Command Palette
Search for a command to run...
Tirant Parti Des Capacités Contextuelles Étendues De Gemini 1.5, Le Système De Santé Conversationnel De Google, AMIE, a Atteint Le Niveau De Raisonnement d'un Médecin Généraliste Dans 100 Scénarios Impliquant De Multiples Visites De patients.

Les grands modèles de langage s'imposent rapidement dans le domaine de la santé, avec des applications allant de la recherche documentaire et la génération de dossiers médicaux à l'aide à la décision clinique. Parmi ces applications, le diagnostic assisté est l'un des domaines les plus aboutis : des modèles médicalement précis peuvent fournir des diagnostics différentiels de haute qualité à partir des antécédents médicaux, des signes cliniques et des résultats d'examens ; les systèmes dotés de capacités de dialogue à plusieurs tours peuvent également enrichir les informations relatives aux antécédents médicaux grâce à une interaction de type consultation.
Cependant, le diagnostic n'est que le point de départ de la prise de décision clinique. Ce qui influence réellement la qualité du traitement, ce sont souvent les décisions de prise en charge qui suivent le diagnostic : la nécessité d'examens complémentaires, le choix d'un plan de traitement, l'ajustement de la médication, la planification des consultations de suivi et la révision continue du plan en fonction de l'évolution de l'état du patient. Ce type de raisonnement thérapeutique est plus au cœur même de la pratique clinique.Cela met également à l'épreuve la compréhension globale, par le modèle, des lignes directrices fondées sur des données probantes, des parcours cliniques, des connaissances sur les médicaments et des différences individuelles entre les patients.
Comparativement au raisonnement diagnostique, le raisonnement managérial est plus difficile à évaluer. Les problèmes diagnostiques admettent généralement des réponses standard relativement claires, tandis que les décisions managériales sont souvent dépourvues de solution unique et sont contraintes par les ressources médicales, les recommandations, l'accès aux médicaments et l'expérience du médecin. Actuellement, la principale méthode d'évaluation de ce type de compétence globale en formation médicale est l'examen clinique objectif structuré (ECOS), mais celui-ci repose sur l'interaction directe avec un praticien et l'évaluation par des experts, ce qui rend difficile son application directe à l'évaluation automatisée de grands modèles de langage.
Pour combler cette lacune, une étude récente de Google DeepMind et Google Research a permis de développer un nouveau système d'agent intelligent basé sur le modèle LLM et s'appuyant sur leur système de santé conversationnel AMIE. Ce système optimise la gestion clinique et le dialogue médecin-patient dans de multiples scénarios de suivi. AMIE exploite les capacités de contexte long du modèle Gemini, combinant la recherche contextuelle et le raisonnement structuré afin de garantir que ses résultats soient conformes aux dernières recommandations de pratique clinique et aux catalogues de prescriptions médicamenteuses.
Dans une étude randomisée, en double aveugle et virtuelle, portant sur un examen clinique objectif structuré (ECOS), des chercheurs ont comparé l'AMIE à 21 médecins généralistes. Le test comprenait 100 scénarios de consultations multiples, la conception des cas faisant référence aux recommandations du NICE britannique et aux recommandations de bonnes pratiques cliniques du BMJ. Les résultats ont montré que…En termes de capacité de raisonnement en matière de gestion des maladies évaluée par des spécialistes, AMIE n'a pas obtenu de résultats inférieurs à ceux des médecins humains (non inférieurs) ;Par ailleurs, l'AMIE a obtenu des résultats supérieurs à ceux du groupe de médecins en ce qui concerne la précision des plans de traitement et des recommandations d'examen, ainsi que le degré d'adhésion aux directives cliniques et la fiabilité de la base de connaissances.
Les résultats de cette recherche, intitulée « Vers une IA conversationnelle pour la gestion des maladies », ont été publiés dans la revue Nature.
