Command Palette
Search for a command to run...
Sélectionné Pour l'ICML 2025 ! La Harvard Medical School Et d'autres Universités Ont Lancé Le Premier Modèle De Carte Mentale Clinique Au Monde Dans Le Domaine De l'EIES, Avec Une Amélioration Des Performances De 151 TP3T Dans Les Tâches De Prédiction Des Résultats neurocognitifs.

Alors que la technologie de l’intelligence artificielle progresse à pas de géant, les modèles vision-langage à grande échelle (LVLM) remodèlent les limites cognitives de multiples domaines à un rythme étonnant.Dans le domaine de l'analyse d'images et de vidéos naturelles,S'appuyant sur une architecture de réseau neuronal avancée, des ensembles de données étiquetés massifs et un support informatique puissant, ce type de modèle peut effectuer avec précision des tâches de haut niveau telles que la reconnaissance d'objets et l'analyse de scènes.Dans le domaine du traitement du langage naturel,En s'appuyant sur des corpus textuels de niveau TB, LVLMs a atteint des performances de niveau professionnel dans des tâches telles que la traduction automatique, la synthèse de textes et l'analyse des sentiments. Les résumés académiques qu'il génère peuvent même extraire avec précision les conclusions essentielles de la littérature médicale.
Cependant, avec l'essor de la technologie dans le domaine médical, la mise en œuvre des LVLM se heurte à une forte résistance. Bien que la demande de diagnostics auxiliaires intelligents en situation clinique soit extrêmement urgente, l'application médicale de ces modèles en est encore à ses débuts.Le principal goulot d’étranglement provient des propriétés uniques des données médicales :En raison de multiples contraintes telles que les réglementations sur la protection de la vie privée des patients, les effets d’îlot de données médicales et les mécanismes d’examen éthique, l’échelle des ensembles de données médicales de haute qualité accessibles au public ne représente qu’un dix-millième de celle du domaine général.La plupart des ensembles de données médicales existants utilisent des architectures de base de réponses visuelles aux questions, en se concentrant sur des tâches primaires de reconnaissance de formes telles que « de quelle structure anatomique s'agit-il ? »——Par exemple, un ensemble de données publiques contient 200 000 annotations radiographiques, mais le contenu des annotations de 90% reste au niveau de la localisation de l’organe et ne peut pas aborder les besoins cliniques fondamentaux tels que la classification de la gravité des lésions et l’évaluation du risque pronostique.
Cette inadéquation entre l’offre de données et la demande réelle fait que le modèle est capable d’identifier des signaux anormaux dans les noyaux gris centraux lorsqu’il est confronté à des images IRM d’encéphalopathie hypoxique-ischémique néonatale (EHI), mais est incapable d’intégrer des informations multidimensionnelles telles que l’âge gestationnel et les antécédents médicaux périnatals pour prédire le pronostic neurodéveloppemental.
Afin de surmonter ce dilemme, une équipe interdisciplinaire du Boston Children's Hospital, de la Harvard Medical School, de l'Université de New York et du MIT-IBM Watson Laboratory a collecté dix années d'images IRM et d'interprétations d'experts de 133 personnes atteintes d'encéphalopathie hypoxique-ischémique (EHI).A construit un ensemble de données de référence de raisonnement médical de niveau professionnel,Vise à évaluer avec précision les performances de raisonnement des LVLM dans les domaines professionnels médicaux.L’équipe de recherche a également proposé un modèle de carte mentale clinique (CGoT).La capacité de simuler le processus de diagnostic grâce à des invites de cartographie mentale guidées par les connaissances cliniques permet l'intégration de connaissances cliniques spécifiques au domaine sous forme d'entrées visuelles et textuelles, améliorant considérablement le pouvoir prédictif des LVLM.
Les résultats de recherche pertinents, intitulés « Connaissances visuelles et de domaine pour le raisonnement médical graphique de pensée de niveau professionnel », ont été sélectionnés avec succès pour l'ICML 2025.
Points saillants de la recherche :
* Créer un nouveau test de référence de raisonnement HIE qui combine pour la première fois la perception visuelle clinique avec les connaissances médicales professionnelles, simule le processus de prise de décision clinique et évalue avec précision les performances professionnelles des LVLM en matière de raisonnement médical.
* Comparer de manière exhaustive les LVLM généraux et médicaux avancés pour révéler leurs limites en termes de connaissances du domaine médical et fournir des orientations pour l'amélioration du modèle.
