Command Palette
Search for a command to run...
30,000 人以上のユーザーによって投票され、収集が推奨された 6 つの古典的な機械学習データ セット

内容概要: この号では、画像認識、機械翻訳、リモート センシング画像などの分野をカバーする、Super Neural によって広くダウンロードされている 6 つのデータ セットをまとめています。これらのデータセットは高品質でデータ量が多いため、収集して保存する価値があることが証明されています。 キーワード: データセット、機械翻訳、マシンビジョン
データセットは機械学習モデルトレーニングの基礎です。高品質の公開データセットは、モデルトレーニングの有効性と研究結果の信頼性にとって非常に重要です。
HyperAI は、その立ち上げ以来、データ サイエンスの専門家に多数の高品質の公開データ セットを提供してきました。この号のコンテンツ共有のために、6 つの人気のあるデータ セットを選別しました。累計ダウンロード数は32,569回に達した。これらのデータセットが大多数の開発者にさらに役立つことを願っています~
注: この記事で取り上げたデータセットはすべて Web サイトからのものです。
No. 6: Tanks Temple 3D 再構築データセット
発行機関:インテル研究所
含まれる数量:21種類のオブジェクトのHDビデオ
データ型:ビデオ
推定サイズ:52.53GB
発売時期:2017年
ダウンロードアドレス:hyper.ai/datasets/5148

Tanks Temple 画像データセットは、研究者が画像を収集できる高解像度ビデオを提供します。画像をもとに三次元再構成を行います。このデータ セットにはトレーニング データとテスト データの 2 つのカテゴリが含まれており、テスト データは中級グループと上級グループに分類されます。
第5位:DOTA航空画像データセット
発行機関:武漢大学
含まれる数量:2,806 枚の航空写真
データ型:画像
推定サイズ:35.38GB
発売時期:2017年
ダウンロードアドレス:hyper.ai/datasets/4920

DOTA は、A Large-scale Dataset for Object DeTection in Aerial Images の略で、2,806 枚の航空写真を含む画像データ セットです。航空画像内の物体検出、画像内の物体の発見と評価に使用されます。
これらの画像ソースには、さまざまなセンサーやプラットフォームが含まれます。各画像のピクセル サイズは 800*800 から 4000*4000 の範囲で、さまざまなスケール、方向、形状のオブジェクトが含まれています。
過去の更新情報については、以下をご覧ください。
DOTA データセット: 2,806 個のリモート センシング画像、約 190,000 個の注釈付きインスタンス
4位:VGG-Face2 顔認識データセット
発行機関:オックスフォード大学
含まれる数量:331万枚の画像
データ型:画像
推定サイズ:37.49GB
発売時期:2015年
ダウンロードアドレス:hyper.ai/datasets/5711

VGG-Face2 は、合計 9131 人の顔データを含む顔画像データ セットです。画像はすべて Google の画像検索から取得したものです。データセット内の人々は、姿勢、年齢、人種、職業が大きく異なります。このデータセットは、2015 年にオックスフォード大学工学部の Visual Geometry Group によってリリースされました。関連論文には「Deep Face Recognition」などがあります。
その3:UCAS-AODリモートセンシング画像データセット
発行機関:中国科学院大学
含まれる数量:910枚の画像
データ型:画像
推定サイズ:3.24GB
発売時期:2014年
ダウンロードアドレス:hyper.ai/datasets/5419

