Command Palette
Search for a command to run...
HUST/上海AIラボ/上海交通大学の研究の先駆者による詳細な情報共有:最新の成果、トップカンファレンスへの論文投稿の経験、学際的なコラボレーションの課題...

人工知能は、コンピュータサイエンス、数学、統計、認知科学などの複数の分野を統合しており、その発展は学際的な才能の育成に大きく依存しています。近年、科学のための AI の台頭により、人工知能と基礎分野の深い統合がもたらす破壊的な可能性が誰もが認識するようになりました。今日、多くの優れた学者が、多分野にわたる背景を活かして科学研究を新たな高みへと押し上げています。例えば:
* 華中科技大学の黄紅准教授は、放送テレビ工学、情報工学、コンピュータサイエンスの分野で学術経験を持っています。現在、彼女はデータマイニング、ビッグデータ分析、ソーシャルネットワーク分析などのデータ駆動型の科学研究に注力しています。
* 上海人工知能研究所のAI科学センターの若手研究者である周東展氏は、物理学でキャリアをスタートしました。人工知能に転向し、現在は材料科学におけるAIの応用に取り組んでいます。
* 上海交通大学自然科学研究所助手研究員 周 炳鑫彼女は学部では金融を専攻し、修士課程ではデータ分析を専攻し、博士課程では機械学習とディープラーニングに重点を置きました。現在、彼女はディープラーニングアルゴリズムに基づいたタンパク質の設計や改変など、生物学分野の問題を解決するためにディープラーニングを使用しています。
黄紅:私たちの研究は、実用的な問題を真に解決できるものでなければなりません
黄紅准教授は、華中科技大学の准教授および博士課程/修士課程の指導者として、長年にわたりデータマイニングとビッグデータ分析の分野に深く携わり、TKDE、TKDD、WWW、IJCAI、WSDMなどのトップクラスの国際ジャーナルや会議で第一著者/責任著者として多数の論文を発表しています。しかし、彼女の科学研究の道のりは順調なものではありませんでした。

