Command Palette
Search for a command to run...
彼女は脳卒中以来 18 年間失語症を患っていますが、AI とブレイン コンピューター インターフェイスが「自分の考えを声に出す」のに役立っています。

ツヴァイクはかつてこう言った。人の人生における最大の幸運は、人生の半ば、まだ若くて強いときに自分の天職を発見することである。
そして人間の最大の不幸とは何でしょうか?
編集者の意見では、人の人生における最大の不幸は、働き盛りの時期に突然、話すことも動くこともすべてできなくなることほど良いことはありません。——一夜にして、夢もキャリアも希望も全て無に帰し、人生は一変した。
アンはその残念な代表者です。
30歳のとき、彼は脳卒中を患い、言葉を失いました。
2005 年のある日、いつも健康だったアンさんは突然、めまい、ろれつが回らない、四肢麻痺、筋力低下などの症状を発症しました。脳幹梗塞(これを私たちは毎日「脳卒中」と呼んでいます)、左椎骨動脈解離と脳底動脈閉塞を伴う。
この予期せぬ脳卒中により、アンは「」と呼ばれる病気を患いました。閉じ込め症候群この病気の副産物として、この病気の患者はすべての感覚と意識を持っていますが、体の筋肉を動かすことができず、自力で動くことも話すこともできず、呼吸ができない人もいます。
「鍵をかける」という文字通りの意味が反映しているように、一般の人々が何千もの山や川を旅するように導いた体は、患者の魂を封印する檻になっています。
当時、アンはまだ 30 歳、結婚して 2 年 2 か月、娘は生後 13 か月で、カナダの高校で数学教師として働いていました。 「一夜にしてすべてが私から奪われました。」 アンはその後、デバイスを使用してこの文をコンピューターにゆっくりと入力しました。

アンが呼吸し、頭を少し動かし、瞬きし、いくつかの言葉を発するまでに、何年もの理学療法が必要でしたが、それ以上は何もできませんでした。
通常の生活では、平均的な人は次のようなスピードで話します。 160~200ワード/分2007年から2007年にかけて、アリゾナ大学心理学部の研究結果によると、男性は平均して次のように言う。 15,669 平均的な女性はこう言います 16,215 単語 (平均して、1 単語は 1.5 ~ 2 文字の漢字に相当します)。
言語が対人コミュニケーションの主な手段である世界では、表現が制限されているアンのどれほど多くのニーズが沈黙させられているでしょうか?失語症によって失われるのは、生活の質だけではなく、人格やアイデンティティも失われます。そしてアンと同じ状況にある麻痺失語症の人は世界中に何人いるのでしょうか?
18年間の麻痺を経て再び口を開いた
完全かつ自然なコミュニケーション能力を回復することは、麻痺により失語症になったすべての人の最大の願いです。科学技術が高度に発達した今日、テクノロジーの力を利用して患者の対人コミュニケーション能力を取り戻す方法はあるのでしょうか?
持っている!
最近、カリフォルニア大学サンフランシスコ校とカリフォルニア大学バークレー校の研究チームがAIを活用した新たなブレインコンピューター技術の開発18年間言葉を失っていたアンが自分を取り戻すことができるようになります。 「話してください」、デジタルアバターに基づいて鮮やかな画像を生成します表情、通常の人間の社会的相互作用と一致する速度と品質で、患者がリアルタイムで他の人と会話できるようにします。

音声と表情が脳信号から合成されるのは人類史上初めてです。
カリフォルニア大学のチームによるこれまでの研究では、麻痺した人の脳活動から言語を解読することは可能であるが、それはテキスト形式であり、速度と語彙も限られていることが示されている。
今回、彼らはさらに一歩前進したいと考えています。豊富な語彙を使ったより高速なテキストコミュニケーションが可能になり、会話に伴う声や顔の動きが復元されます。
研究チームは機械学習とブレイン・コンピューター・インターフェース技術に基づいて次の成果を達成し、2023年8月23日付けの「Nature」に掲載された。
►のための文章、被験者の脳信号を毎分 78 ワードの速度でテキストにデコードし、平均単語誤り率は 25%、対象者の現在の通信デバイス(14ワード/分)よりも4倍以上高速です。
►向け音声オーディオ、脳信号を迅速に合成して、被験者の受傷前の音と一致する、理解できるパーソナライズされた音を生成します。
►向け顔のデジタルアバター、音声および非音声通信ジェスチャの仮想顔の動きの制御を可能にします。