UCAS-AOD はリモートセンシング画像データセットです。航空機や車両の検査に。このデータセットは、2014 年に国立科学技術大学によって初めて公開され、2015 年に補足されました。関連論文には、「深層畳み込みニューラル ネットワークを使用した航空画像における方向性ロバスト オブジェクト検出」などがあります。
No. 2: OpenMantra 漫画機械翻訳データセット
発行機関:東京大学
含まれる数量:214ページのコミック
データ型:JSON ファイル、画像
推定サイズ:32.46MB
発売時期:2020年
ダウンロードアドレス:hyper.ai/datasets/14137
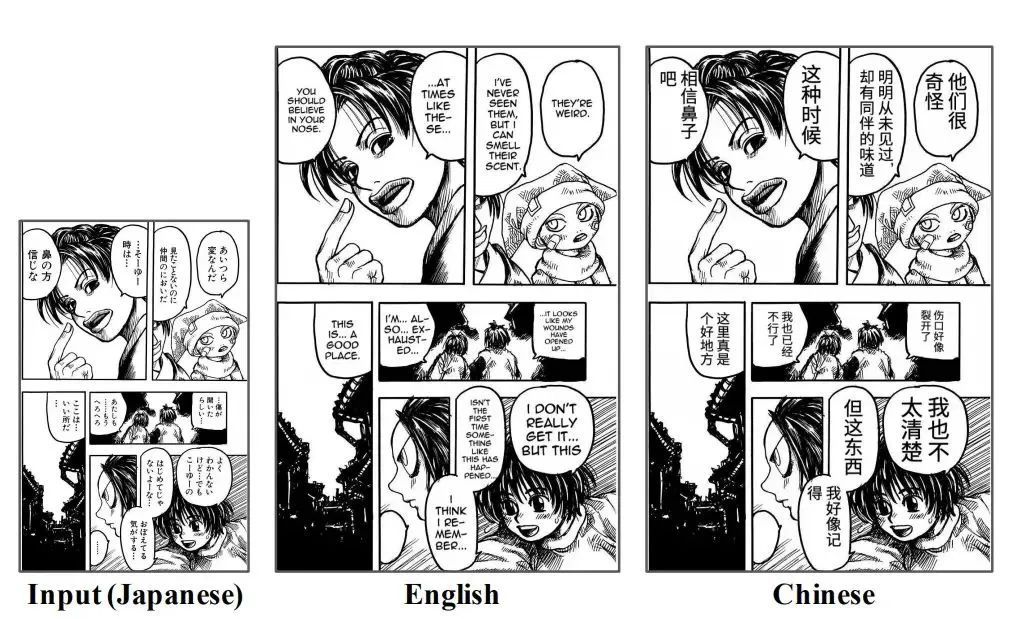
OpenMantra は、5 つの異なるスタイル (ファンタジー、ロマンス、バトル、ミステリー、日常生活) の漫画を含む、日本の漫画の機械翻訳評価データ セットです。データセットには合計 1593 文、848 シーン、214 ページの漫画が含まれています。東京大学マントラチーム発行。
以前のリリースをチェックしてください:
HyperAI Super Neural: 漫画翻訳、埋め込み AI、東京大学の論文が AAAI'21 に掲載されました 3 同意 · 1 コメント
No. 1: ImageNet 10 画像認識データセット
発行機関:プリンストン大学
含まれる数量:1,500万枚の画像
データ型:画像
推定サイズ:860.55GB
発売時期:2009年
ダウンロードアドレス:hyper.ai/datasets/4889

ImageNet は、スタンフォード大学の Li Feifei 教授らが作成した、現在世界最大の画像認識データベースです。主にマシンビジョンの分野で画像分類とターゲット検出に使用されます。
データセットは WordNet 階層に従って編成されており、各ノード (カテゴリとも呼ばれます) は数百、場合によっては数千の画像で構成されています。データ セットには、合計 22,000 の画像カテゴリと約 1,500 万枚の画像が含まれています。
過去の更新情報については、以下をご覧ください。
この年のこの決定により、李飛飛は AI 世界の女王としての地位を確立しました mp.weixin.qq.com/s/VyKUmG512pFJ3XTgVf4Qjg
上記は、この号で推奨される 6 つの hyper.ai 高頻度ダウンロード データ セットです。その他のデータ サイエンスの高品質な公開データ セットについては、記事の最後をクリックしてください。元の記事を読んで、または、次のリンクにアクセスしてダウンロードしてください。
この記事は、WeChat パブリック アカウント「HyperAI Super Neural」から最初に公開されたものです。原文は「」でご覧いただけます。30,000 人以上のユーザーによって投票され、収集が推奨された 6 つの古典的な機械学習データ セット』
- 以上 -