黄紅准教授は大学院時代の悔しい経験を思い出し、論文を28回も改訂したと語った。 25回目の改訂のとき、彼女は圧倒されたと感じました。その後、友人や指導者の励ましを受けて、彼女は落ち着いて論文を再検討し、まだ改善すべき点がたくさんあることに気づきました。最終的に、彼女は継続的な調整と磨きをかけ、それを出版することに成功しました。
黄紅准教授の意見では、「科学研究を行う上で重要なのは、論文のアイデアが特定の側面で本当に問題を解決できるかどうか、そして合理的な研究動機を提示しているかどうかを確認することです。」この概念に基づいて、彼女の研究は 2 つの方向に焦点を当てています。1 つ目は、ビッグ データ分析とデータ マイニングにおける革新的な手法の開発です。 2つ目は、実際の社会問題を解決するためのデータ駆動型アプリケーションを開発することです。
方法論的革新の分野では、黄紅准教授のチームは主にグラフニューラルネットワークと複雑システムのモデリングに焦点を当てています。彼女は、現在のビッグデータ時代において、データの価値をより効果的に掘り出すためには、グラフ構造を使って身の回りの物事を表現する、つまり物事をノードとして抽象的にモデル化し、それらのノード間の関係を分析してグラフ構造を構築すればよいと考えています。
さらに、彼らのチームはソーシャル ネットワーク分析などのデータ駆動型アプリケーションも開発しています。 2009年から2012年にかけて、ソーシャルネットワークの発展はピークに達し、Weibo、Twitter、Facebookなどのプラットフォームが徐々に登場しました。これにより、黄紅准教授のチームは、これらのプラットフォームからのデータを活用してネットワーク構造の発展を分析し、ユーザーの推奨や世論分析などの作業を実行するようになりました。
「COVID-19パンデミックの間、私たちは中国に関する国際ニュースメディアのコメントを分析し、インターネット上での中国に対する態度の変化を研究し、対外的な立場を理解するためのデータサポートを提供しました」と黄紅准教授は語った。