* A proposé le modèle CGoT, qui intègre l'expertise médicale aux LVLM, imite le processus de prise de décision clinique et améliore efficacement le soutien à la décision médicale.

Adresse du document :
https://openreview.net/forum?id=tnyxtaSve5
Autres articles sur les frontières de l'IA :
https://go.hyper.ai/owxf6
Le projet open source « awesome-ai4s » rassemble plus de 100 interprétations d'articles AI4S et fournit des ensembles de données et des outils massifs :
https://github.com/hyperai/awesome-ai4s
Raisonnement HIE : Construction d'ensembles de données multimodaux et création d'un système de tâches de raisonnement professionnel
En termes de construction de données, cette étude se concentre sur l’encéphalopathie hypoxique-ischémique (EHI), une maladie néonatale grave.Sur une période de 10 ans, des images IRM de haute qualité de 133 enfants HIE âgés de 0 à 14 jours ont été collectées.Obtenez simultanément des rapports d’interprétation cliniquement validés par des experts multidisciplinaires (dont un neuroradiologue senior avec 30 ans d’expérience) pour former un ensemble de données de base pour le suivi longitudinal.
Comme le montre la figure ci-dessous, les chercheurs ont défini six tâches pour que les LVLM puissent effectuer un raisonnement clinique professionnel :
* Tâche 1 : Classification des lésions.La tâche quantifie les lésions cérébrales en estimant le pourcentage du volume cérébral affecté par les lésions HIE et en évaluant la gravité des lésions.
* Tâche 2 : Anatomie de la lésion.Cette tâche permet d’identifier la zone spécifique du cerveau affectée par la lésion.
* Mission 3 : Lésion dans des endroits rares.Cette tâche identifie les lésions causées par l’EHI et classe les zones affectées comme courantes ou peu courantes, aidant à déterminer si le patient nécessite une attention supplémentaire.
* Tâche 4 : Score de blessure IRM.La tâche génère un score global de blessure à partir de l’IRM, fournissant une mesure standardisée de la gravité de la blessure pour guider le traitement et prédire le résultat.
* Tâche 5 : Résultat neurocognitif sur 2 ans.La tâche prédit les résultats neurocognitifs des patients 2 ans plus tard, aidant les cliniciens à anticiper les effets à long terme et à planifier des interventions appropriées.
* Tâche 6 : Résumé de l’interprétation de l’IRM.La tâche est basée sur un modèle de résumé d’IRM néonatale recommandé par un radiologue et est capable de générer une interprétation complète de l’IRM pour le patient.
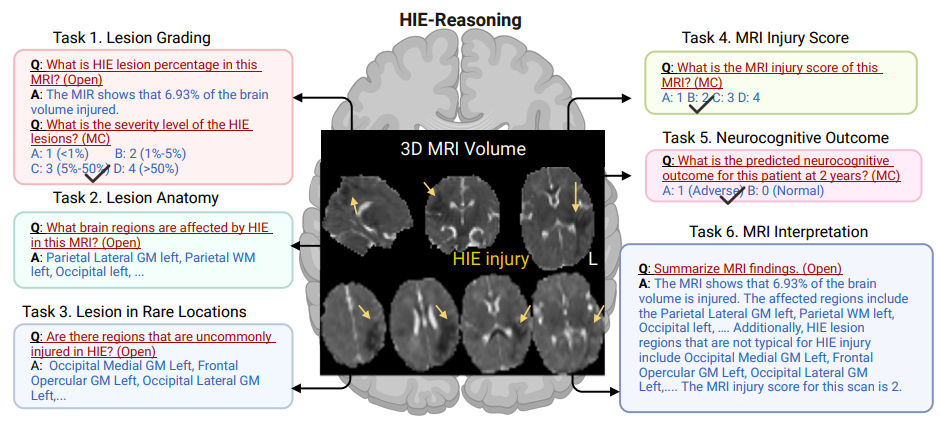
final,Les chercheurs ont construit le premier ensemble de données HIE public au monde, HIE-Reasoning, qui contient 749 paires de questions-réponses et 133 résumés d'interprétation d'IRM.Contrairement aux ensembles de données médicales traditionnels tels que VQAmed et OmiMed-VQA, qui se concentrent sur des questions fondamentales telles que la reconnaissance des méthodes d'imagerie et le positionnement des organes,Cet ensemble de données transforme pour la première fois le processus de raisonnement approfondi des experts cliniques en un système d’évaluation calculable.Son innovation en matière de structure de données adopte une architecture à trois niveaux : images originales et fichiers de tâches au niveau du patient, modèles de raisonnement méta-connaissances inter-cas et cartes de probabilité de lésions individuelles. Non seulement elle préserve l'intégrité des données médicales, mais elle fournit également au modèle des informations explicites, notamment sur les mécanismes pathologiques.
