Command Palette
Search for a command to run...
Professeur Hong Liang De l'Université Jiao Tong De Shanghai : Si l'IA Veut Réellement Réaliser Des Percées Dans Le Domaine De l'ingénierie, Elle Doit Obtenir Des Résultats d'ingénierie Que Les Experts Humains Actuels Ne Peuvent Pas atteindre.

Récemment, l'école d'été sur l'IA pour la bio-ingénierie de l'Université Jiao Tong de Shanghai s'est terminée avec succès. Plus de 100 experts de l'industrie, représentants d'entreprises et jeunes chercheurs exceptionnels issus d'entreprises, d'instituts de recherche et d'universités se sont réunis pour s'engager dans un échange d'idées acharné autour de l'application de l'IA dans le domaine de la bio-ingénierie.
dans,Hong Liang, professeur distingué de recherche en sciences naturelles à l'École de physique et d'astronomie et à l'École de pharmacie de l'Université Jiao Tong de Shanghai, a partagé de manière simple et facile à comprendre l'application de l'IA dans la recherche scientifique, en particulier dans la conception de protéines, ainsi que ses perspectives sur le développement futur de l'IA pour la science.
Extraits de points de vue clés :
* Pour véritablement mettre en œuvre l’IA pour la science, il faut d’abord définir le problème scientifique, puis proposer une solution d’intelligence artificielle.
* L’IA peut transformer des centaines de séquences d’acides aminés tout en maintenant une bonne activité et un taux positif élevé. L’IA est déjà bien supérieure aux experts humains dans ce type de tâche de génération de séquences. * Le domaine de l’ingénierie des protéines présente les données les plus négatives. L’IA peut combiner des sites négatifs et positifs, élargissant ainsi l’espace d’imagination de l’ingénierie des protéines. Cela va au-delà du champ de conception rationnelle des ingénieurs enzymatiques professionnels. L’IA a fondamentalement remplacé l’ancienne voie du calcul physique. * Si l’intelligence artificielle veut faire une percée dans un domaine d’ingénierie, il ne s’agit pas simplement de devenir un assistant pour les scientifiques et d’effectuer des tâches de base comme la collecte de littérature, mais de faire des choses que les experts humains ne peuvent pas faire. * Au cours des trois prochaines années, dans les domaines de la conception de protéines, du développement de médicaments, du diagnostic de maladies, de la découverte de nouvelles cibles, de la conception de voies de synthèse chimique et de la conception de matériaux, l'intelligence artificielle générale dans les domaines professionnels entraînera un changement de paradigme clair, transformant le modèle de découverte scientifique qui reposait auparavant sur des essais et des erreurs sporadiques du cerveau humain en un modèle de conception standard automatisé à grande échelle d'IA.
HyperAI a compilé et résumé le merveilleux partage du professeur Hong Liang sans violer l’intention initiale. Voici une transcription des points saillants du discours.

Étudiants en arts de l'IA contre étudiants en sciences de l'IA
Le professeur Hong Liang a présenté l'application de l'IA dans la vie (IA pour la vie) et la recherche scientifique (IA pour la science) du point de vue des étudiants en arts libéraux de l'IA et des étudiants en sciences de l'IA respectivement.
Étudiants en arts libéraux en IA : assistants personnels dans la vie
En ce qui concerne l'IA pour la vie, le professeur Hong Liang estime que l'IA actuelle est devenue un assistant personnel dans la vie des gens, aidant les gens à réduire le fardeau du travail répétitif, créatif et non scientifique.Ses caractéristiques sont que l’échelle des données disponibles pour la formation est déjà très grande et que les résultats générés ne nécessitent pas une grande précision. Il dispose donc de fortes capacités de généralisation inter-domaines et peut créer de grands modèles de domaine général.
Il a ensuite utilisé des cas spécifiques tels que la génération de texte par IA, la génération d'images par IA, la génération de vidéos par IA, etc., combinés aux grands modèles actuellement populaires, pour décrire de manière vivante l'application de l'IA dans la vie.