もう一つの興味深いケーススタディは、個人の社会経済的地位を分析し、それを都市計画に活用することです。「当社は通信部門と協力してユーザーのモバイルトラフィックログデータを取得し、ユーザーのGPS位置を分析することでユーザーの活動エリアを特定し、そのエリアの住宅価格情報と組み合わせて市内のエリアのレベルを推測します。」簡単な例を挙げると、ある人物が金融街に頻繁に現れる場合、その人は高い社会経済的地位にあることを意味する可能性があり、一方、その人物が学校や教育機関の近くに頻繁に現れる場合、その人は学生または教育者である可能性があります。これに基づいて、研究者は個人の社会経済的地位を総合的に評価し、都市計画の参考資料を提供することができます。
産業知能の面では、黄紅准教授のチームも人工知能技術を利用して産業機器の故障を自動的に特定・診断し、機器メンテナンスの効率と精度を大幅に向上させています。
黄紅准教授は「自分がやりたい研究に興味を持たなければなりません」と結論付けました。彼女の意見では、科学研究は本質的には大きな忍耐力を必要とする退屈なプロセスですが、本当に興味があれば、粘り強く続けるための自発性が生まれます。 「これは私が学生を募集する際に最も重視する資質でもあります。」
周東展:AIが科学者のように新しいアイデアを生み出す
周東展博士も黄紅准教授の見解に同意している。「興味がなければ、より良い仕事をするのは確かに難しい」彼女の意見では、研究の方向性を選択する上で重要なのは、その分野が「ホット」か「人気」かを判断することではありません。人気のある分野は依然として業界で模範的な結果を生み出す可能性があり、ニッチな分野では新たな問題が発見される可能性もあります。私たちは、快適な領域から抜け出し、均質的な研究を避け、より確かな結果を生み出すことを選択すべきです。
現在、周東展博士の研究方向は、大規模言語モデルやマルチモーダルモデルなどの AI 技術を材料科学に適用することです。主な結果は下の図に示されています。
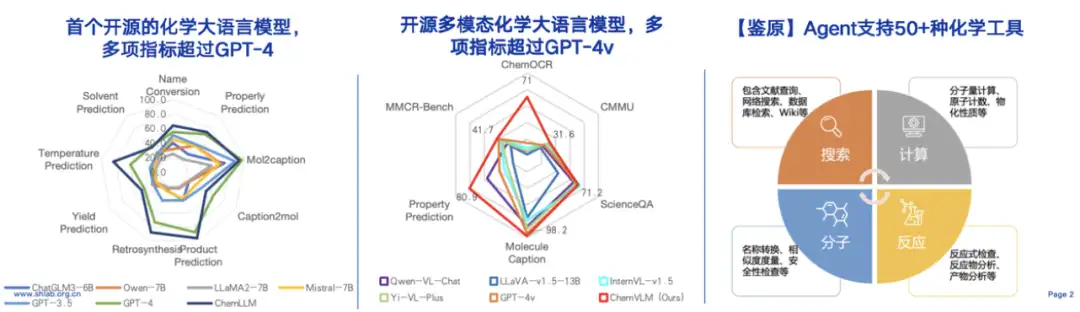
昨年1月、上海人工知能研究所は、「Shusheng Jianyuan」と呼ばれる化学分野の大規模言語モデルを立ち上げました。一般的な大規模モデルと専門分野を組み合わせた最先端のトピックを探ります。化学言語モデルは、多くのコア化学タスク(分子および反応関連)で優れたパフォーマンスを発揮し、多くの指標が GPT-4 を上回っています。