Command Palette
Search for a command to run...
オンラインチュートリアル丨Shiji Niangniangは一瞬にして「四川と重慶の少女」に変身しますか? Step-Audio-TTSは音声複製/音楽合成/音声合成の3つを1つに実現します

DeepSeekオープンソースが引き起こした世界的な熱狂は、今も続いています。最近、Step StarとGeely Auto Groupが再び動き出し、Step-Audio-TTS-3Bモデルをオープンソース化し、再び業界で幅広い議論を巻き起こしました。
むかしむかし、方言データの多様性と複雑さ、およびモデルの一般化に対する高い需要により、音声クローニング モデルは方言ではパフォーマンスが低下します。Step-Audio-TTS-3B は、現地の言語の特徴を鮮明に翻訳できます。 LLM-Chatパラダイムの大規模合成データセットに基づいてトレーニングされており、言語の構造に対する深い洞察力を備えています。行間から言語の微妙な変化を捉えることができます。情熱的な四川語でも、9声と6声の広東語でも、そのリズムとトーンを正確に捉え、強い地元の習慣を表現します。
それだけでなく、RAP やハミング生成を実現した初の TTS モデルでもあり、音楽音声合成のギャップを埋めています。かつては、リズミカルなラップコンテンツを作成するにはプロの歌手が必要でした。現在、Step-Audio-TTS-3B の助けを借りて、ユーザーは正確なリズムとスムーズな流れを備えた RAP ボーカルをすばやく生成し、無限の可能性を刺激することができます。
現在、HyperAI公式サイトの「チュートリアル」セクションで「Step-Audio-TTS-3Bプロダクションレベルの方言音声生成モデル」が公開されています。このチュートリアルには、音声合成、音楽合成、音声複製の3つの機能が含まれています。ぜひご自身で体験してみてください〜
チュートリアルのアドレス:
デモの実行
1. hyper.ai にログインし、チュートリアル ページで Step-Audio-TTS-3B Production-Level Dialect Speech Generation Model を選択し、このチュートリアルをオンラインで実行をクリックします。
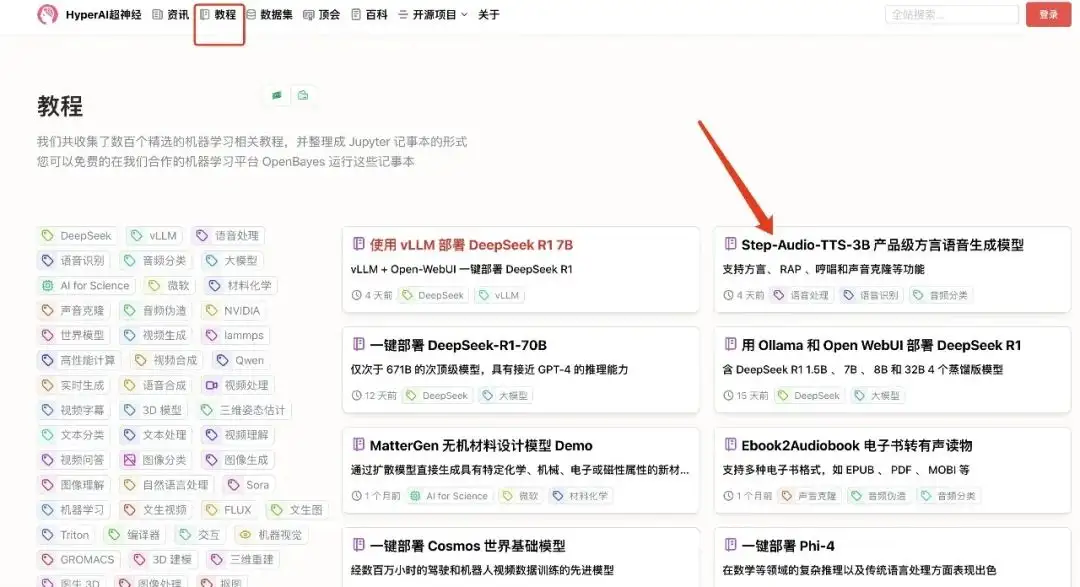
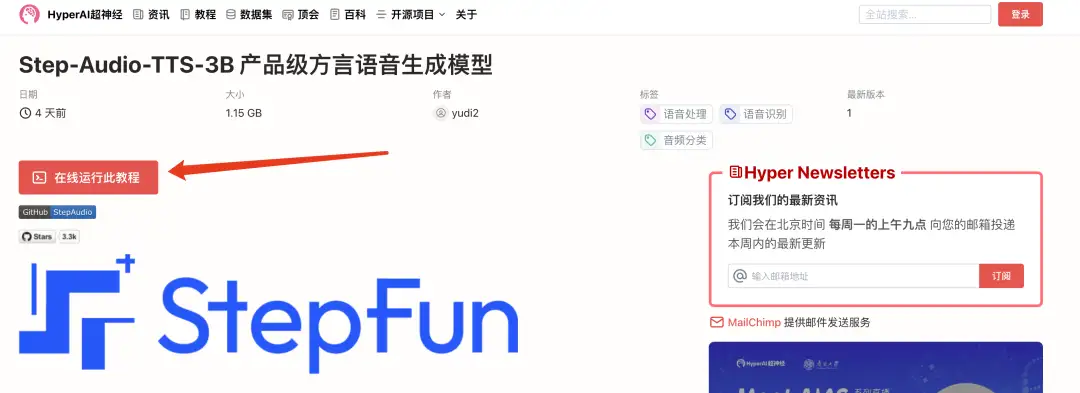
2. ページがジャンプしたら、右上隅の「クローン」をクリックしてチュートリアルを独自のコンテナにクローンします。
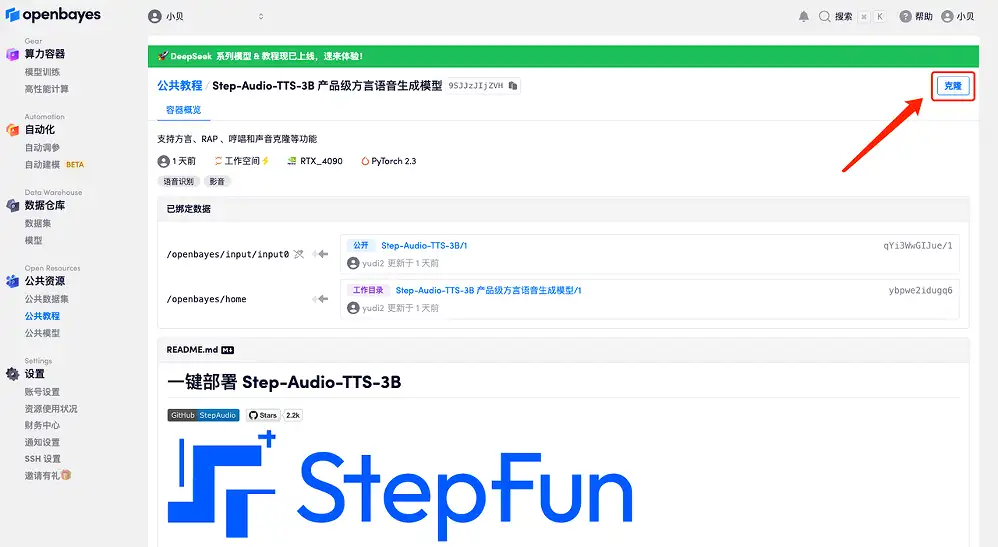
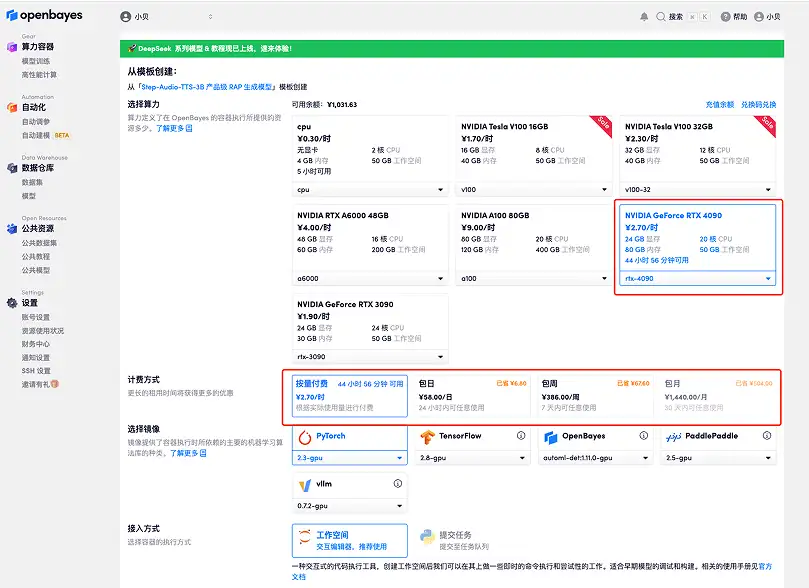