論文リンク:
https://www.nature.com/articles/s41586-023-06443-4
きっと好奇心旺盛でしょうね、この画期的な奇跡はどのようにして成し遂げられたのでしょうか?次に、この論文を詳細に分解して、研究者たちがどのようにして復活したのかを見てみましょう。
1. 基礎となるロジック 脳信号 → 音声 + 表情
人間の脳は末梢神経や筋肉組織を通じて情報出力を実現しており、言語能力は大脳皮質の脳によって制御されています。 「ランゲージセンター」制御されている。
脳卒中患者が失語症になる理由は、血液循環が遮断され、酸素や重要な栄養素の不足により脳の言語野が損傷し、1つまたは複数の言語伝達機構が適切に機能しなくなり、言語機能障害が生じるためです。 。
これに関して、カリフォルニア大学サンフランシスコ校とバークレー校の研究チームは、 「マルチモーダル音声神経補綴」、大規模で高密度の皮質脳波検査(ECoG)を使用して、感覚皮質(SMC)全体に分布する調音路によって表されるテキストおよび視聴覚音声出力をデコードします。つまり、ソースから脳信号をキャプチャし、それらを技術的な方法で変換します。対応するテキスト、音声、さらには顔の表情に翻訳することを意味します。
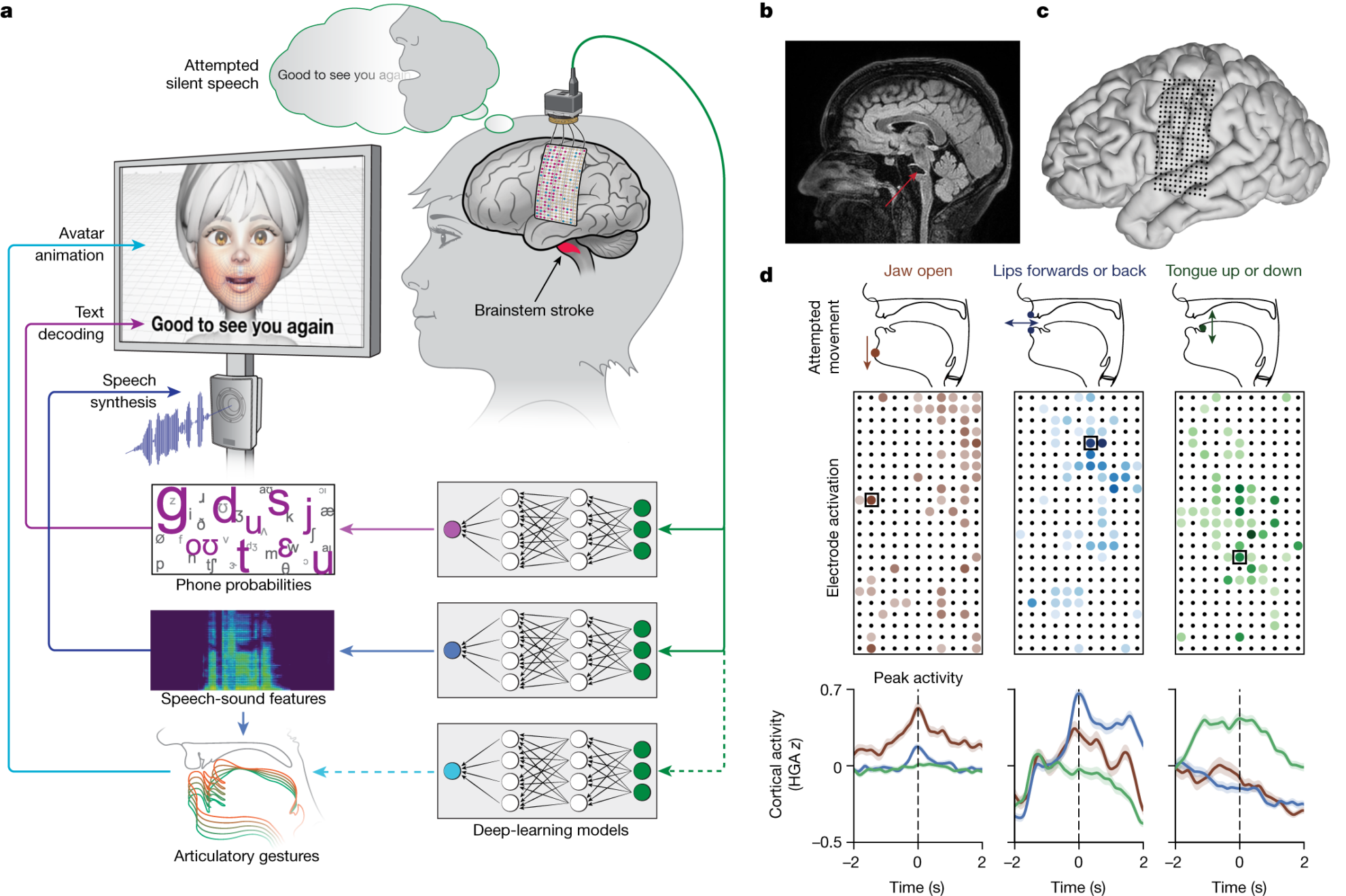
2. プロセスと実装 ブレインコンピューターインターフェース + AIアルゴリズム
一つ目は物理的手段です。
研究者らは、アンの脳の左半球の上面にある硬膜を介してデバイスを埋め込んだ。高密度EEGアレイそして経皮ベースコネクター、音声生成と音声認識に関連する領域をカバーします。
配列は次のもので構成されます 253これは、アンの舌、顎、喉、顔の筋肉に送られた脳信号を傍受するために使用されるディスク状の電極で構成されています。アンの頭に取り付けられたポートにケーブルが差し込まれ、電極が一連のコンピューターに接続されます。

