Command Palette
Search for a command to run...
Tutoriel En Ligne丨shiji Niangniang Se Transforme Instantanément En « Fille Du Sichuan Et De Chongqing » ? Step-Audio-TTS Réalise Le Clonage De voix/synthèse musicale/synthèse Vocale Trois En Un

L’enthousiasme mondial suscité par l’open source DeepSeek est toujours là. Récemment, Step Star et Geely Auto Group ont une fois de plus fait un pas en avant et ont ouvert le code source du modèle Step-Audio-TTS-3B, ce qui a une fois de plus déclenché de nombreuses discussions dans l'industrie.
il était une fois,La diversité et la complexité des données dialectales ainsi que la forte demande de généralisation des modèles font que le modèle de clonage vocal est peu performant sur les dialectes.Le Step-Audio-TTS-3B peut interpréter de manière vivante les caractéristiques des langues locales. Il est formé sur la base du paradigme LLM-Chat, un ensemble de données synthétiques à grande échelle, et possède une connaissance approfondie de la structure du langage. Il peut saisir les changements subtils dans la langue entre les lignes. Qu'il s'agisse du dialecte passionné du Sichuan ou du cantonais à neuf et six tons, il peut capturer avec précision son rythme et son ton, montrant les fortes coutumes locales.
De plus, il s'agit également du premier modèle TTS à réaliser la génération de RAP et de bourdonnement, comblant ainsi le vide dans la synthèse vocale musicale. Dans le passé, créer un contenu rap rythmé nécessitait des chanteurs professionnels. Désormais, avec l'aide de Step-Audio-TTS-3B, les utilisateurs peuvent rapidement générer une voix RAP avec un rythme précis et un flux fluide, inspirant des possibilités infinies.
Actuellement, le « modèle de génération de parole dialectale de niveau production Step-Audio-TTS-3B » a été lancé dans la section « Tutoriel » du site Web officiel d'HyperAI.Ce tutoriel comprend trois fonctions : la synthèse vocale, la synthèse musicale et le clonage vocal. Venez en faire l'expérience par vous-même~
Adresse du tutoriel:
