Command Palette
Search for a command to run...
オンラインチュートリアル|600以上の言語に対応、XiaomiがOmniVoiceをオープンソース化:わずか3~10秒の参照音声で音声クローンを実現

AI音声技術の急速な発展に伴い、テキスト音声合成(TTS)モデルは「話せる」レベルから「人間のように自然にコミュニケーションできる」レベルへと進化しつつあります。しかしながら、既存のシステムは依然として、複雑な生成リンク、高い学習コスト、多言語対応、ゼロサンプル音声クローニング、複雑なアクセントや方言への対応といった点で、言語横断的な汎化能力の限界といった問題を抱えています。
こうした背景のもと、OmniVoiceのリリースは多言語音声生成における新たなブレークスルーとなる。Xiaomi AI Labの次世代Kaldiチームによって開発されたこのモデルは、600以上の言語をサポートし、音声クローン、音声デザイン、自動音声機能を備えている。TTSモデルで一般的に使用されている「テキスト→意味→音響」という従来の2段階生成プロセスと比較して、OmniVoiceは拡散言語モデルに似た離散非自己回帰(NAR)アーキテクチャを採用し、テキストをマルチコードブックの音響トークンに直接マッピングすることで、音声生成プロセスを大幅に簡素化している。
このアーキテクチャの変更により、複雑な処理における従来の離散型NARモデルのパフォーマンスボトルネックが軽減されるだけでなく、OmniVoiceは音声の自然さ、明瞭度、および言語間の一貫性においてより優れたパフォーマンスを実現できます。