Command Palette
Search for a command to run...
Les Performances De Prévision Des Crues Sont Comparables À Celles Du Service Météorologique National Américain ; Le Modèle D’apprentissage Automatique Guidé Par Les Connaissances FHNN Améliore La Précision Des Prévisions En Combinant Des Données D’observation En Temps réel.

Les inondations figurent parmi les catastrophes naturelles les plus fréquentes et les plus étendues au monde, constituant une menace à long terme pour le développement socio-économique et la sécurité publique. Le changement climatique entraînant une augmentation de la fréquence des épisodes de pluies extrêmes, le risque d'inondation s'accroît significativement dans de nombreuses régions. Des prévisions d'inondation précises et opportunes fournissent non seulement des informations cruciales pour la prévention et l'atténuation des catastrophes, mais aussi une aide précieuse à la décision pour la gestion des ressources en eau, l'aménagement urbain et la production agricole.
Pendant longtemps, la prévision des crues s'est principalement appuyée sur des modèles de processus physiques (PBM).En se basant sur la théorie du cycle hydrologique, les variations du ruissellement sont prédites en simulant des processus tels que les précipitations, l'évaporation, les variations de la teneur en humidité du sol, la recharge des eaux souterraines et la confluence des rivières.Par exemple, le modèle de comptabilité de l'humidité du sol de Sacramento (SacSMA), largement utilisé par le Service météorologique national des États-Unis, est un modèle hydrologique typique de bassin versant. Les modèles physiques reposent sur des bases scientifiques solides et jouent un rôle crucial dans la recherche hydrologique et les prévisions opérationnelles. Cependant,Ces types de modèles nécessitent généralement un étalonnage complexe des paramètres, et leurs capacités de simulation sont souvent limitées pour les processus hydrologiques présentant de fortes caractéristiques non linéaires.
Ces dernières années, l'intelligence artificielle a connu un développement rapide en hydrologie, notamment grâce à l'application de plus en plus répandue des modèles d'apprentissage profond à la prévision des ruissellements. Les réseaux de neurones à séries temporelles, tels que les réseaux LSTM (Long Short-Term Memory), sont capables d'apprendre des relations complexes entre les précipitations et les ruissellements à partir de vastes ensembles de données historiques et ont démontré, dans de nombreuses études, des capacités de prédiction supérieures aux modèles traditionnels.
Cependant, les modèles purement basés sur les données sont eux aussi confrontés à de nouveaux défis. D'une part, ces modèles manquent souvent d'interprétabilité physique et peinent à refléter les processus hydrologiques réels ; d'autre part, leur capacité de généralisation demeure incertaine lors d'événements climatiques extrêmes ou pour les bassins versants non observés. C'est pourquoi une nouvelle approche de recherche a progressivement émergé au sein de la communauté hydrologique.Cela implique d'intégrer les connaissances du domaine dans les modèles d'apprentissage automatique afin de construire des modèles intelligents à la fois hautement prédictifs et conformes aux lois physiques.Cette approche est connue sous le nom de « Knowledge-Guided Machine Learning (KGML) ».
Dans ce contexte, une équipe de recherche de l'Université du Minnesota Twin Cities a développé un nouveau modèle d'apprentissage automatique guidé par les connaissances.La structure algorithmique de ce modèle est directement inspirée par les sciences hydrologiques et est appelée réseau neuronal hiérarchique factorisé (FHNN).Les recherches montrent que, sur une période de 2 à 7 jours après la publication des prévisions, le modèle est aussi performant, voire plus performant, que les prévisions d'inondations du Service météorologique national, et surpasse les méthodes d'apprentissage automatique classiques qui n'intègrent pas de connaissances en sciences physiques dans leur structure.
Les résultats de recherche pertinents, intitulés « Apprentissage automatique guidé par les connaissances pour la prévision opérationnelle des inondations », ont été publiés dans la revue Water Resources Research.
Points saillants de la recherche :
* La méthode proposée intègre des informations d'observation via un modèle inverse pour construire une représentation hiérarchique multi-échelle de l'état du bassin versant.
