前回のエピソードの復習
-
60 年間にわたる機械翻訳のゆっくりとした発展
-
ルールベースの機械翻訳 (RBMT)
-
用例ベースの機械翻訳 (EBMT)
")
この記事の(前編)を読むには画像をクリックしてください
統計的機械翻訳 (SMT)
1990 年初頭、IBM Research で、ルールや言語学について何も知らない機械翻訳システムが初めて実証されました。以下の画像内のテキストを 2 つの言語で分析し、パターンを理解しようとしました。
")
アイデアはシンプルで美しいです。どちらの言語でも、同じ文がいくつかの単語に分割されてから再組み立てされます。この操作は約 5 億回繰り返されました。たとえば、「Das Haus」という単語は、「家」対「建物」対「建設」などに翻訳されました。
ほとんどの場合、ソース単語 (たとえば「Das Haus」) が「家」として翻訳される場合、マシンはデフォルトでこの意味を設定します。ルールを設定したり辞書を使用したりしなかったことに注意してください。すべての結論はデータとロジックに基づいて機械によって下されました。翻訳するとき、機械は「人々がこのように翻訳するなら、私も同じように翻訳します」と言っているようです。このようにして、統計的機械翻訳が誕生しました。
")
より効率的かつ正確で、言語学者を必要としないという利点があります。使用するテキストが増えるほど、より良い翻訳が得られます。
")
(Google内からの統計翻訳:この意味の使用確率を示すだけでなく、他の意味の統計も実行します)
もう一つ質問:
機械はどのようにして「Das Haus」という単語と「building」という単語を結びつけるのでしょうか?また、これらが正しい翻訳であることはどのようにしてわかるのでしょうか?
答えは分かりません。
最初、機械は「Das Haus」という単語が翻訳文中のどの単語とも同じ相関関係を持っていると仮定します。その後、「Das Haus」が他の文に現れると、「house」との相関関係が高まります。これは、学校レベルの機械学習の典型的なタスクである「単語アライメント アルゴリズム」です。
機械は各単語に関する統計情報を収集するために 2 つの言語で何百万もの文章を必要とするので、この言語情報をどのように取得するか? 私たちは欧州議会と国連安全保障理事会の会議の概要を取得することにしました。すべての加盟国の言語で提示されるため、資料収集にかかる時間を大幅に節約できます。
-
WordベースのSMT
当初、最初の統計翻訳システムは文を単語に分割しました。この方法は単純で論理的であったため、IBM の最初の統計翻訳モデルは「モデル 1」と呼ばれていました。
モデル 1: 言葉のバスケット
")
モデル 1 では、単語に分割して統計をカウントするという古典的なアプローチを使用しますが、語順を考慮せず、唯一のトリックは 1 つの単語を複数の単語に翻訳することです。たとえば、「Der Staubsauger」は「The Vacuum Cleaner」になる可能性がありますが、これは「The Vacuum Cleaner」になるという意味ではありません。
モデル 2: 文内の単語の順序を考慮する
")
モデル 1 の主な制限は、語順が欠如していることです。これは翻訳プロセスにおいて非常に重要です。モデル 2 の登場により、この問題が解決されました。出力文内の単語の通常の位置を記憶し、中間ステップでそれらを再シャッフルすることで、翻訳がより自然になります。
それで、状況は良くなったでしょうか?あまり。
モデル 3: 新しい単語を追加する
")
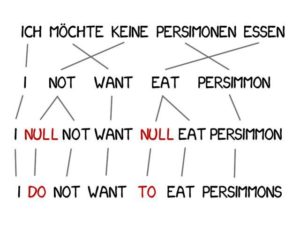
翻訳では、意味を改善するために新しい単語を追加する必要があることがよくあります。たとえば、英語で何かを否定するためにドイツ語を使用する場合は、「do」を使用します。ドイツ語の「Ich will keine Persimonen」を英語に訳すと「Ido not want Persimmons」となります。
この問題を解決するために、モデル 3 は前のステップに基づいて 2 つのステップを追加します。
-
マシンが新しい単語を追加する必要があると判断した場合、NULL は挿入をマークします。
-
各単語に対して正しい文法または単語の配置を選択します。
モデル 4: 単語のアライメント
モデル 2 は単語の配置を考慮しますが、並べ替えについては何も知りません。たとえば、形容詞は名詞と入れ替わることが多く、順序に関係なく記憶されるため、文法要素を追加せずに洗練された翻訳を得ることが困難になります。したがって、モデル 4 はこの「相対順序」を考慮します。2 つの単語が常に位置を交換する場合、モデルはそれを認識します。
モデル 5: エラーを修正する
モデル 5 では、より多くの学習パラメーターが取得され、単語の位置の競合の問題が解決されます。革命的な重要性にもかかわらず、テキストベースのシステムは依然として同音異義語を処理できず、すべての単語が単一の方法で翻訳されます。
ただし、これらのシステムは、より高度なフレーズベースの翻訳に置き換えられたため、現在は使用されていません。
-
フレーズベースのSMT