化学研究における外部知識の重要性を考慮すると、チームは、言語モデルに検索拡張生成 (RAG) メカニズムを追加しました。モデルの幻覚問題を軽減するため。化学データのモダリティの多様性を考慮すると、チームはさらにマルチモーダルバージョンモデルを開発しました。このバージョンのモデルは分子認識とマルチモーダル化学推論において優れたパフォーマンスを発揮し、多くの指標が GPT-4v を上回っています。モデルに科学的ツールを使用することの重要性を考えると、チームはエージェント ツールキットを開発しました。検索、計算、分子、反応をカバーする 50 を超える化学ツールを統合し、モデルが関連タスクをより効率的に実行できるようにします。
上記の研究に基づき、研究チームは、大規模な言語モデルを質問応答レベルにとどめるのではなく、AI がより複雑なタスクを担うことを望んでいます。そこで研究チームは、AI が科学者のように新たな科学的研究仮説を生成できるかどうかを探り始めました。
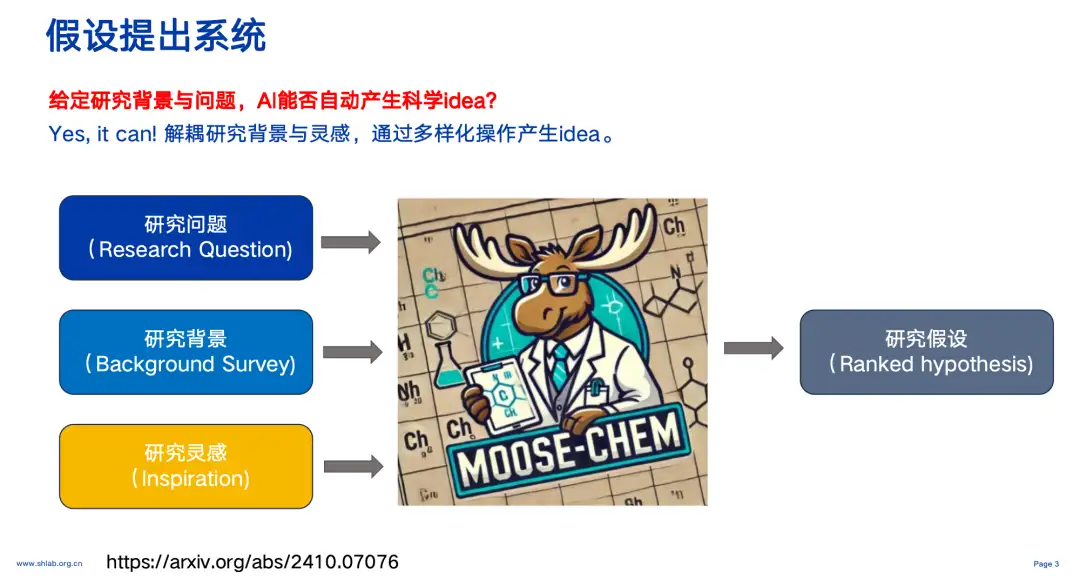
上図に示すように、AI は与えられた研究背景や問題に基づいて研究仮説を自動的に生成します。たとえば、特定の種類のバッテリーを研究し、特定の特性を満たす材料やコンポーネントを探す場合、研究のコンテキストとインスピレーションを切り離し、MOOSE-CHEM システムとその組み込みのマルチエージェント操作を組み合わせるだけで、高品質の科学的アイデアを生成できます。
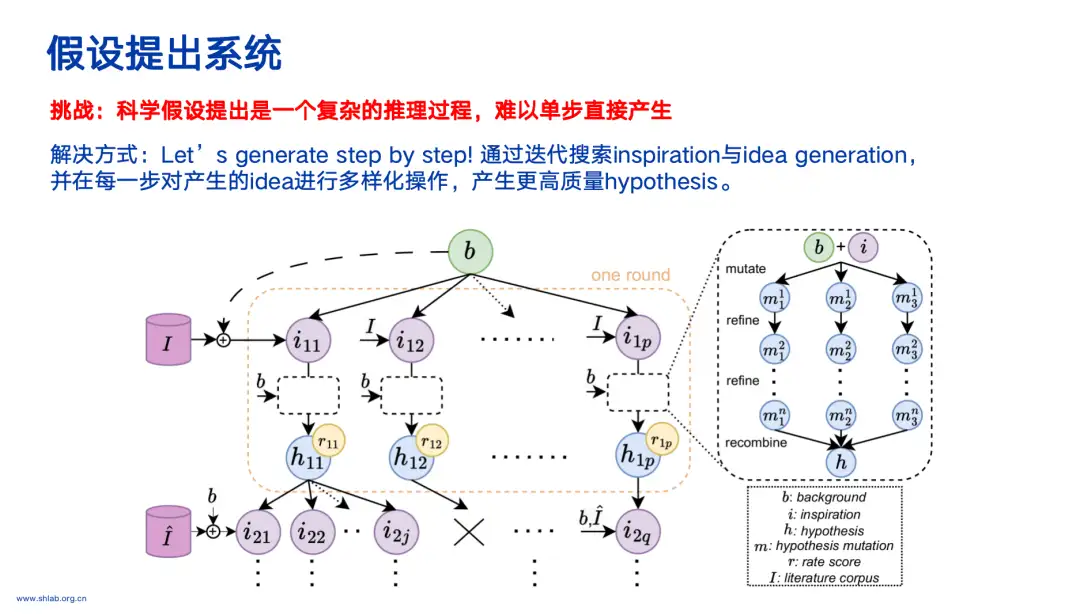
研究により、科学的仮説の策定は複雑な推論プロセスであり、単一のステップで直接生成することは難しいことが判明しました。そのため、チームはプロセスを分解し、インスピレーションと仮説を繰り返し探し、生成された仮説をさらに探し出して、最終的に形成された科学的仮説がより強固で多様なものになるようにしました。
同時に、チームはベンチマーク評価によって生成された科学的仮説も構築しました。下の図に示すように、この研究では、パフォーマンスが優れたモデルの方が検索能力が強いことがわかりました。
