Command Palette
Search for a command to run...
S'appuyant Sur Gemini, Qui Traite Les Informations Provenant De 150 Pays, Google a Publié Groundsource, Un Ensemble De Données Open Source Sur Les Inondations, Couvrant Plus De 2,6 Millions d'enregistrements historiques.
Parmi les diverses catastrophes naturelles qui frappent le monde, les inondations sont l'une des rares à allier une fréquence élevée à un immense pouvoir destructeur. De ce fait, elles constituent depuis longtemps une préoccupation majeure en hydrologie, en climatologie et en gestion des catastrophes. De l'amélioration des modèles de prévision hydrologique et de l'analyse de l'impact du changement climatique sur l'évolution des inondations, à l'évaluation des risques futurs et au perfectionnement des systèmes de prévention et d'atténuation des catastrophes,Presque toutes les études connexes reposent sur la même condition fondamentale : des données historiques de haute qualité sur les inondations.Ces données constituent une référence essentielle pour vérifier la fiabilité du modèle et une base importante pour étayer l'évaluation des risques et les décisions politiques.
Les stations d'observation hydrologiques et météorologiques traditionnelles sont peu nombreuses et la qualité des données est variable, ce qui rend difficile la collecte d'informations précises et à grande échelle sur les inondations. Actuellement, les ensembles de données véritablement exhaustifs sur les inondations sont rares. Bien que la base de données sur les événements de tempête (Storm Events Database) du Centre national américain d'information environnementale (NCE) en soit un exemple typique, de tels enregistrements systématiques restent rares à l'échelle mondiale, et de nombreux pays n'ont pas encore mis en place de bases de données à long terme sur les inondations. Par conséquent, les ensembles de données mondiaux existants sur les inondations souffrent généralement de lacunes en termes de couverture et d'exhaustivité des enregistrements.
Il convient de noter qu'une grande quantité d'informations sur les inondations est restée longtemps dispersée dans des textes non structurés, tels que des articles de presse et des documents gouvernementaux. Si des recherches antérieures ont tenté d'extraire des données de ces sources, les difficultés de normalisation des textes et le coût élevé du traitement manuel ont freiné leur mise en œuvre à grande échelle. Les récents progrès de l'intelligence artificielle générative offrent une perspective novatrice pour résoudre ce problème.
Récemment, Google Research a rendu public le jeu de données Groundsource sur les inondations, qui extrait des informations de terrain validées à partir de données non structurées, permettant ainsi de cartographier les zones touchées par des catastrophes historiques avec une précision sans précédent.Des chercheurs ont automatisé le traitement de plus de 5 millions d'articles de presse provenant de plus de 150 pays, compilant au final plus de 2,6 millions d'enregistrements d'événements d'inondation historiques.Elle offre une échelle et une couverture de données sans précédent pour la recherche mondiale sur les inondations.
à l'heure actuelle,「L'ensemble de données Groundsource Global Flood Events est désormais disponible sur le site web d'HyperAI (hyper.ai) dans la section des ensembles de données.Utilisation en ligne :

Adresse du document :
https://eartharxiv.org/repository/view/12083/
Suivez notre compte WeChat officiel et répondez « Groundsource » en arrière-plan pour obtenir le PDF complet.
À partir de 5 millions d'articles de presse, plus de 2,6 millions de rapports d'inondations ont été analysés.
L'ensemble de données Groundsource a été constitué selon un processus standardisé et automatisé. Lors des phases de collecte de données à l'échelle mondiale et de reconnaissance d'entités, l'équipe de recherche a utilisé certaines infrastructures de Google, notamment le système de reconnaissance d'entités nommées WebRef et l'outil Read Aloud. Cependant, la logique d'extraction des données, le cadre de suggestion du modèle de langage et les règles d'agrégation spatio-temporelle sont tous documentés publiquement. Par conséquent, ce processus peut être reproduit dans différents environnements techniques, même après remplacement par des algorithmes open source ou d'autres modèles de langage.
La construction des données commence par la collecte d'informations d'actualité.L'équipe de recherche a utilisé des robots d'exploration du Web pour collecter les articles de presse publics publiés depuis 2000 et a utilisé WebRef pour calculer un score de pertinence sur le thème des inondations pour chaque article.Les chercheurs ont fixé le seuil à 0,6.dépistage préliminaireEnviron 9,5 millions de pages webCependant, un échantillonnage manuel a révélé que seulement la moitié d'entre eux environ ont effectivement fait état des inondations, tandis que les autres étaient simplement mentionnés en arrière-plan.
