Command Palette
Search for a command to run...
L’université De Cambridge Et D’autres Ont Proposé Un Modèle Fondamental Au Niveau Du Pixel Pour Les Missions D’observation De La Terre, Atteignant Une Précision De Pointe (SOTA) Dans De Multiples missions.

Les satellites d'observation de la Terre, capables de surveiller de vastes zones et de longues périodes, sont devenus des outils essentiels dans des domaines tels que la production agricole, la gestion forestière, la surveillance écologique et l'aménagement du territoire. Grâce aux données de télédétection à long terme acquises par satellite, les chercheurs peuvent suivre l'évolution de la surface terrestre. Cependant, les données d'observation satellitaires réelles sont loin d'être parfaites : la couverture nuageuse, les intervalles de revisite orbitaux irréguliers, les différences de résolution des capteurs et le bruit des équipements figurent parmi les facteurs de perturbation.Il en résulte des données brutes incomplètes, hétérogènes et désordonnées, ce qui rend difficile leur utilisation directe pour une analyse intelligente de haute précision.En particulier dans des scénarios détaillés tels que la phénologie agricole et les perturbations écologiques à court terme, les nuages peuvent masquer directement des processus de changement clés.
Actuellement, l'industrie utilise couramment la technologie de composition d'images pour supprimer les nuages et réduire le bruit, générant ainsi des images standardisées sans nuages. Bien que cela améliore la qualité et l'utilisabilité des données, cela entraîne également une perte d'informations importante.Les caractéristiques temporelles fines, telles que la dynamique phénologique et les changements abrupts à court terme, sont souvent atténuées, voire effacées, lors du processus de synthèse, ce qui entraîne la perte d'informations clés.
Ces dernières années, les modèles de base de télédétection ont réalisé des progrès considérables grâce au pré-entraînement à grande échelle. Cependant, la plupart de ces modèles reposent encore sur des données idéales, ayant subi un filtrage et une normalisation poussés, et n'utilisant, lors de l'entraînement que des images synthétiques sans nuages ou des données moyennes de séries temporelles. Cette approche élimine de fait une grande quantité de données d'observation qui, bien qu'affectées par la couverture nuageuse, contiennent néanmoins de véritables tendances d'évolution. Par conséquent, confrontés à des données de séries temporelles éparses, incomplètes et complexes, couvertes de nuages, dans des scénarios opérationnels réels, ces modèles rencontrent des difficultés.L'extraction instable des caractéristiques réduit considérablement la capacité de généralisation.
Pour surmonter cet obstacle, une équipe de recherche conjointe des universités de Cambridge, d'Aalto et de Bristol a élaboré un nouveau paradigme d'apprentissage des caractéristiques temporelles basé sur l'algorithme des jumeaux de Barlow. Au lieu de filtrer les données contenant des nuages, ce paradigme contraint la cohérence des caractéristiques entre différents sous-ensembles d'observations au même endroit, permettant ainsi au modèle d'apprendre de manière autonome les variations spatio-temporelles stables de la surface terrestre et de former des représentations des caractéristiques de télédétection avec une invariance d'échantillonnage temporel. Sur cette base,L'équipe de recherche a également proposé TESSERA, un modèle de base de télédétection au niveau du pixel pour les données de séries temporelles multimodales Sentinel-1/Sentinel-2.
Les résultats de recherche associés, intitulés « TESSERA : Intégrations temporelles des spectres de surface pour la représentation et l'analyse de la Terre », ont été publiés sur la plateforme de prépublication arXiv.
Points saillants de la recherche :
* Construire des représentations vectorielles de caractéristiques à l'échelle mondiale et au niveau du pixel avec une utilisation élevée des étiquettes, concevoir une nouvelle architecture auto-supervisée et entraîner un modèle de base de télédétection au niveau du pixel qui intègre les données multimodales Sentinel-1/Sentinel-2.
