HyperAI
Command Palette
Search for a command to run...
WenetSpeech-Chuan 四川省・重慶省方言音声データセット
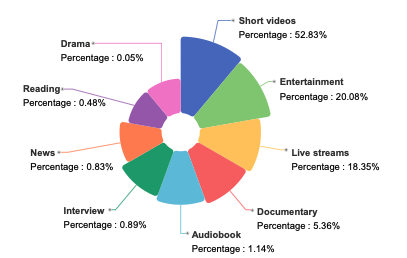
WenetSpeech-Chuanは、西北工科大学がHillbeak、中国電信人工知能研究所などの機関と共同で2025年に公開した大規模な四川省・重慶方言音声データセットです。関連する研究論文は「WenetSpeech-Chuan: 方言音声処理のための豊富な注釈を備えた大規模四川語コーパス”。 このデータセットには、10,013時間分の四川語と重慶語の方言の音声が含まれており、そのうち3,714時間分は強くラベル付けされたデータ、6,299時間分は弱くラベル付けされたデータです。このデータは9つの実世界のシナリオを網羅しており、短編動画が52,83%を占め、残りはエンターテイメント、ライブストリーミング、オーディオブック、ドキュメンタリー、インタビュー、ニュース、朗読、テレビドラマなどで構成されており、非常に多様でリアルな音声分布を示しています。すべての音声には、テキスト内容、信頼度、音声品質スコア、話者の性別と年齢、感情タグなどの豊富なアノテーション情報が付与されています。
このデータセットはコミュニティユーザーによって提供されており、教育および情報提供のみを目的としています。著作権侵害に関わるコンテンツがある場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。