* 12 à 18 heures après la génération des prévisions, le modèle FHNN a généralement surpassé les prévisionnistes humains experts utilisant des modèles de mécanismes physiques.
* La méthode proposée surpasse un modèle alternatif de pointe (LSTM autorégressif), en particulier dans les bassins versants arides, des régions souvent difficiles à prévoir à l'aide d'autres méthodes.

Adresse du document :
https://agupubs.onlinelibrary.wiley.com/doi/10.1029/2024WR039064
Suivez notre compte WeChat officiel et répondez « FHNN » en arrière-plan pour obtenir le PDF complet.
Jeux de données : Équilibrer les jeux de données de référence et les jeux de données d’entreprise
Pour valider le pouvoir prédictif du modèle, les chercheurs ont utilisé deux types d'ensembles de données :
Ensemble de données de référence CAMELS-US à grand échantillon
Lors des phases d'entraînement et d'évaluation initiale du modèle, le jeu de données CAMELS-US, largement reconnu, a été utilisé. CAMELS (Catchment Attributes and Meteorology for Large-Sample Studies) est l'un des jeux de données les plus influents en recherche hydrologique ces dernières années ; sa principale caractéristique est qu'il contient une grande quantité de données d'observation hydrologiques et météorologiques à long terme provenant de bassins versants. L'ensemble de données CAMELS-US couvre des centaines de bassins versants à travers les États-Unis continentaux, y compris des données diurnes sur les précipitations, la température, l'évapotranspiration et le ruissellement fluvial, et fournit également de riches informations sur les attributs des bassins versants.Par exemple, la topographie, le type de climat, les caractéristiques du sol et le couvert végétal. Ces informations constituent un fondement important pour l'étude des processus hydrologiques dans différentes conditions environnementales.
Dans cette étude,Les chercheurs ont sélectionné 531 bassins versants comme sujets d'étude.Les données sont divisées en phases d'entraînement, de validation et de test selon la séquence temporelle :
* 1985–1993 comme période de formation
* 1993–1995 comme période de vérification
* 1995–2005 comme période de test
données prévisionnelles d'inondations pour les entreprises
En plus de l'ensemble de données standard, l'étude a également introduit des données opérationnelles réelles de prévision des crues afin de tester les performances du modèle dans des environnements de prévision réels.L'étude a sélectionné plusieurs bassins fluviaux relevant de la juridiction du Centre de prévision des rivières du Nord et du Moyen-Orient du Service météorologique national (NCRFC) comme études de cas.Ces bassins versants, situés dans le Midwest américain, présentent des caractéristiques climatiques continentales typiques, subissant à la fois des crues dues à de fortes pluies et à la fonte des neiges, ce qui les rend très représentatifs. Les données hydrologiques pertinentes proviennent principalement des observations de débit des cours d'eau réalisées par l'Institut d'études géologiques des États-Unis (USGS), tandis que les données météorologiques, telles que les précipitations et la température, sont issues de la base de données de prévisions du Service météorologique national (NWS).
Il convient de noter que le système de prévision des crues du Service météorologique national américain utilise un modèle de « prévision participative ». Dans ce modèle, un modèle physique génère d'abord des résultats de prévision initiaux, qui sont ensuite ajustés par des hydrographes expérimentés en fonction des observations en temps réel et de leur expertise, pour aboutir à la prévision officielle. Cette méthode permet d'améliorer considérablement la précision des prévisions dans de nombreux cas. Par conséquent, dans cette étude,Comparer les prévisions d'experts humains avec celles de modèles d'apprentissage automatique est important car cela reflète directement le potentiel d'application des modèles d'IA dans des environnements commerciaux réels.
Cadre de modélisation : Architecture guidée par les connaissances FHNN
FHNN est une architecture guidée par les connaissances conçue pour modéliser des processus de dynamique de systèmes complexes et hiérarchiques sur plusieurs échelles de temps.
