Command Palette
Search for a command to run...
Depth-Anything-3 : Restauration De L’espace Visuel Depuis N’importe Quelle Perspective
Date
Organisation
URL du document
Licence
Apache 2.0
1. Introduction au tutoriel

Depth-Anything-3 (DA3) est un modèle de géométrie visuelle révolutionnaire publié par l'équipe ByteDance-Seed en novembre 2025. L'article de recherche associé est le suivant : Depth Anything 3 : Récupérer l’espace visuel à partir de n’importe quelle vue .
Ce modèle révolutionne les tâches de géométrie visuelle grâce à son concept de « modélisation minimaliste » : il utilise un seul Transformer classique (tel que l’encodeur DINO standard) comme réseau de base, remplaçant l’apprentissage multitâche complexe par une « représentation par rayons de profondeur ». Ceci lui permet de prédire des structures géométriques spatialement cohérentes à partir de n’importe quelle entrée visuelle (qu’il s’agisse de poses de caméra connues ou inconnues). Ses performances surpassent largement celles de modèles précédents comme DA2 (estimation de profondeur monoculaire) et de solutions similaires comme VGGT (estimation de profondeur/pose multivue). Tous les modèles sont entraînés sur des jeux de données académiques publics, garantissant un équilibre optimal entre précision et reproductibilité.
Fonctionnalités principales :
- Intégration multitâche : Un seul modèle prend en charge des tâches telles que l'estimation de profondeur monoculaire, la fusion de profondeur multivue, l'estimation de la pose de la caméra et la génération gaussienne 3D.
- Sortie de haute précision : Précision de profondeur monoculaire atteinte de 94,6% sur l'ensemble de données HiRoom ; la précision de reconstruction ETH3D surpasse des modèles tels que VGGT.