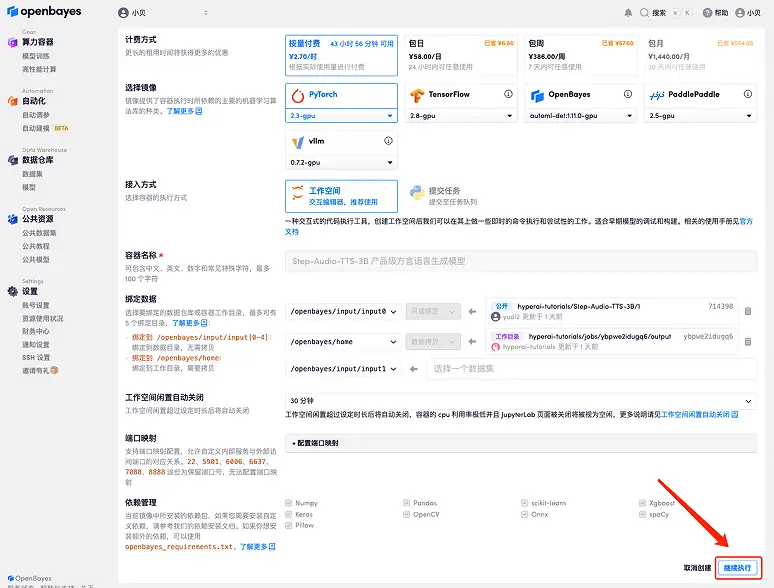
3. 「NVIDIA RTX A6000」と「PyTorch」イメージを選択します。OpenBayes プラットフォームは新しい課金方法を導入しました。ニーズに応じて、「従量課金制」または「日次/週次/月次パッケージ」を選択できます。「続行」をクリックします。新規ユーザーは、以下の招待リンクを使用して登録すると、4 時間の RTX 4090 + 5 時間の CPU フリータイムを獲得できます。
HyperAI ハイパーニューラルの専用招待リンク (ブラウザに直接コピーして開きます):
https://openbayes.com/console/signup?r=Ada0322_QZy7
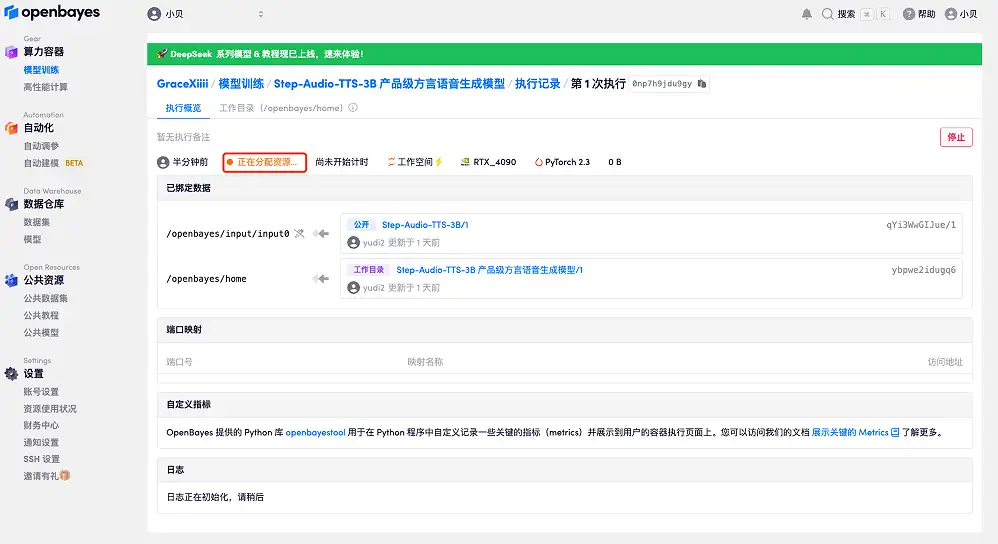
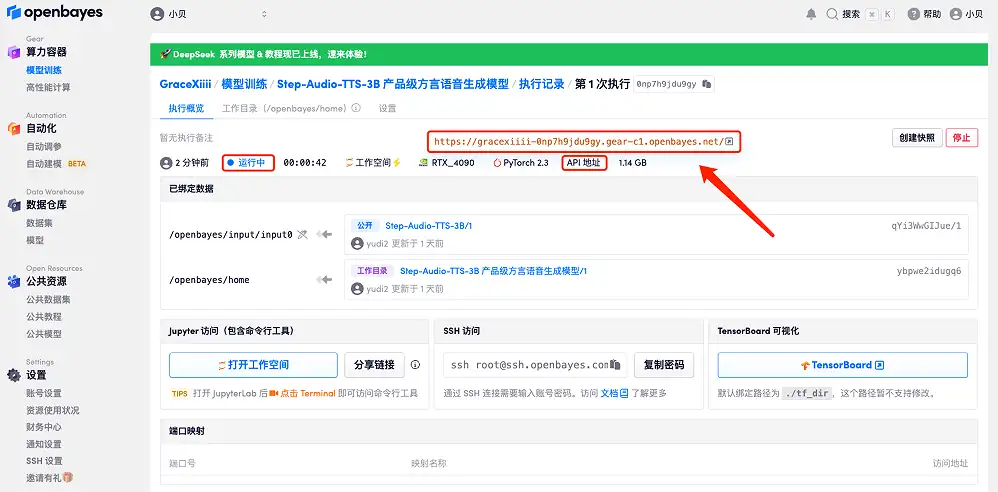
4. リソースが割り当てられるのを待ちます。最初のクローン作成プロセスには約 2 分かかります。ステータスが「実行中」に変わったら、「API アドレス」の横にあるジャンプ矢印をクリックしてデモ ページに移動します。 APIアドレスアクセス機能を使用する前に、ユーザーは実名認証を完了する必要がありますのでご注意ください。

エフェクト表示
このチュートリアルには、一般的な音声合成、音楽合成、音声複製の 3 つの機能が含まれています。