Cette structure d'interaction hiérarchique est cruciale pour la modélisation hydrologique des bassins versants. Par exemple, un épisode de fortes pluies peut entraîner des variations rapides de l'humidité du sol en surface, laquelle est ensuite utilisée par les plantes par évapotranspiration, un processus qui peut varier à l'échelle horaire, journalière et saisonnière. Simultanément, ces précipitations peuvent reconstituer les réserves d'eau souterraine à travers les couches plus profondes du sol au fil du temps, où les variations sont généralement plus progressives. De plus, l'humidité du sol en surface influence également la quantité d'eau de pluie ou de fonte des neiges qui se transforme en ruissellement lors des crues.
La méthode FHNN vise à capturer ces processus multi-échelles et hiérarchiques qui sont omniprésents en hydrologie et dans la génération du ruissellement.Son architecture générale est illustrée dans la figure suivante :
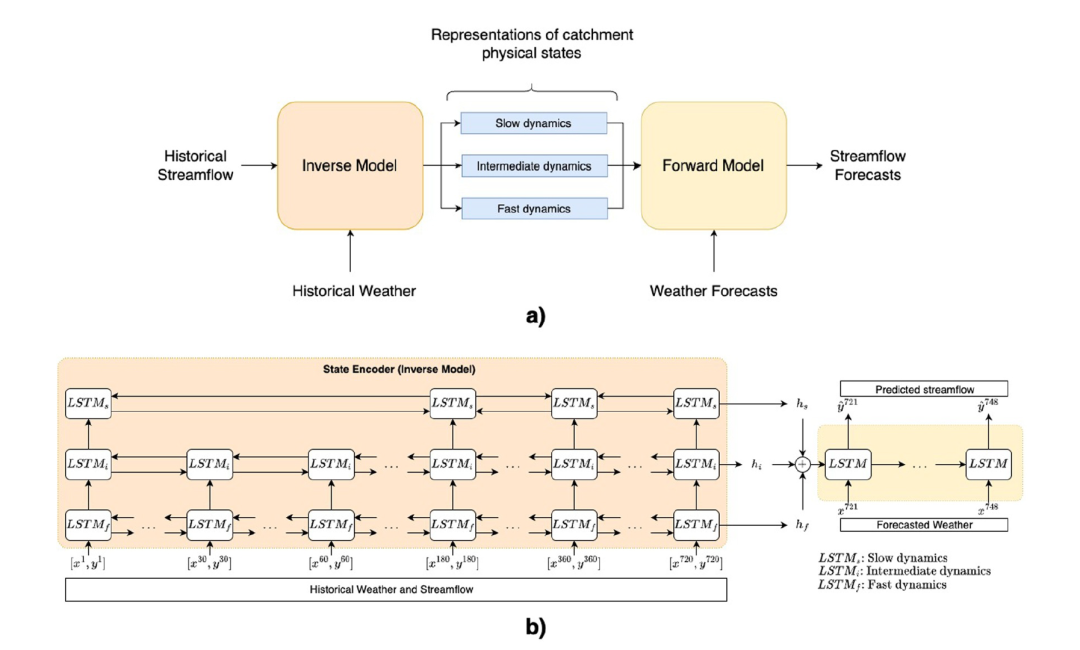
Dans l'architecture FHNN, les connaissances sont introduites de deux manières :
Méthode 1 : Utilisation d’une architecture encodeur-décodeur
Cette approche modélise explicitement les processus directs et inverses à l'aide d'un encodeur d'état (modèle inverse) et d'un décodeur de réponse (modèle direct).La partie encodeur est considérée comme un « modèle inverse », dont la fonction principale est de déduire l'état interne actuel du bassin versant à partir de données météorologiques et de ruissellement historiques.Par exemple, en analysant les variations passées des précipitations, de la température et du ruissellement, le modèle peut estimer des variables clés telles que l'humidité actuelle du sol et les réserves d'eau souterraine. Bien que ces variables soient difficiles à observer directement, elles peuvent être estimées efficacement grâce à des méthodes d'apprentissage automatique. Une fois l'état du bassin versant déterminé, le modèle passe à la phase de décodage.