Points saillants de la recherche :
* Cette recherche fait progresser les capacités du système de soins de santé conversationnel AMIE, passant d'un diagnostic en une seule séance à un raisonnement de gestion clinique complet qui couvre la progression de la maladie, les décisions relatives à plusieurs visites, le retour d'information sur la réponse au traitement et la prescription de médicaments.
* Le système tire parti des capacités de contextualisation à long terme de Gemini, combinant la récupération contextuelle avec un raisonnement structuré pour garantir que les protocoles de gestion soient hautement cohérents avec les connaissances cliniques faisant autorité telles que les directives NICE et les meilleures pratiques du BMJ.
* Le système a obtenu des résultats égaux ou supérieurs à ceux d'un médecin généraliste pour de multiples indicateurs, notamment la pertinence globale du protocole, la qualité des recommandations de traitement et l'exactitude des recommandations d'examen.
Voir le document :
https://www.nature.com/articles/s41586-026-10764-5
Ensembles de données : de la réponse à une question unique aux scénarios cliniques verticaux
Pour évaluer les capacités concrètes de l'IA conversationnelle dans le domaine de la santé en matière de raisonnement pour la gestion à long terme, l'équipe de recherche a construit un système de données à plusieurs niveaux.Il couvre des scénarios cliniques impliquant plusieurs visites et intègre également des recommandations fondées sur des données probantes et des connaissances sur les médicaments.Utilisé pour l'entraînement des modèles, la génération de schémas et l'évaluation standardisée.
L'outil d'évaluation principal est un ensemble de données intitulé « Scénario OSCE virtuel à visites multiples ».L'étude a compilé un total de 100 études de cas indépendantes.Les cas sont répartis équitablement entre cinq spécialités : cardiologie, pneumologie, obstétrique-gynécologie/urologie, gastro-entérologie et neurologie/médecine musculo-squelettique, avec 20 cas par spécialité. Tous les cas ont été conçus conjointement par des cliniciens canadiens et indiens et élaborés en se référant aux protocoles de traitement des recommandations cliniques du NICE et des recommandations de bonnes pratiques du BMJ.
Contrairement aux séances de questions-réponses médicales classiques qui se déroulent en une seule session, ces cas ont été conçus pour impliquer trois consultations consécutives. Chaque scénario comprend non seulement le motif de consultation initial du patient,Il comprend également des informations longitudinales telles que l'évolution des symptômes, la réponse au traitement et les résultats des examens complémentaires.L'objectif était de refléter fidèlement le processus décisionnel réel dans la prise en charge des maladies chroniques et le suivi des cas complexes. Afin d'accroître la difficulté clinique, certains cas intégraient des éléments tels que des incohérences dans les informations et des comorbidités multisystémiques, pour tester les capacités de jugement du système dans des conditions non standard.En plus de 100 cas d'évaluation formels, l'étude a également mis en place 20 scénarios de validation pour la pré-expérimentation et l'étalonnage des scores.
L'approche fondée sur des données probantes provient d'une base de connaissances en matière de lignes directrices cliniques.Cette base de connaissances contient 627 documents, dont 527 recommandations NICE et 100 documents de bonnes pratiques du BMJ.La base de connaissances, d'une taille totale d'environ 10,5 millions de jetons, couvre les critères diagnostiques, les parcours de soins, les plans de traitement et les recommandations de suivi. Lors de l'évaluation, cette base est accessible au système d'IA et aux médecins généralistes participants afin de simuler la consultation de recommandations en situation clinique réelle et de garantir ainsi une comparaison homme-machine aussi équitable que possible.
La prise de décision en matière de médicaments est une composante indispensable du raisonnement managérial. Par conséquent,L'équipe de recherche a également construit un banc d'essai spécifique pour RxQA.Ce référentiel permet d'évaluer la compréhension, par un modèle, des instructions relatives aux médicaments, de leurs indications, contre-indications, posologies et risques liés aux médicaments. Il comprend 600 questions à choix multiples, issues des notices de médicaments de l'OpenFDA américain et du Formulaire national britannique, réparties en deux catégories : questions courtes et simples et questions approfondies portant sur des scénarios longs.La première version des questions a été générée par le modèle Gemini conformément aux instructions, puis examinée, révisée et corrigée avec difficulté par 8 pharmaciens agréés des deux pays.En raison de restrictions de licence, seules 300 questions d'OpenFDA sont actuellement disponibles pour le public, fournissant une référence standardisée pour comparer les capacités de raisonnement sur les médicaments.