Vient ensuite l'étape d'extraction du texte.Le système supprime automatiquement les publicités et les éléments de navigation des pages web, ne conservant que le texte de l'article et la date de publication, et filtre les langues non analysées ou les sites web inaccessibles.Le nombre final d'articles utilisables était d'environ 7,5 millions.Tous les textes non anglais seront traduits en anglais, et les noms de lieux géographiques seront extraits par reconnaissance d'entités afin de constituer une base de données de lieux candidats.
Identifier les inondations spécifiques à partir des articles de presse est la partie la plus complexe de tout le processus. Les articles mentionnent souvent plusieurs lieux et des indications temporelles vagues, comme « hier » ou « la semaine dernière ». Par conséquent,L'équipe de recherche a conçu un cadre de suggestion structuré pour le modèle de langage étendu Gemini et l'a testé à l'aide de 250 articles annotés manuellement.Le modèle a utilisé Google Read Aloud pour extraire le texte brut de 80 langues, puis l'a normalisé en anglais via l'API Cloud Translation. Il a ensuite effectué quatre tâches successives : déterminer si l'article décrivait une inondation réelle, extraire et normaliser la date et l'heure de l'événement, identifier les lieux précis touchés par l'inondation et associer les noms de lieux à des identifiants géographiques standard.
Dans le cadre de ce processus,Sur les 7,5 millions d'articles, environ 5 millions ont été identifiés comme contenant des récits de véritables inondations.D'après des échantillons étiquetés manuellement, la précision de la reconnaissance d'événements est d'environ 751 TP3T et le rappel d'environ 901 TP3T. La précision de l'extraction de la date et du lieu est légèrement inférieure, mais elle fournit néanmoins des indications spatio-temporelles pertinentes.
Pour localiser ces événements sur la carte, le système géocode également les emplacements : si une entité géographique existante peut être appariée, sa limite spatiale est directement invoquée ; si aucune correspondance n’est trouvée, le nom du lieu est converti en coordonnées via un service de géocodage, et une petite zone tampon est générée si nécessaire pour l’analyse spatiale.
Enfin, à partir d'identifiants géographiques et d'informations temporelles, l'équipe de recherche a regroupé les enregistrements consécutifs en événements d'inondation uniques et a effectué un contrôle de qualité, en supprimant les enregistrements dont la portée était trop large ou dont le calendrier était anormal. Après cette série d'étapes,Les résultats ont permis de recueillir plus de 2,64 millions d'enregistrements uniques, chacun correspondant à une observation d'inondation rapportée dans des articles de presse à un moment et un lieu précis.
Évaluation de l'ensemble de données : L'événement 82% a une valeur analytique ; sa précision au niveau de la rue comble une lacune dans les enregistrements de catastrophes à petite échelle.
Pour évaluer la fiabilité de l'ensemble de données Groundsource, ceL'étude analyse les données sous trois aspects : l'exactitude, la distribution spatio-temporelle et la cohérence avec les bases de données externes.Elle a été comparée à deux bases de données majeures : le Système mondial d’alerte et de coordination en cas de catastrophe (GDACS) et l’Observatoire des inondations de Dartmouth (DFO).
Pour évaluer l'exactitude des données, les chercheurs ont sélectionné aléatoirement 400 enregistrements et ont retracé leur provenance jusqu'aux sources d'information originales afin de vérifier les informations de date et de lieu. Les résultats ont montré que les enregistrements strictement exacts représentaient 60% (intervalle de confiance : 95% ± 5%).Si des enregistrements présentant de légers biais mais ayant tout de même une valeur analytique sont inclus, environ 82% d'événements peuvent encore être utilisés pour une analyse ultérieure.Les quelque 181 erreurs TP3T restantes proviennent principalement d'erreurs de positionnement spatial causées par l'ambiguïté des noms de lieux, ainsi que par une mauvaise lecture des expressions temporelles relatives telles que « hier » et « la semaine dernière ».
En termes de distribution spatio-temporelle, l'ensemble de données présente un net « biais récent ».Comme le montre la figure ci-dessous, environ 641 enregistrements TP3T sont concentrés entre 2020 et 2025, dont 151 pour la seule année 2025. Cette tendance reflète davantage la croissance rapide des médias d'information numériques qu'une augmentation du nombre d'inondations elles-mêmes.