同時に、このモデルはフルコードブックランダムマスク学習戦略を導入し、事前学習済みの大規模言語モデルに基づいて初期化されるため、学習効率が向上し、音声生成の品質がさらに向上します。
さらに重要なのは、OmniVoiceは単なる「多言語」TTSモデルではないということです。中国語、英語、日本語、韓国語といった主要言語だけでなく、河南方言、四川方言、東北方言といった中国語の方言、そしてアメリカ英語、イギリス英語、オーストラリア英語、インド英語といった様々な英語のバリエーションにも対応しています。わずか数秒の参照音声だけでゼロサンプル音声クローンを作成できる機能と組み合わせることで、AI音声合成、デジタルヒューマン、多言語コンテンツ生成、グローバルな音声対話といった分野で計り知れない応用可能性を発揮します。
現在、HyperAIの公式サイト(hyper.ai)のチュートリアルセクションでは、「OmniVoice:600以上の言語に対応した高品質TTS」が公開されており、ワンクリックで開始でき、導入のハードルも低くなっています。
オンラインで実行:
その他のオンラインチュートリアル:
より詳しい情報については、弊社の公式ウェブサイトをご覧ください。
デモの実行
1. hyper.ai のホームページにアクセスしたら、「チュートリアル」ページを選択するか、「その他のチュートリアルを見る」をクリックし、「OmniVoice: 600 以上の言語をサポートする高品質 TTS」を選択して、「このチュートリアルを実行する」をクリックします。
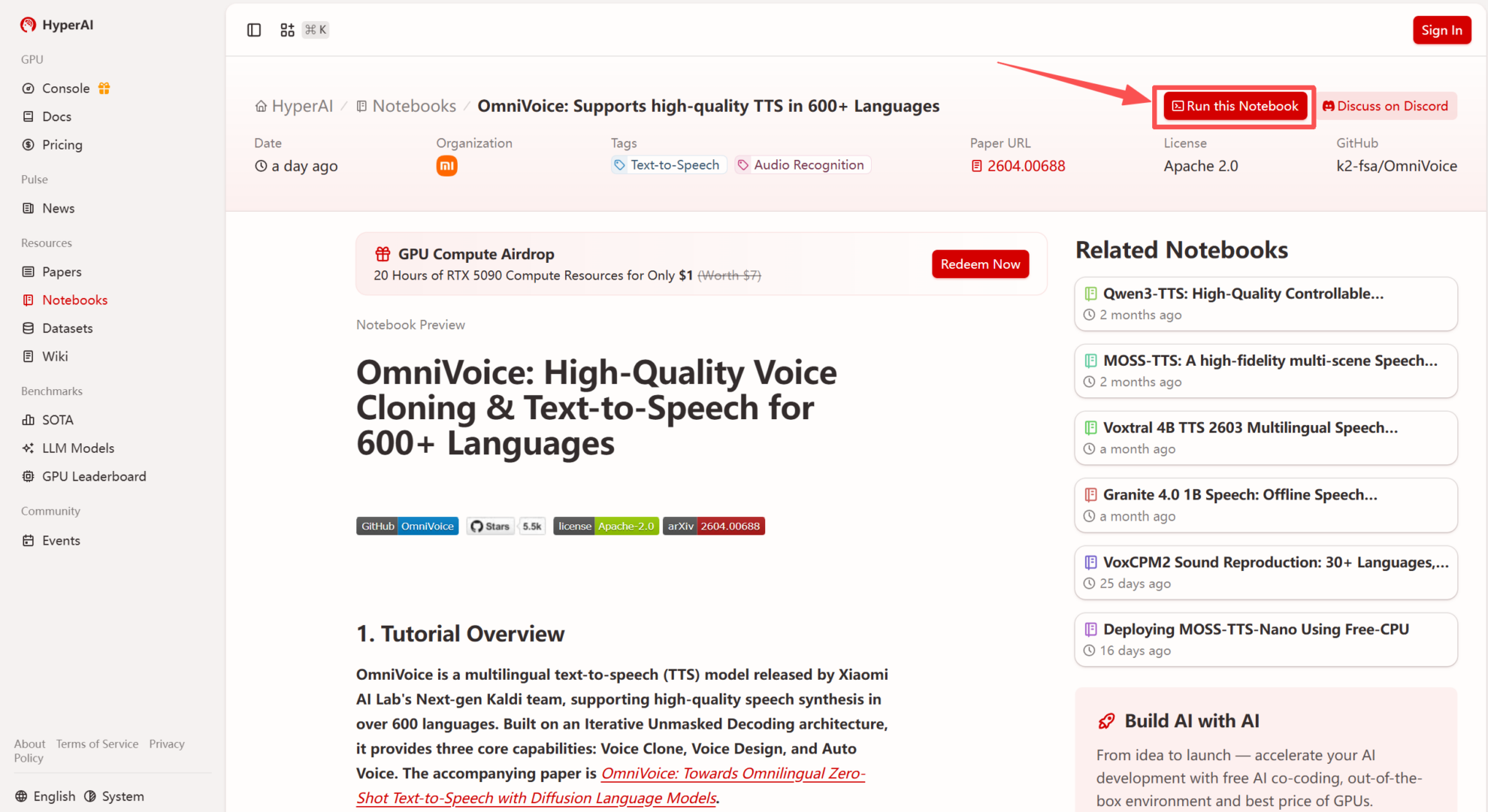
2. ページがリダイレクトされたら、右上隅の「複製」をクリックして、チュートリアルを独自のコンテナーに複製します。
