Command Palette
Search for a command to run...
SEER n'est Que Le Début ? Le NIH Américain a Publié Un Document Interdisant Aux Utilisateurs Chinois d'accéder Aux Données Biomédicales De Base, Et Des Bases De Données Nationales Sont En place.

Le 5 avril, la nouvelle selon laquelle « la base de données SEER est interdite aux utilisateurs chinois » s'est répandue comme une traînée de poudre dans le milieu universitaire national.
Un courriel de réponse officiel reçu par un doctorant de l'Université de Heidelberg a été repris par de nombreux médias, qui indiquaient clairement que « à compter du 4 avril 2025, les National Institutes of Health interdiront aux chercheurs et aux institutions de certains pays d'accéder à tout projet en cours impliquant le CADRS des National Institutes of Health et les données connexes, et mettront fin à ces projets.Ces pays spécifiques comprennent la Chine (y compris Hong Kong et Macao), la Russie, l'Iran, la Corée du Nord, Cuba et le Venezuela.
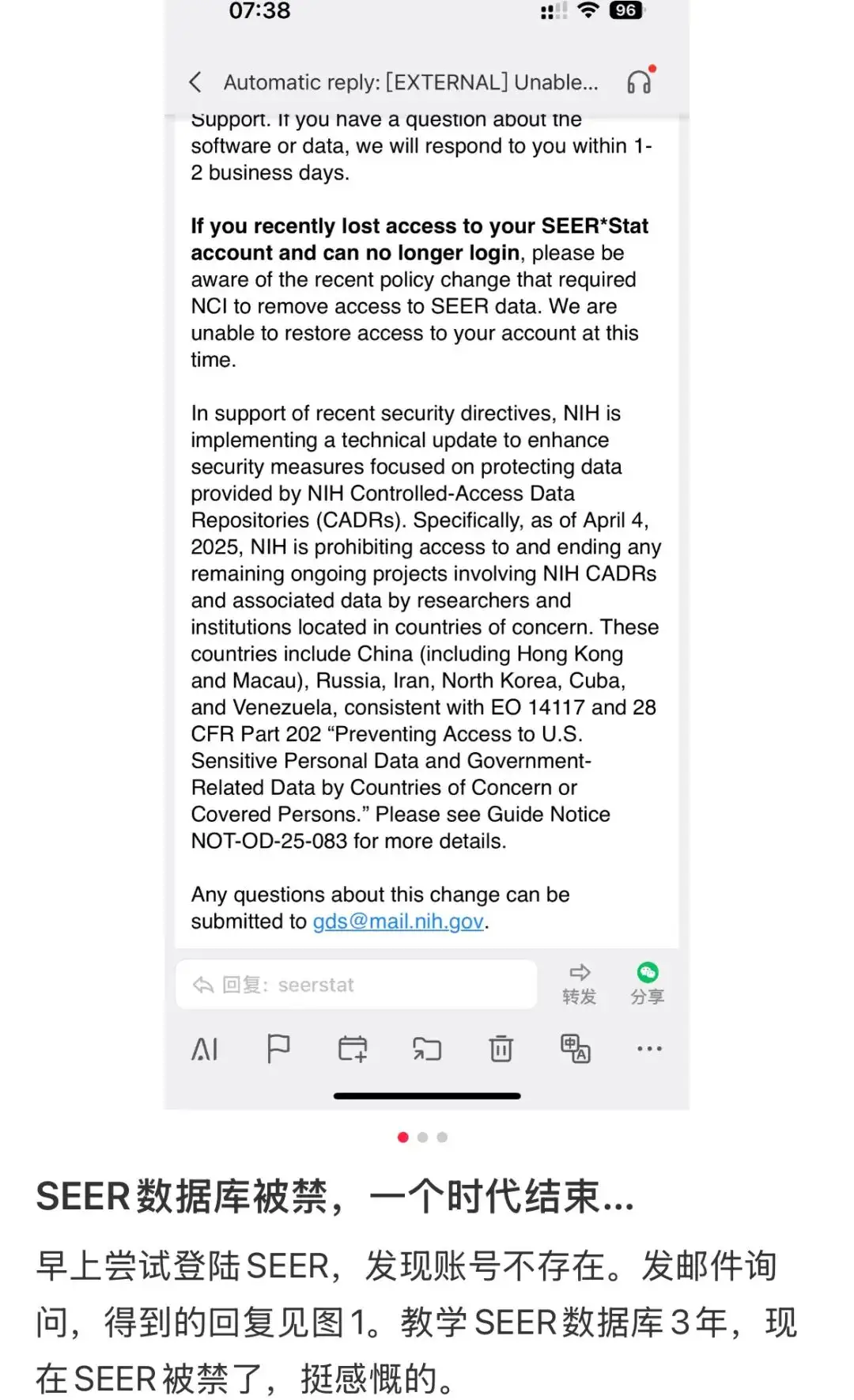
En fait, les Instituts nationaux de la santé (NIH) des États-Unis ont publié un avis le 2 avril, heure locale.Il a été annoncé qu'à partir du 4 avril, heure locale, les institutions situées dans les pays concernés ne seront plus autorisées à accéder à la base de données à accès contrôlé du NIH et aux données connexes.