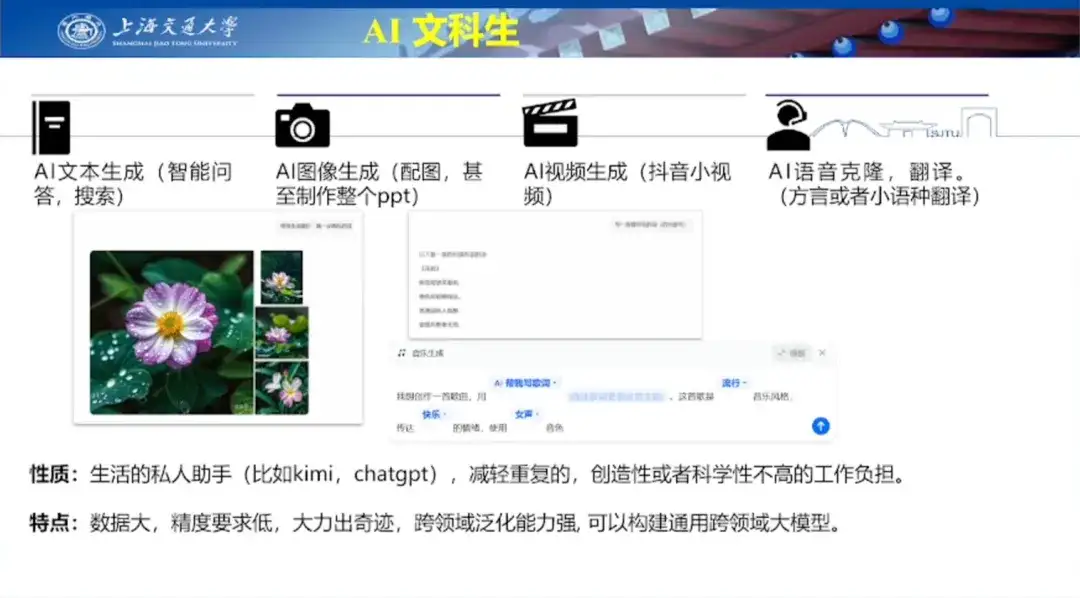
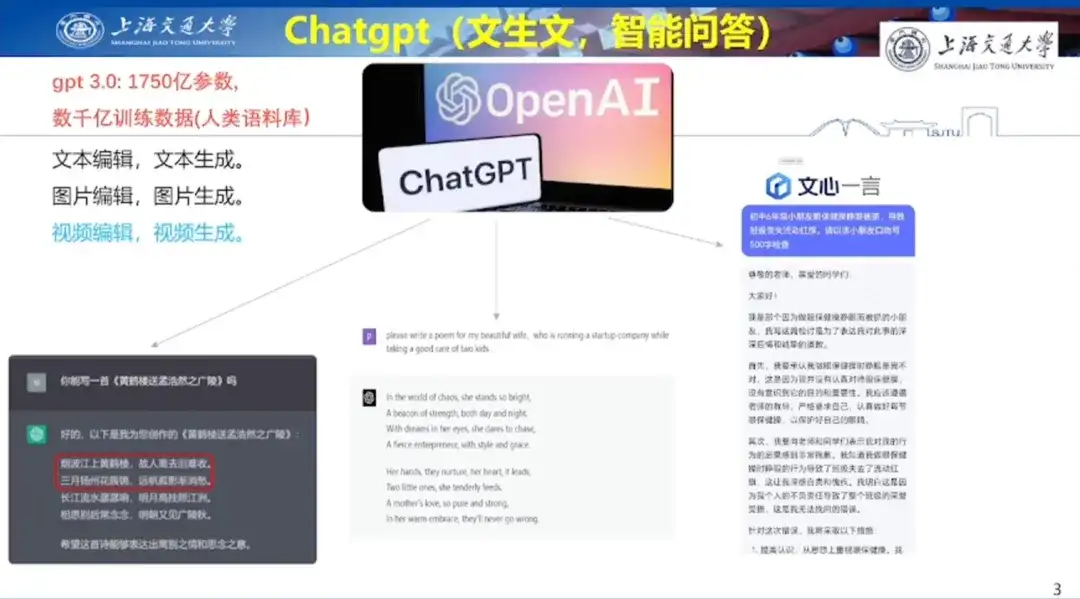
En termes de génération de texte par IA, le professeur Hong Liang a démontré les capacités de création de poésie de ChatGPT en prenant l'exemple de l'écriture d'un poème pour sa femme le jour de la Saint-Valentin. Dans le même temps, il a également partagé l'exemple de l'utilisation de Wen Xin Yi Yan pour aider son fils à l'école primaire à écrire une autocritique, démontrant ainsi la capacité de création de texte de Wen Xin Yi Yan.