Le décodeur est considéré comme un « modèle prédictif » dont la tâche est de prédire les variations futures du ruissellement en fonction des conditions connues du bassin versant et des prévisions météorologiques futures.
Le modèle FHNN est entraîné de bout en bout afin de minimiser l'écart entre les données de réponse prédites et réelles. De plus, l'architecture met à jour l'état de l'encodeur en temps réel dès qu'une observation de ruissellement (réponse) est obtenue, permettant ainsi une intégration dynamique des données.
Méthode 2 : Introduction de connaissances dans l’architecture FHNN par le biais d’une conception de factorisation hiérarchique
Dans cette conception,L'encodeur du FHNN est conçu pour capturer les processus multi-échelles et leurs interactions.L'encodeur d'état hiérarchique utilise plusieurs LSTM bidirectionnels pour prendre en entrée des observations historiques de ruissellement et des données météorologiques et générer des représentations pour différentes résolutions/échelles temporelles (par exemple, lente, moyenne et rapide).
Ces représentations vectorielles fournissent des versions compressées des informations contenues dans les données de conduite historiques, les réponses du système et leurs interactions multi-échelles (saisonnière, sous-saisonnière et journalière/sous-journalière). Ces représentations, sous forme de versions compressées d'états potentiels du système (par exemple, l'humidité du sol, la connectivité spatiale, le stock de neige), sont concaténées pour initialiser les états cachés et unitaires du décodeur. Par la suite,Le décodeur utilise les données météorologiques futures comme entrées pour générer des prévisions de ruissellement. L'encodeur et le décodeur sont entraînés conjointement à l'aide d'une seule fonction objectif.La fonction objectif minimise l'erreur quadratique moyenne (RMSE) entre le ruissellement prédit et observé dans la fenêtre de temps de prédiction cible.
Le LSTM bidirectionnel lit simultanément les séquences dans les deux sens, permettant à l'encodeur d'utiliser toutes les relations disponibles dans les données d'observation pour obtenir une compréhension plus complète de l'état du bassin versant.Cette approche a également des implications intuitives en hydrologie. Par exemple, les chercheurs peuvent obtenir des informations sur l'humidité du sol en observant les précipitations et le ruissellement différé qui en résulte ; de même, ils peuvent déduire l'humidité du sol en observant d'abord le ruissellement, puis en analysant les précipitations à l'origine de cet événement. L'encodeur LSTM bidirectionnel permet au modèle d'analyser les données historiques selon ces deux perspectives et d'obtenir la meilleure estimation finale utilisée pour initialiser l'état caché et les états des cellules du décodeur.
FHNN surpasse globalement les experts en prévision humaine qui utilisent des modèles de mécanismes physiques.
Des chercheurs ont démontré la capacité prédictive du réseau FHNN en prévision hydrologique au moyen de plusieurs expériences. La première série d'expériences a comparé FHNN à LSTM-AR, une méthode d'apprentissage profond de pointe utilisant les mêmes variables d'entrée et capacités d'intégration de données, sur un vaste ensemble de données CAMELS. La seconde série d'expériences s'est concentrée sur les performances de FHNN en contexte opérationnel de prévision, en évaluant celles des stations de prévision officielles du NWS (National Weather Service) dans le Midwest américain.