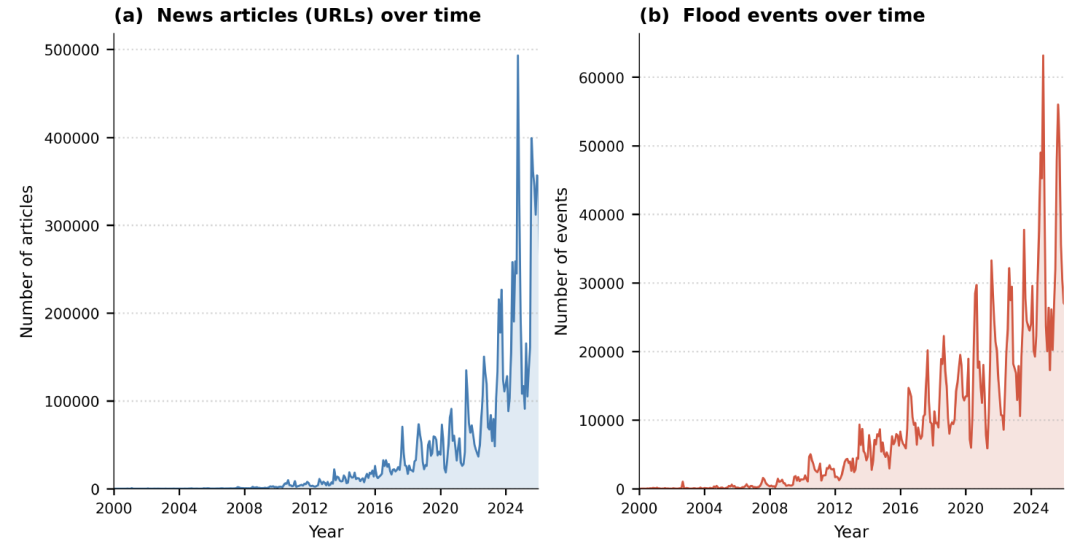
La répartition spatiale est également influencée par l'écosystème médiatique : les événements sont plus nombreux dans les zones bénéficiant d'une forte couverture médiatique, et moins représentatifs dans les zones où l'information numérique est rare ou le support linguistique insuffisant. Toutefois, les données mettent clairement en évidence les zones à haut risque d'inondation telles que l'Europe, l'Asie du Sud et l'Asie du Sud-Est.Sa répartition spatiale correspond parfaitement aux localisations des principales inondations enregistrées par le GDACS.
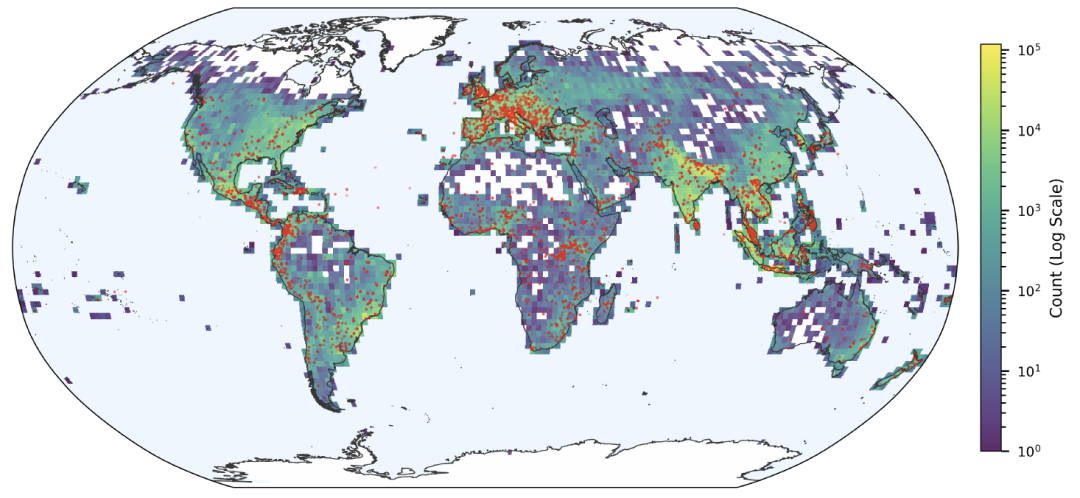
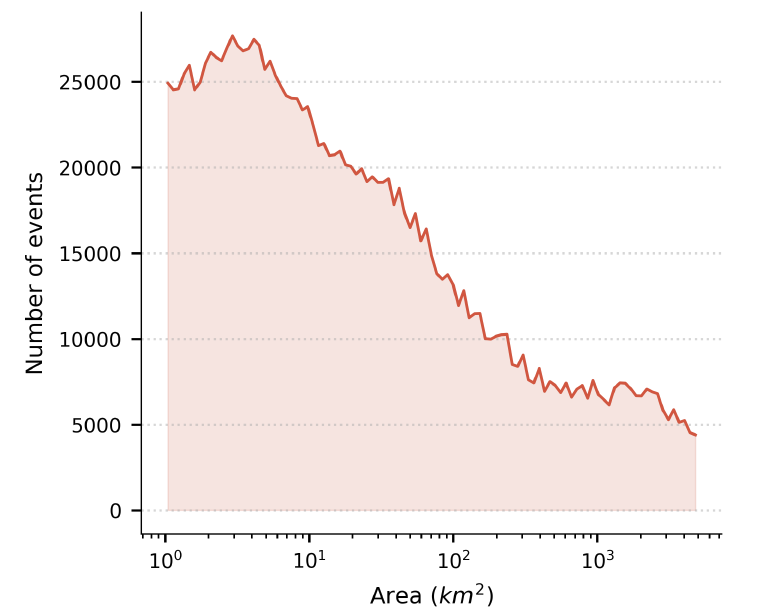
Malgré les biais de saisie, Groundsource offre des performances exceptionnelles en termes de résolution spatiale.Les statistiques montrent que la couverture moyenne des événements extraits est de 142 kilomètres carrés, dont 821 enregistrements TP3T couvrent moins de 50 kilomètres carrés. De nombreux événements peuvent être affinés à l'échelle du pâté de maisons ou de la communauté, permettant ainsi de recenser les inondations localisées souvent négligées par les bases de données mondiales classiques sur les catastrophes.