En termes de génération d'images IA, le professeur Hong Liang a démontré respectivement Baidu Wenxin Yiyan, Adobe Firefly et Midjourney, ainsi que les différents effets générés sur la base des mêmes mots d'invite, comme le montre la figure ci-dessous.

En termes de génération de vidéos IA, le professeur Hong Liang a démontré les puissantes capacités du populaire Sora en matière de génération de vidéos. Il a cité l'exemple d'une vidéo générée par Sora d'une femme à la mode marchant dans la rue à Tokyo, louant la technique du one-shot et le traitement détaillé des pores du visage montrés dans la vidéo.
Dans le même temps, il a également approuvé l'évaluation faite par les initiés de l'industrie selon laquelle « Sora est un moteur physique basé sur les données » et a estimé que Vincent Video a été d'une grande aide pour les créateurs de contenu sur des plateformes telles que TikTok.

Étudiants en sciences de l'IA : des scientifiques qui résolvent une classe de problèmes scientifiques
Pour les étudiants en sciences de l'IA, c'est-à-dire l'IA pour la science ou l'IA pour l'ingénierie, le professeur Hong Liang estime « Il s'agit d'un scientifique qui résout un type de problème scientifique. Il s'agit essentiellement de former des scientifiques dans différents domaines tels que la biomédecine, la chimie des matériaux, la physique nucléaire, etc. »La principale difficulté réside dans le fait que les exigences de précision sont très élevées et qu’il existe relativement peu de données fonctionnelles disponibles pour la formation. Par conséquent, seuls des modèles d’IA propriétaires peuvent être construits.

Afin d'aider chacun à mieux comprendre l'application de l'IA à la science, le professeur Hong Liang a mené une analyse approfondie basée sur des cas spécifiques tels que l'IA pour la biologie/médecine, l'IA pour les matériaux/la chimie et l'IA pour la fusion nucléaire contrôlée.
Le premier cas concerne l’IA dans le domaine biologique.Le professeur Hong Liang a déclaré : « La prédiction de la structure tridimensionnelle des protéines est le point de départ le plus important pour l'IA pour la science. » Il a expliqué que la prédiction de la structure des protéines préoccupe les scientifiques depuis près de 50 ans. « Avant que DeepMind ne publie le modèle AlphaFold, les scientifiques pensaient généralement que l’utilisation de l’IA pour prédire la structure des protéines n’était qu’un jeu. »
D’AlphaFold 1 à AlphaFold 3, l’IA a démontré ses prouesses dans la prédiction des structures tridimensionnelles des protéines. En particulier, la précision d'AlphaFold 3 a été considérablement améliorée par rapport à de nombreux outils spécialisés précédents, tels que l'interaction protéine-ligand, l'interaction protéine-acide nucléique et la prédiction anticorps-antigène.