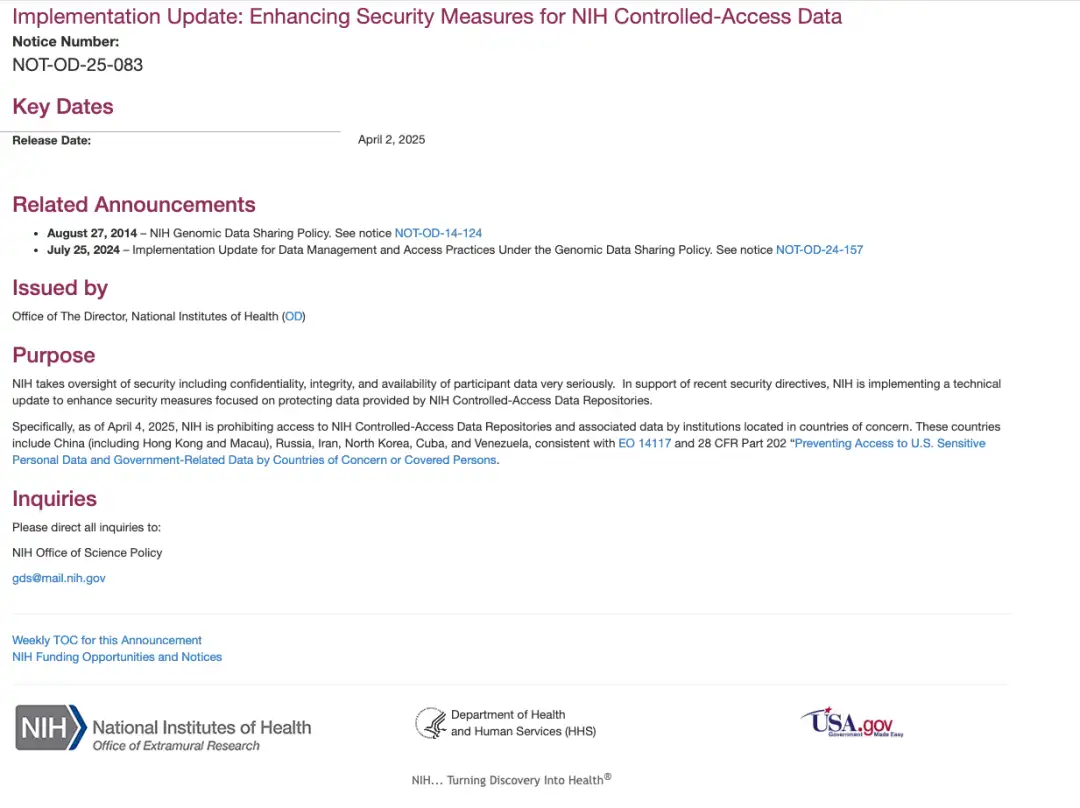
Le décret exécutif n° 14117 mentionné dans l'avis a été publié en février 2024. Le gouvernement américain a lancé un « décret exécutif visant à empêcher certains pays d'accéder à de grandes quantités de données personnelles sensibles des citoyens américains et de données relatives au gouvernement américain ». Comme son nom l'indique, il interdit à six « pays préoccupants », tels que la Chine, la Russie et l'Iran, d'accéder à « de grandes quantités de données personnelles sensibles et de données liées au gouvernement américain » des citoyens américains.