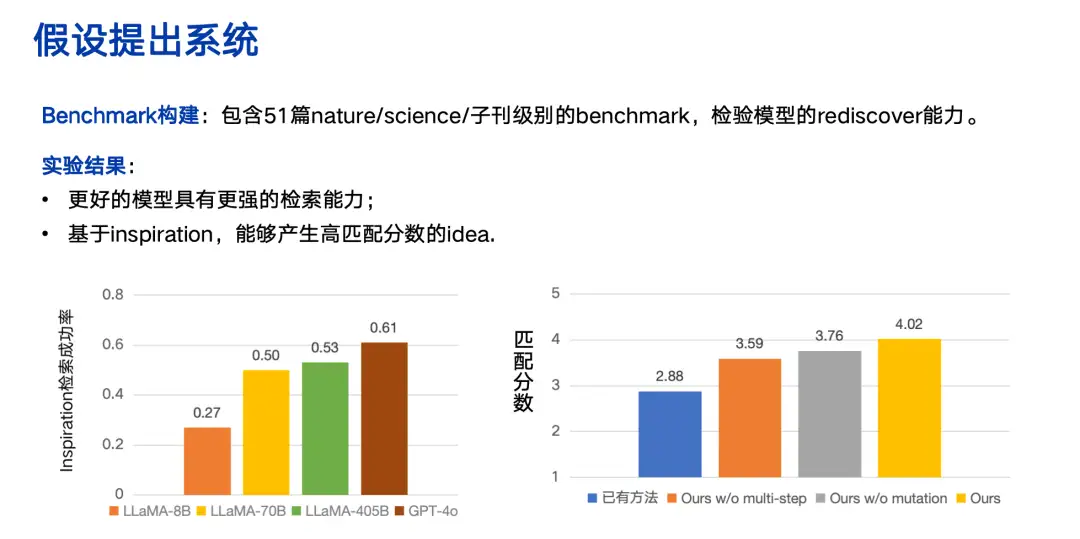
さらに、この研究では、電気化学関連のタスクにおいて、モデルが単なる一般的な概念ではなく、実行可能な科学的仮説を生成できることも確認されました。例えば、その科学的仮説には、金属ルテニウム、窒素ドーピングなど、材料のコア成分が含まれています。研究チームはすでに関連研究グループと連携し、システムの実用化を促進し、真の科学研究アシスタントにすることを目指しています。

AI が科学的研究のアイデアを生み出し、さらには科学的革新を促進できるようにすることが、研究室チームが目指していることです。周東璜氏は自身の学術的経験を振り返り、自身の科学研究に対する姿勢は物理学者の呉建雄氏に深く影響を受けたと認めた。「研究結果の逸脱は、非常に小さな細部の問題から生じる可能性がある」そのため、彼女は常に、細部に注意を払い、徹底的に研究することが科学研究で画期的な成果を達成するための鍵であると強調しています。
周秉馨:自社開発のタンパク質モデルが世界権威リストで第1位に
誰の成長の軌跡にも、勉強や仕事、さらには人生設計に微妙な影響を与える「アイドル」がいるかもしれません。周秉馨博士は、自身の「科学研究のアイドル」について語り、「私が科学研究を選んだ理由は、博士課程の指導教官の影響が大きい」と紹介した。周秉馨さんの印象では、博士課程の指導教官は非常に責任感があり、真面目で、忍耐強く、親しみやすく、学生のメッセージに数秒で返信する人物です。彼は、彼女がコードを単語ごとに修正したり、式の導出を行ごとに確認したりするのを手伝います。 「将来は指導者のように、学生の育成を非常に重要なこととして捉えられるよう願っています。」
周秉馨氏は、科学研究の方向を選択する際に、唯一の「正しい道」は存在しないと考えている。重要なのは、自分に最も適した道を見つけて、それに固執することです。 「それはあなたが何をしたいか、そしてあなたのリスク許容度によります。あなたが幸せである限り、トレンドに盲目的に従う必要はありません。」
周秉馨氏はまた、近年のチームの研究、特にタンパク質修飾における AI の探求についてもいくつか共有しました。
