Command Palette
Search for a command to run...
MonkeyOCR : Analyse De Documents Basée Sur Le Triple Paradigme structure-reconnaissance-relation
Date
URL du document
Licence
Apache 2.0
GitHub
1. Introduction au tutoriel

MonkeyOCR est un modèle d'analyse syntaxique de documents open source, publié le 5 juin 2025 par l'Université des sciences et technologies de Huazhong en collaboration avec Kingsoft Office. Ce modèle convertit efficacement le contenu non structuré de documents en informations structurées. Grâce à une analyse précise de la mise en page, à la reconnaissance du contenu et au tri logique, il améliore considérablement la précision et l'efficacité de l'analyse syntaxique. Comparé aux méthodes traditionnelles, MonkeyOCR excelle dans le traitement de documents complexes (contenant notamment des formules et des tableaux), avec un gain de performance moyen de 5,11 TP3T, et des gains respectifs de 15,01 TP3T et 8,61 TP3T pour l'analyse des formules et des tableaux. Le modèle est particulièrement performant dans le traitement de documents multipages, atteignant 0,84 page par seconde, surpassant largement les autres outils similaires. MonkeyOCR prend en charge différents types de documents, tels que les articles universitaires, les manuels scolaires et les journaux, et est compatible avec de nombreuses langues, offrant ainsi un support puissant pour la numérisation et le traitement automatisé de documents. Des articles de recherche associés sont disponibles. MonkeyOCR : analyse de documents avec un paradigme triplet structure-reconnaissance-relation .
Caractéristiques principales :
- Analyse et structuration de documents : convertissez le contenu non structuré (y compris le texte, les tableaux, les formules, les images, etc.) dans des documents de différents formats (tels que PDF, images, etc.) en informations structurées lisibles par machine.
- Prise en charge multilingue : prend en charge plusieurs langues, dont le chinois et l'anglais.
- Gérez efficacement les documents complexes : il fonctionne bien lors du traitement de documents complexes (tels que ceux contenant des formules, des tableaux, des mises en page à plusieurs colonnes, etc.).
- Traitement rapide de documents multipages : traitez efficacement les documents multipages avec une vitesse de traitement de 0,84 page par seconde, nettement meilleure que d'autres outils (tels que MinerU 0,65 page par seconde Qwen2.5-VL-7B 0,12 page par seconde).
- Déploiement et extension flexibles : prend en charge un déploiement efficace sur un seul GPU NVIDIA 3090 pour répondre aux besoins de différentes échelles.
Principe technique :
- Paradigme du triplet Structure-Reconnaissance-Relation (SRR) : un détecteur de mise en page basé sur YOLO identifie l'emplacement et la catégorie des éléments clés d'un document (blocs de texte, tableaux, formules, images, etc.). La reconnaissance de contenu est effectuée sur chaque région détectée, et la reconnaissance de bout en bout est réalisée à l'aide d'un grand modèle multimorphique (LMM) pour garantir une grande précision. Grâce à un mécanisme de prédiction de l'ordre de lecture au niveau des blocs, la relation logique entre les éléments détectés est déterminée afin de reconstruire la structure sémantique du document.
- Ensemble de données MonkeyDoc : MonkeyDoc est l'ensemble de données d'analyse de documents le plus complet à ce jour, contenant 3,9 millions d'instances, couvrant plus de dix types de documents en chinois et en anglais. Cet ensemble de données repose sur un pipeline en plusieurs étapes, intégrant une annotation manuelle rigoureuse, une synthèse programmatique et une annotation automatique pilotée par modèle. Il permet d'entraîner et d'évaluer les modèles MonkeyOCR, garantissant ainsi de solides capacités de généralisation dans des scénarios documentaires divers et complexes.
- Optimisation et déploiement du modèle : L'optimiseur AdamW et la planification du taux d'apprentissage cosinus sont utilisés en combinaison avec des jeux de données à grande échelle pour l'entraînement, afin de garantir un équilibre entre précision et efficacité du modèle. Basé sur l'outil LMDeplov, MonkeyOCR peut fonctionner efficacement sur un seul GPU NVIDIA 3090, permettant un raisonnement rapide et un déploiement à grande échelle.
Ce tutoriel utilise une seule carte graphique RTX 5090 comme ressource de calcul.
2. Affichage des effets
Exemple de document de formule

Exemple de document de tableau

Exemple de journal

Exemple de rapport financier


3. Étapes de l'opération
1. Démarrez le conteneur
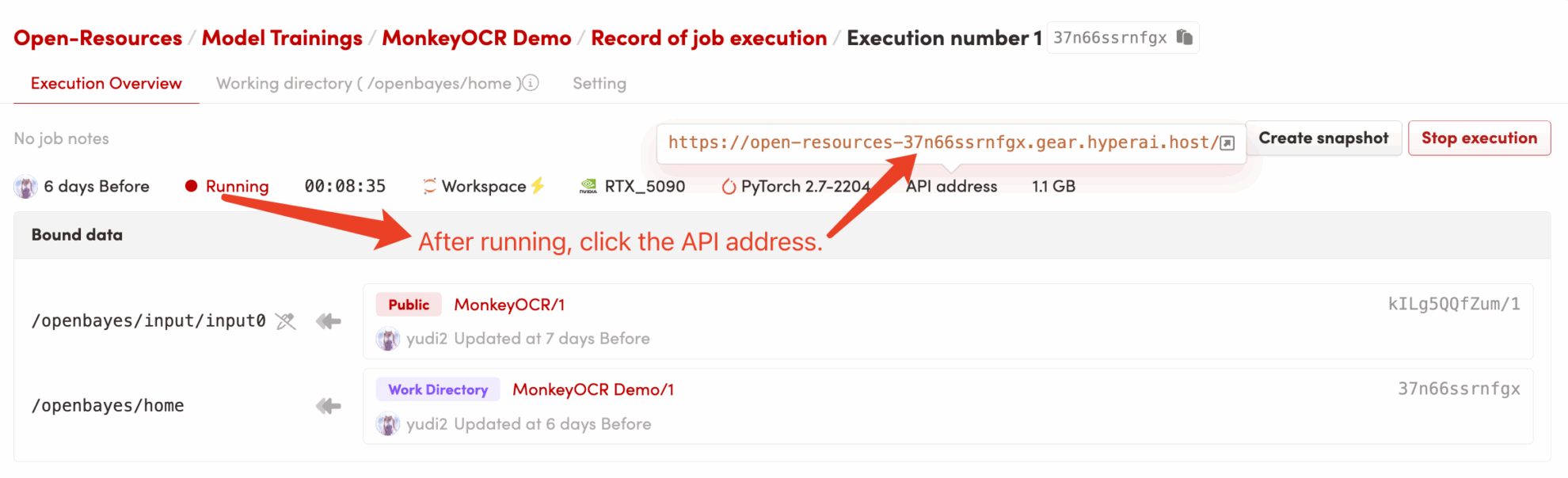
2. Étapes d'utilisation
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 2 à 3 minutes et actualiser la page.

Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@misc{li2025monkeyocrdocumentparsingstructurerecognitionrelation,
title={MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm},
author={Zhang Li and Yuliang Liu and Qiang Liu and Zhiyin Ma and Ziyang Zhang and Shuo Zhang and Zidun Guo and Jiarui Zhang and Xinyu Wang and Xiang Bai},
year={2025},
eprint={2506.05218},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.05218},
}
Vue d’ensemble de Notebook
Niveau
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.