Modèle AMIE : Permettre aux systèmes de posséder à la fois des « capacités de dialogue » et des « capacités de gestion approfondies »
Cette recherche s'appuie sur le système de santé conversationnel précédemment proposé par Google, AMIE, et intègre des améliorations spécifiques pour répondre aux besoins de raisonnement des gestionnaires. Le nouveau système utilise une architecture collaborative à deux agents, inspirée de la « théorie des deux processus » en sciences cognitives.Un agent est responsable d'un dialogue médecin-patient rapide et continu, tandis qu'un autre agent est responsable d'un raisonnement managérial plus lent mais plus approfondi.Le modèle sous-jacent utilise uniformément Gemini 1.5 Flash pour équilibrer la vitesse de réponse en temps réel et les capacités de raisonnement sur un contexte long.
Spécifiquement,Le système se compose d'un agent de dialogue et d'un agent d'inférence de gestion MX.L'agent de dialogue est plus proche du « Système 1 » : il assure la communication en temps réel avec les patients, recueille leurs antécédents médicaux, explique les plans de traitement et assure le suivi de leur état pendant le dialogue. L'agent Mx est plus proche du « Système 2 » : il est principalement chargé de générer des plans de prise en charge structurés et traçables, basés sur des informations complètes sur la maladie et les recommandations cliniques. Les deux agents synchronisent leurs informations via un module d'état partagé, permettant à l'agent de dialogue d'accéder à tout moment aux résultats d'analyse de Mx. Ainsi, les conseils médicaux sont pertinents tout en préservant une communication naturelle.
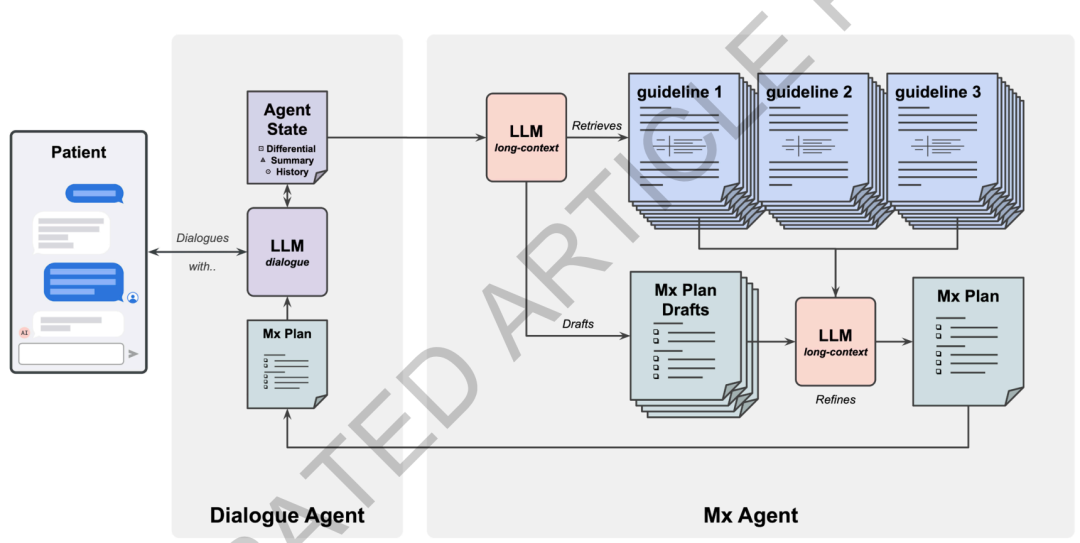
En tant que plateforme interactive, l'agent de dialogue a subi trois mises à jour par rapport au modèle de diagnostic original.D'abord,Le modèle de base a été remplacé par Gemini 1.5 Flash, qui possède de longues capacités contextuelles, lui permettant de gérer des dossiers médicaux plus longs et des informations de dialogue à plusieurs tours.deuxième,Les données d'entraînement comprenaient plusieurs consultations médicales simulées afin d'améliorer la compréhension par le système de la progression de la maladie et de sa prise en charge à long terme.troisième,Après une phase de mise au point supervisée, l'étude a en outre intégré un apprentissage par renforcement basé sur les retours d'information humains et de l'IA afin d'optimiser la qualité du dialogue et les performances de prise de décision.