* Introduction d'une solution de données intégrées conforme aux directives FAIR, publiant un ensemble de données annuel mondial d'intégrations de caractéristiques entières 8 bits au niveau du pixel avec une résolution de 10 mètres, fournissant des ressources de télédétection conformes qui peuvent être déployées directement.
* Des expériences ont montré que TESSERA peut atteindre une précision de pointe avec une efficacité d'étiquetage extrêmement élevée dans diverses tâches de classification, de segmentation et de régression, ne nécessitant généralement qu'un en-tête de tâche léger et un minimum de calculs.

Voir le document :
https://hyper.ai/papers/2506.20380
Jeu de données : Construction d’un système d’évaluation multidimensionnel, du niveau global au niveau local
Cette étude a permis de construire un système de données de télédétection temporelles à grande échelle et à l'échelle mondiale, utilisé à la fois pour le pré-entraînement du modèle et pour l'évaluation de sa capacité de généralisation. Ce système comprend un ensemble de données de pré-entraînement et un ensemble de données d'évaluation.Toutes les données sont basées sur les données radar de Sentinel-1 et les données optiques de Sentinel-2.Exploiter pleinement les avantages complémentaires de l'observation radar et optique.

Au cours de la phase de pré-entraînement, l'équipe de recherche a constitué un ensemble de données de séries temporelles à grande échelle à l'échelle mondiale, couvrant la période de 2017 à 2024 et englobant spatialement plus de trois mille tuiles de grille dans le monde entier.Un total d'environ 800 millions d'échantillons de pixels d.Contrairement à de nombreux jeux de données rigoureusement sélectionnés et standardisés, celui-ci conserve autant que possible les caractéristiques originales des observations réelles, notamment les données manquantes, l'échantillonnage irrégulier et la couverture nuageuse. De plus, chaque pas de temps est accompagné d'un masque binaire indiquant les états valides des observations, ce qui permet au modèle de prendre explicitement en compte les données manquantes et les différences de qualité des observations.
Étape d'évaluation en aval,L'équipe de recherche a sélectionné six jeux de données de référence accessibles au public, couvrant trois tâches principales : la classification, la segmentation et la régression.La zone d'évaluation couvre plusieurs pays et régions, dont l'Allemagne, la France, l'Autriche, la Finlande et la Malaisie, et englobe des scénarios d'application typiques tels que l'agriculture et la sylviculture. Chaque tâche comprend à la fois des ensembles de données régionaux à grande échelle et des ensembles de données locaux plus précis afin d'évaluer respectivement la transférabilité interrégionale du modèle et ses capacités de modélisation fine des caractéristiques.
De plus, face à la rareté actuelle de données d'annotation multimodales Sentinel-1/2 à haute résolution et multi-temporelles,L'équipe de recherche a également élaboré indépendamment deux nouveaux référentiels d'évaluation :Le premier est un ensemble de données de cartographie des cultures à l'échelle de la parcelle autrichienne, utilisé pour évaluer les capacités de classification et de segmentation dans des scénarios d'agriculture de précision ; le second est un ensemble de données sur la hauteur de la canopée forestière d'Asie du Sud-Est construit sur la base d'une correction lidar, utilisé pour vérifier les performances dans les tâches d'inversion des paramètres de structure forestière.
Un modèle de base au niveau du pixel pour les missions d'observation de la Terre
TESSERA est conçu pour permettre aux modèles d'apprendre des représentations stables directement à partir de données de séries temporelles complexes et incomplètes, tout en préservant autant d'informations d'observation originales que possible, réduisant ainsi la dépendance aux processus de préparation, de complétion et de réparation des données.