Bien que la taille de l'échantillon n'était que de 133 cas, grâce à une collecte rétrospective multicentrique sur 17 ans (2001-2018), combinée à la faible incidence d'EHI dans les hôpitaux tertiaires de 1 à 5 ‰,Cet ensemble de données est devenu la première référence spécifique à l'HIE intégrant des informations multimodales d'imagerie, cliniques et pronostiques.Sa précision d'étiquetage et sa profondeur clinique sont suffisantes pour compenser les limitations d'échelle, fournissant une référence indispensable aux LVLM pour briser le goulot d'étranglement de « l'identification de base » et entrer dans les eaux profondes du diagnostic et de la prise de décision en matière de traitement.
Modèle CGoT : piloté par une carte de pensée clinique, créant un nouveau cadre pour un raisonnement médical hiérarchique interprétable
Afin de surmonter le goulot d'étranglement de l'interprétabilité des modèles visuels et linguistiques à grande échelle (LVLM) traditionnels dans le raisonnement médical (comme illustré dans la figure A ci-dessous), l'équipe de recherche a proposé le modèle de cartographie des objectifs cliniques (CGoT), illustré dans la figure BC ci-dessous. En intégrant les connaissances cliniques pour guider le modèle linguistique et simuler le processus diagnostique du médecin, la fiabilité de la prédiction des résultats neurocognitifs peut être considérablement améliorée.Ce modèle adopte de manière innovante une « carte mentale de raisonnement » structurée, transformant les étapes de diagnostic des experts médicaux en un pipeline de raisonnement hiérarchique pour résoudre des tâches complexes en accumulant progressivement des connaissances.
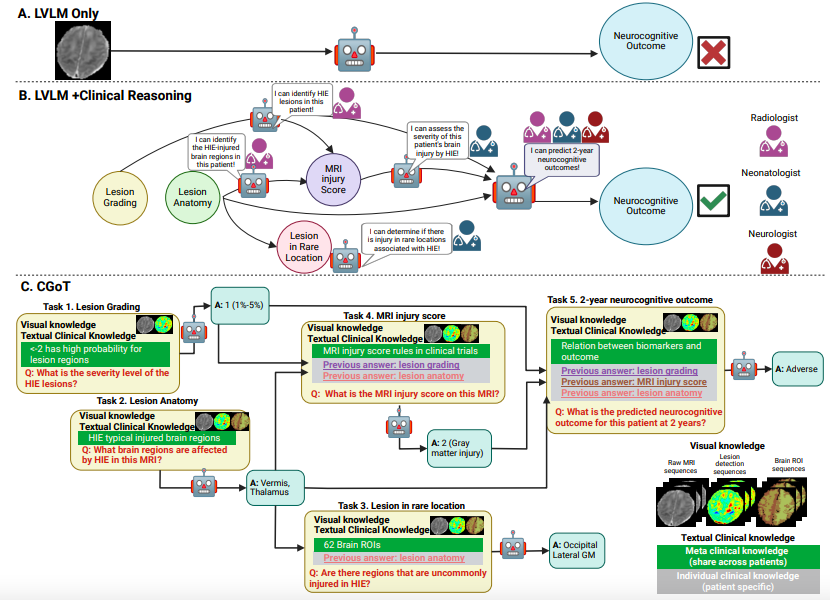
La partie « connaissances textuelles » est divisée en connaissances métacliniques (comprenant le contexte médical général, comme les cartes anatomiques cérébrales, les schémas de distribution des lésions, les associations pronostiques des biomarqueurs IRM, etc.) et en connaissances cliniques individuelles (indices diagnostiques spécifiques au patient, générés dynamiquement à partir des résultats des tâches précédentes). Ces deux types de connaissances sont structurés et saisis de manière intuitive afin de guider LVLM dans ses déductions étape par étape, selon la chaîne logique « directives cliniques - caractéristiques d'imagerie - antécédents médicaux individuels ».
L'ensemble du cadre transforme la logique diagnostique médicale implicite en données d'entrée calculables pour un modèle, en intégrant des invites structurées de graphiques cliniques à des connaissances intermodales. Cela permet non seulement de conserver les capacités de traitement intermodal des LVLM, mais aussi d'éviter le caractère aléatoire du raisonnement en ancrant les connaissances cliniques.