Lors du raisonnement en temps réel, l'agent de dialogue adopte un processus en trois étapes : « planification-génération-raffinement » :Tout d'abord, le système planifie les prochaines étapes de consultation ou de réponse en fonction de la situation actuelle, puis génère des réponses en langage naturel pour le patient, et enfin effectue une auto-vérification et une correction. Afin d'assurer une prise en charge continue lors des différentes consultations, il maintient également une structure de statut modulaire, comprenant un résumé du patient, un diagnostic différentiel, le plan de traitement actuel et d'autres informations, et la met à jour en continu en arrière-plan pour éviter de repartir de zéro à chaque conversation.
L'agent Mx est le module central de l'ensemble du système, responsable de l'inférence de gestion approfondie.Il exploite pleinement les capacités de contexte long de Gemini 1.5 Flash, en employant une stratégie de « récupération grossière + raisonnement sur le contexte complet ».Afin de minimiser la fragmentation de l'information pouvant résulter d'une recherche par blocs classique, le système indexe d'abord tous les documents de recommandations à l'aide d'un modèle d'intégration Gecko 1B. Ensuite, il génère une requête en langage naturel basée sur le cas du patient actuel, sélectionnant environ six documents complets et hautement pertinents dans la bibliothèque de recommandations, soit environ 256 000 occurrences. Le système intègre ensuite ces recommandations en texte intégral, ainsi que l'historique médical complet du patient, au modèle, ce qui permet à ce dernier d'effectuer un raisonnement holistique à travers les documents et les étapes en une seule requête.
Afin d'améliorer la convivialité et la traçabilité des résultats, l'agent Mx utilise les contraintes du schéma JSON pour générer les résultats et les affiche selon le cadre suivant : « analyse de la situation clinique – définition des objectifs de prise en charge – formulation des étapes de prise en charge et citation des sources de recommandations ». Chaque suggestion doit être accompagnée de la référence de recommandation correspondante. Parallèlement, le système génère d'abord quatre ébauches de prise en charge de manière indépendante, puis les intègre et les améliore en s'appuyant sur le texte original des recommandations afin d'optimiser l'exhaustivité et l'adaptabilité de la solution finale.
Elle n'est pas inférieure aux médecins généralistes pour aucun des 15 indicateurs.