Essai de démonstration
1. Connectez-vous à hyper.ai, sur la page du didacticiel, sélectionnez Step-Audio-TTS-3B Production-Level Dialect Speech Generation Model, puis cliquez sur Exécuter ce didacticiel en ligne.
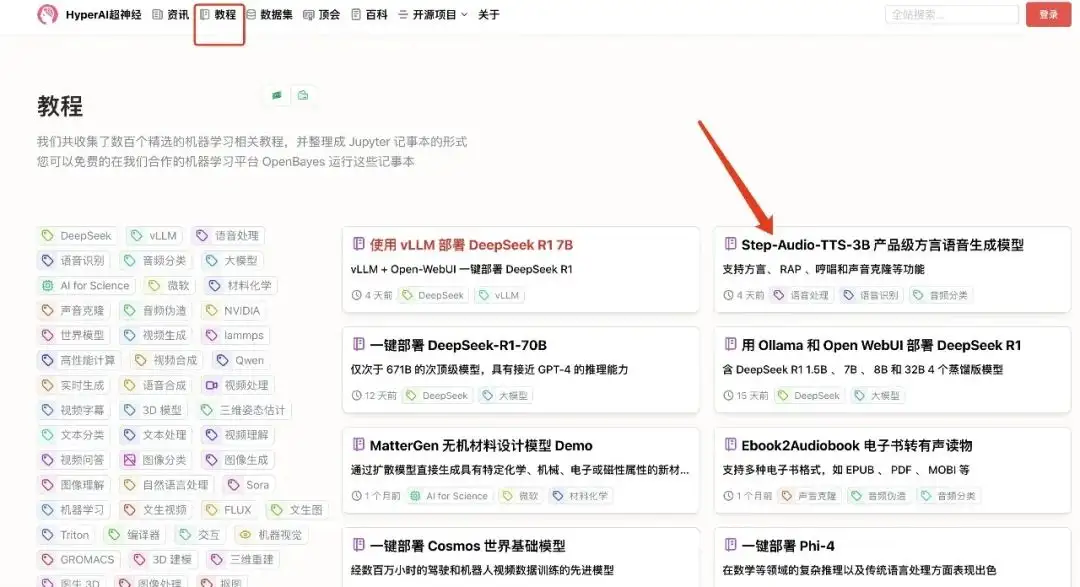
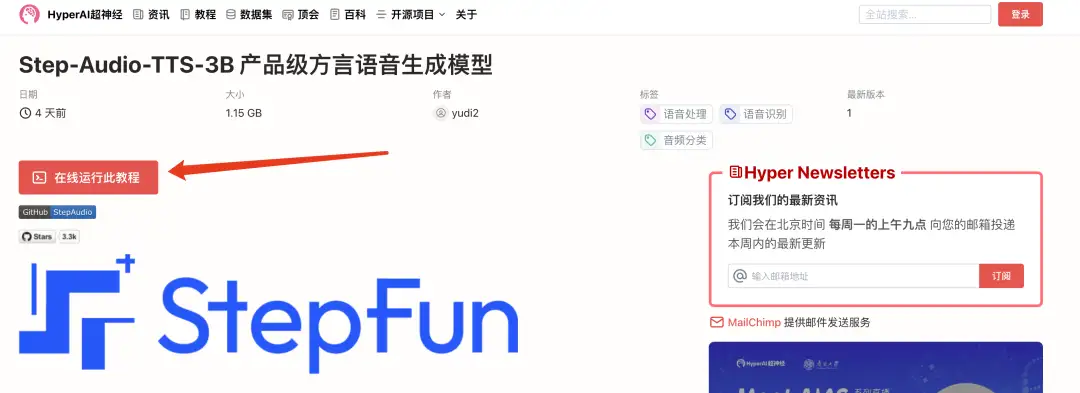
2. Une fois la page affichée, cliquez sur « Cloner » dans le coin supérieur droit pour cloner le didacticiel dans votre propre conteneur.
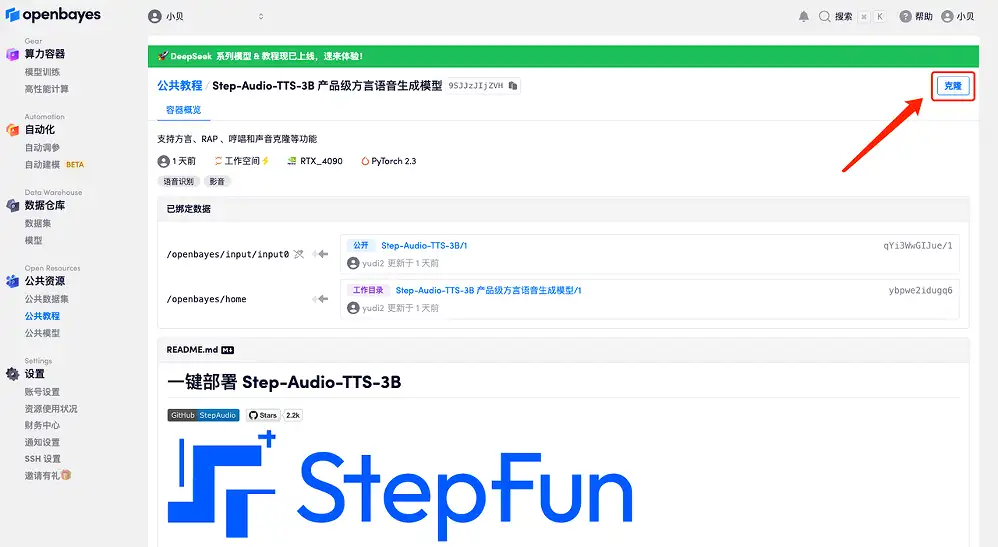
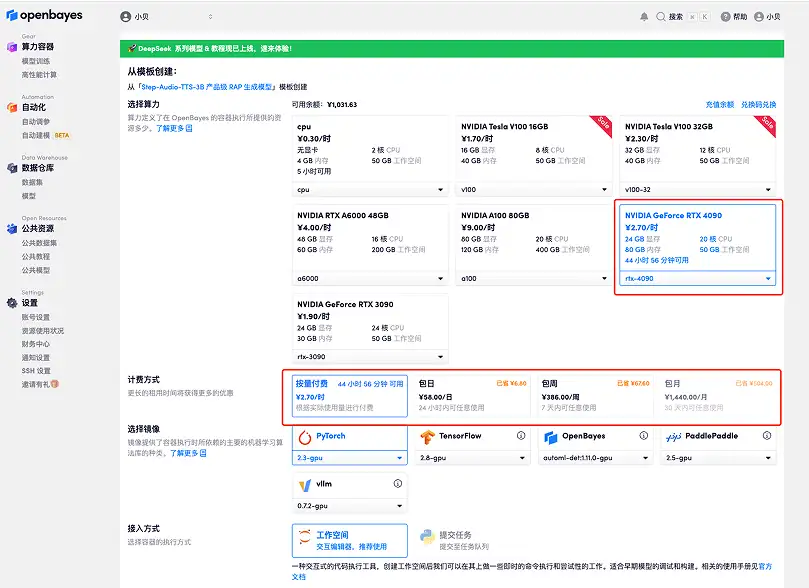
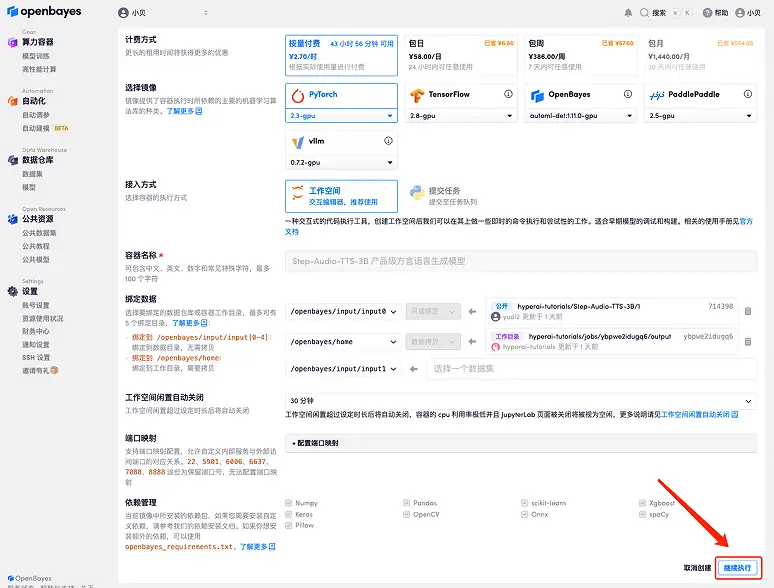
3. Sélectionnez les images « NVIDIA RTX A6000 » et « PyTorch ». La plateforme OpenBayes a lancé une nouvelle méthode de facturation. Vous pouvez choisir « Payer au fur et à mesure » ou « Forfait journalier/hebdomadaire/mensuel » selon vos besoins. Cliquez sur « Continuer ». Les nouveaux utilisateurs peuvent s'inscrire en utilisant le lien d'invitation ci-dessous pour obtenir 4 heures de RTX 4090 + 5 heures de temps CPU gratuit !