産業界では、酵素は医薬品開発、疾病監視、プラスチック分解などの用途に使用されています。しかし、天然タンパク質は自然界に由来し、独自の特定の生息環境(高圧や高温など)を持っているため、産業上のニーズを満たさない可能性があります。したがって、触媒活性、熱安定性、結合親和性、基質選択性を改善するために、それらを改変する必要があります。
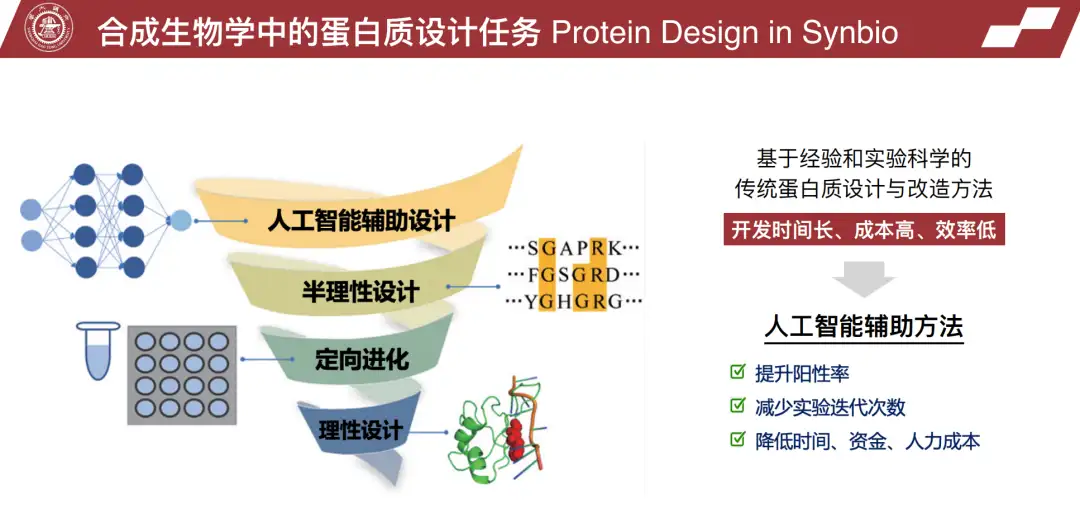
近年、人工知能を活用したタンパク質設計が徐々に登場してきました。下の図に示すように、簡単に言えば、まず自己教師ありモデルに大量のタンパク質データ(配列、構造、進化情報)を学習させ、次に下流のタスク(タンパク質活性の予測)に関連する少量のラベル付きデータセットを使用して予測モデルをトレーニングします。特定のニーズ(活性の向上)に応じて、タンパク質の構造または配列が再最適化されるか、完全に設計されます。
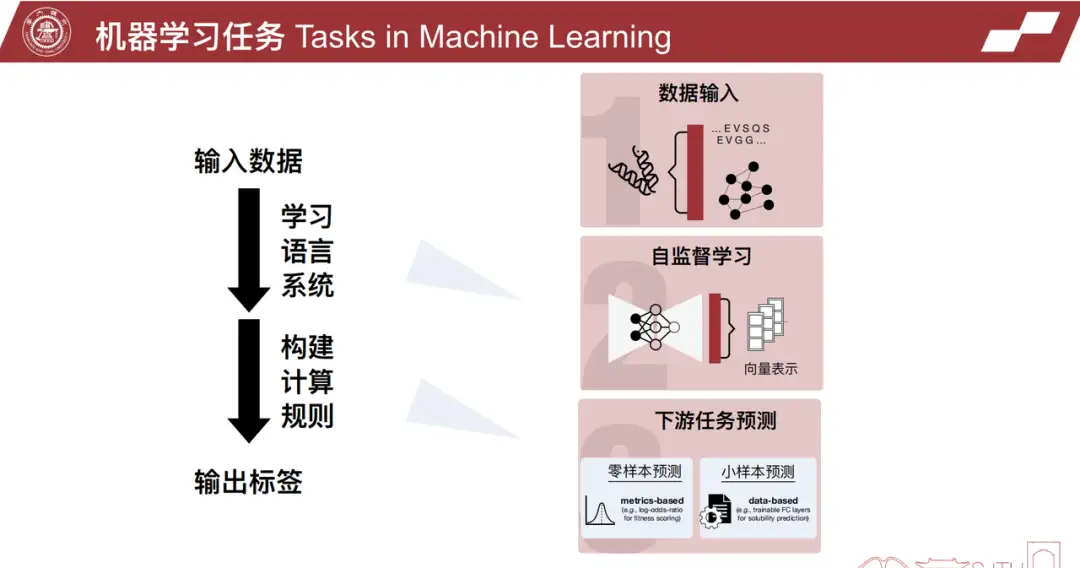
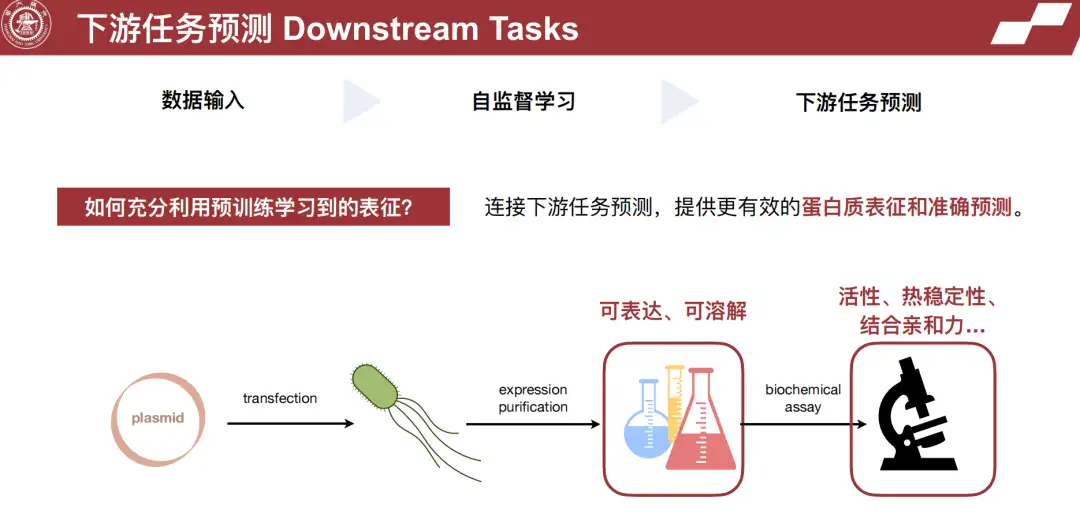
タンパク質配列が変更された後、大腸菌や酵母などの発現システムに導入され、生物学チームが発現および精製できるようになります。精製されたタンパク質は、その後、タンパク質の特定の用途に応じて、活性、安定性、結合親和性などの生化学的特性についてテストされます。アルゴリズムは、特定のタンパク質の表現力、溶解性、活性などを予測するなど、このプロセスを支援することもできます。最後に、アルゴリズムによって推奨されたタンパク質配列のみを実験で使用する必要があるため、コストをさらに節約できます。
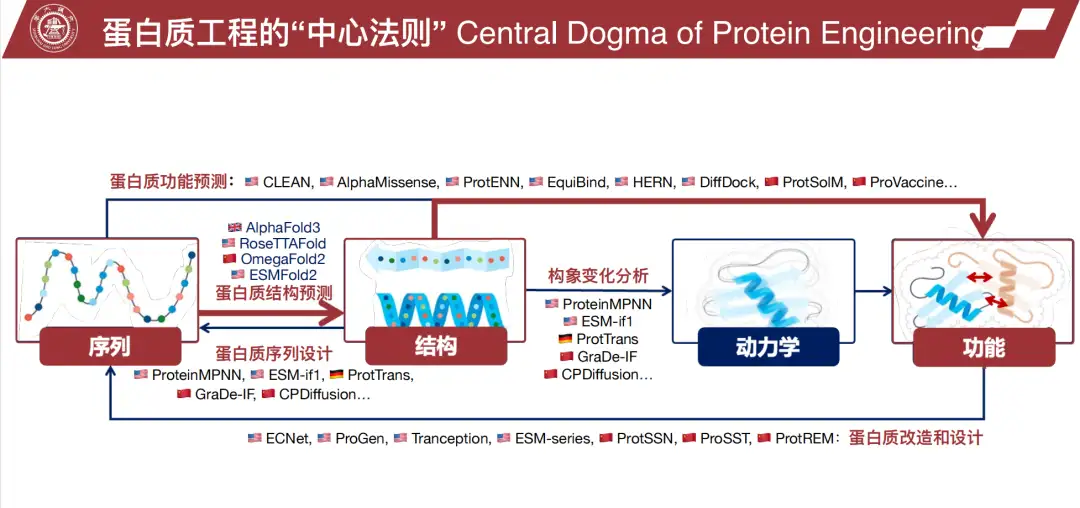
以下の図に示すように、周秉鑫氏のチームの研究は、タンパク質構造から配列を推測したり、機能から配列を推測したりすることなど、タンパク質工学のさまざまなモジュールに焦点を当てています。「私たちは独自のツールを開発し、これらのツールを後続の生物学的実験と組み合わせて完全なサイクルを形成する方法を模索し、それによってドライ実験(計算シミュレーション)とウェット実験(実際の生物学的実験)の間の反復的な最適化を実現したいと考えています。」