Parmi toutes les « données sensibles », les données bioinformatiques sont les plus touchées.

Une guerre froide scientifique pourrait commencer
Un an après la publication du décret, celui-ci a finalement touché le domaine universitaire qui prône l’ouverture et l’absence de frontières. En tant que premier coup de feu tiré par le NIH, l’influence du SEER est évidente.
SEER est un système statistique de données sur le cancer établi et maintenu par le National Cancer Institute (NCI) des États-Unis.Depuis sa mise en service en 1973, elle est devenue l'une des bases de données épidémiologiques sur le cancer les plus fiables et les plus utilisées au monde, couvrant environ 481 TP3T de la population américaine. Les données couvrent des informations de base telles que l'âge, le sexe, le moment du diagnostic, les informations de diagnostic telles que le type de cancer, la classification et la stadification pathologiques, les informations de traitement telles que la chirurgie, la radiothérapie/chimiothérapie et les informations de suivi telles que la durée de survie et l'état de survie. Il ne fait aucun doute que cette base de données présente une valeur de recherche extrêmement élevée dans les domaines de l’épidémiologie tumorale, de la santé publique et des modèles pronostiques.
Certes, l’interdiction de la base de données SEER est déjà le dernier mot, mais il existe encore de nombreuses bases de données bien connues qui sont en danger.
En tant que principal établissement de recherche médicale aux États-Unis, le NIH compte 27 instituts et centres axés sur différents domaines de maladies.Parmi eux, le NCI, qui se concentre sur la recherche sur le cancer, gère non seulement la base de données SEER, mais également le Cancer Genome Atlas TCGA (The Cancer Genome Atlas) ; l'Institut national des sciences médicales générales (NIGMS), qui se concentre sur la recherche biologique fondamentale, est responsable de la maintenance de la base de données sur les protéines Protein Data Bank ; la Bibliothèque nationale de médecine des États-Unis (NLM) possède la première base de données de littérature médicale au monde, PubMed ; Le Centre national d'information sur la biotechnologie des États-Unis (NCBI) possède la base de données génotype-phénotype dbGaP...
Les bases de données de grande valeur couramment utilisées mentionnées ci-dessus appartiennent toutes au NIH. En d’autres termes, l’accès à tous ces sites est interdit aux utilisateurs chinois. Ce n’est peut-être qu’une question de temps. D’une part, les limitations des données conduiront à des résultats de recherche trop unilatéraux et, d’autre part, elles augmenteront la difficulté et le cycle de recherche. Cela a sans aucun doute sonné l’alarme au sein de la communauté de recherche scientifique nationale. Outre la promotion active de la coopération avec les équipes étrangères, il est d'une grande importance de créer une « base de données chinoise » représentative au niveau international.
Construire activement une base de données locale
Il n’est pas nécessaire d’insister sur l’importance des données pour la recherche scientifique. Qu'il s'agisse de recherche scientifique traditionnelle ou de l'IA pour la science d'aujourd'hui, il s'agit d'un support important pour les conclusions de la recherche. La collecte de données est particulièrement difficile dans les domaines biologique et médical. C'est pourquoi, dès la publication du décret exécutif n° 14117, certains chercheurs ont averti que les données à haute fréquence telles que la base de données du National Center for Biotechnology Information (NCBI) et le Cancer Genome Atlas (TCGA) risquaient d'être soumises à un accès restreint.
Un initié du secteur a déclaré lors d'une interview avec DeepTech : « Pour résoudre le problème de l'accès restreint à cette base de données, je pense que plusieurs pistes méritent d'être explorées. Premièrement, les chercheurs chinois peuvent lancer un appel collectif et organiser des consultations avec les États-Unis pour examiner des solutions envisageables, comme la modification de la base de données, qui est restreinte, pour en faire un système payant. Deuxièmement, nous pouvons coopérer avec d'autres pays tiers qui ne sont pas soumis à des restrictions. Enfin, le point le plus important est que la Chine doit rapidement créer sa propre base de données. »Une fois que nous aurons construit notre propre base de données, nous aurons davantage d’atouts lorsque nous négocierons avec les Américains. Par exemple, nous pouvons discuter de la question de savoir si les deux parties devraient ouvrir leurs bases de données l’une à l’autre et parvenir à un partage mutuel.
