Command Palette
Search for a command to run...
PaddleOCR-VL : Analyse De Documents Multimodaux
Date
URL du document
Licence
Apache 2.0
GitHub
1. Introduction au tutoriel

PaddleOCR-VL est un modèle de pointe (SOTA) économe en ressources, conçu spécifiquement pour l'analyse syntaxique de documents. Son composant principal, PaddleOCR-VL-0.9B, est un modèle de langage visuel (VLM) compact et puissant qui intègre un encodeur visuel à résolution dynamique de type NaViT au modèle de langage ERNIE-4.5-0.3B, permettant une reconnaissance précise des éléments. Ce modèle innovant prend en charge efficacement 109 langues et excelle dans la reconnaissance d'éléments complexes tels que le texte, les tableaux, les formules et les graphiques, tout en maintenant une consommation de ressources extrêmement faible. Grâce à une évaluation complète sur des benchmarks publics et internes largement utilisés, PaddleOCR-VL atteint des performances de pointe tant pour l'analyse syntaxique au niveau de la page que pour la reconnaissance au niveau des éléments. Ce modèle surpasse significativement les solutions existantes, démontre une forte compétitivité face aux meilleurs modèles de langage visuel et offre des vitesses d'inférence rapides. Ces avantages le rendent parfaitement adapté aux déploiements en conditions réelles. Des articles de recherche associés sont disponibles. PaddleOCR-VL : Amélioration de l’analyse syntaxique de documents multilingues grâce à un modèle vision-langage ultra-compact de 0,9 octet .
Ce tutoriel utilise une seule carte graphique RTX 5090 comme ressource de calcul.
2. Exemples d'effets
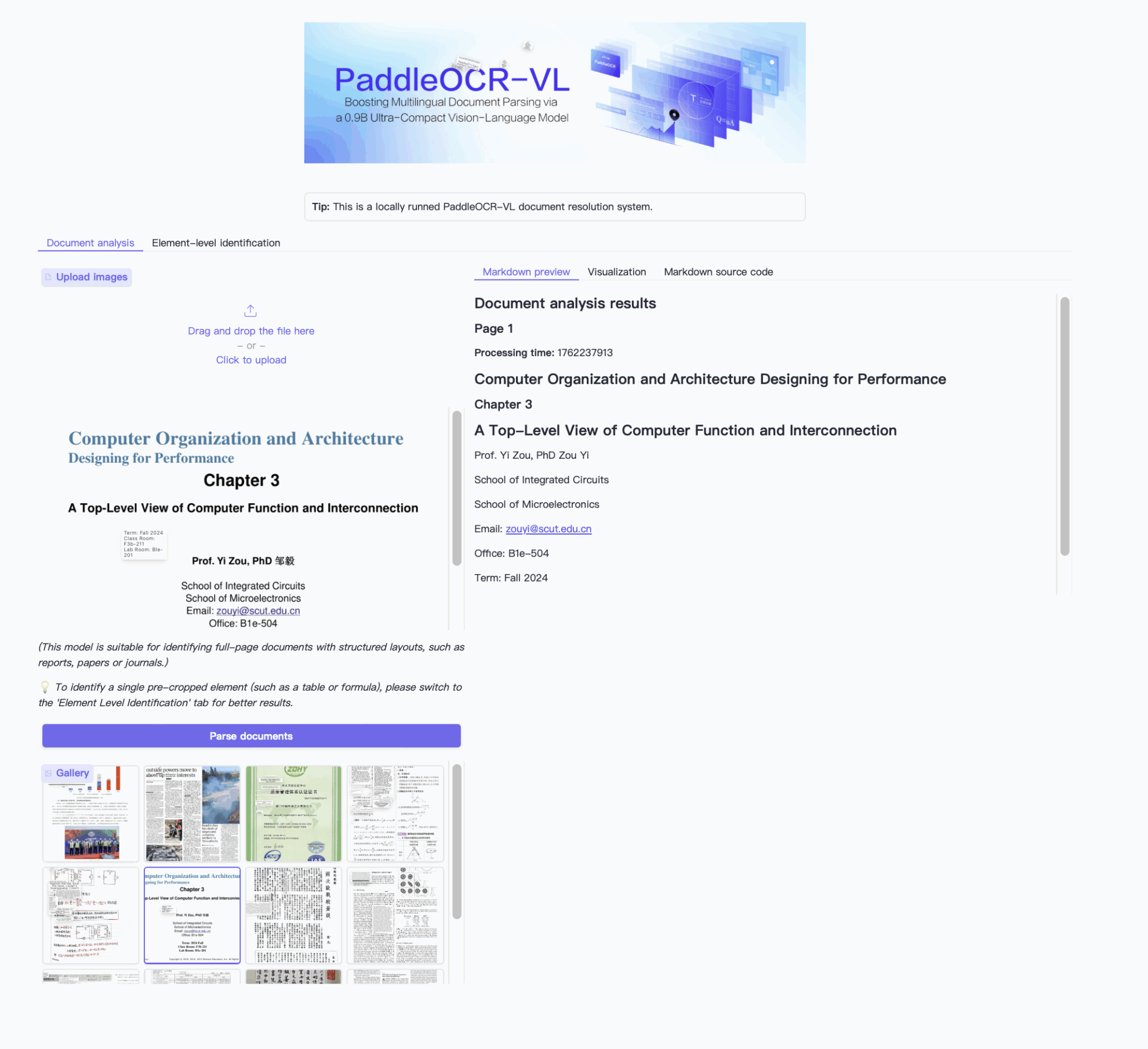
3. Étapes de l'opération
1. Démarrez le conteneur
2. Après être entré sur la page Web, vous pouvez démarrer une conversation avec le modèle
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 2 à 3 minutes et actualiser la page.