これまでのところ、チームが開発したツールは、乾式実験と湿式実験の両方で優れた結果を達成しています。たとえば、世界的に権威のあるリストである ProteinGym では、同社のモデルがそれぞれ 1 位と 2 位を獲得しました。
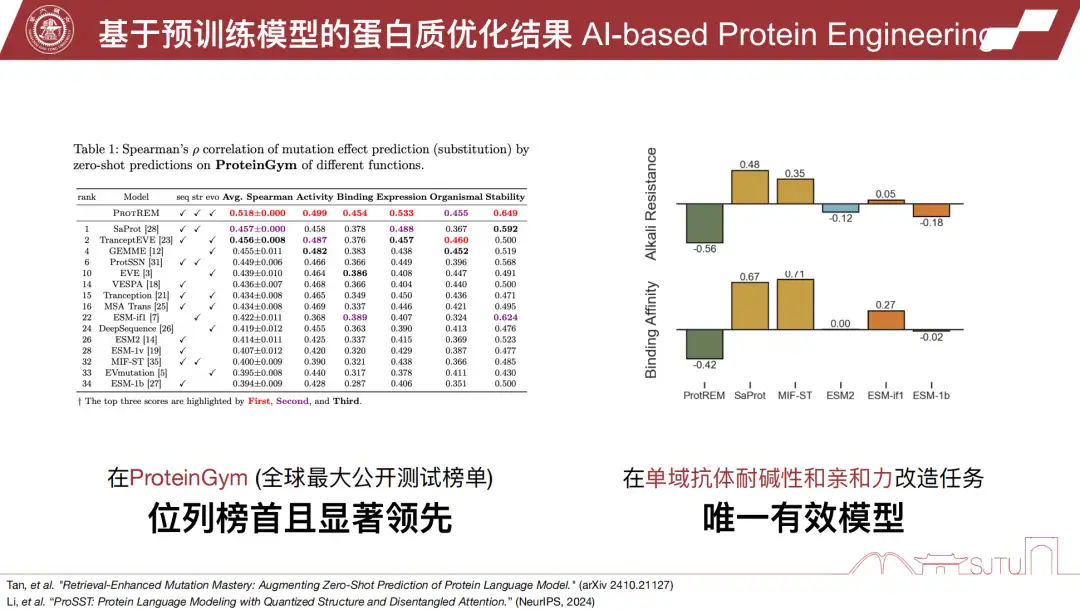
さらに、チームが開発した成長ホルモンは、AI設計タンパク質の本格的な大規模生産(5,000リットル)に世界で初めて成功しました。また、EPS-G7酵素の改変にも成功し、特異性と触媒活性を向上させ、生産コストを90%削減し、輸入独占制限を打ち破りました。

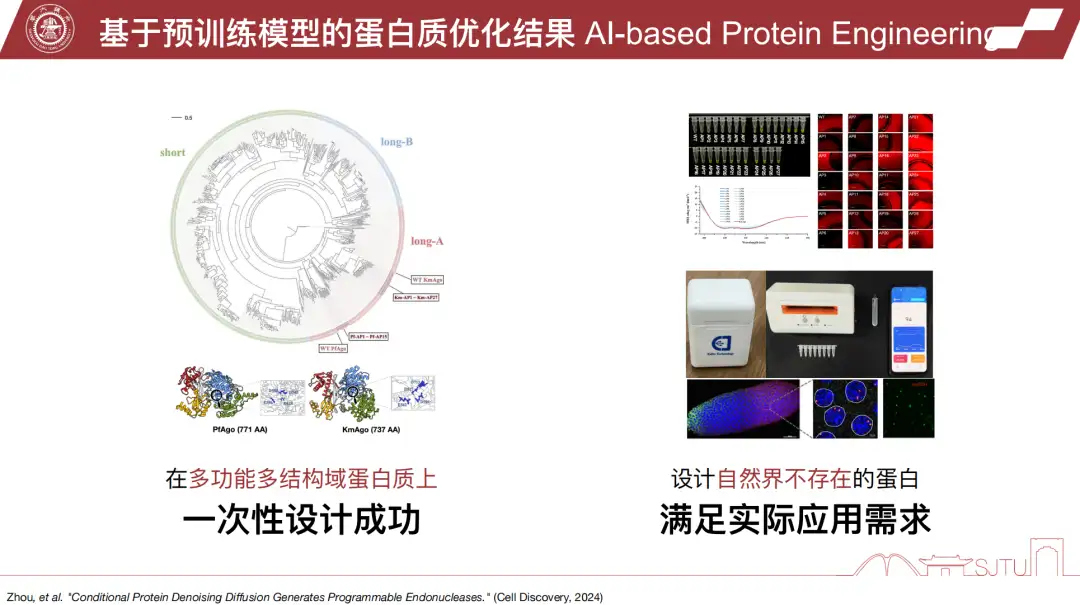
単一点または少数点の変換に加えて、彼らはまた、完全なタンパク質配列全体を生成しました。例えば、核酸のせん断に用いられるAgoシリーズタンパク質(高温生存性)は、室温でも良好な活性を維持できるように改変されており、核酸検査キットにおけるせん断作業に適している。
AI実践者と科学実践者の間の最大の問題はコミュニケーションである
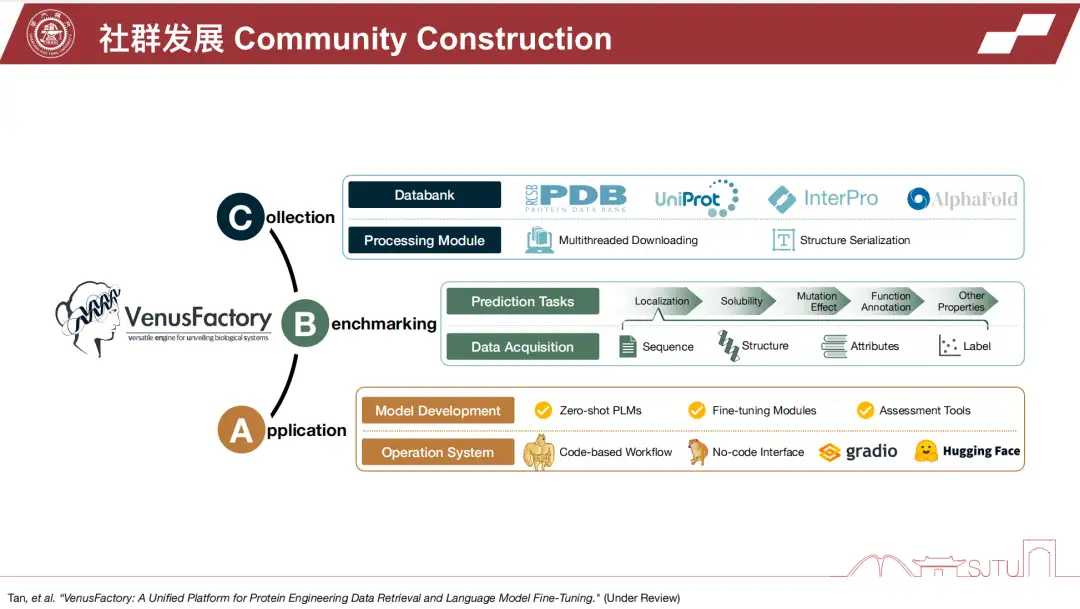
周秉鑫博士の分野は高度に学際的であるため、AI 実践者と科学実践者の間のコミュニケーションを促進するために、同博士のチームが大量のデータ、ツール、下流タスク検出モジュールをまとめたことは特筆に値します。そしてそれを VenusFactory というツール ライブラリに統合しました。
周秉鑫博士の見解では、AIと科学の連携にはコミュニケーションスキルが極めて重要です。 「生物学の学際研究を始めた頃、多くの生物学パートナーが私たちと協力したいと言ってきましたが、私は彼らの言っていることが理解できませんでした。今では、自分の理解に基づいて、彼らが提起する科学的問題を工学的問題に変換し、それらを解決するための対応するアルゴリズムを見つけることができます。」
周東展博士もこの見解に同意している。彼女は次のように強調した。「大学、研究機関、企業と協力する場合、双方が同じレベルで問題を理解することが重要です。科学分野のパートナーにAI技術の現状を理解してもらうと同時に、技術チームに最も重要な問題が何であるかを理解してもらう必要があります。」