Comparaison avec le modèle LSTM
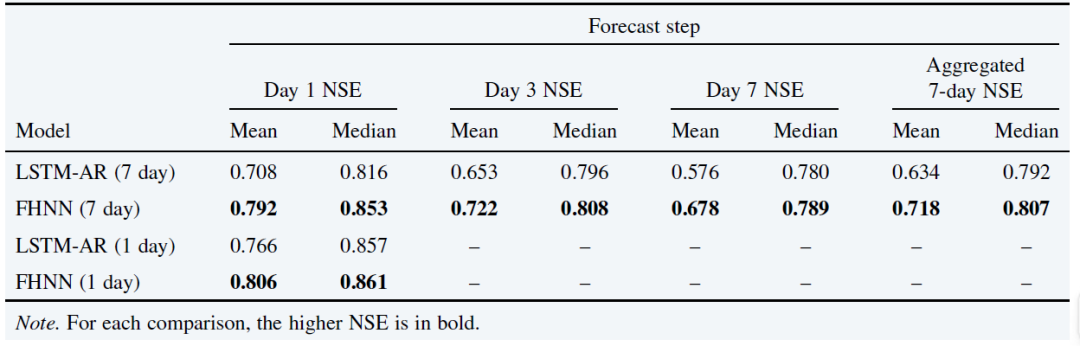
Sur l'ensemble de données CAMELS-US, FHNN a été comparé au modèle LSTM autorégressif traditionnel (LSTM-AR).FHNN surpasse LSTM-AR à la fois sur la période de prédiction de 7 jours et sur la prédiction globale.Même lorsque les deux modèles ont été entraînés uniquement sur des prévisions à un jour, le modèle FHNN a conservé de meilleures performances. Les performances globales sont présentées dans le tableau ci-dessous :
En analysant la relation entre les différences de performance et les caractéristiques de chaque bassin versant, un diagramme a été créé.Les chercheurs ont également constaté que FHNN était plus performant que LSTM-AR dans les bassins versants caractérisés par de faibles précipitations, de faibles coefficients de ruissellement et des niveaux de sécheresse élevés.Comme indiqué ci-dessous :
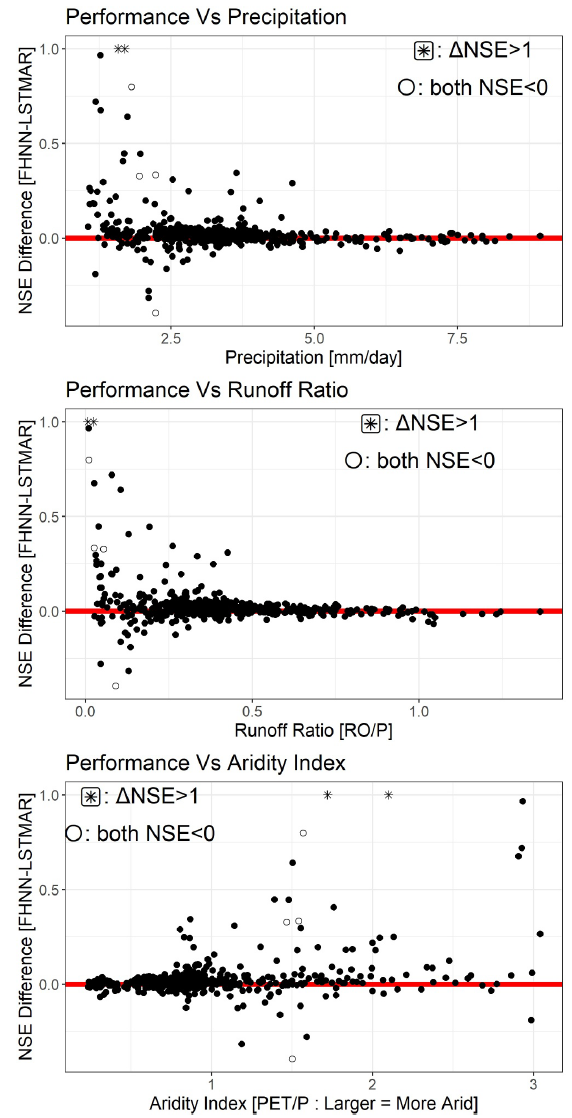
Relation entre les précipitations, le coefficient de ruissellement et l'indice de sécheresse
Aucune tendance claire n'a été observée concernant l'indice de débit de base, l'évapotranspiration potentielle (ETP) et la pente du bassin versant. Ce résultat indique que…Dans les bassins versants arides et les bassins versants présentant un faible rapport entre le ruissellement total et les précipitations totales, FHNN affiche le plus grand avantage en termes de performances par rapport à LSTM-AR.