à cette fin,Cette étude a proposé pour la première fois une nouvelle façon d'organiser les données de séries temporelles : le d-pixel.L'analyse traditionnelle utilise généralement des images d'une seule scène ou des séries temporelles fixes comme entrée, tandis que d-pixel se concentre sur un seul emplacement spatial, organisant les observations multi-sources du même pixel acquises à différents moments en une séquence d'observations dans l'ordre chronologique.Chaque pixel d contient non seulement des informations optiques Sentinel-2 et des informations radar Sentinel-1, mais identifie également les étapes temporelles présentant une obstruction nuageuse ou des données manquantes grâce à des vecteurs de masque.Cette méthode de représentation préserve intégralement les caractéristiques temporelles des changements de surface. Qu'il s'agisse des changements lents dus à la croissance de la végétation ou des changements brusques et de courte durée causés par des catastrophes, des perturbations, etc., tous sont préservés, évitant ainsi la perte d'information inhérente au processus de régularisation traditionnel.
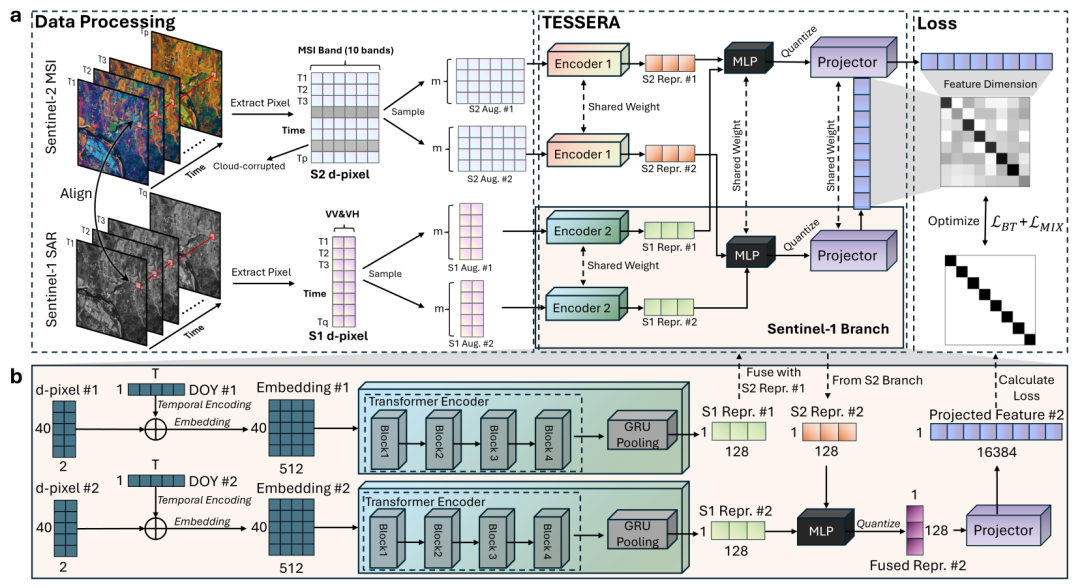
En termes d'architecture du modèle,TESSERA utilise un encodeur à double branche pour traiter séparément les données optiques et radar.Les deux types de données présentent des mécanismes d'imagerie et des propriétés physiques significativement différents. Un encodage indépendant permet d'explorer pleinement leurs caractéristiques respectives, puis leur fusion permet d'obtenir une complémentarité multimodale. Pour chaque modalité, le modèle intègre d'abord les observations pertinentes et ajoute un encodage de localisation quotidien intra-annuel apprenable afin d'introduire l'information temporelle. Ensuite, un encodeur Transformer est utilisé pour modéliser les dépendances temporelles à long terme. Enfin, une unité récurrente à porte est utilisée pour agréger l'ensemble de la série temporelle afin de générer une représentation unimodale de dimension fixe. Après la fusion des caractéristiques optiques et radar, une représentation de surface multimodale de 128 dimensions est formée. L'étude introduit également un apprentissage de la perception quantifiée, compressant les caractéristiques finales en entiers de 8 bits.La taille du stockage a été réduite d'environ 75% sans presque aucune perte de précision.
La stratégie de pré-entraînement constitue une innovation majeure de TESSERA. S'appuyant sur le cadre d'apprentissage auto-supervisé des jumeaux de Barlow, le système extrait aléatoirement, pour un même pixel d, deux sous-ensembles d'observations de sa série temporelle complète afin de construire deux « points de vue » différents. Bien que ces deux ensembles d'observations contiennent des instants différents, et même que certaines données soient manquantes, ils décrivent le même objet de surface.