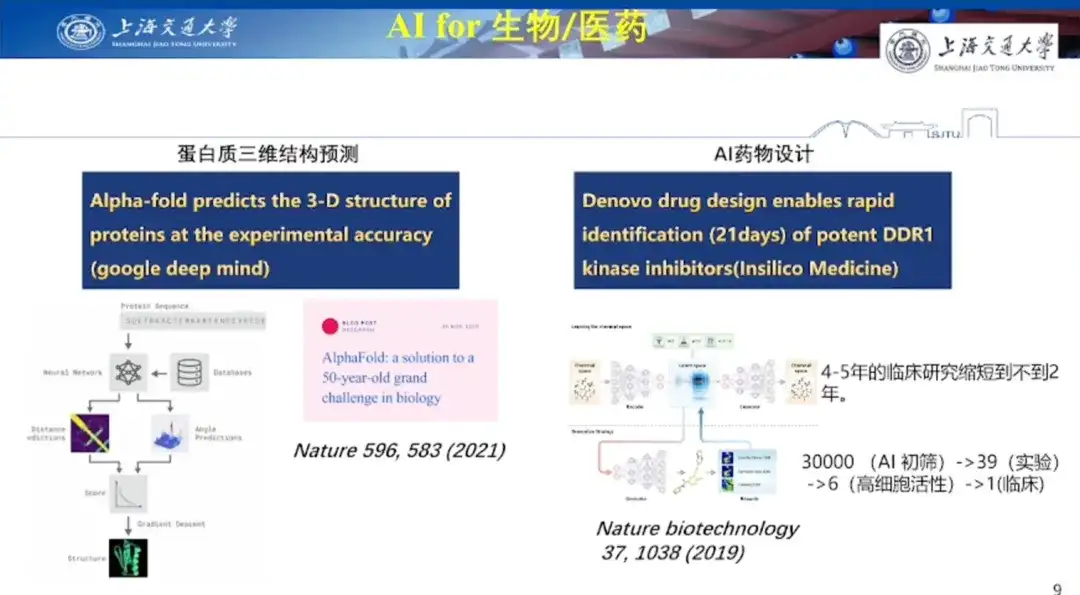
Le deuxième cas est celui de la conception de médicaments par IA.Le professeur Hong Liang a déclaré que la conception de médicaments par IA est relativement difficile car l'application doit non seulement résoudre des problèmes au niveau moléculaire, mais également faire face aux défis des essais cliniques ultérieurs. Les méthodes traditionnelles de découverte de médicaments, telles que le criblage à haut débit, testent des milliers de petites molécules et ne produisent qu’un petit nombre de composés phares, dont seulement un sur dix, voire moins, peut passer les essais cliniques.
Les résultats de recherches publiés dans Nature Biotechnology en 2019 ont révélé l’énorme potentiel de l’IA dans la conception de médicaments. En utilisant l'apprentissage par renforcement (GENTRL), les chercheurs ont découvert de puissants inhibiteurs du récepteur du domaine discoïdine 1 (DDR1), une cible kinase associée aux maladies fibrotiques, en 21 jours. Les chercheurs ont utilisé la technologie de l’IA pour sélectionner initialement 30 000 molécules, puis ont mené 39 expériences cellulaires en utilisant diverses méthodes de criblage, en trouvant 6 avec une activité cellulaire élevée et en faisant finalement passer 1 aux essais cliniques.
En outre, le professeur Hong Liang a également cité des cas d’IA pour les matériaux/la chimie.Il croit que« L’IA pour les matériaux, en particulier les matériaux chimiques, est une chose difficile à mettre en œuvre. »Cependant, les matériaux ne sont pas comme les langues naturelles, les langues humaines et les séquences d’ADN. Ils n’ont pas de jetons discrets. Étant donné que les matériaux sont essentiellement un problème de structure tridimensionnelle, lors de la construction d’un grand modèle, il est nécessaire de combiner des calculs DFT, des expériences automatisées et l’IA pour promouvoir de manière récursive la synthèse de composés inorganiques spécifiques. Par exemple, l'équipe des matériaux de DeepMind a lancé le réseau de graphes pour l'exploration des matériaux (GNoME) basé sur l'apprentissage profond en 2023. Lors d'une tâche de test, le laboratoire A-Lab a synthétisé avec succès 41 des 58 matériaux prédits en 17 jours, ce qui n'était possible qu'au cours des 10 dernières années, voire plus.

