Command Palette
Search for a command to run...
Supertonic : Un Modèle De Synthèse Vocale TTS Haute Vitesse Basé Sur ONNX
1. Introduction au tutoriel

Ce tutoriel est basé sur le projet open-source officiel Supertone.SupertoniqueMerci à l'équipe Supertone pour sa contribution à la communauté open source ! ❤️
Supertonic est un moteur de synthèse vocale (TTS) natif lancé par l'équipe Supertone en janvier 2025. Sa couche d'inférence principale est implémentée avec ONNX Runtime, conçu spécifiquement pour les environnements à faible latence et à forte concurrence. Contrairement aux modèles TTS traditionnels à grande échelle, Supertonic réduit considérablement les exigences matérielles tout en conservant une synthèse vocale de haute qualité, prenant en charge l'inférence hors ligne et en temps réel sur ordinateurs, serveurs et même périphériques. Il est particulièrement adapté aux environnements exigeants en matière de confidentialité et de sécurité, ou nécessitant une intégration dans des applications interactives en temps réel (telles que les humains numériques et le chat vocal dans les jeux).
Veuillez noter : ce projet ne prend actuellement en charge que la synthèse vocale de textes anglais.
Ce tutoriel démontre la puissance de calcul d'un seul GPU RTX 5090 sur la plateforme OpenBayes, en utilisant l'accélération matérielle onnxruntime-gpu et Grado pour construire une interface web visuelle qui atteint une synthèse vocale anglaise au niveau de la milliseconde.
2. Exemples de projets
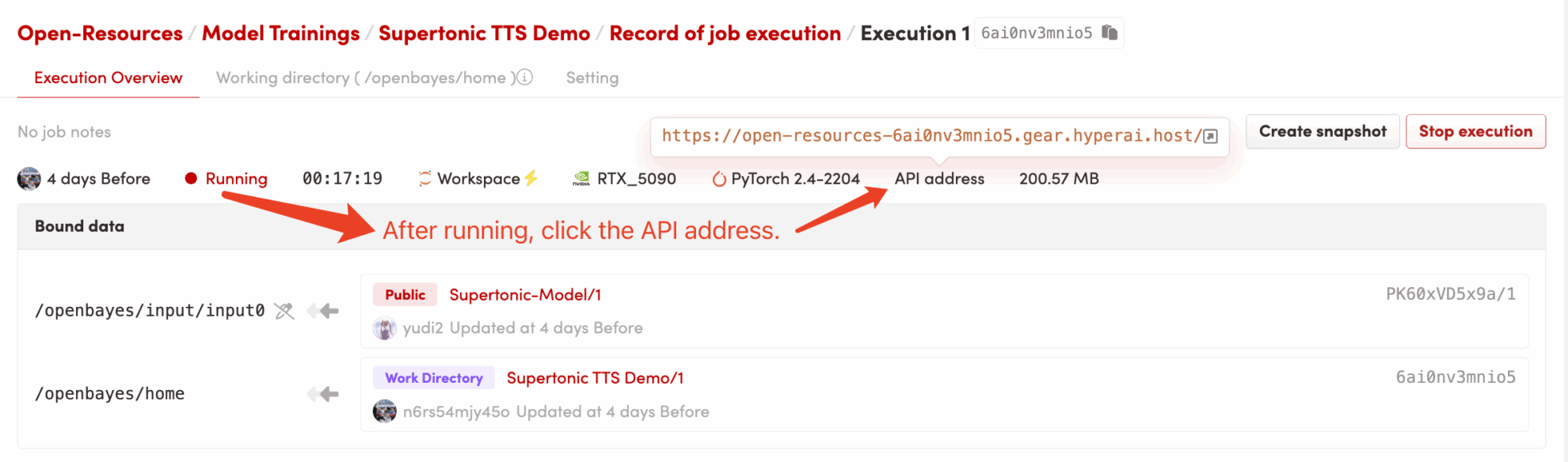
3. Étapes de l'opération
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
- Clonez ce tutoriel public dans la console OpenBayes.
- Démarrage du conteneur : le système allouera automatiquement les ressources de la RTX 5090 pour vous.
- En attente de démarrage : une fois le conteneur démarré, le script en arrière-plan
dependencies.shL'environnement CUDA sera configuré automatiquement et le modèle sera chargé. Les dépendances principales étant préinstallées, ce processus est très rapide et ne prend généralement qu'une à deux minutes. - Accès à l'application : Une fois que l'état du conteneur passe à « En cours d'exécution », cliquez sur le bouton « Adresse API » dans le coin supérieur droit de la page de détails du conteneur pour ouvrir l'interface Web de Grado.
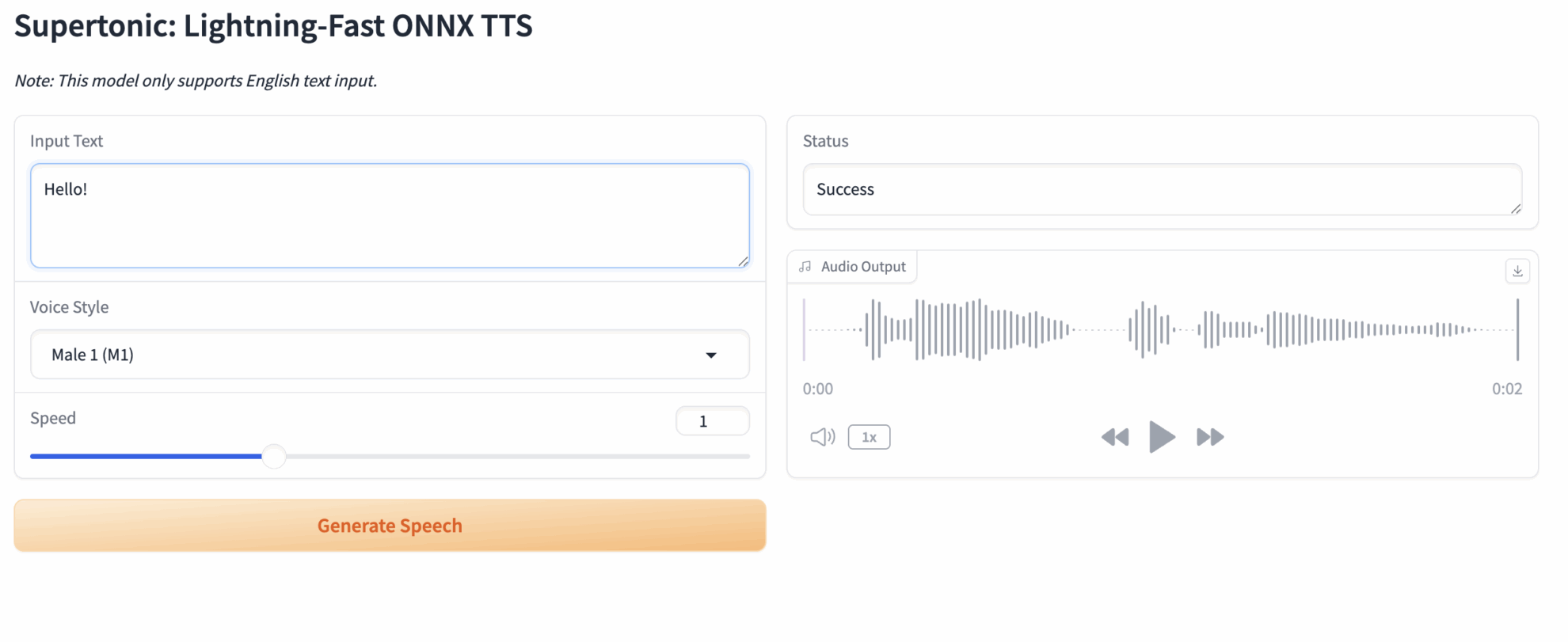
2. Saisir du texte dans une page web et synthétiser la parole.
Si le message « Bad Gateway » s'affiche, cela signifie que le service est en cours de démarrage. Le chargement du modèle pouvant prendre un certain temps, veuillez patienter 1 à 2 minutes, puis actualiser la page.
Lorsque vous utilisez le navigateur Safari, l'audio peut ne pas être lu directement et doit être téléchargé avant la lecture.
Une fois sur la page web, vous verrez une interface interactive entièrement en anglais.
Étapes d'utilisation de base :
- Texte d'entrée : Saisissez le texte anglais à synthétiser dans la zone de texte située à gauche. Exemple : Supertonic est un modèle de synthèse vocale ultra-rapide.
- Style de voix : Sélectionnez un style prédéfini dans le menu déroulant (par exemple, ...).
Male 1Voix masculine ouFemale 1(Voix féminine) - Vitesse : Faites glisser le curseur pour ajuster la vitesse d’élocution. La valeur par défaut est 1,0.
- Générer un discours : Cliquez sur le bouton Générer.
- Sortie audio : Veuillez patienter quelques instants. Le lecteur à droite lancera automatiquement la lecture du fichier audio généré. Vous pouvez également cliquer sur le bouton de téléchargement en haut à droite pour l’enregistrer.
.wavdocument.

