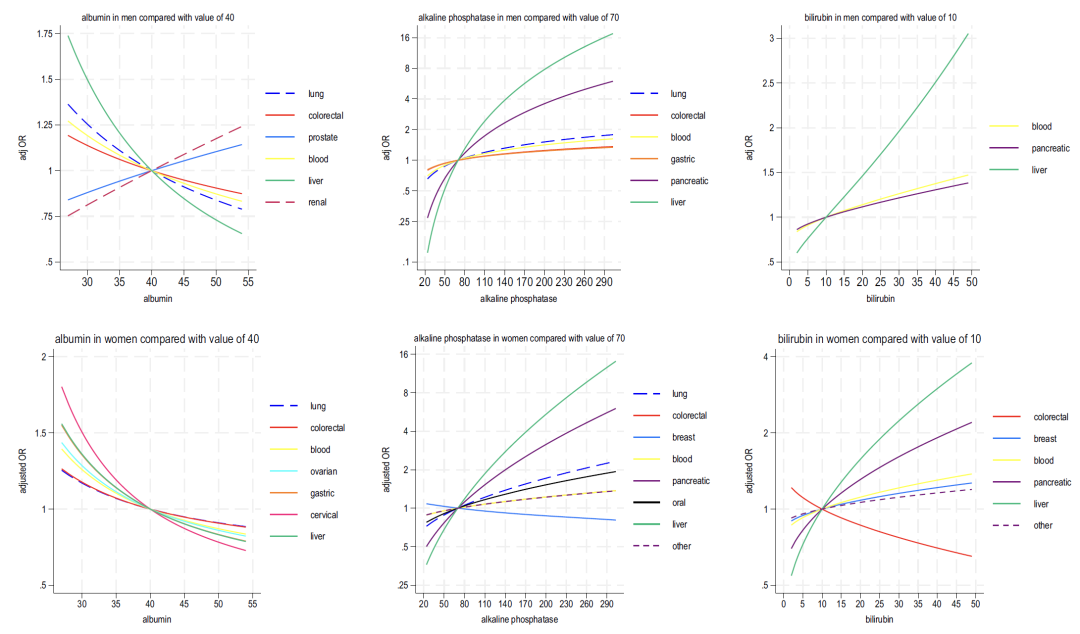
以下の図 2 ~ 4 に示すように、モデル B に含まれる血液指標の分析から次のことがわかります。
* ヘモグロビン:この指標の減少は、男性では肺がんや大腸がん、女性では大腸がんや肝臓がんと関連しています。
* リンパ球: ほとんどの癌とは負の相関があり、血液癌とは強い正の相関があります。
* 好中球:女性では、この指標の増加はがん(肺がんが最も顕著)と広く関連していますが、男性では「双方向に関連しています(高値は6種類のがんに関連し、低値は肝臓がんと前立腺がんに関連)」しています。
* 血小板: 血小板数の増加は、男性と女性の両方で複数の癌と正の相関関係があり (男性の大腸癌と女性の卵巣癌が最も強い)、好中球の増加とリンパ球の減少と相乗的に関連しています。
* 肝機能:アルブミンの減少とアルカリホスファターゼの上昇は一般に癌のリスクを示しますが、ビリルビンの上昇は肝臓癌や血液癌と密接に関連しています。
識別能力の評価では、下図に示すように、モデル B(血液検査を含む)の c 統計量(AUROC)が全体的にモデル A より優れています。男性の全体的な識別効率(0.876)は女性(0.844)よりも高くなっています。 15種類のがんのc値は大部分が0.8を超えており、女性の口腔がん(0.747)と子宮頸がん(0.694)のみがわずかに低くなっています。マルチカテゴリー識別指数(PDI)では、モデル B がモデル A よりも男女を区別する能力(男性 0.323、女性 0.266)が優れており、精巣がん(男性 PDI 0.641)および子宮がん(女性 PDI 0.439)の分類性能も優れていることが示されました。サブグループ解析では、モデルのパフォーマンスは、さまざまな人種、年齢、地理的地域にわたって安定していましたが、イベント数が少ないため、まれな癌ではわずかな変動がありました。
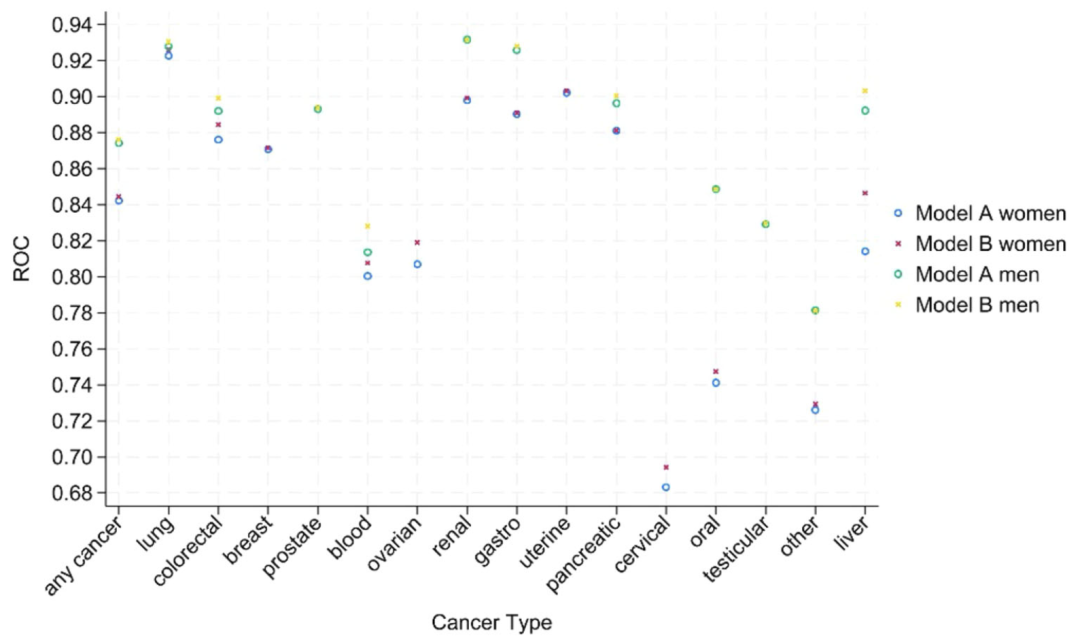
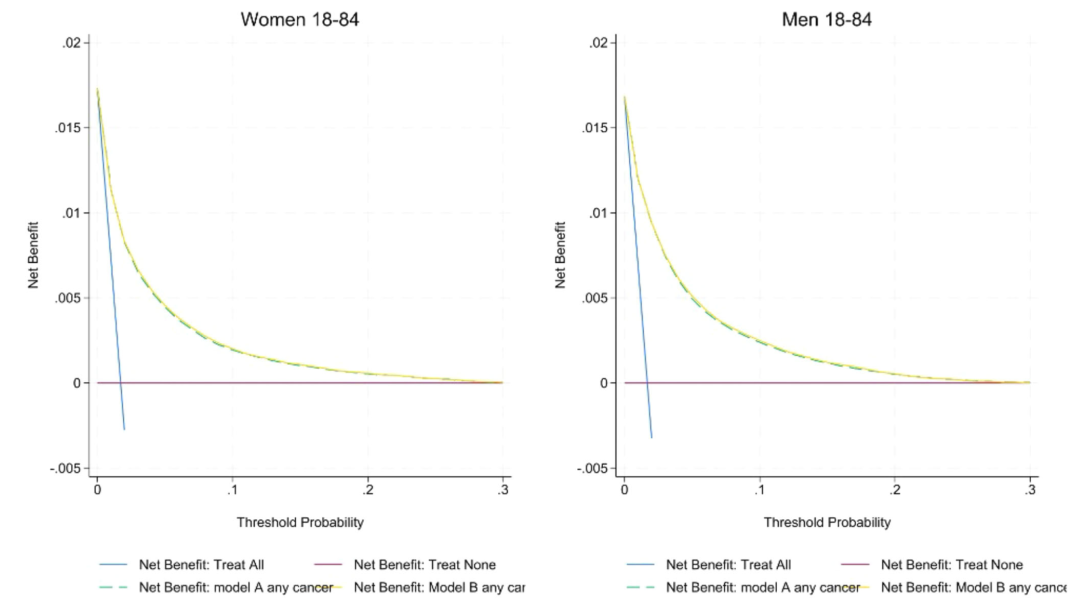