Les chercheurs ont également comparé FHNN avec LSTM-AR dans le bassin versant KALI4 du NWS, et l'ont en outre comparé aux capacités prédictives des prévisionnistes humains experts du NWS, comme le montre la figure ci-dessous :
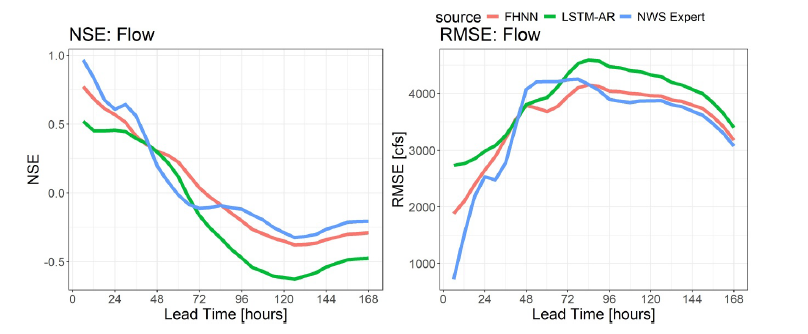
Les résultats montrent que le premier jour suivant la publication des prévisions, la capacité prédictive des prévisionnistes experts du NWS utilisant le modèle SacSMA est supérieure à celle des modèles FHNN et LSTM-AR ; cependant, au cours de la même période,FHNN reste plus performant que LSTM-AR et démontre de meilleures capacités d'intégration des données lors des inondations.Avec un délai de prévision de 2 à 4 jours et plus, FHNN présente le pouvoir prédictif relatif le plus élevé par rapport aux prévisions NWS et LSTM-AR.
Comparaison avec les prévisions commerciales
L'étude a également analysé 46 inondations réelles, et les résultats ont montré que :FHNN a surpassé les prévisions officielles lors de l'événement 65%.Comme le montre le tableau ci-dessous :
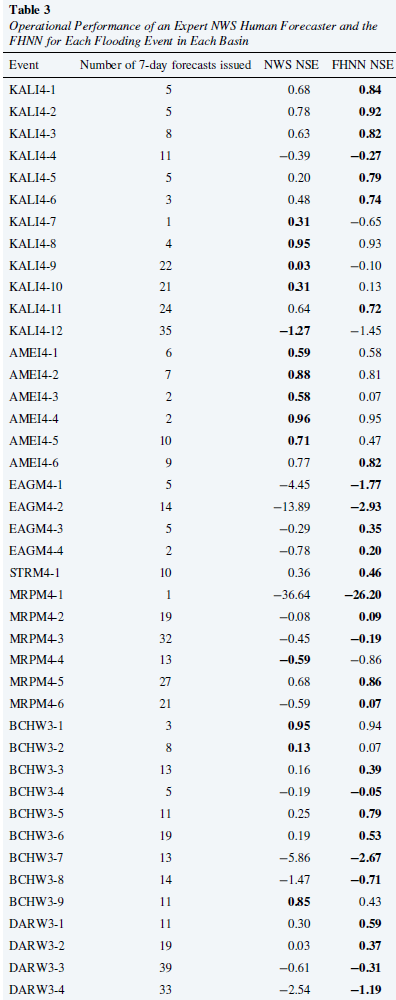
En termes de délai de prévision : pour les prévisions de niveau d'eau (c'est-à-dire les prévisions effectivement publiées par le NWS).FHNN a commencé à surpasser les prévisionnistes experts du NWS 12 heures (2 périodes) après la publication des prévisions ;En matière de prévision du trafic, le réseau de neurones artificiels FHNN surpasse les experts du Service météorologique national (NWS) après 18 heures (3 périodes de prévision). Entre le deuxième et le troisième ou quatrième jour (selon les critères d'évaluation), la capacité prédictive du FHNN est nettement supérieure à celle des prévisionnistes humains. Après le quatrième jour, la différence de capacité prédictive entre le FHNN et les prévisionnistes humains devient négligeable.
capacité de prévision des pics de crue
Un indicateur clé de performance est l'erreur de prédiction du niveau de crête du cours d'eau.Cela fait référence à la valeur de crête la plus élevée atteinte dans l'hydrogramme de ruissellement lors d'un épisode de pluie ou de fonte des neiges particulier.Les chercheurs ont donc évalué les performances des prévisionnistes humains des réseaux FHNN et NWS pour la prévision des pics de crue (en utilisant tous deux des prévisions de précipitations futures incertaines). Ils ont également comparé ces performances avec celles du modèle SacSMA sous-jacent utilisé par les prévisionnistes. Les résultats ont montré que…Le modèle FHNN surpasse nettement les modèles physiques sans correction humaine en matière de prévision des pics de crue, mais reste légèrement en deçà des prévisions des experts.