- Adaptation multi-modèles : propose les modèles des séries Main (polyvalent), Metric (mesure de profondeur), Monocular (monoculaire uniquement) et Nested (fusion imbriquée).
- Exportation flexible : prend en charge les formats tels que GLB, NPZ, PLY et la vidéo 3DGS, s’intégrant parfaitement aux outils 3D en aval (tels que Blender).
Ce tutoriel utilise Grado pour déployer le modèle de base DA3, avec des ressources de calcul « RTX_5090 », qui peuvent exécuter intégralement des tâches lourdes telles que la génération gaussienne 3D (haute résolution) et la reconstruction 3D multivue sans aucun goulot d'étranglement de mémoire vidéo/mémoire.
2. Affichage des effets
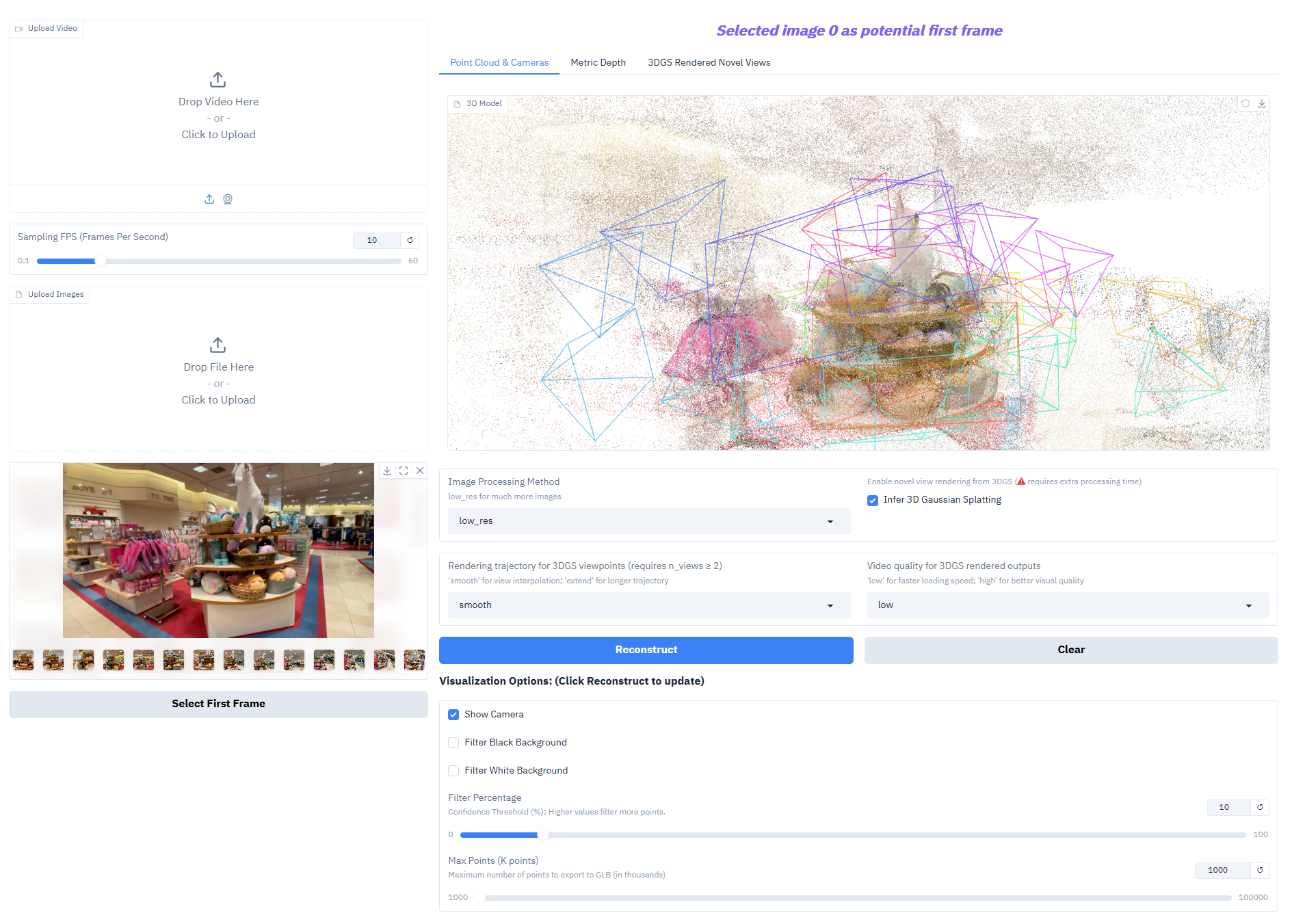
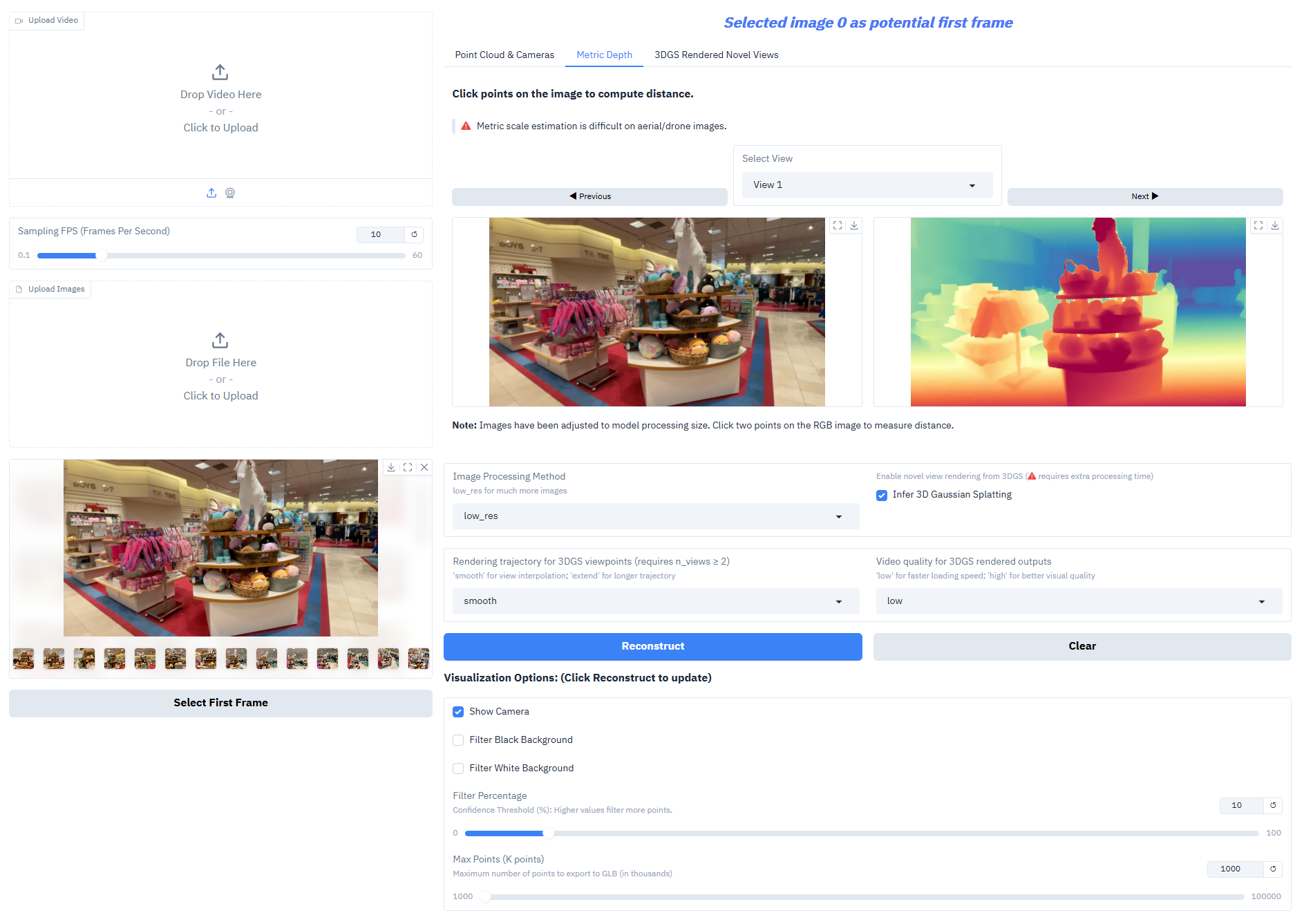
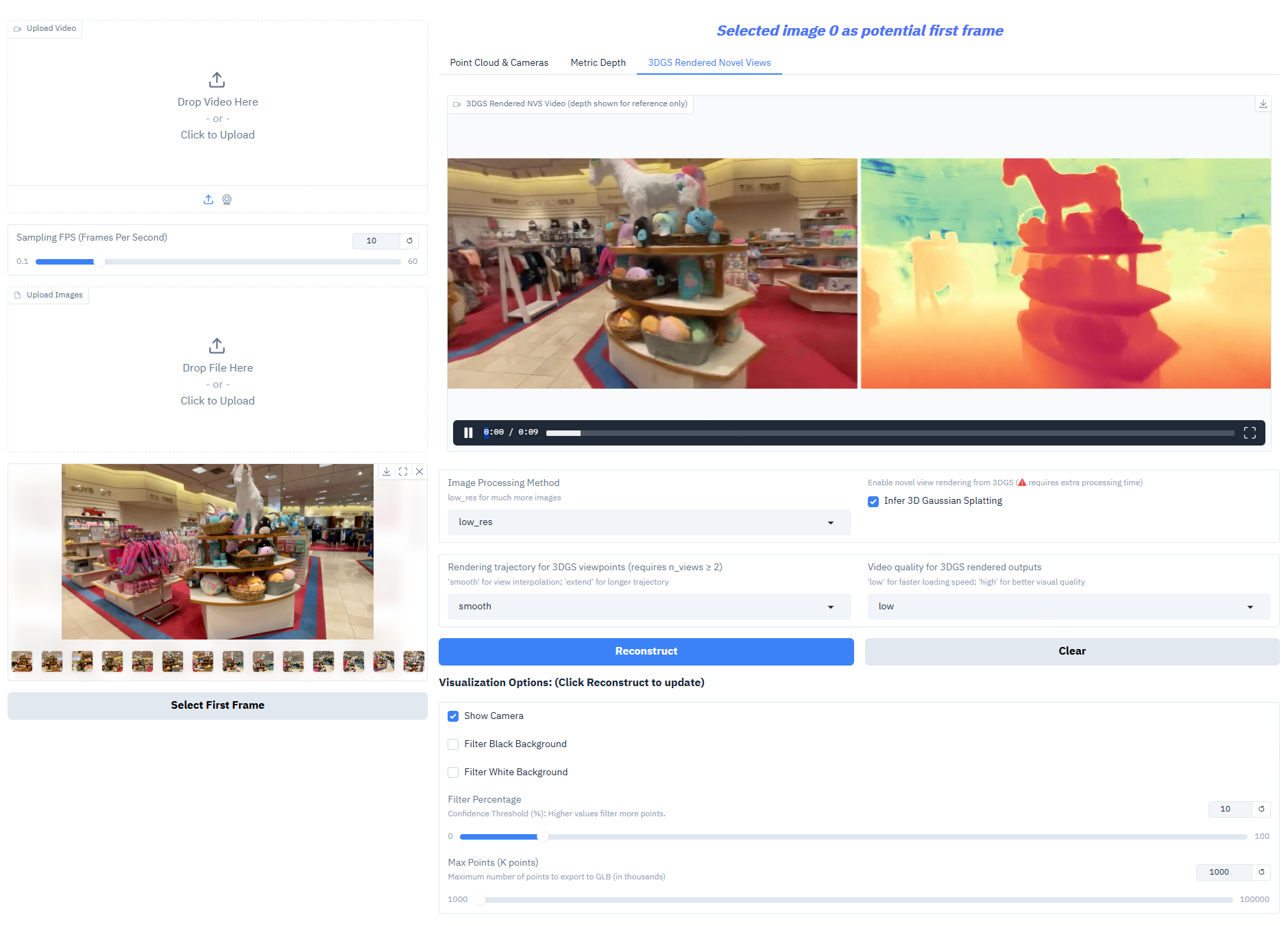
Depth-Anything-3 obtient des résultats exceptionnels sur les tâches principales :
- Estimation de profondeur monoculaire : génération de cartes de profondeur de haute précision à partir d’une seule image RVB pour reconstruire la hiérarchie spatiale de la scène.
- Fusion de profondeur multi-vues : Génère un champ de profondeur cohérent à partir de plusieurs images de la même scène, permettant une reconstruction 3D de haute qualité.
- Estimation de la pose de la caméra : Prédire avec précision les paramètres intrinsèques et extrinsèques de la caméra (paramètres extrinsèques [N,3,4], paramètres intrinsèques [N,3,3]), s'adaptant aux tâches collaboratives multi-vues.
- Génération gaussienne 3D : génère directement des modèles gaussiens 3D haute fidélité, prenant en charge une nouvelle composition de vues (fréquence d'images ≥ 30 ips).
- Mesure de profondeur : Les modèles en série imbriqués peuvent générer une profondeur à l’échelle réaliste, répondant aux besoins des levés topographiques, de l’aménagement intérieur et d’autres scénarios.