この方法は、統計、並べ替え、語彙技法など、すべての単語ベースの翻訳原則に基づいています。テキストを単語に分割するだけでなく、正確には複数の単語の連続したシーケンスであるフレーズにも分割します。
その結果、機械は単語の安定した組み合わせを翻訳することを学習し、精度が大幅に向上しました。
")
重要なのは、これらのフレーズは必ずしも単純な構文構造ではなく、言語学と文構造の干渉を意識すると翻訳の品質が大幅に低下するということです。コンピューター言語学の先駆者であるフレデリック・イェリネックはかつてこう冗談を言いました。「言語学者に挑戦するたびに、音声認識装置のパフォーマンスが向上します。」
精度の向上に加えて、フレーズベースの翻訳により、バイリンガル テキストのオプションが増えます。テキストベースの翻訳の場合、ソースとの正確な一致が非常に重要であるため、文芸翻訳やフリーランス翻訳にはほとんど価値がありません。
フレーズベースの翻訳にはこの問題はありません。機械翻訳のレベルを向上させるために、研究者はさまざまな言語のニュース Web サイトを解析し始めています。
")
2006 年以来、ほぼ全員がこの方法を使用しています。 Google Translate、Yandex、Bing などの他の有名なオンライン翻訳システムは、2016 年以前はすべてフレーズベースでした。したがって、これらの翻訳システムの翻訳結果は完璧か意味不明のどちらかになりますが、これがフレーズ翻訳の特徴です。
この古いルールベースの方法では、常に偏った結果が生成される可能性があります。Google は躊躇せずに「300」を「300」と翻訳しましたが、実際には「300」は「300 年」も意味します。これは統計翻訳マシンの普遍的な制限です。
2016 年以前は、ほとんどすべての研究がフレーズベースの翻訳が最も先進的であると信じており、「統計的機械翻訳」と「フレーズベースの翻訳」を同じものとさえみなしていました。人々は Google が機械全体に革命を起こすだろうと認識していました。翻訳。 。
-
構文ベースの SMT
この方法についても簡単に説明します。ニューラル ネットワークが登場する数年前、文法ベースの翻訳は「未来」であると考えられていましたが、このアイデアが普及することはありませんでした。
その支持者は、ルールベースのアプローチと統合できると信じています。文は、主語、述語、および文のその他の部分を決定し、文ツリーを構築することにより、正確な文法分析を受けることができます。これを使用することで、機械学習は言語間の構文単位を変換し、単語やフレーズごとに翻訳します。これで「翻訳ミス」の問題は完全に解決できます。
")
アイデアは素晴らしいですが、現実は非常に醜いものです。たとえ文法ライブラリの問題が以前に解決されていたとしても (既製の言語ライブラリがすでにたくさんあるため)、文法解析は非常にうまく機能しません。
ニューラル機械翻訳 (NMT)
2014 年にニューラル機械翻訳に関する興味深い論文がありましたが、Google がこの分野をさらに深く掘り下げ始めたことを除けば、広く注目を集めることはありませんでした。 2 年後の 2016 年 11 月、Google は大々的に「機械翻訳ゲームのルールを正式に変更しました」と発表しました。
このアイデアは、有名なアーティストの作品のスタイルを模倣する Prisma の機能と似ています。 Prisma では、写真をゴッホの作品のように見せるなど、アーティストの作品のスタイルと、その結果得られる様式化された画像を認識するようにニューラル ネットワークが学習されます。これはインターネットの幻想ですが、私たちはそれを美しいと考えます。
")
写真にスタイルを移すことができるとしたら、ソーステキストに別の言語を適用しようとしたらどうなるでしょうか? テキストはまさに「アーティストのスタイル」であり、画像の本質を保持しながらそれを移そうとするでしょう。 、テキストの本質)。
この種のニューラル ネットワークを翻訳システムに適用するとどうなるかを想像してみてください。
ここで、ソース テキストが特定の特徴の集合であるとします。つまり、ソース テキストをエンコードしてから、別のニューラル ネットワークにデコードして、デコーダーだけが知っている言語のテキストに戻す必要があります。これらの機能がどこから来たのかはわかりませんが、スペイン語で表現することができます。
これは非常に興味深いプロセスになるでしょう。あるニューラル ネットワークは特定の特徴セットにのみ文章をエンコードでき、別のニューラル ネットワークはそれらをデコードしてテキストに戻すことしかできません。どちらも相手が誰であるかを知らず、それぞれが自分の言語しか知りませんでした。お互いに見知らぬ人でしたが、音程は合いました。
")
ただし、ここにも問題があります。それは、これらの特性をどのように見つけて定義するかということです。犬について語るとき、その特徴は明らかですが、文章についてはどうでしょうか。ご存知のとおり、科学者たちはすでに 30 年前に世界共通言語コードの作成を試みていましたが、最終的には失敗しました。
しかし、現在ではこの問題を非常にうまく解決できるディープラーニングが存在します。ディープラーニングはこの目的のために存在するからです。ディープ ラーニングと従来のニューラル ネットワークの主な違いは、これらの特定の特徴をその性質に関係なく正確に検索できることです。ニューラル ネットワークが十分に大きく、学習するための数千枚のビデオ カードがある場合、これらの特徴をテキストで一般化できます。