黄紅准教授は、学際的な連携においては基礎知識を習得することが非常に重要であると付け加えた。彼女は清華大学社会学部の羅家徳教授のチームとの共同研究を振り返った。初期段階では、社会学チームが研究課題を提案し、技術チームがデータ分析のサポートを提供し、実験設計を担当しました。時間が経つにつれて、技術チームは徐々に社会学の基礎知識を習得し、独自に質問を投げかけ、社会学チームと議論するようになりました。このアイデアの衝突により、多くの研究成果が生まれました。
ICLR 2025 やその他のトップカンファレンスが最近結果を発表しており、まだ期限に達していない重要なカンファレンスもいくつかあることは注目に値します。また、この機会を利用して、以下のように、トップ AI カンファレンスに論文を提出した際の経験を教師の方々に共有してもらいました。
1. 論文募集要項を注意深く読んでください。さまざまなトップカンファレンスで論文を受理するための要件を明確にし、投稿の機会を逃さないようにします。
2. 記事の詳細に注意を払います。フォーマットは正しく、写真は鮮明で、レイアウトは美しくなければなりません。
3. 提出期限を明確にします。論文の完全性を確保し、査読者の質問の余地を減らすために、すべての実験は少なくとも 1 週間前に完了する必要があります。
4. 研究上の疑問記事のアイデアが本当に特定の問題を解決するかどうか。研究の動機が合理的であるかどうか。
5. 論文執筆に関するアドバイス
* 推奨される論文の概要: まず、背景を紹介します。第二に、これまでの研究はどのようなもので、どのような問題があったのか。第三に、私たちの仕事は何でしょうか?私たちはあなたのアイデアがレビュー担当者に伝わり、納得してもらえるようにします。
* さらに、論文の論理性を保証するために、各研究の質問とそれに続く実験検証は相互に関連し、一貫性が保たれている必要があります。
6. 拒否について:原稿が拒否されるのは普通のことです。レビュー担当者の好みはそれぞれ異なります。もう数回送信してみてください。