Remarque : lors de la première génération, l’environnement d’exécution ONNX peut prendre quelques secondes pour initialiser CUDA et optimiser le graphe. Les générations suivantes seront très rapides.

Informations sur la citation
@article{kim2025supertonic, title={SupertonicTTS: Towards Highly Efficient and Streamlined Text-to-Speech System}, author={Kim, Hyeongju and Yang, Jinhyeok and Yu, Yechan and Ji, Seunghun and Morton, Jacob and Bous, Malek and Lee, Sungjae}, journal={arXiv preprint arXiv:2503.23108}, year={2025}, url={[https://arxiv.org/abs/2503.23108](https://arxiv.org/abs/2503.23108)} } @article{kim2025larope,
title={Length-Aware Rotary Position Embedding for Text-Speech Alignment},
author={Kim, Hyeongju and Lee, Juheon and Yang, Jinhyeok and Morton, Jacob},
journal={arXiv preprint arXiv:2509.11084},
year={2025},
url={https://arxiv.org/abs/2509.11084}
}@article{kim2025spfm,
title={Training Flow Matching Models with Reliable Labels via Self-Purification},
author={Kim, Hyeongju and Yu, Yechan and Yi, June Young and Lee, Juheon},
journal={arXiv preprint arXiv:2509.19091},
year={2025},
url={https://arxiv.org/abs/2509.19091}
}
Vue d’ensemble de Notebook
Niveau
Rubrique
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.