Command Palette
Search for a command to run...
Dernières Découvertes De l'Université Tsinghua Et De l'Université De Chicago Publiées Dans Nature ! L'IA Permet Aux Scientifiques d'avancer Leur Carrière De 1,37 an Et Réduit Le Champ De l'exploration Scientifique De 4,631 TP3T.

Le développement rapide de l'intelligence artificielle (IA) bouleverse profondément la logique même de la recherche scientifique. De la prédiction précise de la structure des protéines par AlphaFold, récompensée par le prix Nobel, à ChatGPT qui pilote les laboratoires autonomes pour réaliser des expériences à haut débit, en passant par les grands modèles de langage qui facilitent la rédaction scientifique et l'extraction des résultats, l'IA démontre son immense potentiel pour améliorer la productivité de la recherche scientifique et accroître sa visibilité sous diverses formes.
Cependant, si les outils d’IA stimulent les progrès des scientifiques individuels, ils suscitent également une profonde réflexion sur leur impact sur le développement global de la science, la question centrale portant sur le conflit potentiel entre les intérêts individuels et collectifs :L'IA se contente-t-elle d'assister le développement académique individuel des scientifiques, ou peut-elle simultanément stimuler l'exploration diversifiée et les progrès à long terme dans le domaine scientifique ?Bien que les recherches existantes suggèrent que l'IA puisse apporter des avantages considérables aux chercheurs, elle risque aussi d'exacerber les inégalités en raison du manque de formation dans ce domaine, et l'évolution des pratiques de citation transforme discrètement le paysage de la recherche. Cependant, les mesures empiriques à grande échelle de l'impact de l'IA sur la science font encore défaut, et ses effets précis et dynamiques sur l'écosystème de la recherche restent à élucider.
Récemment,Une équipe de recherche de l'université Tsinghua et de l'université de Chicago a publié ses dernières conclusions de recherche dans la revue Nature, intitulées « Les outils d'intelligence artificielle augmentent l'impact des scientifiques mais réduisent le champ d'application de la science ».L'analyse des données issues de 41,3 millions d'articles scientifiques et de 5,37 millions de chercheurs entre 1980 et 2025 révèle un paradoxe surprenant concernant l'IA appliquée à la science : l'IA est un « super accélérateur » pour la recherche individuelle, mais un « dispositif de réduction invisible » pour la science collective. Cette étude se distingue non seulement par l'immensité de son ensemble de données, mais aussi par l'utilisation d'un cadre analytique sophistiqué.Cela apporte des preuves systématiques sans précédent de la compréhension, par l'industrie, de l'impact fondamental de l'IA sur la science.
Adresse du document :
Suivez notre compte WeChat officiel et répondez « Outils d'IA » en arrière-plan pour obtenir le PDF complet.
Autres articles sur les frontières de l'IA :
https://hyper.ai/papers
Démarche de recherche : Construction d’une chaîne causale complète allant de l’individu au collectif.
La méthodologie de cette étude est extrêmement claire. Elle ne se limite pas à une simple description du phénomène, mais construit une chaîne analytique complète, de l'identification à l'exploration du mécanisme.
Point de départ : Identification précise (Quoi)
La première et la plus cruciale étape de la recherche a consisté à distinguer avec précision, au sein d'une vaste littérature, les études qui « utilisent l'IA comme un outil » de celles qui « étudient l'IA elle-même ». L'équipe de recherche a délibérément exclu les travaux relevant des domaines de l'informatique et des mathématiques.L'accent est mis sur six disciplines des sciences naturelles, dont la biologie, la médecine et la chimie.Les recherches devraient se concentrer sur les « répercussions » de l'IA sur les méthodes de production scientifique.