Dans le cadre de l'évaluation de l'intégrité, l'étude a comparé Groundsource au Système mondial d'alerte et de coordination en cas de catastrophe (GDACS) et à l'Observatoire des inondations de Dartmouth (DFO) par appariement spatio-temporel. Les résultats ont montré que depuis 2020, le taux de rappel des événements GDACS variait de 851 à 1 001 TP3T ; dans les régions dotées d'infrastructures médiatiques bien développées, comme les États-Unis, les taux de correspondance atteignaient respectivement 961 TP3T (GDACS) et 911 TP3T (DFO). De plus,Les taux de rappel sont significativement corrélés à la gravité de l'impact de la catastrophe : les taux de rappel pour les inondations majeures sont proches ou supérieurs à 90%.
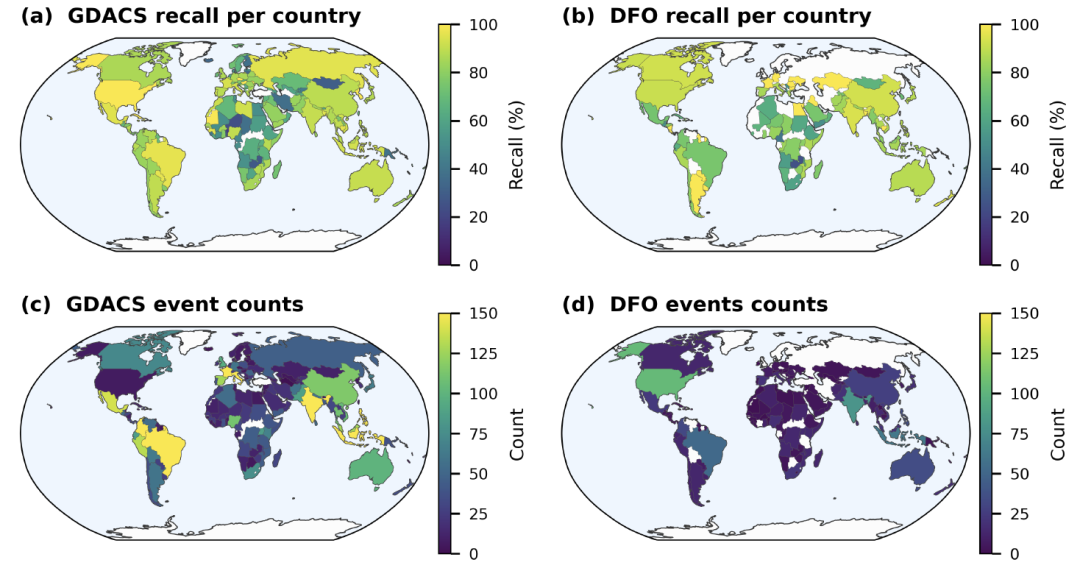
Globalement, bien que Groundsource ne puisse pas fournir une couverture mondiale parfaitement équilibrée,Cependant, avec plus de 2,6 millions d'enregistrements et une haute résolution spatiale, elle compense les lacunes des bases de données traditionnelles sur les catastrophes en matière d'enregistrement des inondations localisées et de petite ampleur.Cela constitue une nouvelle source de données pour la recherche sur les inondations mondiales.