Bien qu'il soit encore difficile de remplacer complètement le SEER à court terme, l'accumulation de bases de données nationales sur les sciences de la vie et la médecine a permis d'obtenir certains résultats sur une longue période, et certaines bases de données peuvent servir de compléments dans une certaine mesure.
Par exemple, le National Genome Science Data Center se concentre sur la construction de systèmes de bases de données et de ressources de données autour des données génomiques des humains, des animaux, des plantes et des micro-organismes.Actuellement, nous avons créé la base de données BioProject pour le partage d'informations sur les projets de recherche biologique, le répertoire mondial de bases de données biologiques Database Commons, la base de données sur les variations du génome Genome Variation Map (GVM), la bibliothèque de littérature sur les sciences de la vie OpenLB, etc.
* Site officiel :https://ngdc.cncb.ac.cn/
Le Centre national de bioinformatique a actuellement collecté 69,9 Po de données nationales et 7,75 Po de données internationales.Sa plate-forme de base de données bioinformatique comprend des données telles que le génome, l'ARN-seq, l'épigénome, etc. Les bases de données couramment utilisées incluent la base de données d'archives publiques pour les données du génome entier multi-espèces (Genome Warehouse, GWH), la bibliothèque de ressources pour le partage d'informations sur les échantillons biologiques_Biological Sample Database (BioSample), etc.
*Site officiel :https://www.cncb.ac.cn/
La plateforme China National GeneBank DataBase (CNGBdb) construite par la Shenzhen National GeneBank (CNGB)Fournir des échantillons de ressources génétiques biologiques et des services de partage et d'application d'informations,Soutenir la soumission et l'archivage des données, l'analyse informatique, la récupération des connaissances et le développement de bases de données scientifiques.
Elle a établi conjointement le portail de données spatiotemporelles STOmicsDB (Spatial Transcript Omics DataBase) avec le Spatiotemporal Omics Consortium (STOC).Les normes et systèmes d'archivage des données du transcriptome spatial ont été établis, soutenant un certain nombre de projets scientifiques majeurs, notamment l'Atlas du transcriptome spatiotemporel du développement embryonnaire de la souris (MOSTA). Grâce à STOmicsD, les utilisateurs peuvent soumettre une variété de types de données, notamment des données de séquençage brutes, des matrices de transcriptome spatial, des fichiers d'annotation, des informations sur les images, ainsi que l'analyse des données et la visualisation des résultats d'analyse en aval.
aussi,Le portail de données de groupe cellulaire CDCP (Cell-omics Data Coordinate Platform) qu'il a construit,Il a réalisé l'intégration et la normalisation des données cytogénomiques multidimensionnelles, soutenu un certain nombre de projets scientifiques majeurs tels que le Non-Human Primate Cell Atlas (NHPCA) et fourni une plate-forme de collaboration de données cytogénomiques hautement efficace pour les chercheurs du monde entier.
Le portail de données génomiques qu’il a initié est dédié à l’intégration et au partage des données sur la biodiversité mondiale.En lançant des programmes scientifiques majeurs tels que le Earth BioGenome Project (EBP) et le MEER (Mariana Trench Environmental and Ecological Research), nous fournissons de riches ressources de données génomiques dans le domaine de la biodiversité aux chercheurs du monde entier.
Conclusion
Aujourd’hui, la science et la technologie sont devenues le principal champ de compétition entre les grandes puissances. Surtout avec le développement rapide de l’IA, le concept de recherche scientifique sans frontières ne semble plus pur. Cependant, ces dernières années, le contrôle indépendant et la substitution nationale ont permis de réaliser des progrès dans de nombreux domaines. Tout en appelant à l’ouverture et à la coopération gagnant-gagnant et en promouvant la coopération internationale, il est plus urgent de renforcer la construction de bases de données locales.
Références :