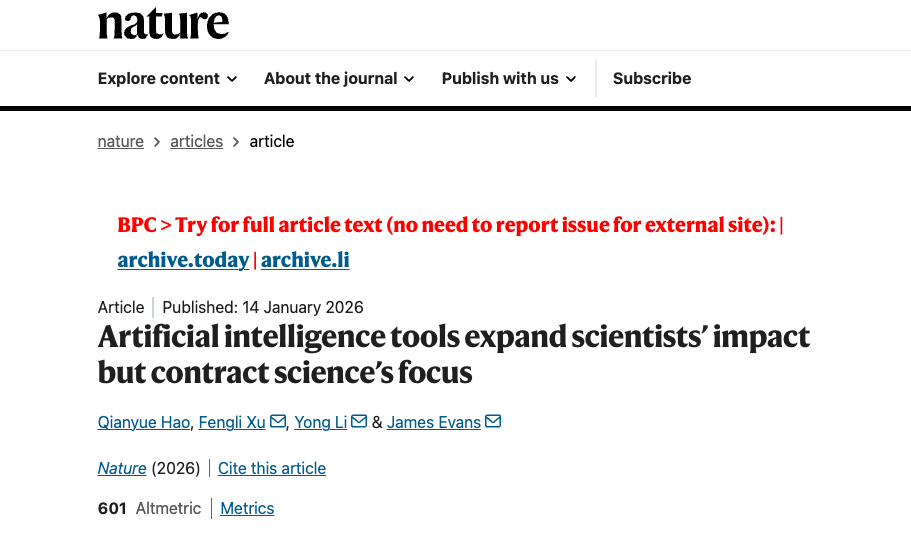
A : Lors de l'ajustement en deux étapes du modèle BERT pré-entraîné, les performances de reconnaissance d'articles de l'IA se sont continuellement améliorées : la première étape utilisait des données d'entraînement relativement grossières, tandis que la seconde a permis d'affiner la discrimination grâce à ces données. Les chercheurs ont entraîné indépendamment deux modèles, l'un à partir des titres (vert) et l'autre à partir des résumés (violet), puis les ont intégrés dans un modèle d'ensemble (orange). Le modèle le plus performant lors des deux étapes a été sélectionné dynamiquement (astérisque rouge) pour identifier tous les articles pertinents.
b : La précision des résultats de reconnaissance a été évaluée par des experts humains. Pour les échantillons couvrant trois étapes du développement de l’IA, un consensus élevé a été atteint entre les experts (κ ≥ 0,93). Le modèle a démontré une grande précision lors de la validation sur des données annotées par des experts, avec un score F1 d’au moins 0,85.
c : Fréquence d'adoption relative des 15 principales méthodes d'IA dans chaque discipline au cours de la période de développement de l'IA sélectionnée.
d, e : Croissance du nombre d’articles intégrant l’IA (d, n = 41 298 433) et de chercheurs utilisant l’IA (e, n = 5 377 346) dans les disciplines scientifiques sélectionnées, de 1980 à 2025, pour les trois périodes suivantes : apprentissage automatique (ML), apprentissage profond (DL) et IA générative (GAI). L’axe vertical est logarithmique.
f : Taux de croissance mensuel moyen du nombre d’articles et de chercheurs en IA dans toutes les disciplines sélectionnées au cours de chacune des périodes ML, DL et GAI (n = 543 observations mensuelles). Les barres d’erreur représentent les intervalles de confiance (IC) à 99% centrés sur la moyenne.
Niveau individuel : Quantification de l'impact individuel
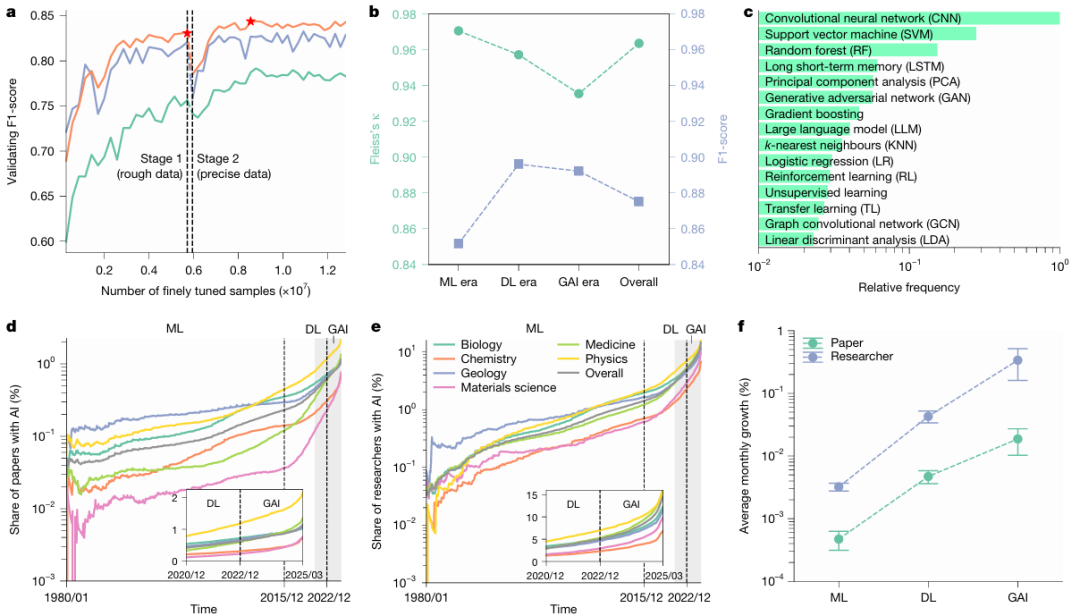
S’appuyant sur une identification précise, l’étude a d’abord répondu à la question : « Quels sont les avantages pour les scientifiques individuels ? »En suivant les publications annuelles, les citations et les transitions de carrière (de jeune chercheur à chef de projet) des chercheurs, l'équipe de recherche est parvenue à un ensemble de données surprenantes :3,02 fois plus d'articles publiés, 4,84 fois plus de citations et une avance de carrière de 1,37 an.