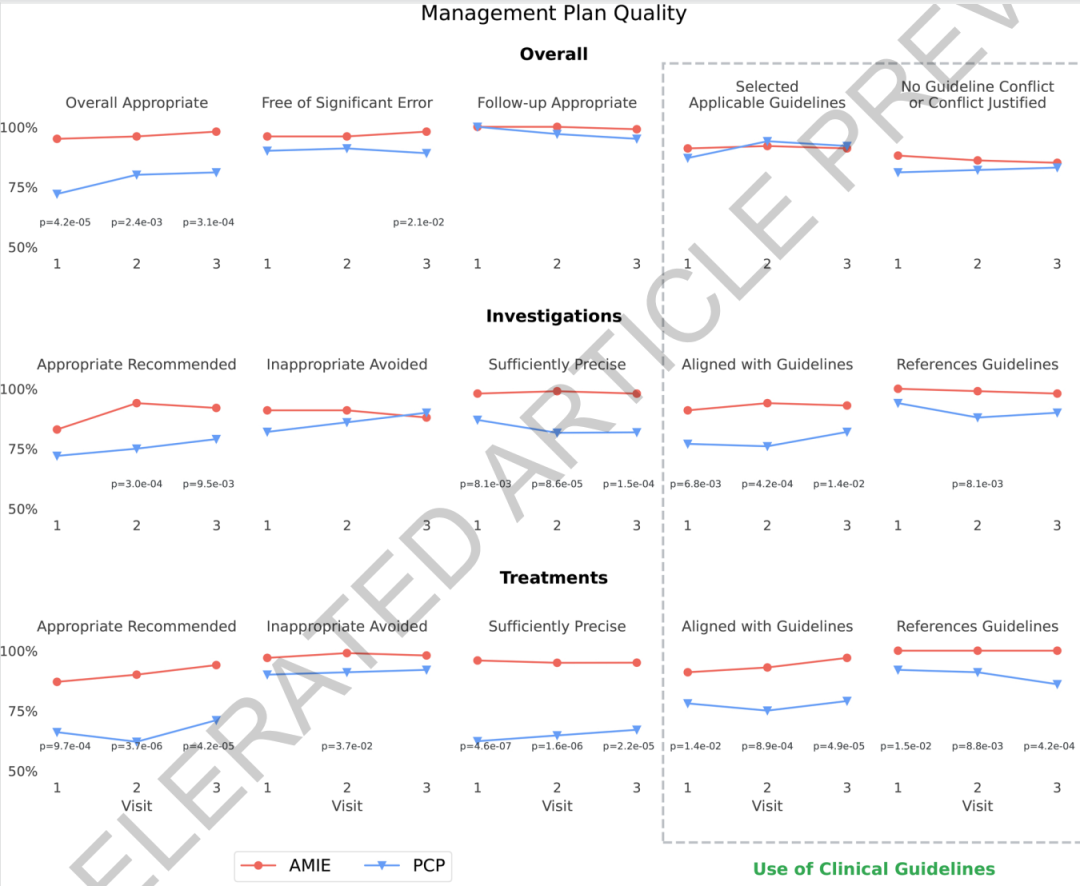
Pour valider la capacité de raisonnement en matière de gestion clinique du système mis à jour, cette étude a utilisé un cadre OSCE virtuel randomisé et en aveugle, combiné à des tests de référence de médicaments RxQA.Le système AMIE a été comparé à celui de 21 médecins généralistes.L'évaluation globale s'articule autour de trois dimensions : la qualité globale du plan de prise en charge, la qualité des recommandations d'investigation et la qualité des recommandations de traitement.
Dans le cadre de l'évaluation clinique, les médecins généralistes et les médecins spécialistes doivent tous deux compléter 100 séries de cas multiples en consultation externe. Trente médecins spécialistes et des patients standardisés ont procédé à une évaluation en aveugle selon deux perspectives : la qualité des soins et l’expérience du patient. Autrement dit, les évaluateurs ignoraient si le plan de traitement provenait d’un système d’IA ou d’un médecin, minimisant ainsi l’impact des biais d’identité sur les résultats. Les tests pharmacologiques ont été menés dans des environnements à documentation ouverte et fermée afin d’observer si des données externes pouvaient modifier les performances du système et du médecin.
Les résultats montrent queEn ce qui concerne la qualité globale du plan de traitement, le système n'est pas inférieur aux médecins généralistes dans les 15 dimensions d'évaluation et présente des avantages statistiques dans de nombreux indicateurs.Prenons l'exemple de la pertinence globale du plan de traitement : le système a obtenu des scores de 95%, 96% et 98% lors des trois consultations, respectivement, supérieurs aux scores du médecin généraliste (72%, 80% et 81%). Concernant le taux de pertinence des recommandations de traitement, le système a obtenu des scores de 87%, 90% et 94%, respectivement, également supérieurs aux scores du médecin généraliste (66%, 62% et 71%).