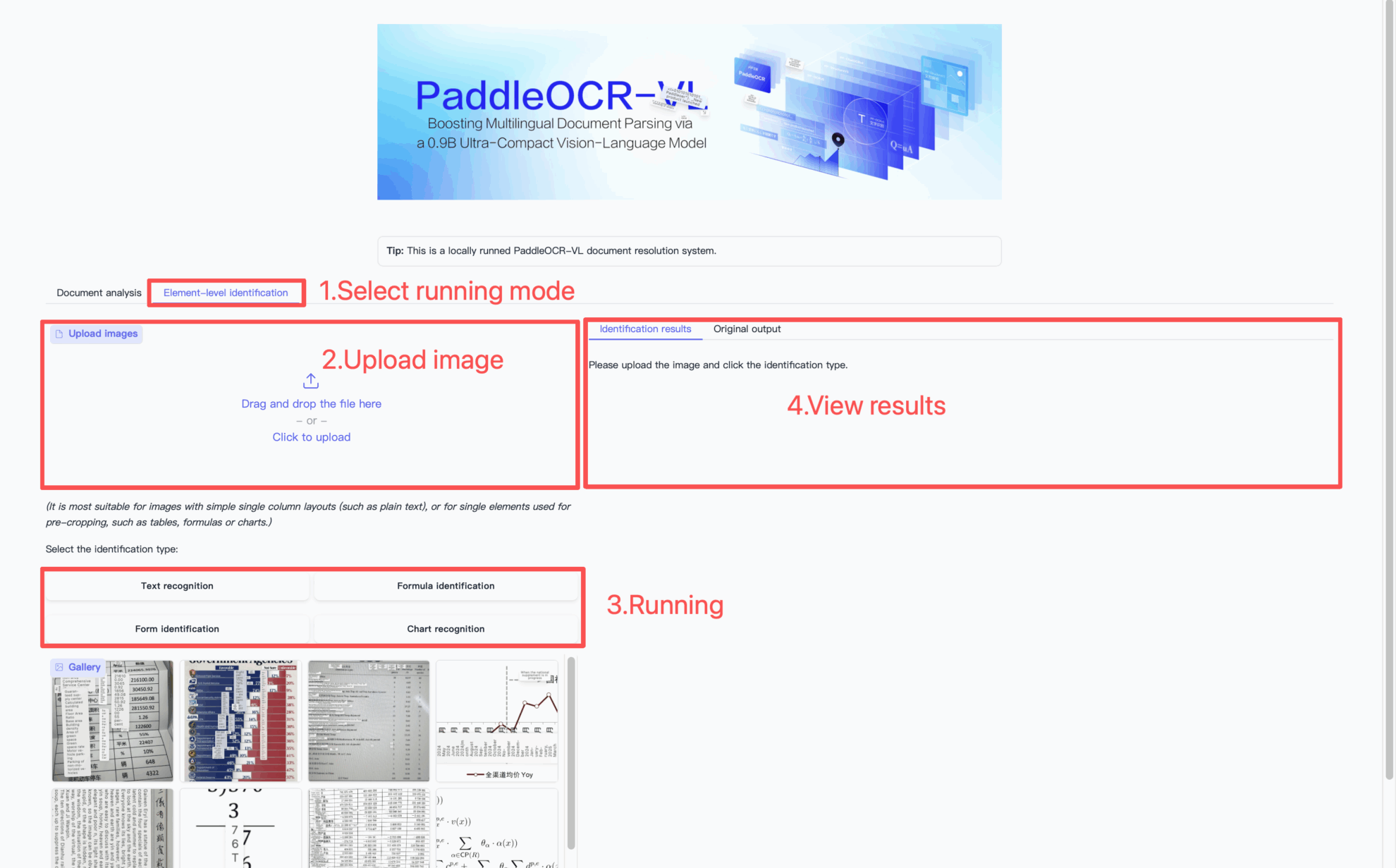
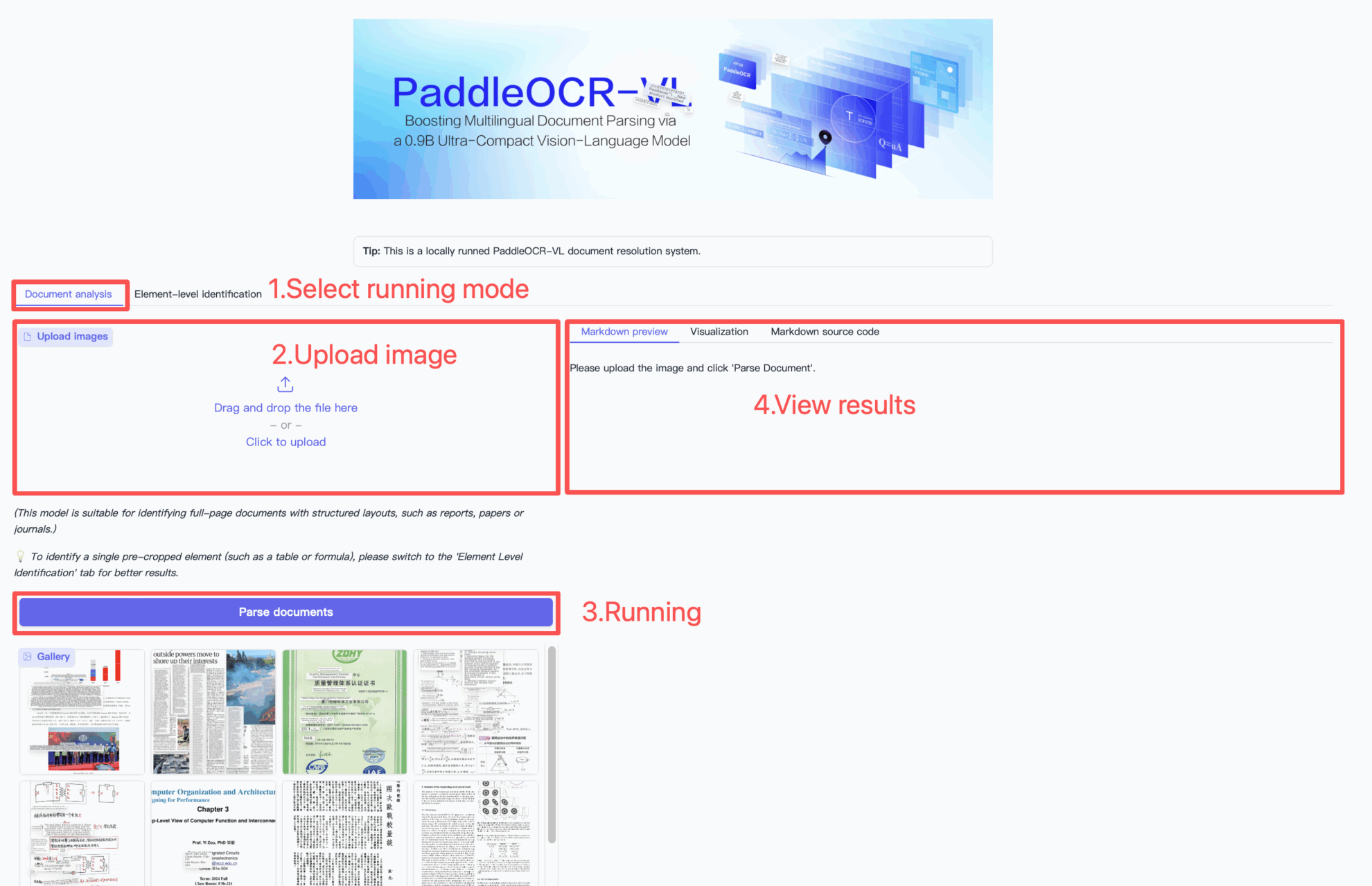
Comment utiliser
Informations sur la citation
@misc{cui2025paddleocrvlboostingmultilingualdocument,
title={PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model},
author={Cheng Cui and Ting Sun and Suyin Liang and Tingquan Gao and Zelun Zhang and Jiaxuan Liu and Xueqing Wang and Changda Zhou and Hongen Liu and Manhui Lin and Yue Zhang and Yubo Zhang and Handong Zheng and Jing Zhang and Jun Zhang and Yi Liu and Dianhai Yu and Yanjun Ma},
year={2025},
eprint={2510.14528},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.14528},
}Vue d’ensemble de Notebook
Niveau
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.