2つ目はアルゴリズムの構築です。
アンのユニークな脳音声信号を識別するには、研究チームは彼女と数週間を費やして深層学習モデルのトレーニングと評価を行いました。
研究者らは、nltk Twitter コーパスと Cornell 映画コーパスに基づいて 1,024 語の普遍的な文のセットを作成し、アンに自然な話す速度で黙って話すように指示しました。彼女は 1,024 語の会話語彙からさまざまなフレーズを何度も繰り返しつぶやきました。コンピューターがこれらの音に関連する脳活動のパターンを特定するまで。
このモデルは単語全体を認識するように AI をトレーニングしないことに注意してください。その代わりにシステムが作られました単語を「音素」から解読する、「Hello」などには、「HH」、「AH」、「L」、「OW」の 4 つの音素が含まれています。
この方法に基づくと、コンピューターは英単語を解読するために 39 音素を学習するだけで済みます。精度が向上するだけでなく、速度も 3 倍向上します。
注: 音素は言語の最小の音単位であり、調音場所、調音方法、声帯振動などを含む音声の発音特性を記述することができます。たとえば、an の音素は /ə/ と /n/ で構成されます。 。
この音素解読プロセスは、赤ちゃんが話すことを学ぶプロセスに似ています。発達言語学の分野で現在受け入れられている見解によると、生まれたばかりの赤ちゃんは世界中の言語の慣用句を区別することができます。 800 個人の音素。未就学児は言葉の書き方や意味を理解できないかもしれませんが、音素の知覚、区別、模倣を通じて言語の発音と理解を徐々に学ぶことができます。
最後に、音声と表情の合成です。
基礎が整いましたので、次のステップは声と表情の表現です。研究者合格音声合成そしてデジタルアバターこの問題を解決するには。
音声面、研究者らは、デジタルアバターをできるだけ彼女に近づけるために、脳卒中前のアンさんの声の録音を使用した合成音声アルゴリズムを開発した。
表情, アンのデジタル アバターは、Speech Graphics が開発したソフトウェアを使用して作成され、アニメーション化された女性の顔として画面上に表示されます。
研究者は機械学習プロセスを次のようにカスタマイズしました。アンが話そうとするときにソフトウェアを脳からの信号に合わせて調整するこれにより、顎の開閉、唇の突出と引っ込み、舌の上下の動き、喜び、悲しみ、驚きを表現する顔の動きや身振りを表現します。

今後の展望
カリフォルニア大学サンフランシスコ校の脳神経外科部長、エドワード・チャン医学博士は、「目標は、完全で体現されたコミュニケーション形態を回復することだ」と語った。、私たちが他の人と会話するための最も自然な方法... 可聴音声と実際の人のアバターを組み合わせるという目標により、単なる言葉をはるかに超えた、人間の言語コミュニケーションの完全な表現が可能になります。
研究チームの次のステップは次のとおりです。ワイヤレスバージョンを作成する、ブレインコンピューターインターフェースの物理的な接続を取り除く、麻痺のある人々がこのテクノロジーを使用して個人の携帯電話やコンピューターを自由に制御できるようになり、彼らの自立と社会的交流に大きな影響を与えるでしょう。
携帯電話の音声アシスタントや電子顔認識決済から、工場のロボットアームや生産ラインの仕分けロボットまで、AI は人間の手足や顔の特徴を拡張し、私たちの生産や生活のあらゆる側面に徐々に浸透しています。
研究者らは、麻痺した失語症患者の特殊なグループに注目し、AIの力を利用して彼らが本来のコミュニケーション能力を回復できるようにすることで、患者と親戚や友人との接触を促進し、対人交流を取り戻す機会を拡大することが期待されている。そして最後に言及した患者の高い生活の質。
私たちはこの成果に興奮しており、AI が人類に利益をもたらすという更なる朗報を期待しています。
参考リンク:
[1] https://www.sciencedaily.com/releases/2023/08/230823122530.htm
[2] http://mrw.so/6nWwSB