Enfin, le professeur Hong Liang a cité des cas tels que l’IA pour la fusion nucléaire contrôlée, et a déclaré que les progrès dans cette direction sont très gratifiants.Il a souligné que le principal problème de la fusion nucléaire actuelle est que le plasma est très facile à « déchirer » et à s’échapper du champ magnétique puissant utilisé pour le confiner, provoquant ainsi l’interruption de la réaction de fusion. L’équipe de Princeton a développé un contrôleur d’IA capable de prédire le risque potentiel de déchirure du plasma 300 millisecondes à l’avance et d’intervenir à temps.
Comme le montre la figure ci-dessous, les chercheurs ont intégré des méthodes traditionnelles basées sur la physique avec des techniques d’IA avancées pour améliorer le contrôle et la compréhension du comportement du plasma. Les figures suivantes a, b et c révèlent l’état du plasma dans un réacteur à fusion.
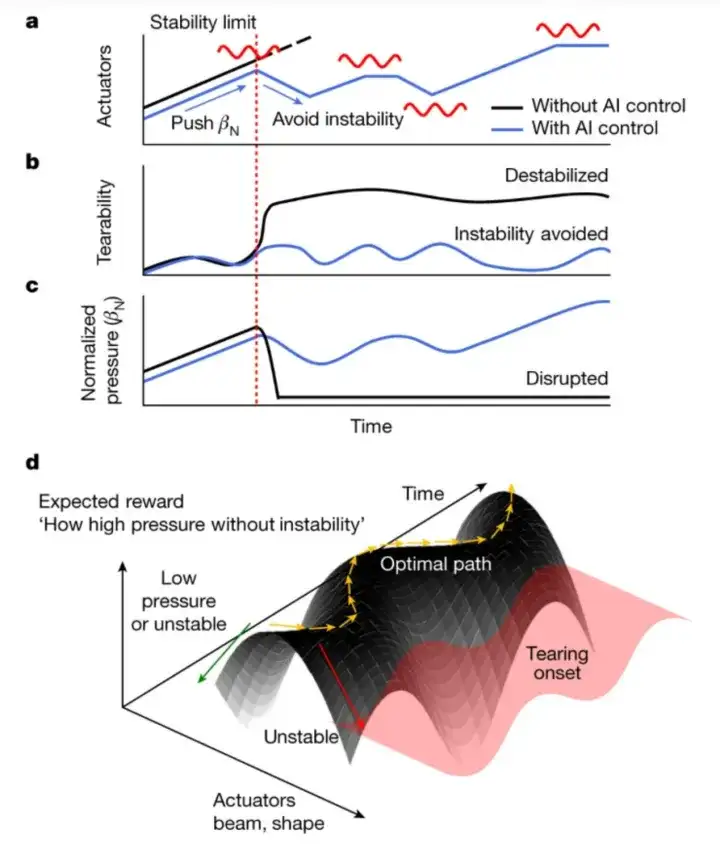
La ligne noire du panneau a montre que lorsque la pression du plasma est augmentée en augmentant la température externe (par exemple un faisceau de particules neutres), une limite de stabilité est finalement atteinte. Lorsque cette limite est dépassée, des instabilités de déchirure sont excitées. Une fois l'instabilité de déchirure excitée, le plasma sera rapidement détruit, ce qui peut entraîner de graves conséquences en fonctionnement réel, comme le montrent les figures b et c.