注:ページの右上で言語を切り替えることができます。現在、中国語と英語が利用可能です。このチュートリアルでは英語で手順を説明します。
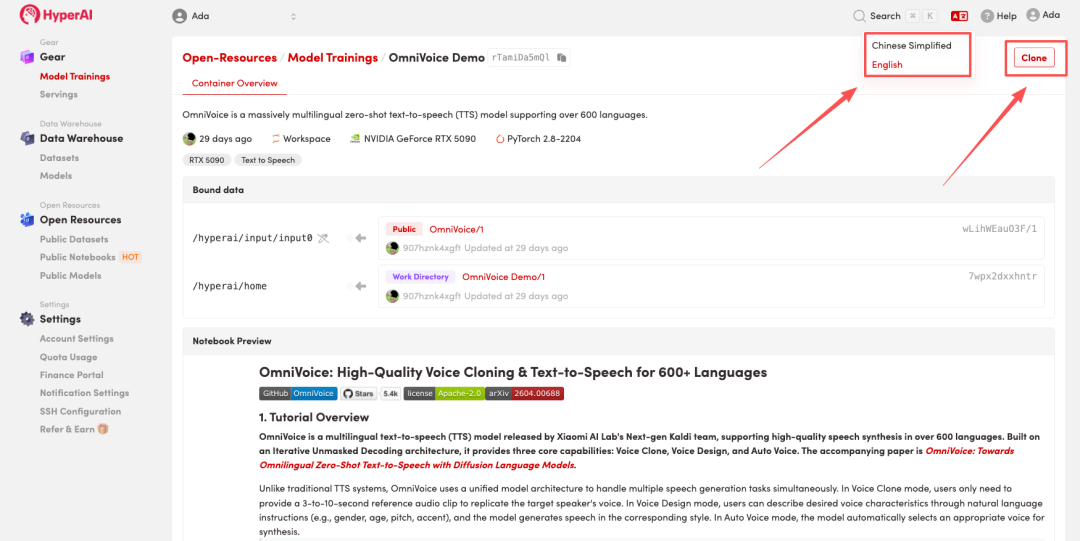
3. 「NVIDIA RTX 5090」と「PyTorch」の画像を選択し、「ジョブの実行を続行」をクリックします。
HyperAI は新規ユーザー向けに登録ボーナスを提供しています。わずか $1 で、RTX 5090 のコンピューティング パワー (元の価格は $7) を 20 時間利用でき、リソースは無期限に有効です。
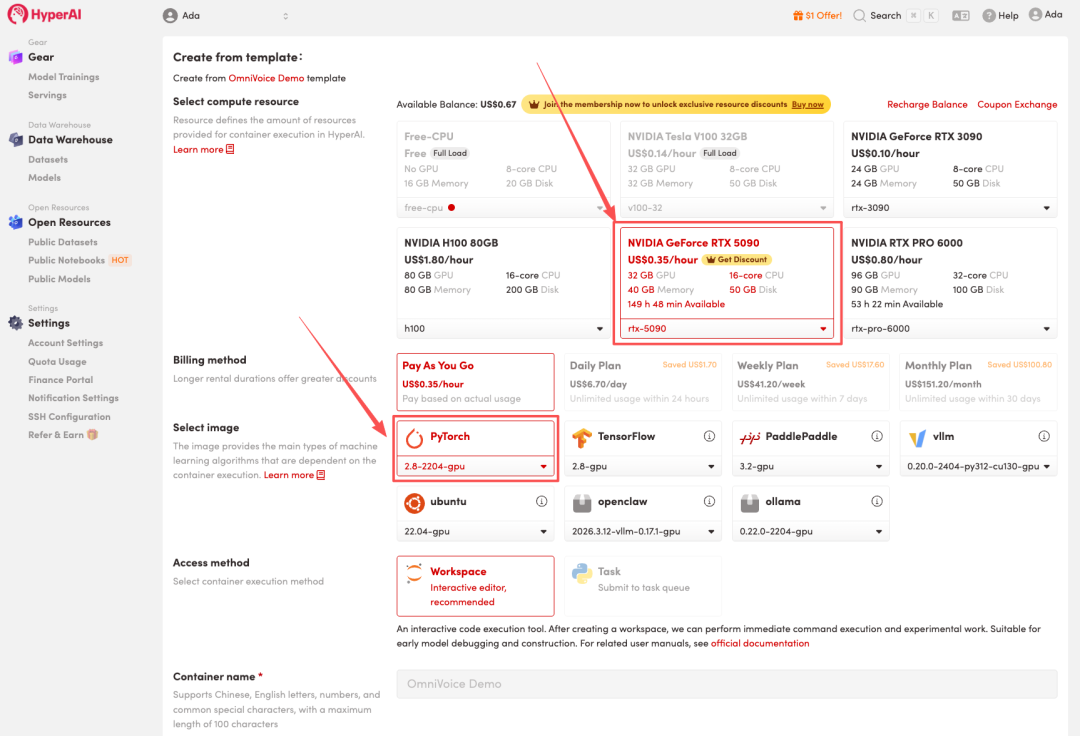
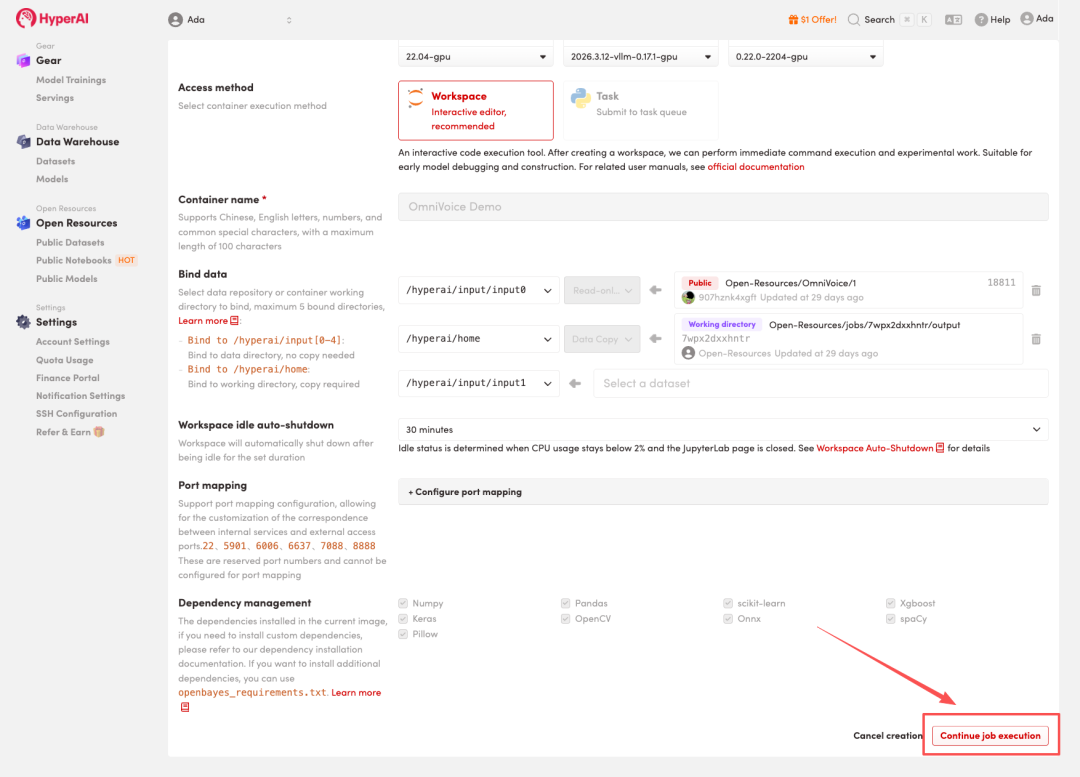