Le système présente également un avantage constant en termes de précision de ses recommandations d'examen et de traitement.Le taux de précision de ses recommandations de traitement est constamment supérieur à 95%, tandis que celui des médecins généralistes se situe entre 62% et 67%.En matière de respect des recommandations, la traçabilité du système est nettement supérieure à celle des médecins, car chaque recommandation exige une citation explicite. Ce résultat suggère que l'intégration du raisonnement contextuel étendu au texte original des recommandations pourrait améliorer la stabilité et l'interprétabilité du modèle dans le cadre de tâches de gestion complexes.
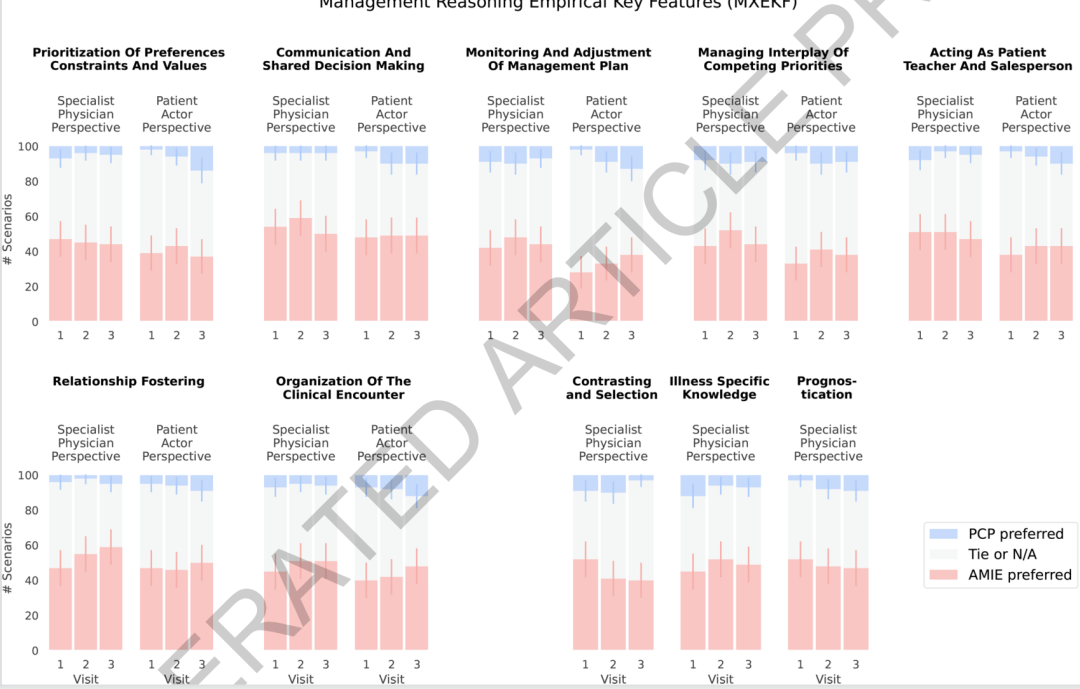
Dans le cadre de l'évaluation des préférences selon une double perspective, l'étude a porté sur 10 dimensions fondamentales du raisonnement managérial, aboutissant à 51 séries de comparaisons. Dans près de la moitié des cas, le spécialiste et le patient ont jugé leurs performances comparables.Dans les cas où une préférence claire a été observée, le taux de victoire du système était de 47%, significativement plus élevé que le 7% pour les médecins généralistes.Plus particulièrement, les tendances d'évaluation des médecins spécialistes et des patients sont globalement cohérentes, ce qui indique que les avantages du système se reflètent non seulement dans le jugement professionnel, mais aussi dans des dimensions liées à l'expérience du patient.
À mesure que le nombre de visites augmente, les avantages du système en matière de gestion du temps, tels que le suivi dynamique, le parcours patient et la relation médecin-patient, deviennent plus évidents. Ceci correspond à l'objectif initial de la recherche : la difficulté de la gestion du raisonnement ne réside pas dans la justesse d'une réponse unique, mais dans la capacité à relier en permanence l'évolution de l'état du patient, le retour d'information sur le traitement et les prochaines étapes du plan de soins.