Les prévisionnistes humains ont surpassé les FHNN dans l'estimation du pic de crue pour presque tous les délais de prévision (sauf pour les délais de prévision d'environ 60 heures ou plus), comme le montre la figure ci-dessous :
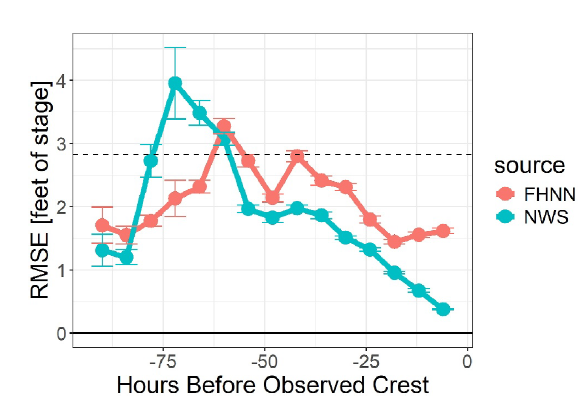
Cependant, même avec des conditions météorologiques futures incomplètement connues, l'estimation des pics de crue par FHNN surpasse toujours le modèle SacSMA, qui est uniquement basé sur les précipitations observées mais sans intervention du prévisionniste.
Entre 48 et 18 heures avant le pic de la crue,Grâce à l'intégration des données, FHNN atteint un taux d'amélioration des prévisions similaire à celui des prévisionnistes humains.Durant cette période, les prévisions ont été mises à jour toutes les 6 heures et l'erreur de prédiction du pic de crue (RMSE) a diminué d'environ 0,2 pied ; cependant, les prévisionnistes humains ont conservé leur avantage prédictif dans toutes les prévisions dans les 2,5 jours précédant le pic de crue ; 12 à 18 heures (2 à 3 pas de temps) avant le pic de crue, la RMSE de prédiction du pic de crue du FHNN a pratiquement cessé de diminuer et a même légèrement augmenté.
Cela indique que le réseau FHNN est moins sensible aux variations du système que les prévisionnistes humains à l'approche des pics de crue. Ce résultat concorde avec les comparaisons des capacités de prévision globales, où le NWS présente une meilleure capacité de prédiction durant les 12 à 18 premières heures suivant la publication de la prévision. La réponse insuffisante du réseau FHNN à proximité des pics de crue pourrait être liée à des problèmes de prédiction des valeurs extrêmes.Pour tout modèle LSTM, prédire le pic de crue le plus élevé est souvent difficile car les données d'entraînement contiennent relativement peu d'événements de crue extrêmes.
Progrès dans l'application de l'intelligence artificielle à la recherche hydrologique
Ces dernières années, l'intelligence artificielle a profondément transformé l'approche technologique de la recherche hydrologique et des prévisions opérationnelles. Des premières méthodes basées sur la régression statistique aux modèles actuels, fondés sur les données et représentés par l'apprentissage profond, les prévisions hydrologiques évoluent progressivement vers une phase de développement plus intelligente et automatisée.
Au niveau applicatif, les modèles d'apprentissage profond temporels, représentés par les réseaux LSTM (Long Short-Term Memory), sont devenus un outil incontournable pour la prévision hydrologique. De nombreuses études ont montré que…Ces types de modèles surpassent généralement les modèles physiques traditionnels dans la simulation du ruissellement multibassin, en particulier dans les zones disposant de données abondantes, où leurs capacités de prédiction sont encore plus remarquables.