理論的には、ニューラル ネットワークから取得した特徴を言語学者に渡し、言語学者がまったく新しい地平を切り開くことができます。
テキストのエンコードとデコードにはどのようなタイプのニューラル ネットワークを適用できるのかという疑問があります。
畳み込みニューラル ネットワーク (CNN) は現在、ピクセルの独立したパッチに基づく画像に対してのみ機能することがわかっていますが、テキストには独立したパッチは存在せず、各単語は言語や音楽と同じように周囲の環境に依存します。リカレント ニューラル ネットワーク (RNN) は、以前の結果 (この場合は前の単語) をすべて記憶しているため、最適な選択肢を提供します。
そして、リカレント ニューラル ネットワークは、iPhone の RNN-Siri 音声認識 (音の順序を解析し、次のものは前のものに依存します)、キーボード プロンプト (前のものを記憶し、次のものを推測する) など、今日すでに使用されています。音楽生成、さらにはチャットボットまで。
")
2 年間で、ニューラル ネットワークは過去 20 年間の翻訳を完全に上回りました。語順の誤りが 50%、語彙の誤りが 17%、文法上の誤りが 19% 減少しました。ニューラル ネットワークは、異なる言語の同音異義語などの問題の処理方法も学習します。
ニューラル ネットワークは辞書を完全に無視して、真の直接翻訳を実現できることは注目に値します。英語以外の 2 つの翻訳を行う場合、以前は、ロシア語をドイツ語に翻訳する場合、まずロシア語を英語に翻訳し、次に英語をドイツ語に翻訳する必要がありました。これにより、翻訳を繰り返すとエラー率が増加します。
")
Google 翻訳 (2016 年以降)
2016 年に、彼らは 9 つの言語を翻訳するための Google Neural Machine Translation (GNMT) と呼ばれるシステムを開発しました。これには、8 つのエンコーダーと 8 つのデコーダーに加えて、オンライン翻訳のためのネットワーク接続が含まれています。
")
文を分割するだけでなく、単語も分割することで、珍しい単語にアプローチします。単語が辞書にない場合、NMT は参照できません。たとえば、文字グループ「Vas3k」を翻訳すると、この場合、GMNT は単語を単語のチャンクに分割し、その翻訳を復元しようとします。
ヒント: ブラウザーでウェブサイトを翻訳する Google 翻訳では、依然として古いフレーズベースのアルゴリズムが使用されています。どういうわけかGoogleはそれをアップグレードしなかったので、オンラインバージョンと比較すると違いは顕著です。
ただし、現在ブラウザでの Web サイト翻訳に使用されている Google 翻訳は、何らかの理由で依然としてフレーズベースのアルゴリズムを使用していますが、この点でも従来の翻訳モデルとの違いがわかります。
Google はオンラインのクラウドソーシングを使用しており、ユーザーは最も正しいと思われるバージョンを選択でき、多くのユーザーがそれを気に入った場合、Google はそのフレーズをそのように翻訳し続け、特別なバッジでマークします。これは、「映画に行きましょう」や「待っています」などの日常的な短い文に便利です。
Yandex 翻訳 (2017 年以降)
Yandex は、ニューラル ネットワークと統計的手法を組み合わせた CatBoost アルゴリズムを使用するニューラル翻訳システムを 2017 年に発売しました。
この方法は、頻度の低い語句では翻訳の歪みが発生しやすいというニューラル ネットワーク翻訳の欠点を効果的に補うことができ、この場合、単純な統計翻訳で正しい単語を迅速かつ簡単に見つけることができます。
")
機械翻訳の未来は?
リアルタイム音声翻訳「バベルフィッシュ」のコンセプトに誰もが今も興奮しています。 GoogleはPixel Budsでそれに向けて一歩を踏み出しましたが、実際には、いつ翻訳を開始するか、いつ黙って聞くべきかを知る必要があるため、確かに完璧ではありません。しかし、Siriでもこれはできません。
検討すべきもう 1 つの困難があります。それは、すべての学習が機械学習コーパスに限定されているということです。たとえより複雑なニューラル ネットワークを設計できたとしても、現時点では、提供されたテキストから学習することに限定されています。人間の翻訳者は、書籍や記事を読んで関連するコーパスを補完して、より正確な翻訳結果を確保できます。この点が、機械翻訳が人間の翻訳に比べて遅れている点です。
しかし、人間による翻訳はこれを行うことができるため、理論的にはニューラル ネットワークでもこれを行うことができます。そして、誰かがすでにニューラルネットワークを使ってこの機能を実現しようとしているようです。つまり、知っている 1 つの言語を通じて別の言語を読み取って経験を積み、それを後で使用できるように独自の翻訳システムにフィードバックします。
追加の読み物
")
《統計的機械翻訳》
フィリップ・ケーン著
公開アカウントをフォローして「統計的機械翻訳」に返信するとPDF版をダウンロードできます
")
")