L'évaluation des performances du raisonnement clinique du CGoT permet des améliorations révolutionnaires dans les tâches clés
Pour vérifier l’efficacité du benchmark HIE-Reasoning et du modèle CGoT, l’équipe de recherche a conçu un système expérimental multidimensionnel.
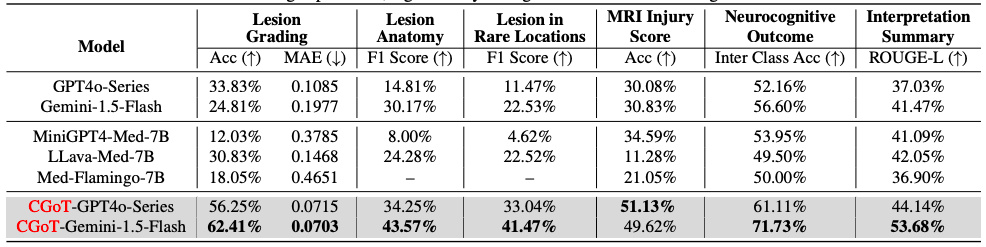
d'abord,Les chercheurs ont mené des évaluations à zéro coup sur six modèles de langage visuel à grande échelle.Trois types de LVLM généraux (Gemini1.5-Flash, GPT4o-Mini, GPT4o) et trois types de LVLM médicaux (MiniGPT4-Med, LLava-Med, Med-Flamingo) ont été sélectionnés comme modèles de référence. Six tâches cliniques majeures, dont la classification des lésions, la localisation anatomique et la prédiction du pronostic, ont été évaluées à l'aide d'indicateurs spécifiques tels que la précision, l'EMA, le score F1 et le score ROUGE-L. La prédiction des résultats neurocognitifs à deux ans a utilisé la précision moyenne entre les catégories afin de compenser le biais de distribution des étiquettes.
Les résultats expérimentaux révèlent les limites importantes des LVLM traditionnels : lorsque les coupes IRM et les descriptions de tâches sont saisies directement, tous les modèles de base affichent de faibles performances dans les tâches de raisonnement médical professionnel. Certains modèles présentent des hallucinations de réponse ou refusent de répondre par manque de connaissances cliniques. Par exemple, Med-Flamingo génère un contenu répétitif et dénué de sens dans les tâches de positionnement anatomique, et la série GPT4o ne peut pas gérer les problèmes de forte incertitude en raison de sa stratégie d'alignement.
En revanche, comme le montre le tableau suivant,Le modèle CGoT réalise des améliorations révolutionnaires dans des tâches clés en intégrant des cartes mentales cliniques et des connaissances intermodales——En particulier dans le besoin clinique principal de prédiction du pronostic à deux ans, ses performances sont améliorées de plus de 15% par rapport au modèle de base, et la précision et la cohérence des tâches telles que la classification des lésions et la notation des blessures sont également significativement meilleures que celles du groupe témoin.
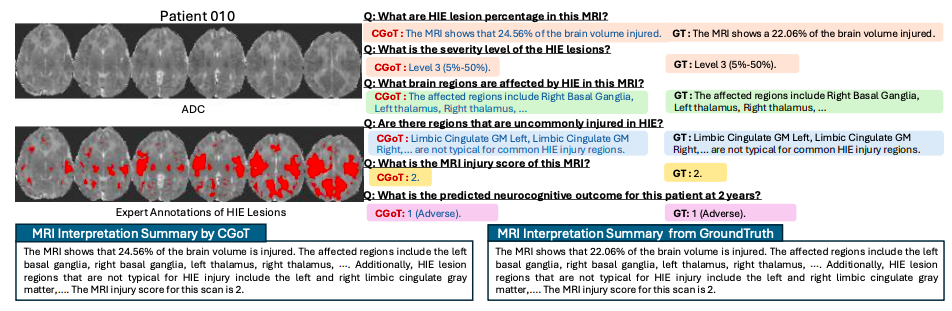
Parallèlement, des expériences de robustesse montrent que même lorsque des perturbations de ±1 niveau de score sont introduites dans les résultats des tâches intermédiaires des tests 10%-30%, les performances du modèle ne déclinent que progressivement, démontrant ainsi sa capacité à s'adapter au bruit de données courant en pratique clinique. L'ensemble de ces résultats indique queEn simulant le processus de raisonnement hiérarchique du diagnostic clinique, CGoT non seulement brise les angles morts des connaissances des modèles traditionnels, mais construit également un système d'aide à la décision fiable et proche des scénarios réels de diagnostic et de traitement.