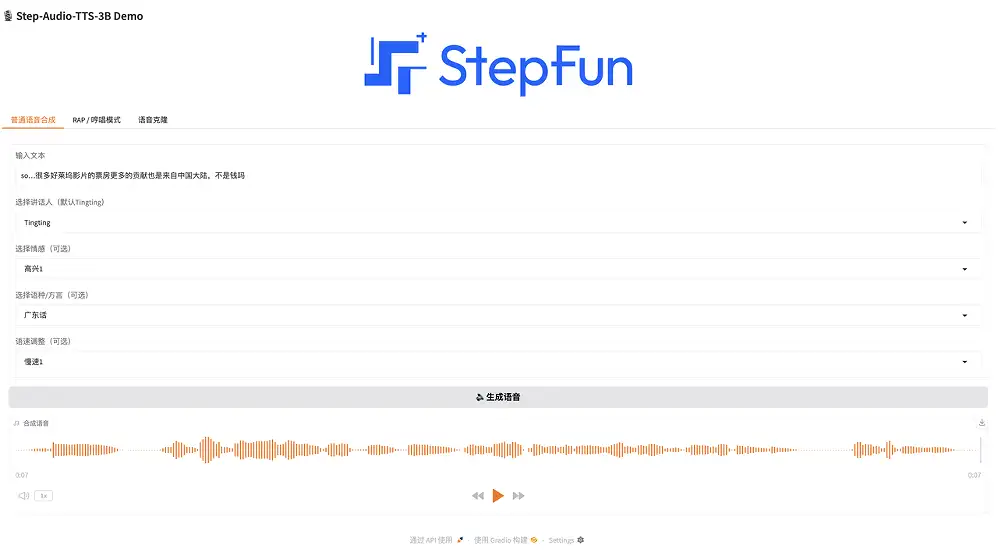
1. 一般的な音声合成
この機能は、公式のデフォルトの音声キャラクターであるティンティンと新しく追加された音声であるネザをプリセットし、多言語生成、感情、方言などの設定をサポートします。
音声合成トーンの説明
* ティンティンという音は公式の4sオーディオプロンプトファイルによって生成されます
* 哪哪の音は、14秒の音声プロンプト「私は第三王子哪哪です。私は気ままで詩を書くのが大好きです。ポケットに手を入れて歩き、曲がった道もまっすぐにすることができます」ファイルから生成されています。
デモ ページで、「通常の音声合成」を選択し、テキストを入力し、話者 (デフォルトは Tingting) を選択し、感情 (幸せ、怒り、悲しみ、コケティッシュ) を選択し、言語/方言 (中国語、英語、日本語、北京語、四川語、広東語、広東語) を選択し、発話速度 (速い、遅い) を選択します。 「音声の生成」をクリックするだけです。
2. 音楽合成
この機能は公式サイトのデフォルトの音声キャラクターであるティンティンと新しく追加された哪吒の音色をプリセットしており、RAPやハミングもサポートしています。
RAPサウンドの説明
* ティンティンという音は、公式の11sオーディオプロンプトファイルによって生成されます。