En s'appuyant sur des réseaux neuronaux profonds et sur l'apprentissage par renforcement, les chercheurs ont développé un système de contrôle intelligent capable de réagir aux changements d'état du plasma en temps réel, de prédire l'état futur du plasma et d'ajuster les actions de contrôle en conséquence, de sorte que le fonctionnement du tokamak suive le chemin idéal et évite les instabilités de déchirure tout en maintenant une pression élevée.
Enfin, le professeur Hong Liang a souligné :« Pour véritablement mettre en œuvre l’IA pour la science, il faut d’abord définir le problème scientifique, puis proposer une solution d’IA. »
L'IA pour la bio-ingénierie : résoudre des problèmes d'ingénierie et mettre en œuvre des produits multi-scénarios
Le professeur Hong Liang a ensuite expliqué la définition et les défis de l'ingénierie protéique traditionnelle, l'application de l'IA dans le domaine de l'ingénierie protéique, les résultats de R&D de l'équipe et leur mise en œuvre, ainsi que les principaux avantages de l'équipe, révélant davantage la valeur de l'IA pour la bio-ingénierie.
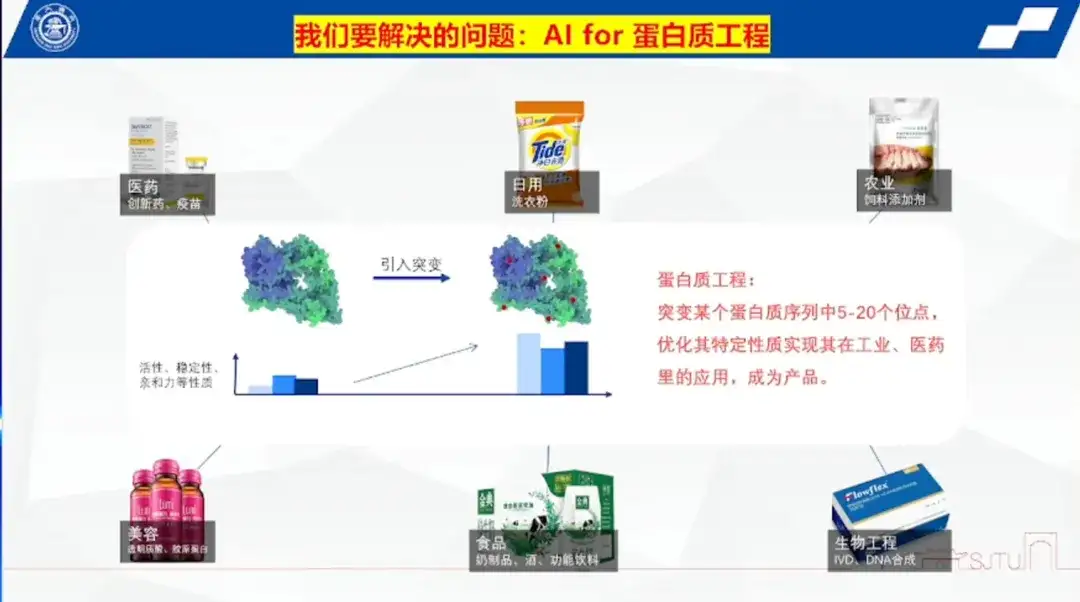
Ingénierie des protéines : mutation des sites de séquences protéiques pour répondre aux exigences des applications des produits
Le professeur Hong Liang a souligné que l'ingénierie des protéines consiste à muter 5 à 20 sites dans une séquence protéique pour optimiser ses propriétés spécifiques et réaliser son application dans l'industrie et la médecine, la transformant ainsi en un produit.
Il a expliqué que les protéines ne sont pas seulement un composant important des organismes, mais aussi un produit indispensable dans la vie quotidienne des gens. Les enzymes, en tant que molécules protéiques, sont largement utilisées dans les scénarios industriels et ont des effets catalytiques. Par exemple, les enzymes couplées au site ADC des anticorps dans le domaine des médicaments innovants, les enzymes dans les détergents à lessive, les additifs enzymatiques dans les aliments pour animaux qui aident le métabolisme animal et diverses enzymes dans la beauté, l'alimentation et la bio-ingénierie.
