Command Palette
Search for a command to run...
Décrivez n'importe Quoi Modèle De Démonstration
Date
Taille
776.37 MB
Licence
Apache 2.0
GitHub
URL du document
Aperçu du projet

Le modèle Describe Anything (DAM) est un modèle innovant de description d'images et de vidéos, développé conjointement par des équipes de NVIDIA, de l'UC Berkeley et de l'UCSF, et publié en 2025. Ce modèle génère des descriptions détaillées à partir de régions spécifiées par l'utilisateur (points, rectangles, traits ou masques). Pour les contenus vidéo, une description complète est obtenue simplement en annotant des régions sur n'importe quelle image. Des articles de recherche associés sont disponibles. Décrivez n'importe quoi : sous-titrage détaillé et localisé d'images et de vidéos .
Ce tutoriel utilise des ressources pour une seule carte RTX 4090.
Exemples de projets
Étapes de course
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 1 à 2 minutes et actualiser la page.
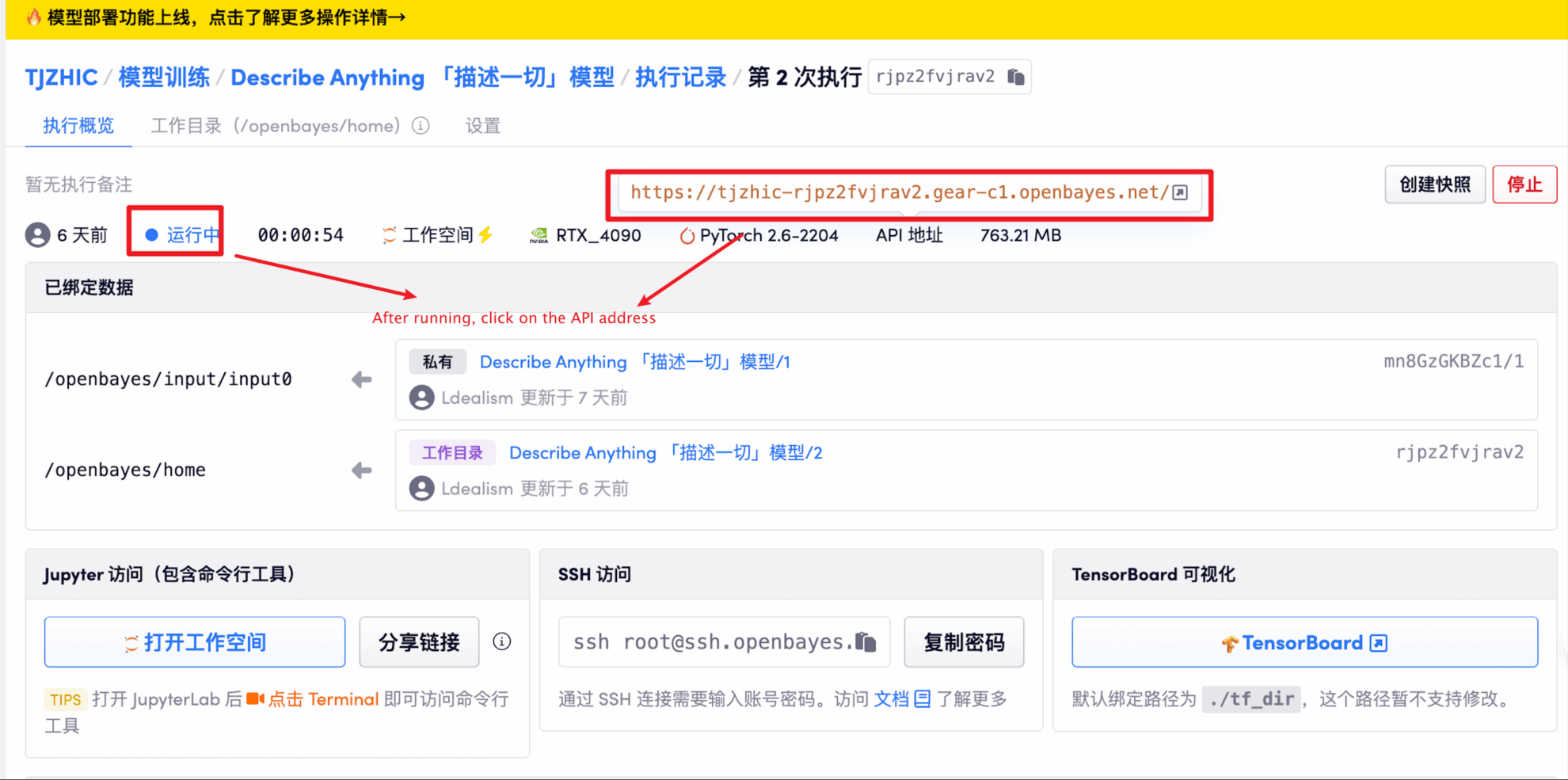
2. Une fois que vous entrez sur la page Web, vous pouvez interagir avec le modèle
La taille de l'image ne doit pas dépasser 5 Mo, la durée de la vidéo ne doit pas dépasser 20 secondes et la taille de la vidéo ne doit pas dépasser 5 Mo, sous peine de ralentir le modèle ou de signaler une erreur. Veuillez sélectionner la zone de description de manière raisonnable.