Lien d'invitation exclusif HyperAI (copier et ouvrir dans le navigateur) :
https://openbayes.com/console/signup?r=Ada0322_QZy7
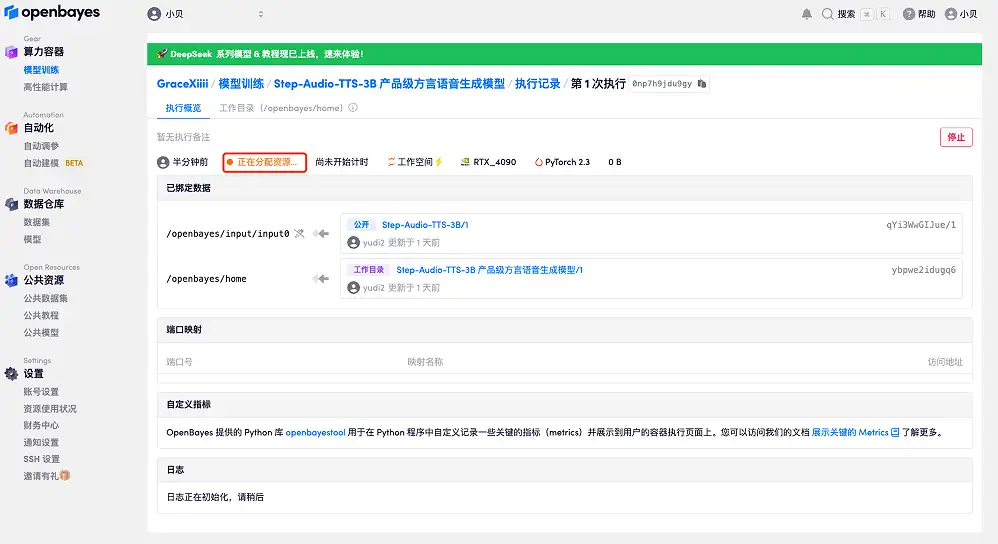
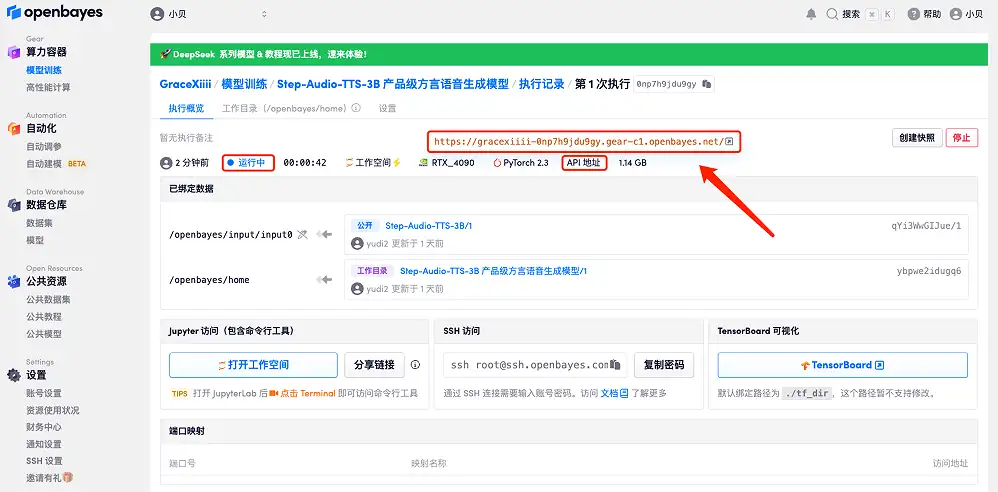
4. Attendez que les ressources soient allouées. Le premier processus de clonage prend environ 2 minutes. Lorsque le statut passe à « En cours d'exécution », cliquez sur la flèche de saut à côté de « Adresse API » pour accéder à la page de démonstration. Veuillez noter que les utilisateurs doivent effectuer l'authentification par nom réel avant d'utiliser la fonction d'accès à l'adresse API.

Affichage des effets
Ce tutoriel comprend trois fonctions : la synthèse vocale générale, la synthèse musicale et le clonage de la parole.
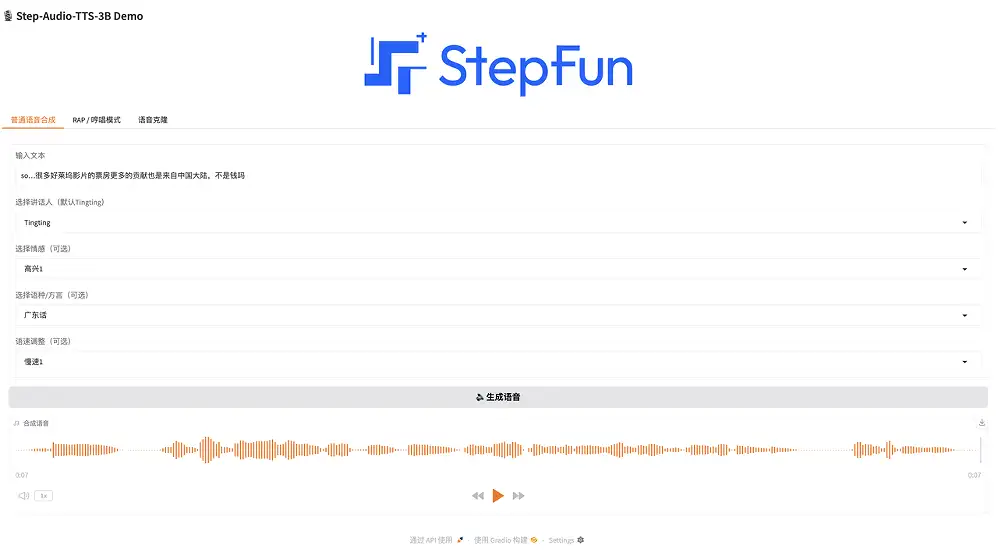
1. Synthèse vocale générale
Cette fonctionnalité prérégle le personnage vocal par défaut officiel Tingting et la voix nouvellement ajoutée Nezha, et prend en charge la génération multilingue, les émotions, les dialectes et d'autres paramètres.