Le professeur Hong Liang a ensuite présenté les deux pratiques les plus courantes en matière d’ingénierie des protéines.
La première est la conception rationnelle/semi-rationnelle.En général, il est nécessaire d’étudier clairement la structure des protéines et le mécanisme catalytique, puis d’effectuer des modifications en fonction du mécanisme. Cependant, l’inconvénient d’une conception rationnelle est qu’elle prend du temps, que les sites à modifier sont principalement concentrés autour des poches actives, que la portée de la conception est relativement limitée et que la portée de la réflexion est également restreinte.
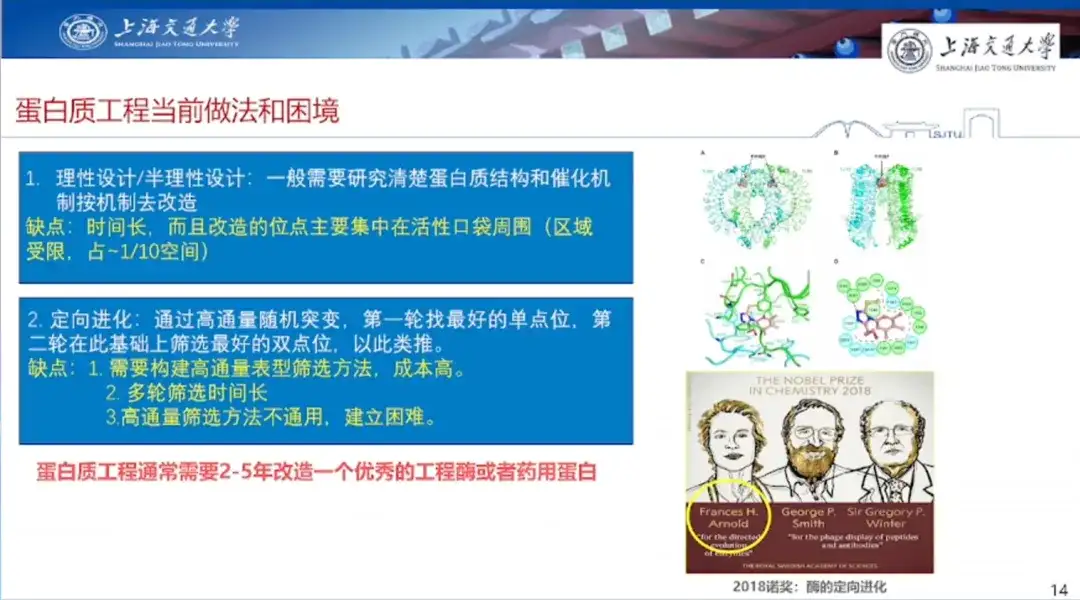
La deuxième est l’évolution dirigée.C'est-à-dire, briser le paradigme de la pensée humaine, grâce à un criblage à haut débit, une mutagenèse aléatoire à site unique à haut débit basée sur la nature, à la recherche du meilleur mutant à site unique au premier tour, et au criblage du meilleur double site sur cette base au deuxième tour, et ainsi de suite. Son avantage est qu’il ne s’appuie pas sur l’expérience passée et peut être réalisé uniquement avec de l’argent ; Son inconvénient est qu’il nécessite la construction d’une méthode de criblage phénotypique à haut débit, qui est coûteuse, nécessite une longue série de criblages, et les méthodes de criblage à haut débit ne sont pas universelles et difficiles à établir.