Ce tutoriel fournit deux tests de modules : les modules mode image et mode vidéo.
Les fonctions de chaque module sont les suivantes :
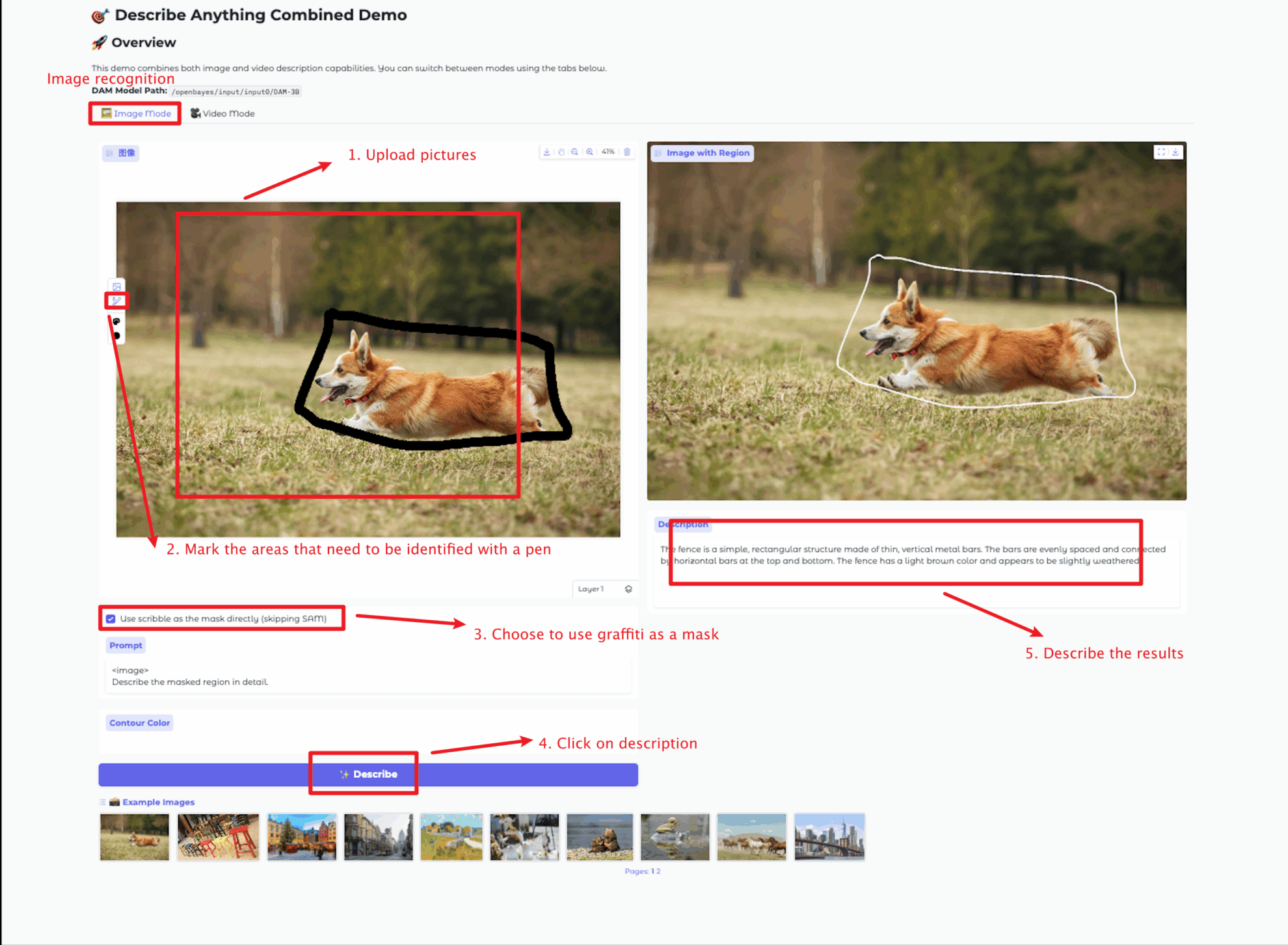
Mode image
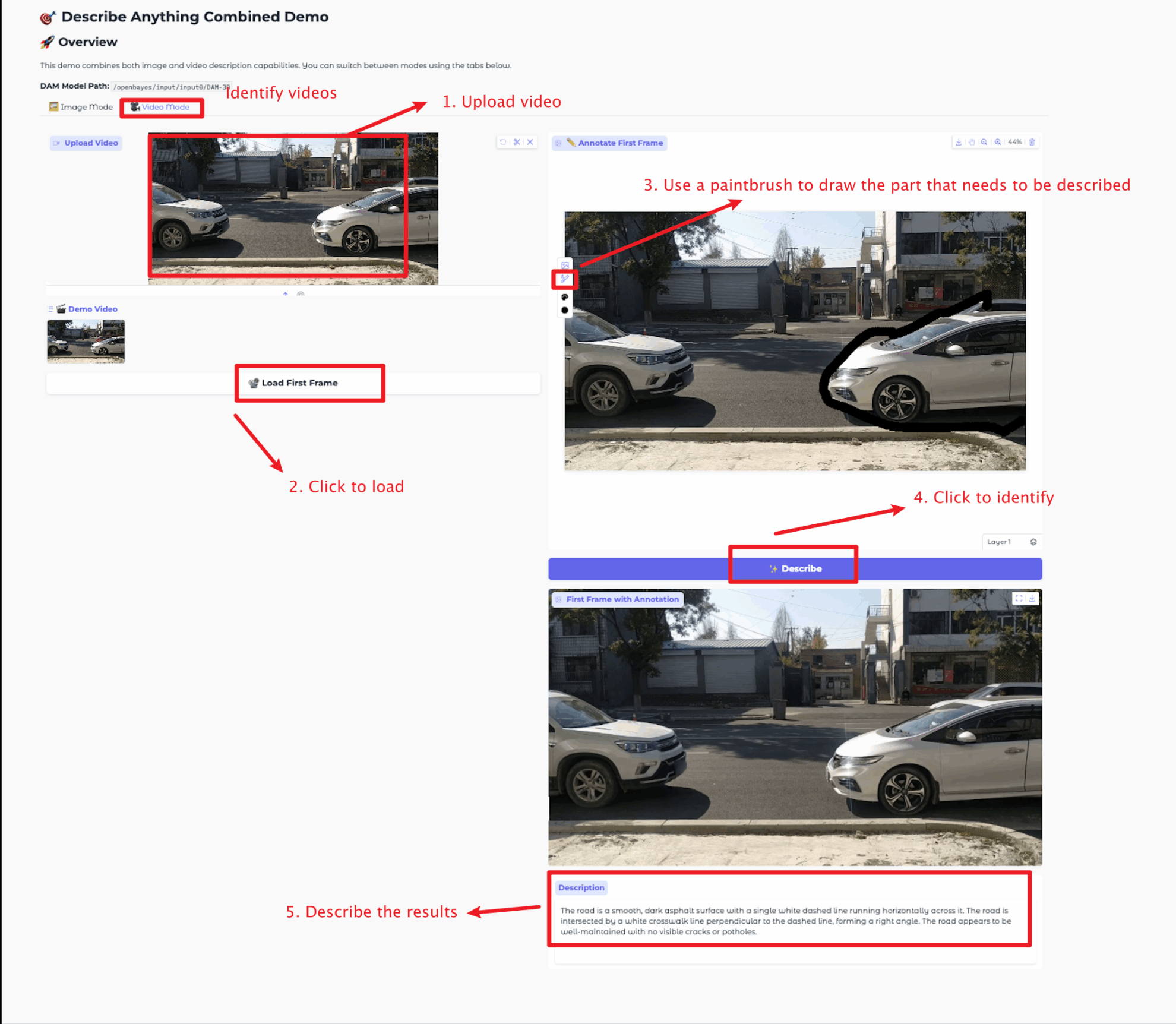
Mode vidéo
Échange et discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Informations sur la citation
Merci à l'utilisateur Github zhangjunchang Pour le déploiement de ce tutoriel, les informations de référence du projet sont les suivantes :
@article{lian2025describe,
title={Describe Anything: Detailed Localized Image and Video Captioning},
author={Long Lian and Yifan Ding and Yunhao Ge and Sifei Liu and Hanzi Mao and Boyi Li and Marco Pavone and Ming-Yu Liu and Trevor Darrell and Adam Yala and Yin Cui},
journal={arXiv preprint arXiv:2504.16072},
year={2025}
} GitHub Stars arXiv Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.