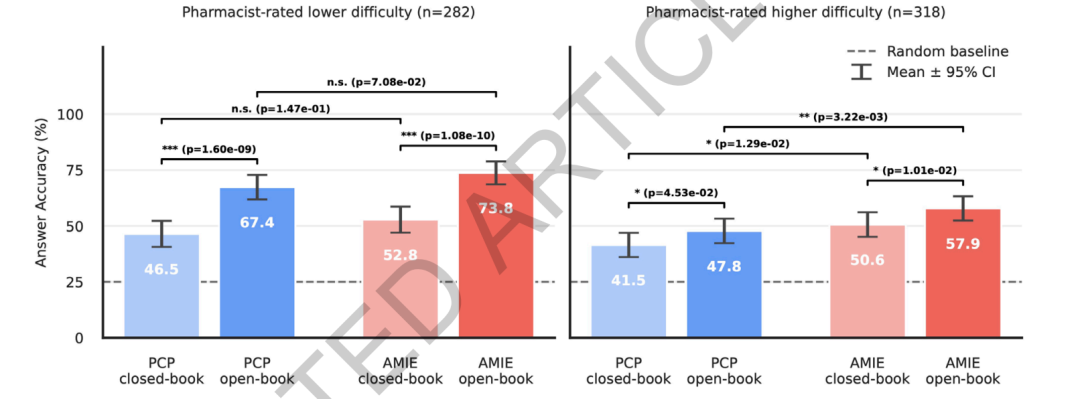
En matière de raisonnement sur les drogues,Les analyses comparatives de RxQA montrent que le système surpasse les médecins généralistes sur des questions très difficiles évaluées par des pharmaciens.En situation de documentation restreinte, la précision du système était de 50,61 % (TP3T), contre 41,51 % pour les médecins généralistes. En situation de documentation ouverte, la précision du système était de 57,91 % (TP3T), contre 47,81 % pour les médecins généralistes. Aucune différence significative n'a été observée entre les deux méthodes pour les questions les plus simples. La documentation ouverte s'est avérée utile tant pour le système que pour les médecins, améliorant notamment la précision de plus de 20 points de pourcentage pour les questions les plus simples. L'amélioration était moindre pour les questions plus difficiles, mais restait néanmoins statistiquement significative. Ceci indique que le modèle présente un certain avantage relatif pour les tâches complexes d'intégration d'informations sur les médicaments, mais que les ressources externes seules ne permettent pas de résoudre entièrement les problèmes de raisonnement médicamenteux très complexes.
Derniers mots
L'intérêt de cette étude ne réside pas dans la démonstration que des modèles médicaux à grande échelle peuvent remplacer les médecins, mais dans le déplacement du centre d'évaluation du « diagnostic » vers la « prise en charge continue ». Comparé aux séances de questions-réponses ponctuelles, le raisonnement thérapeutique est plus proche de la pratique clinique réelle : les médecins doivent constamment adapter leurs jugements en fonction de l'évolution de la maladie, des retours sur le traitement, des données probantes des recommandations et des particularités de chaque patient. L'étude propose un cadre plus pertinent sur le plan clinique pour l'évaluation de l'IA médicale : un examen clinique objectif structuré (ECOS) virtuel à visites multiples, une base de connaissances sur les recommandations, des critères de référence spécifiques aux médicaments et un système à double agent. Toutefois, l'environnement virtuel ne peut encore pas reproduire pleinement les examens physiques, les contraintes de ressources, l'observance du traitement par le patient et les limites de responsabilité propres aux soins de santé réels.
Par conséquent, une évaluation plus prudente consiste à dire que le modèle des mégadonnées médicales évolue de « l’aide au diagnostic » vers « l’aide à la prise en charge ». Sa valeur à court terme n’est pas de remplacer les médecins dans la prise de décisions finales, mais de devenir un outil d’aide à la décision clinique traçable, auditable et mis à jour en continu dans des domaines tels que l’analyse de la progression de la maladie, la conformité aux recommandations, la vérification des médicaments, la planification du suivi et la communication avec les patients.