Description du ton de la synthèse vocale
* Le son Tingting est généré par le fichier audio officiel de 4s
* Le son de Nezha est généré à partir du fichier audio de 14 secondes « Je suis Nezha le troisième prince, je suis décomplexé et j'aime écrire de la poésie, je marche avec mes mains dans mes poches et je peux rendre une route courbe droite »
Sur la page de démonstration, sélectionnez « Synthèse vocale normale », saisissez du texte, sélectionnez le locuteur (la valeur par défaut est Tingting), sélectionnez l'émotion (joyeux, en colère, triste et coquet), sélectionnez la langue/le dialecte (chinois, anglais, japonais, mandarin, sichuanais, cantonais et dialecte du Guangdong) et sélectionnez la vitesse de parole (rapide ou lente). Cliquez simplement sur Générer la parole.
2. Synthèse musicale
Cette fonction prérégle le caractère vocal par défaut du site Web officiel Tingting et le timbre Nezha nouvellement ajouté, et prend en charge le RAP et le fredonnement.
Description du son RAP
* Le son Tingting est généré par le fichier audio officiel 11s
* Le son de Nezha est généré par le fichier audio de 14 secondes « Le tonnerre gronde et j'ai tellement peur, il me frappe partout, je souffle dans la trompette pour changer mon destin, je ris pour traverser la calamité, tic-tac-tic-tic-tic »
Description du bourdonnement
* Le son Tingting est généré par un fichier audio de 12 secondes
* Le son de Nezha est généré par le fichier audio de 14 secondes « Je suis né sans peur, peu importe qui est mon père ou qui que ce soit, si le maître élimine le dirigeant, il ne pourra jamais me commander »
Sélectionnez « Synthèse musicale » sur la page de démonstration, saisissez le texte, sélectionnez le haut-parleur (par défaut, Tingting) et sélectionnez le mode (RAP ou Humming). Cliquez simplement sur « Générer RAP/Humming ».

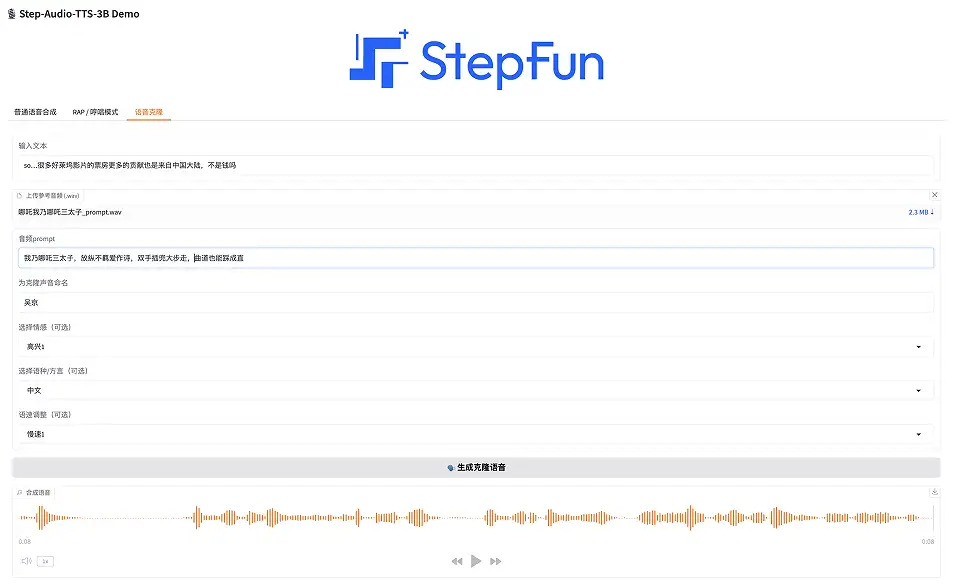
3. Clonage vocal
Cette fonction permet aux utilisateurs de télécharger des sons au timbre personnalisé et de générer une voix personnalisée.
Sélectionnez « Clonage de voix » sur la page de démonstration, saisissez du texte, téléchargez l'audio de référence (format .wav), nommez la voix clonée, sélectionnez l'émotion (joyeuse, en colère, triste et coquette), sélectionnez la langue/le dialecte (chinois, anglais, japonais, mandarin, sichuanais, cantonais et dialecte du Guangdong) et sélectionnez la vitesse de parole (rapide ou lente). Cliquez simplement sur « Générer une voix clonée ».