La double traction des LVLM médicaux : pratiques et tendances innovantes dans le monde universitaire et commercial
À l’échelle mondiale, la recherche et l’application des grands modèles vision-langage (LVLM) dans le domaine médical connaissent un changement de paradigme, et les pratiques innovantes dans le monde universitaire et le monde des affaires conduisent conjointement à des percées dans ce domaine.
Au niveau de la recherche universitaire, le laboratoire d'intelligence artificielle de Shanghai, en collaboration avec l'Université de Washington, l'Université Monash, l'Université normale de Chine orientale et d'autres institutions de recherche, ont publié conjointement le test de référence GMAI-MMBench.Il intègre 284 ensembles de données de tâches cliniques, couvrant 38 modalités d'imagerie médicale et 18 besoins cliniques fondamentaux (tels que le diagnostic tumoral, l'analyse de neuroimagerie, etc.).L'indice de référence utilise un système de classification par arbre de vocabulaire pour classer avec précision les cas par département, modalité et type de tâche, fournissant un cadre standardisé pour évaluer la capacité de raisonnement clinique des LVLM.
* Cliquez ici pour consulter le rapport complet : Contenant 284 ensembles de données, couvrant 18 tâches cliniques, Shanghai AI Lab et d'autres ont publié le benchmark médical multimodal GMAI-MMBench
De plus, Med-R1, développé conjointement par l'Université Emory, l'Université de Californie du Sud, l'Université de Tokyo et l'Université Johns Hopkins, introduit de manière innovante l'optimisation des politiques relatives au groupe (GRPO) pour répondre aux limites des méthodes traditionnelles de réglage fin supervisé (SFT).Mises à jour de politiques stables grâce à des récompenses de règles et des comparaisons de groupes sans modèles de valeur complexes.Les LVLM open source tels que MedDr lancé par l'Université des sciences et technologies de Hong Kong ont atteint des performances proches des modèles commerciaux dans des tâches spécifiques (telles que le classement des lésions), démontrant le potentiel de l'écosystème open source dans le domaine de l'IA médicale.
Le monde des affaires accélère la transformation clinique des LVLM en s'appuyant sur la technologie. Par exemple, la plateforme cloud médicale Microsoft Azure a permis une intégration poussée de l'analyse d'images médicales, de l'automatisation des dossiers médicaux électroniques et d'autres fonctions, en intégrant des outils d'IA et des données cliniques. Le système de radiologie intelligent qu'elle a développé en collaboration avec de nombreux hôpitaux estCapacité à identifier rapidement les zones anormales dans les images IRM grâce aux LVLM et à générer des rapports structurés.Aider les médecins à accomplir les tâches de classification des lésions et de positionnement anatomique.
Google a lancé le modèle médical open source MedGemma, basé sur l'architecture Gemma3 et spécialement conçu pour le secteur médical et de la santé. Il vise à améliorer les applications médicales et de santé, ainsi qu'à optimiser l'efficacité des diagnostics et des traitements médicaux en combinant harmonieusement l'analyse d'images médicales et de données textuelles.
* Cliquez ici pour un rapport détaillé : Google lance MedGemma, basé sur Gemma 3, spécialisé dans la compréhension de textes et d'images médicaux
Ces pratiques révèlent ensemble deux tendances majeures dans le développement des LVLM médicaux :Premièrement, l’intégration profonde des connaissances cliniques et de l’architecture du modèle.Par exemple, le système de tâches construit grâce à l’annotation d’experts dans le benchmark HIE-Reasoning décrit dans cet article, et la carte de pensée clinique introduite par le modèle CGoT ;Le deuxième est l’innovation dans la collaboration interdisciplinaire et la gouvernance des données.Par exemple, GMAI-MMBench intègre des ensembles de données mondiaux grâce à des formats d'annotation unifiés et à des processus de conformité éthique, fournissant ainsi un modèle pour pallier la pénurie de données médicales. À l'avenir, grâce à l'application croissante de technologies telles que l'apprentissage fédéré et la génération de données synthétiques, le monde universitaire et le monde des affaires devraient réaliser des avancées majeures dans des scénarios cliniques plus complexes (tels que la prédiction pronostique multimodale et la navigation chirurgicale en temps réel), favorisant ainsi la transformation de l'IA, passant d'un outil auxiliaire à un partenaire décisionnel intelligent.
Articles de référence :
1.https://blog.csdn.net/Python_cocola/article/details/146590017
2.https://mp.weixin.qq.com/s/0SGHeV8OcXu8kFk68f-7Ww