a : Nombre moyen annuel de citations reçues après publication pour les articles sur l'IA (rouge) et les articles non liés à l'IA (bleu) (l'encart montre respectivement les 11 premiers quantiles TP3T et les 101 premiers quantiles TP3T ; n = 27 405 011), indiquant que les articles sur l'IA attirent généralement plus de citations.
b : Comparaison des citations annuelles moyennes entre les chercheurs qui ont utilisé l'IA et ceux qui ne l'ont pas utilisée (P < 0,001, n = 5 377 346), les chercheurs qui ont utilisé l'IA recevant en moyenne 4,84 fois plus de citations que ceux qui ne l'ont pas utilisée.
c : Chez les jeunes chercheurs, une comparaison des probabilités de transition de rôle entre ceux qui ont adopté l’IA et ceux qui ne l’ont pas fait (toutes les observations concernent n = 46 ans). Les jeunes chercheurs ayant adopté l’IA étaient plus susceptibles de devenir des chercheurs expérimentés et moins susceptibles de quitter le milieu universitaire que leurs collègues n’ayant pas utilisé l’IA.
d : Fonction de survie pour la transition de chercheur junior à chercheur senior (p < 0,001, n = 2 282 029). Cette fonction de survie suit une loi exponentielle, ce qui indique que les jeunes chercheurs utilisant l’IA effectuent cette transition plus rapidement. Dans tous les graphiques, les barres d’erreur représentent l’intervalle de confiance (IC) à 99% ; l’encart de la figure a est centré sur les quantiles à 1% et 10%, tandis que les autres graphiques sont centrés sur la moyenne. Tous les tests statistiques ont été réalisés à l’aide de tests t bilatéraux.
Niveau collectif : Révéler les changements structurels
Par la suite, la perspective de recherche est passée du micro-individu au macro-écosystème, soulevant une question plus fondamentale : « Quels changements s’opèrent dans la science dans son ensemble lorsque chacun bénéficie de l’IA ? » À cette fin, l’équipe de recherche a introduit deux indicateurs collectifs novateurs : l’étendue des connaissances, qui mesure la couverture des sujets de recherche ; et l’engagement post-divulgation, qui mesure la densité d’interaction entre les études ultérieures. Les chercheurs ont considéré l’ensemble des résultats ultérieurs citant la même étude originale, en calculant la densité de citations mutuelles entre ces résultats. Les résultats ont montré que les interactions post-divulgation dans la recherche en IA ont diminué d’environ 221 TP3T.
Attribution : Exploration des mécanismes sous-jacents (Pourquoi)
Enfin, les recherches ne se sont pas arrêtées aux seuls phénomènes.Elle s'intéresse plutôt au mécanisme à l'origine de ce paradoxe de « l'expansion-contraction ».En éliminant des facteurs tels que la popularité, l'impact initial et les priorités de financement, l'équipe de recherche a mis en évidence la raison fondamentale : la disponibilité des données. L'IA est naturellement attirée par les domaines matures disposant de données abondantes et d'une modélisation aisée, ce qui entraîne une concentration de l'attention collective et une réduction des possibilités d'exploration.