Ces dernières années, l'architecture Transformer a été progressivement introduite en hydrologie. Ses avantages en matière de modélisation de longues séquences ont ouvert de nouvelles perspectives pour la capture de la mémoire hydrologique à long terme. Parallèlement, les milieux universitaires et d'ingénierie ont progressivement pris conscience des limites des modèles basés uniquement sur les données. Par exemple, l'absence de contraintes physiques peut conduire, dans des cas extrêmes, à des résultats non conformes aux lois hydrologiques, et l'interprétabilité du modèle s'en trouve également compromise. Par conséquent,Les méthodes d'apprentissage automatique « pilotées par l'information physique » ou « guidées par les connaissances » sont devenues un nouveau sujet de recherche très en vogue.
Concernant les avancées récentes de la recherche, la fusion de données multisources s'impose comme une voie essentielle pour améliorer les performances des modèles hydrologiques. La combinaison de données de télédétection (telles que les précipitations satellitaires, l'humidité du sol et l'équivalent en eau de la neige) avec des données d'observation au sol permet aux modèles d'obtenir des informations plus complètes sur les bassins versants. Parallèlement, les réseaux de neurones graphiques (GNN) commencent également à être utilisés pour modéliser les relations spatiales entre les bassins versants, contribuant ainsi à améliorer la prévision des crues à l'échelle régionale.
Récemment, Google Research a rendu public le jeu de données Groundsource sur les inondations, qui extrait des informations de terrain validées à partir de données non structurées, permettant ainsi de cartographier les zones touchées par des catastrophes historiques avec une précision sans précédent.Des chercheurs ont automatisé le traitement de plus de 5 millions d'articles de presse provenant de plus de 150 pays, compilant au final plus de 2,6 millions d'enregistrements d'événements d'inondation historiques, ce qui fournit une échelle et une couverture de données sans précédent pour la recherche mondiale sur les inondations.
à l'heure actuelle,L'ensemble de données « Groundsource Global Flood Events Dataset » est désormais disponible sur le site web d'HyperAI (hyper.ai) dans la section des ensembles de données et peut être utilisé en ligne.
https://go.hyper.ai/KO3dB
Auparavant, Grey Nearing et son équipe de Google Research avaient mis au point un modèle de prévision des crues fluviales basé sur l'apprentissage automatique, capable de prédire les inondations avec fiabilité jusqu'à cinq jours à l'avance. Pour les crues quinquennales, ce modèle est plus performant, voire aussi performant, que la méthode actuelle pour les crues annuelles. Le système est opérationnel dans plus de 80 pays.
Titre de l'article : Prévision mondiale des crues extrêmes dans les bassins versants non jaugés
Adresse du document :https://www.nature.com/articles/s41586-024-07145-1
Du point de vue des applications commerciales, l'intelligence artificielle ne remplacera pas complètement les prévisionnistes hydrologiques traditionnels, mais jouera probablement un rôle complémentaire grâce à la collaboration homme-machine. Les modèles d'IA peuvent fournir des résultats de prévision rapides et fiables, tandis que les experts peuvent apporter des corrections et des analyses sur les scénarios clés en s'appuyant sur leur expérience. Ce modèle collaboratif permet non seulement d'améliorer l'efficacité des prévisions, mais aussi de renforcer la fiabilité du système lors d'événements extrêmes. Avec l'augmentation constante du volume de données et l'amélioration continue des capacités algorithmiques, les futurs systèmes de prévision des crues seront plus intelligents, plus efficaces et plus adaptables, offrant ainsi un soutien technique accru à la prévention et à l'atténuation des catastrophes ainsi qu'à la gestion des ressources en eau.
Références :
1.https://agupubs.onlinelibrary.wiley.com/doi/10.1029/2024WR039064
2.https://phys.org/news/2026-03-ai-higher-accuracy-current-methods.html
3.https://mp.weixin.qq.com/s/ZWU-v_4k7FIm0MoDh6Rxuw
4.https://www.nature.com/articles/s41586-024-07145-1