Lors de l'entraînement, le modèle doit projeter les deux ensembles d'observations dans un espace de caractéristiques aussi cohérent que possible. De cette manière,Le modèle n'apprend plus les caractéristiques instantanées d'une observation spécifique, mais plutôt les schémas de surface stables cachés derrière différentes observations.Ceci permet d'obtenir des représentations de caractéristiques robustes aux méthodes d'échantillonnage temporel. De plus, l'étude introduit une stratégie hybride de régularisation et de brassage global afin d'améliorer encore la robustesse du modèle face aux perturbations observationnelles et à l'autocorrélation spatiale.
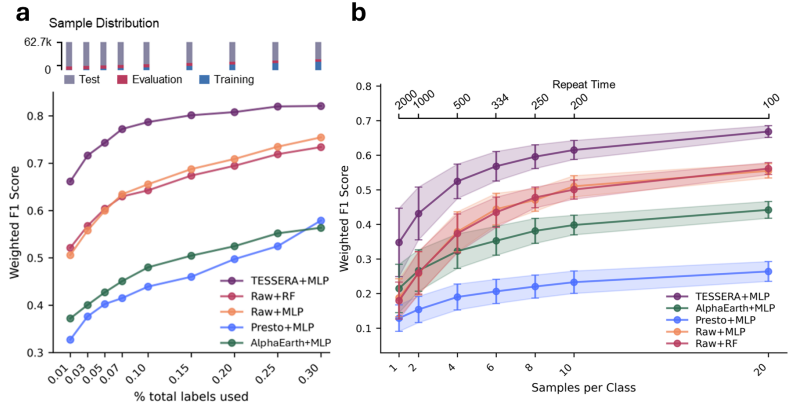
TESSERA démontre ses avantages dans les données peu étiquetées et éparses.
Afin d'évaluer de manière exhaustive les performances de TESSERA, cette étude a conçu une expérience systématique basée sur des scénarios d'application typiques en télédétection. L'expérience, portant sur trois tâches (classification, segmentation et régression), a permis de vérifier les performances du modèle pour différentes échelles de données, conditions d'annotation et scènes régionales. Plusieurs modèles de base de télédétection et des modèles visuels classiques ont été sélectionnés comme références, et trois taux d'annotation uniformes (1%, 30% et 100%) ont été définis.L'objectif est d'évaluer la capacité d'apprentissage dans des scénarios où les étiquettes sont rares.Pour garantir l'équité, des adaptateurs légers sont utilisés pour l'inférence en aval entre différentes tâches.
Dans les tâches de classification, TESSERA présente un avantage significatif dans l'apprentissage des caractéristiques temporelles. Le modèle obtient des performances de premier plan tant pour la classification des espèces d'arbres à l'échelle nationale que pour les tâches de classification plus fines des cultures.En particulier dans les scénarios avec des tailles d'échantillon extrêmement faibles utilisant uniquement des données étiquetées 1%, TESSERA maintient des performances stables.La précision de la classification a été améliorée d'environ 8 points de pourcentage par rapport à la méthode de référence optimale. Cet avantage provient principalement de la modélisation efficace des changements de surface à long terme. Grâce à l'utilisation d'observations temporelles complètes permettant de saisir les cycles de croissance de la végétation et ses caractéristiques phénologiques, des représentations catégorielles très discriminantes peuvent être obtenues, même avec un minimum d'annotations.