Cette chaîne logique complète, allant du « Quoi » au « Pourquoi », rend les conclusions de la recherche extrêmement convaincantes.
Points saillants de la recherche : Trois innovations majeures qui s’attaquent directement aux problèmes fondamentaux
Méthodes de reconnaissance de documents basées sur l'IA qui vont au-delà de la simple correspondance de mots-clés :
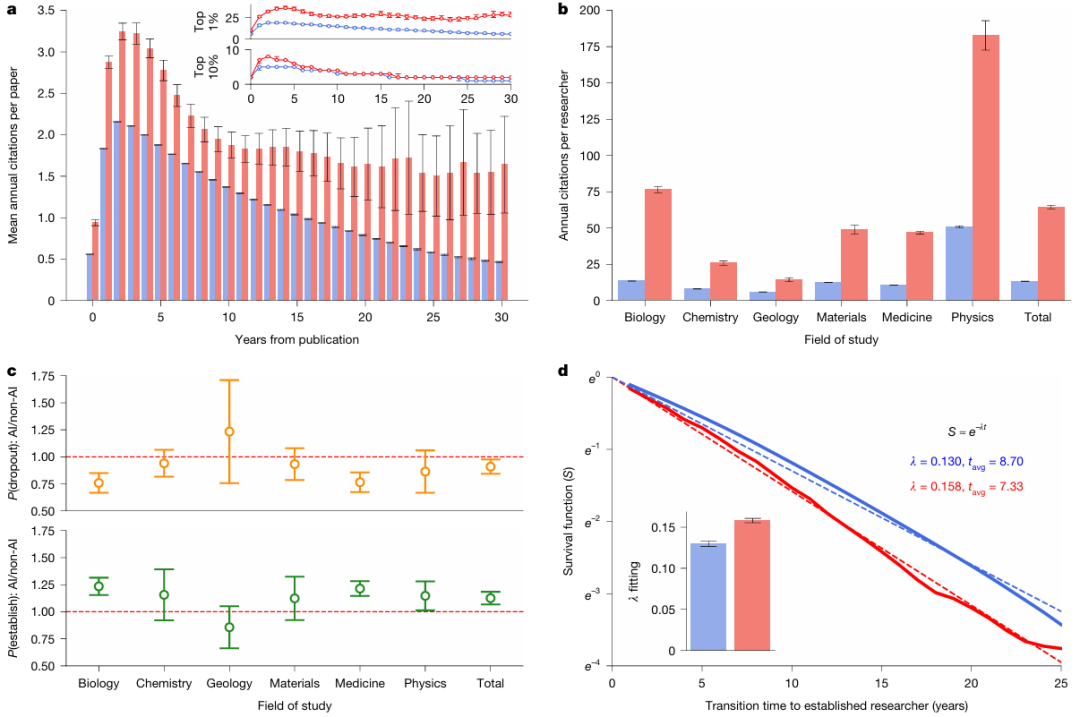
La recherche traditionnelle s'appuie souvent sur des mots-clés (tels que « réseau de neurones ») pour sélectionner les articles en IA, mais cette méthode est très sujette aux biais. Cette étude utilise un modèle BERT à deux étapes d'ajustement fin : entraîné séparément sur le titre et le résumé de l'article, il intègre ensuite ces résultats pour établir le jugement final.Cette méthode, après un examen à l'aveugle par des experts, a obtenu un score F1 de 0,875.Cela a permis de constituer une base de données solide et fiable pour l'ensemble de l'étude.
a : Un schéma du modèle de langage déployé, composé d'un tokenizer, du modèle BERT de base et de couches linéaires.
b : Schéma du processus de mise au point du modèle en deux étapes, dans lequel les chercheurs ont conçu des méthodes spécifiques pour construire des données d'échantillons positifs et négatifs à chaque étape.
Un indicateur quantitatif novateur pour « l'étendue des connaissances » :
Comment mesurer « l’étendue de l’exploration » dans un domaine ? L’équipe de recherche a utilisé SPECTER 2.0, un modèle d’intégration spécifiquement conçu pour la littérature scientifique.Chaque article est mappé sur un espace vectoriel sémantique à 768 dimensions.L’« étendue des connaissances » d’un ensemble d’articles est définie comme le diamètre maximal qu’elle couvre dans cet espace. Cette approche, qui transforme le concept abstrait de « diversité des connaissances » en une distance géométrique précisément calculable, constitue une innovation majeure en scientométrie.