較正能力の面では、下の図に示すように、イングランドのコホートにおけるモデル A/B の較正傾きは 1 に近く (女性は 1.00、男性は 0.99)、切片はゼロに近づいています。しかし、外部 CPRD コホートの男性と女性の癌発生確率はある程度過大評価されています。決定曲線を見ると、モデル B の純利益はモデル A および QCancer よりも高く、特に紹介閾値 3% ではその傾向が顕著であり、男性がんに対するモデル A/B の感度 (82.6%) は QCancer (78.1%) よりも高く、女性がんに対する感度は 66.0% から 77% 以上に増加し、ステージ 1/2 の早期がんを特定する能力は全ステージの能力 (女性 75%、男性 81%) に匹敵することが示されています。再分類分析の結果、QCancer と比較すると、モデル A はより多くの高齢者を高リスクとして分類し、若い人を低リスクとして分類することで、臨床リソースの割り当ての精度を最適化します。
グローバルがん予測アルゴリズムと早期診断:大学研究と企業イノベーションにおける学際的進歩
がん予測アルゴリズムと早期診断の分野では、世界中の大学やテクノロジー企業の科学研究チームが、学際的なイノベーションを通じて理論研究の臨床応用への変革を加速させています。
例えば、北京大学のDong BinとShen Linのチームが開発したMuMoモデルでは、HER2 陽性胃がん患者の画像、病理、臨床データを統合し、個別治療の正確な予測を提供します。中国科学院コンピュータネットワーク情報センターは、Transformer アーキテクチャを採用した「Dongfang」スーパーコンピュータ システムに基づいて、SuRe-Transformer モデルを構築しました。21% による乳がん病理画像の HRD 予測精度の向上。清華大学の Li Shao 氏の研究グループは、弱教師あり学習フレームワーク HistoCell を使用しました。病理画像内の細胞の空間関連ネットワークの教師なし推論を実現します。腫瘍微小環境研究のための新しいツールを提供します。