Dans les tâches de segmentation, TESSERA a également démontré d'excellentes capacités de rendu des détails spatiaux. Face à des tâches de segmentation de terres agricoles à grande échelle, le modèle a atteint des performances de pointe lorsque les données étaient entièrement étiquetées ; dans des scénarios avec peu d'étiquetage, ses performances ont même surpassé celles de tous les modèles de contrôle. Il convient de noter que…TESSERA peut apprendre efficacement les informations contextuelles spatiales en utilisant uniquement un décodeur léger, tout en maintenant la précision et en garantissant l'efficacité du déploiement.Sur l'ensemble de données de segmentation sémantique des cultures autrichiennes, le modèle génère des limites de parcelles plus claires, réduit considérablement la confusion entre les différentes cultures et démontre une cohérence sémantique globale plus forte.
La tâche de régression évalue principalement la capacité du modèle à représenter des paramètres de surface continus. Lors de l'estimation de la biomasse aérienne, TESSERA a obtenu les meilleurs résultats à différentes échelles d'étiquetage, avec des erreurs de prédiction plus faibles et une distribution spatiale plus continue. Pour l'inversion de la hauteur de la canopée forestière, le modèle a démontré sa capacité à capturer les informations tridimensionnelles de la structure forestière, les résultats d'estimation présentant la plus forte concordance avec les données de mesures lidar et permettant de restituer efficacement les caractéristiques de la structure verticale de la forêt.
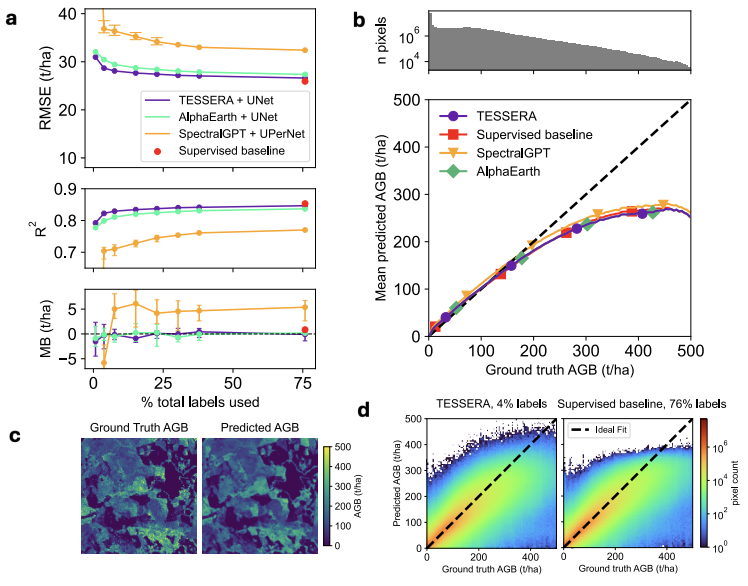
D'après tous les résultats expérimentaux,TESSERA conserve un avantage stable dans les trois types de tâches : classification, segmentation et régression, et cet avantage est encore plus évident dans des conditions complexes telles qu'une faible annotation, des données éparses et des observations manquantes.Comparé à de nombreux modèles qui s'appuient sur des données d'entraînement de haute qualité, TESSERA présente une dégradation des performances plus progressive dans des scénarios de télédétection réels, démontrant une robustesse et une capacité de généralisation supérieures.
Derniers mots
Les modèles fondamentaux de télédétection nécessitent-ils réellement des « données idéales » ? L’approche de TESSERA propose une réponse différente : permettre aux modèles d’interagir directement avec des séquences d’observations réelles incomplètes, irrégulières et souvent perturbées par les nuages, en apprenant des représentations de caractéristiques avec une invariance d’échantillonnage temporelle dans un cadre d’apprentissage auto-supervisé. Cela ne signifie pas que le nettoyage des données devient superflu, mais suggère plutôt que les chercheurs pourraient se concentrer non plus sur le « nettoyage des données », mais plutôt sur « l’apprentissage de la gestion des données imparfaites par les modèles ». Après tout, chaque image satellite contenant des nuages fait partie des observations du monde réel. Plutôt que de rechercher constamment des données toujours plus « parfaites », permettre aux modèles de comprendre la complexité du monde réel pourrait constituer une voie essentielle pour la généralisation des modèles fondamentaux de télédétection.