Révéler le modèle d'interaction académique de « surpopulation solitaire » :
Des recherches ont montré que les études ultérieures citant le même article en IA sont moins susceptibles de se citer entre elles (22%). Ceci révèle un paysage de la recherche scientifique « en étoile » plutôt que « en réseau » : un grand nombre d’études gravitent autour de quelques avancées majeures en IA, comparables à des planètes, mais manquent de liens transversaux. Cet état de « foules isolées » est un signe inquiétant de la répression de la créativité scientifique.
Comment utiliser l'espace vectoriel pour « mesurer » l'étendue des sciences ?
Si l'article tout entier est un grand édifice, alors sa technologie de base est sans aucun doute le modèle d'intégration SPECTER 2.0 et l'étendue des connaissances.
Imaginez l'ensemble du savoir scientifique comme un vaste univers. Le rôle de SPECTER 2.0 est d'établir un système de coordonnées précis pour cet univers. En analysant des dizaines de millions d'articles et leurs relations de citation, il transforme chaque article en un point de coordonnées à 768 dimensions (c'est-à-dire un vecteur). Dans cet espace multidimensionnel, les articles traitant de sujets similaires ont des points de coordonnées proches les uns des autres ; ceux traitant de sujets très différents ont des points de coordonnées très éloignés.
Avec ce système de coordonnées, comment mesurer le « territoire » d'un champ de recherche ? L'approche de l'équipe de recherche est très ingénieuse :
échantillonnage: Un lot d'articles est sélectionné au hasard dans un domaine spécifique (tel que la recherche biologique améliorée par l'IA).
position: À l'aide de SPECTER 2.0, tous ces articles ont été projetés dans un univers de connaissances à 768 dimensions, ce qui a donné lieu à un ensemble de points de coordonnées.
Trouvez le centre : Calculez le centre géométrique (centroïde) de tous ces points.
Mesurez le diamètre : La distance par rapport au point le plus éloigné du centre est définie comme « l'étendue des connaissances » de cet ensemble d'articles.
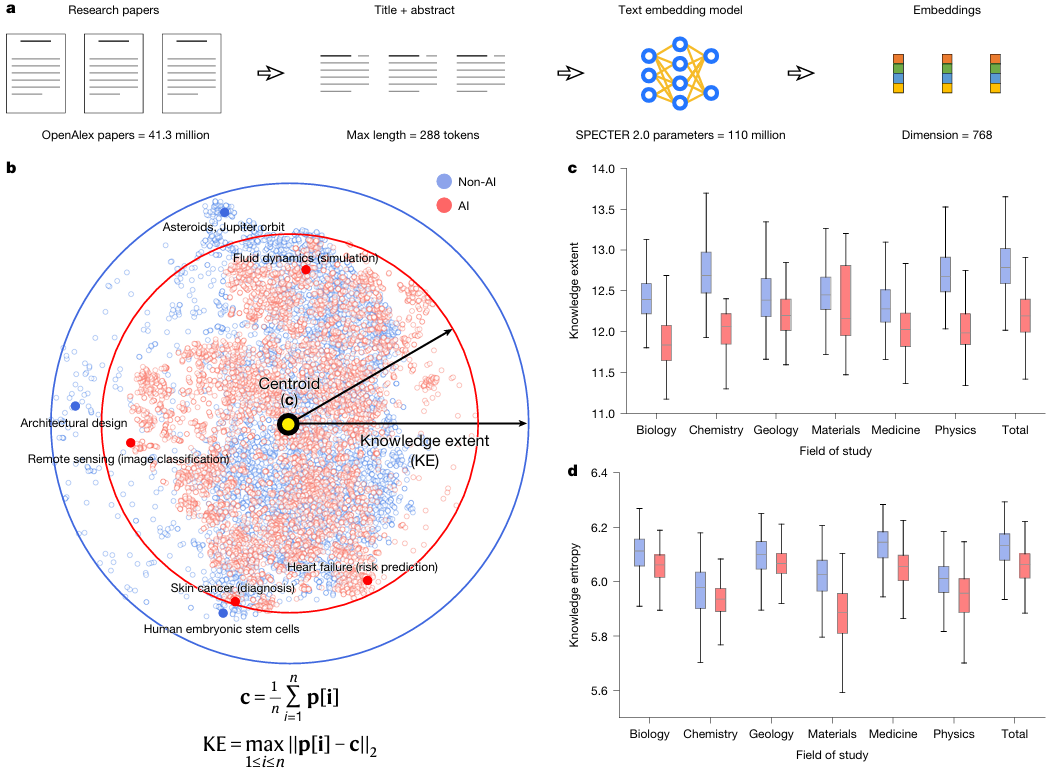
a: Les chercheurs ont utilisé un modèle d'intégration de texte pré-entraîné pour intégrer des articles de recherche dans un espace vectoriel de 768 dimensions et mesurer l'étendue des connaissances dans les articles au sein de cet espace.