Recherche sur les données d'inondations basée sur l'IA
L'extraction d'informations standardisées sur les inondations à partir de textes non structurés à l'aide de grands modèles de langage devient progressivement une méthode importante dans le domaine de la recherche sur les inondations.
Dans le milieu universitaire, de nombreuses équipes de recherche explorent continuellement cette voie. Des chercheurs du MIT ont proposé une stratégie améliorée de mots-clés et une méthode d'association contextuelle pour résoudre les problèmes d'ambiguïté temporelle et d'ambiguïté des noms de lieux fréquemment rencontrés par les grands modèles de langage dans l'extraction des événements d'inondation.En affinant le modèle à l'aide de données d'observation hydrologiques historiques, l'équipe a amélioré la précision de l'extraction des dates des événements d'inondation à plus de 80% et a développé un module d'adaptation multilingue, permettant au modèle de traiter le texte des actualités dans différentes langues de manière plus stable, construisant ainsi un ensemble de données sur les événements d'inondation couvrant plusieurs régions.
Titre de l'article : Générer des images satellitaires physiquement cohérentes pour les visualisations climatiques
Lien vers l'article :
https://ieeexplore.ieee.org/document/10758300
L'équipe de recherche de l'Université nationale de Singapour a encore élargi le champ d'application de ses recherches.L'équipe a combiné des données historiques sur les inondations, extraites de reportages par l'IA, avec des données sur les réseaux de drainage urbain et des informations topographiques de haute précision, afin d'établir un modèle d'évaluation des risques d'inondation à l'échelle urbaine.En analysant la relation entre la fréquence et l'ampleur des inondations dans différentes régions et les infrastructures urbaines, les chercheurs parviennent à identifier plus précisément les zones à risque et à fournir des références plus ciblées pour la planification de la protection contre les inondations urbaines. Ils s'efforcent également d'évaluer l'évolution des risques d'inondation futurs dans un contexte de conditions climatiques extrêmes.
Titre de l'article : Prévoir les crues importantes grâce à une IA transférable dans les régions où les données sont rares
Lien vers l'article :
https://www.cell.com/the-innovation/fulltext/S2666-6758(24)00090-0
Les progrès de la recherche dans ce domaine commencent également à s'étendre à l'industrie.Microsoft Research s'est associé à la NASA pour développer Hydrology Copilot, une plateforme de prédiction des risques d'inondation basée sur l'IA.Ce système intègre des données sur les inondations issues de reportages, d'observations satellitaires et de données de surveillance hydrologique en temps réel, et utilise des modèles d'apprentissage automatique pour prédire la probabilité d'occurrence d'une inondation et l'étendue potentielle de son impact. Actuellement, la plateforme est testée aux États-Unis et dans plusieurs autres pays afin d'aider les services locaux de gestion des urgences à améliorer leurs procédures d'alerte et de réponse aux inondations.
De manière générale, l'extraction automatique d'informations sur les inondations à partir d'articles de presse devient progressivement une source importante de données complémentaires aux données d'observation traditionnelles. Grâce à l'amélioration continue des capacités des modèles et à l'augmentation du volume de données, cette méthode devrait fournir une base de données plus riche et plus précise pour la recherche sur les risques d'inondation à l'échelle mondiale.
Liens de référence :
1.https://www.geekwire.com/2025/microsoft-nasa-ai-hydrology-copilot-floods