3. Étapes de l'opération
1. Démarrez le conteneur
Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
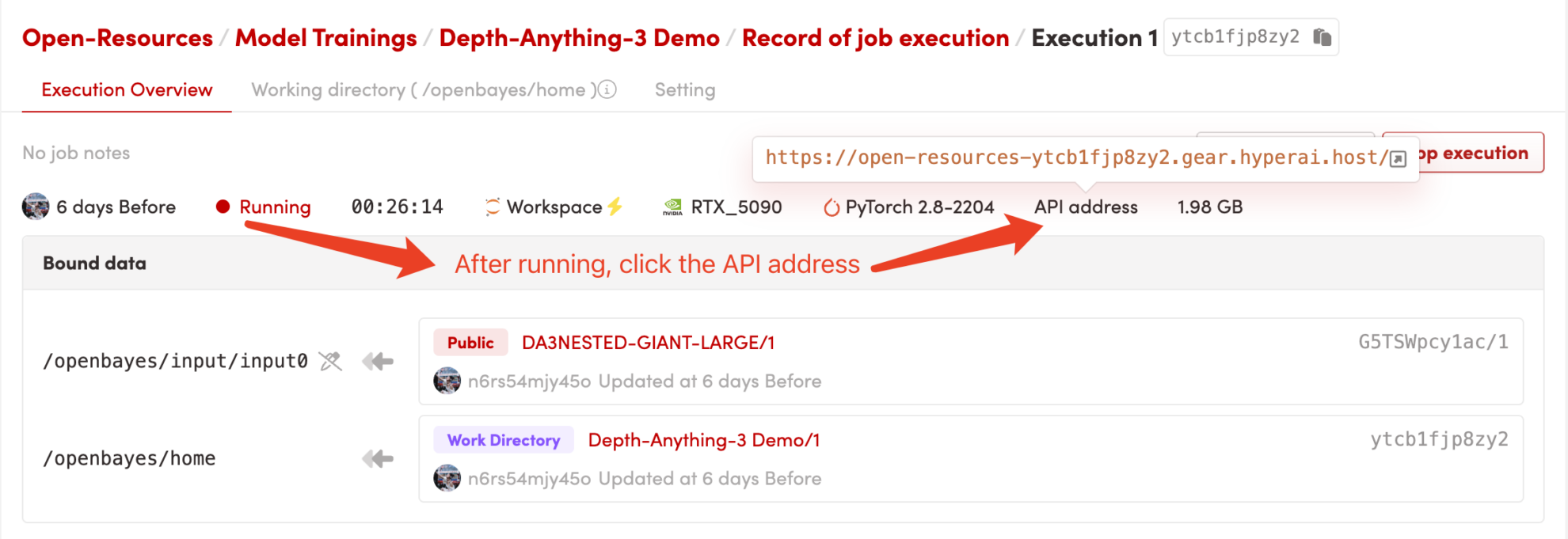
2. Pour commencer
Si le message « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Ce modèle étant volumineux, veuillez patienter 2 à 3 minutes et actualiser la page.
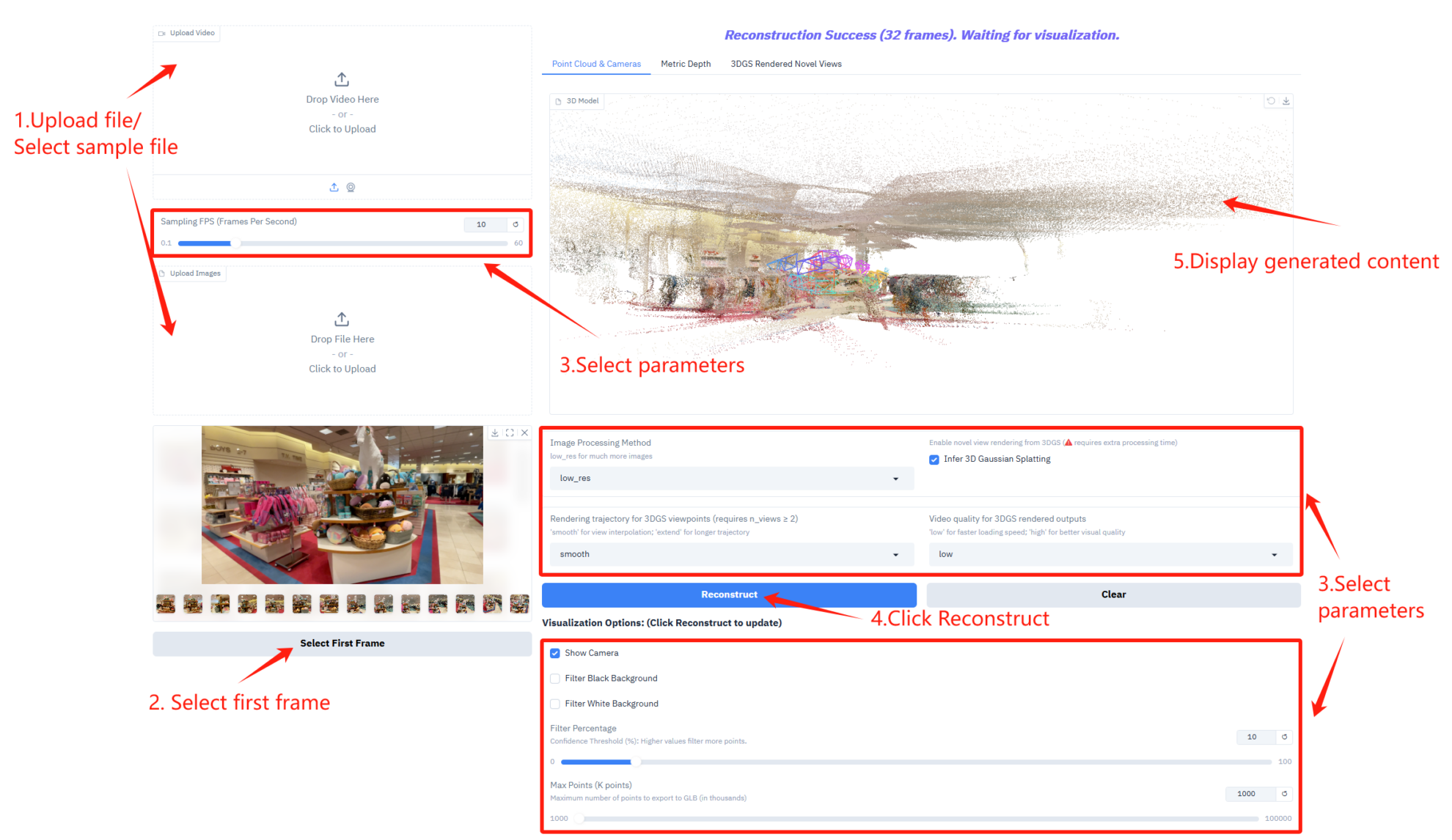
Description des paramètres
- Paramètres de fréquence d'échantillonnage
- Fréquence d'échantillonnage (images par seconde) : contrôle le nombre d'images par seconde utilisées pour l'échantillonnage vidéo.
- Configuration du traitement d'images et de l'inférence 3D
- Méthode de traitement d'image : Sélectionnez le mode de traitement d'image permettant de traiter un plus grand nombre d'images.
- Inférence de la pulvérisation gaussienne 3D : L’activation de l’inférence de la pulvérisation gaussienne 3D nécessite un temps de traitement supplémentaire pour générer des modèles 3D.
- Paramètres de rendu de la trajectoire et de la qualité vidéo
- Trajectoire de rendu pour les points de vue 3DGS : Sélectionnez le type de trajectoire de rendu pour le point de vue 3DGS.
- Qualité vidéo des rendus 3DGS : contrôle la qualité vidéo des rendus 3DGS.
- Options de visualisation
- Afficher la caméra : Affiche la trajectoire de la caméra dans une vue 3D.
- Filtrer l'arrière-plan noir : Supprime la zone d'arrière-plan noire dans le nuage de points.
- Filtrer les fonds blancs : Supprime les zones de fond blanc dans le nuage de points.
- Pourcentage de filtrage : contrôle l’intensité du filtrage du nuage de points.
- Points max. (K points) : Définit le nombre maximal de points pour l’exportation d’un modèle 3D au format GLB.
Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@article{depthanything3,
title={Depth Anything 3: Recovering the visual space from any views},
author={Haotong Lin and Sili Chen and Jun Hao Liew and Donny Y. Chen and Zhenyu Li and Guang Shi and Jiashi Feng and Bingyi Kang},
journal={arXiv preprint arXiv:2511.10647},
year={2025}
}Vue d’ensemble de Notebook
Niveau
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.