* 哪吒の音は、14 秒のオーディオ プロンプト「雷が鳴り響き、とても怖い。全身に雷が落ちてくる。トランペットを吹いて運命を変える。笑って災難を乗り越える。チクタクチクタク」ファイルによって生成されます。
ハミングトーンの説明
* ティンティンという音は12秒のオーディオプロンプトファイルによって生成されます
* 哪吒の音は、14秒の音声プロンプト「私は恐れ知らずで生まれ、父が誰であろうと、主が支配者を倒せば、私に命令することは決してできない」によって生成されます。
デモページで「音楽合成」を選択し、テキストを入力し、スピーカー(デフォルトはTingting)を選択し、モード(RAPまたはハミング)を選択します。 「RAP/ハミングを生成」をクリックするだけです。

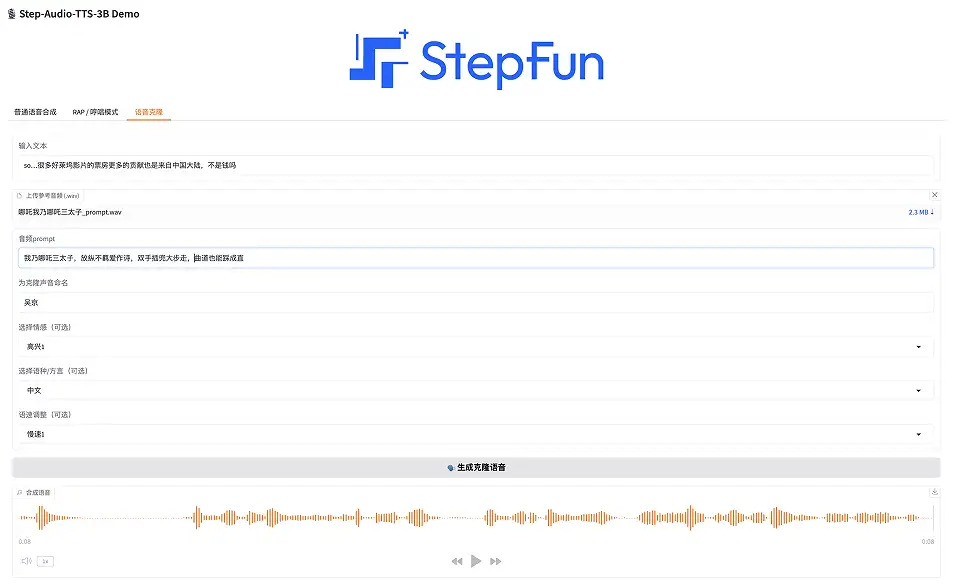
3. 音声クローン
この機能は、ユーザーがカスタム音色のオーディオをアップロードし、パーソナライズされた音声を生成することをサポートします。
デモ ページで [音声の複製] を選択し、テキストを入力し、参照オーディオ (.wav 形式) をアップロードし、複製された音声に名前を付け、感情 (幸せ、怒り、悲しみ、コケティッシュ) を選択し、言語/方言 (中国語、英語、日本語、北京語、四川語、広東語、広東語) を選択し、発話速度 (速いまたは遅い) を選択します。 「クローン音声の生成」をクリックするだけです。