ハーバード大学医学部とスタンフォード大学が開発したCHIEFモデルは、19種類の癌を94%の精度で診断し、また、病理画像に基づいて患者の生存率を予測することもできます。ケンブリッジ大学が構築した ResNetRS50 ディープラーニング モデルは、高度なモデルよりも高い精度、速度、低いエラー率で血液データを分析して血液がんを予測します。
ビジネス分野におけるイノベーションは、テクノロジーの実装と臨床実践の統合に重点を置いています。 Microsoft の AI for Health プラットフォームは、ゲノムと電子健康記録を統合して個人のがんリスク マップを作成し、乳がんのリスクが高い人に対する予測精度は 89% です。 Google DeepMind の AlphaScan システムは、肺がんの早期検出において 96% の精度を誇ります。 AI医療技術企業InferReadの肺画像AIソリューション(ディープラーニングベースの肺結節検出システム)が臨床CTに適用され、診断効率が大幅に向上しました。
全体的に、がん予測アルゴリズムと早期診断の分野は、単一がんのスクリーニングから複数のがんに対する汎がん早期スクリーニングへと進化しています。米国のGrailのGalleriテストは50種類のがんをスクリーニングし、血液のメチル化分析を通じて原発性病変を特定します。また、中国のXunyuan Biotechnology社のPanSeer®テクノロジーは、5種類の一般的ながんの早期スクリーニングを効果的に実現します。人工知能とビッグデータの深い融合により、がん予測アルゴリズムがプライマリーケアで普及し、「経験的医療」から「精密データ医療」への診断・治療モデルの変革を促進し、「早期発見・早期介入」を実現するための基盤が築かれることが期待されています。
参考リンク:
1.https://bda.pku.edu.cn/info/1003/2824.htm
2.https://www.cas.cn/syky/202505/t20250522_5069507.shtml
3.https://mp.weixin.qq.com/s/s1JyOTPChdoMipmTzBBqvw
4.https://mp.weixin.qq.com/s/4fhMJ25xVAThAFTdmZyt9w