4. リソースが割り当てられるのを待ちます。ステータスが「実行中」に変わったら、「ワークスペースを開く」をクリックしてJupyterワークスペースに入ります。
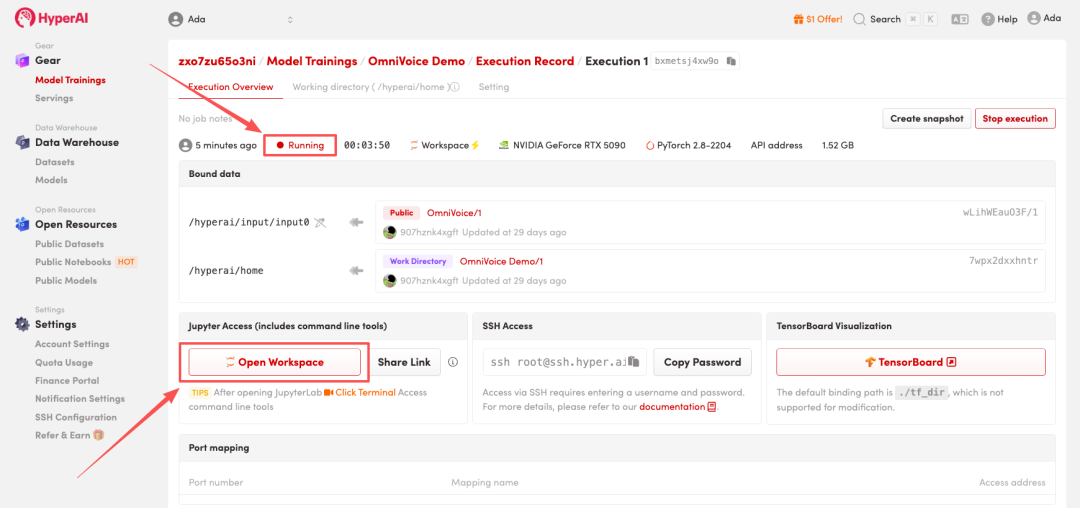
エフェクト表示
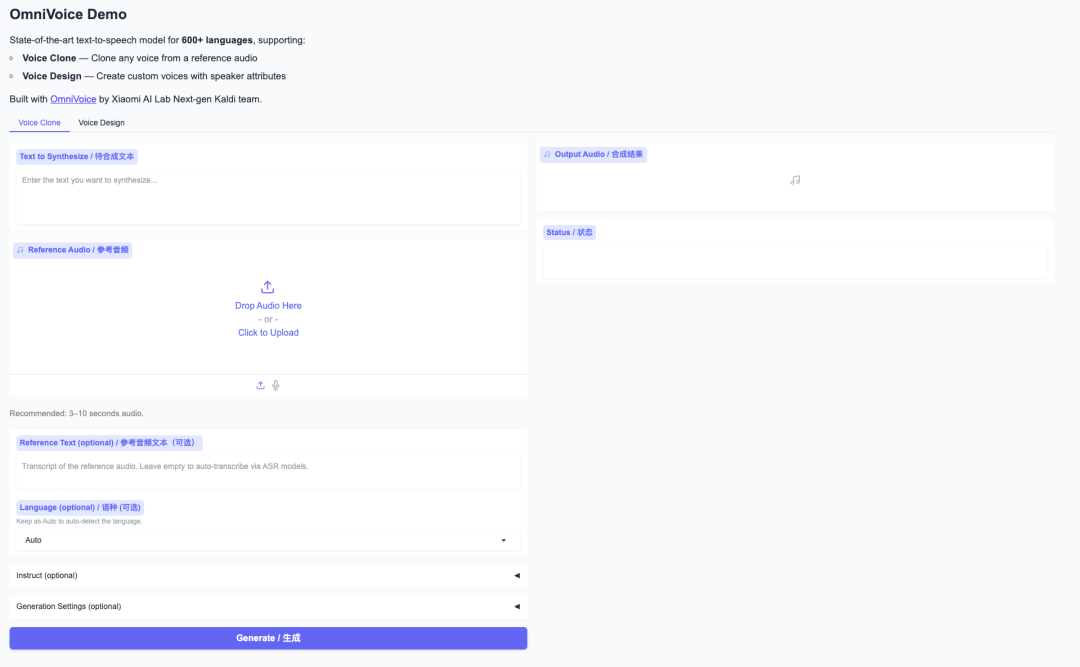
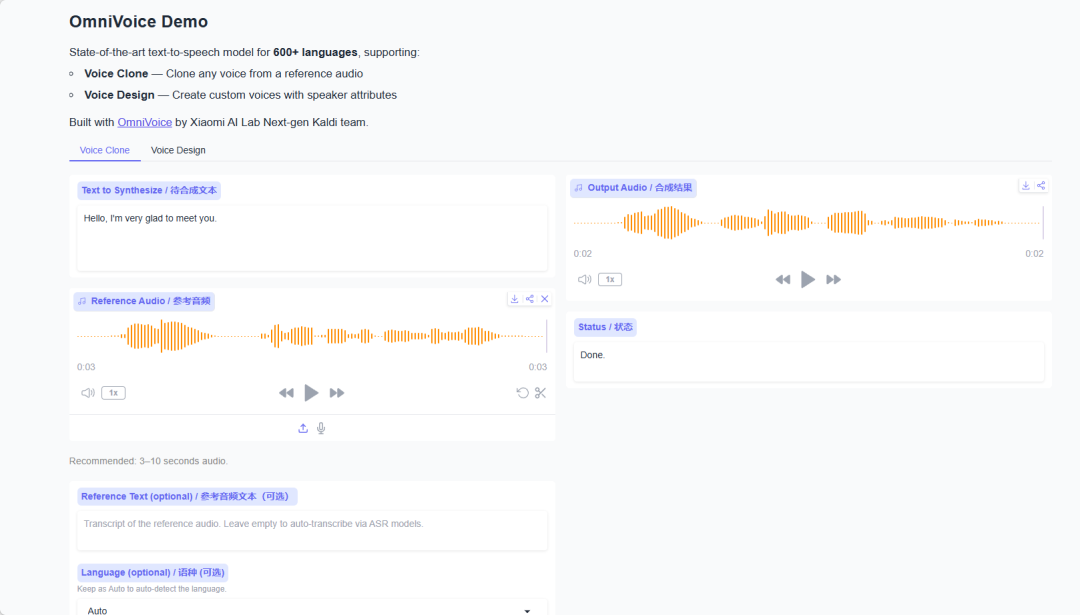
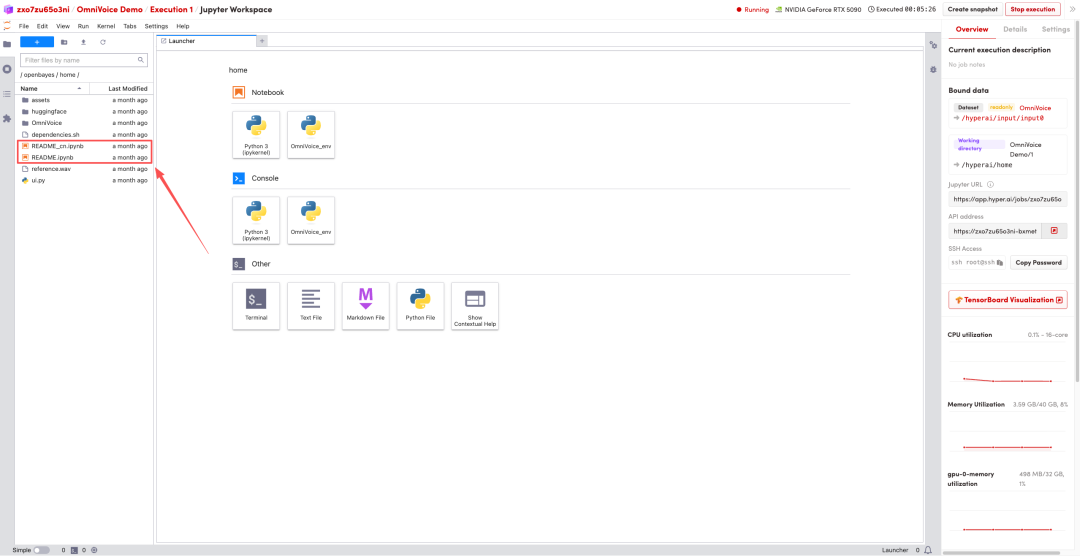
1. ページがリダイレクトされたら、左側のREADMEファイルをクリックし、上部の「実行」をクリックします。
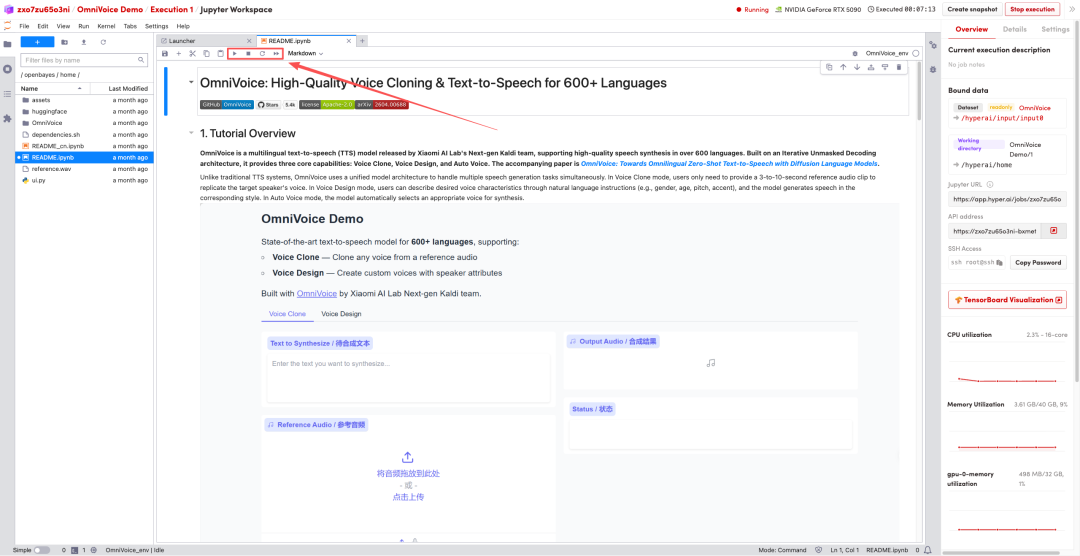
2. 処理が完了したら、右側のAPIアドレスをクリックしてデモページに移動します。