b : Afin de faciliter la visualisation, les chercheurs ont utilisé l’algorithme t-SNE (t-distributed random neighborhood embedding) pour compresser les représentations vectorielles de haute dimension de 10 000 articles sélectionnés aléatoirement (dont la moitié portaient sur l’IA) dans un espace bidimensionnel. Comme l’indiquent les flèches pleines et les contours circulaires, les articles sur l’IA (dont l’étendue des connaissances a été calculée dans l’espace d’origine sans réduction de dimensionnalité) présentent une étendue des connaissances plus faible pour l’ensemble des sciences naturelles. De plus, ces articles montrent un degré de regroupement plus élevé dans l’espace des connaissances, ce qui indique une attention plus ciblée sur des problématiques spécifiques.
c : Comparaison de l’étendue des connaissances entre les articles portant sur l’IA et ceux n’en portant pas, toutes disciplines confondues (p < 0,001, n = 1 000 échantillons par discipline). Les résultats montrent que la recherche en IA se concentre sur un espace de connaissances plus restreint.
d : Comparaison de l’entropie des connaissances entre les articles portant sur l’IA et ceux n’en portant pas, toutes disciplines confondues (p < 0,001, n = 1 000 échantillons par discipline). La recherche en IA présente une entropie des connaissances plus faible. Dans les figures c et d, les diagrammes en boîte sont centrés sur la médiane. Leurs limites supérieure et inférieure correspondent respectivement aux premier et troisième quartiles (Q1 et Q3), et les moustaches représentent 1,5 fois l’écart interquartile. Tous les tests statistiques ont été réalisés à l’aide du test de la médiane.
Grâce à cette méthode, l'équipe de recherche a pu comparer équitablement l'étendue du « territoire » de la recherche en IA et celle de la recherche hors IA. Les résultats montrent clairement que l'« étendue des connaissances » médiane de la recherche en IA est inférieure de 4,631 TP3T à celle de la recherche hors IA. Cela signifie que, sous l'impulsion de l'IA, les scientifiques convergent unanimement vers un domaine de connaissances plus restreint et plus concentré.
De plus, l'étude a analysé la distribution des citations et a constaté que la recherche en IA présente un « effet Matthieu » plus marqué :Les 22,21 meilleurs articles TP3T sur l'IA ont reçu 801 TP3T de citations, et leur inégalité de citation (coefficient de Gini 0,754) était significativement plus élevée que celle de la recherche non-IA (0,690).
Conclusion
En résumé,Cette solution technique répond non seulement à la question de savoir si « la science s'est rétrécie », mais elle indique aussi plus précisément aux chercheurs « dans quelle mesure elle s'est rétrécie », « dans quelle dimension elle s'est rétrécie » et « quel type de structure s'est formée après ce rétrécissement ».Il ne s'agit plus d'une vague préoccupation, mais d'une réalité qui peut être précisément décrite par des données.
L'intérêt de cette étude ne réside pas dans la réfutation de l'IA, mais dans la mise en lumière, avec la plus grande rigueur, des coûts cachés que les chercheurs peuvent encourir en adoptant l'IA. Elle rappelle aux chercheurs que la véritable intelligence scientifique ne doit pas se limiter à un simple « outil » d'amélioration de l'efficacité, mais bien à un véritable « partenaire » pour repousser les limites de la cognition humaine.