Le professeur Hong Liang a présenté l’expérience sur la protéine fluorescente verte en utilisant comme exemple l’article de recherche publié dans Nature en 2016. Il a souligné que dans cette expérience, bien que le criblage à haut débit puisse sélectionner des sites positifs et améliorer les propriétés de la protéine lorsque les chercheurs font muter les sites individuellement, si plusieurs sites de mutation sont combinés, la protéine synthétique perdra son activité.
Il a dit,« Comment trouver d'excellents sites de mutation dans le vaste espace de phase et les combiner en d'excellents mutants multi-sites pour réaliser leur valeur d'application est le défi auquel est actuellement confrontée l'ingénierie des protéines. »

Technologie générale d'intelligence artificielle pour l'ingénierie des protéines : conception de séquences orientées fonction de bout en bout
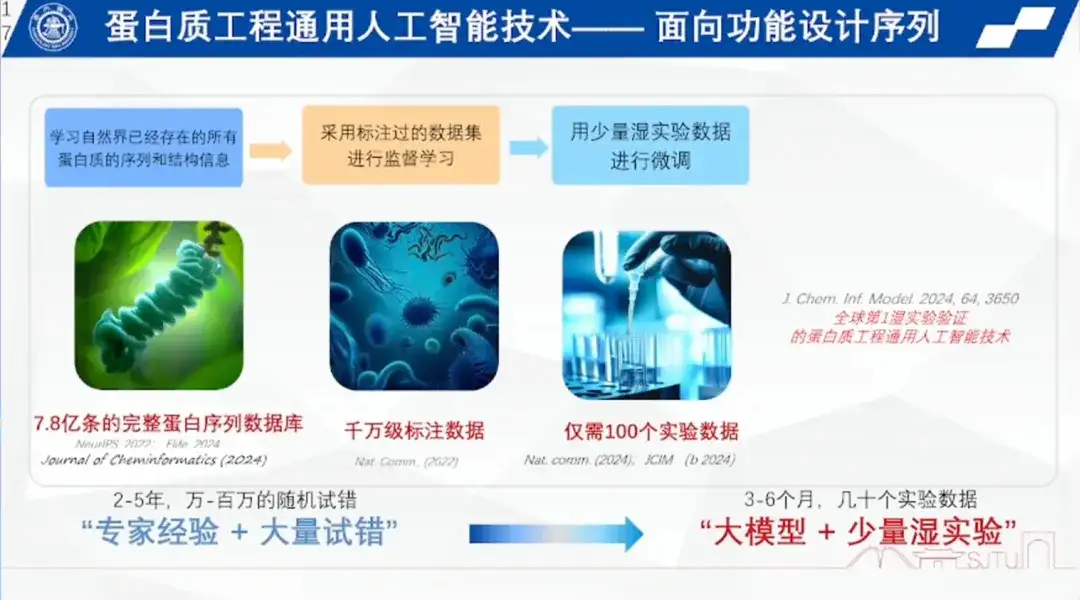
« Si l’intelligence artificielle veut faire une percée dans un domaine d’ingénierie, il ne s’agit pas simplement de créer un assistant pour les scientifiques et d’effectuer des tâches de base comme la collecte de littérature, mais de faire des choses que les experts humains ne peuvent pas faire. »Sur cette base, l'équipe du professeur Hong Liang a commencé à explorer des modèles propriétaires dans le domaine de l'ingénierie des protéines en 2021, en concevant des séquences fonctionnelles de bout en bout.
L'équipe de recherche a compilé une base de données de centaines de millions de séquences protéiques complètes basées sur toutes les protéines connues dans la nature et a construit une intelligence artificielle générale pour l'ingénierie des protéines afin d'apprendre l'agencement et les règles des acides aminés sur la base de cette base de données.
Le professeur Hong Liang a donné une explication détaillée des scénarios d'application de la technologie générale de l'intelligence artificielle dans l'ingénierie des protéines à travers cinq cas d'application pratiques du monde réel, notamment la collaboration avec le professeur Liu Jia de l'Université ShanghaiTech pour améliorer la stabilité thermique de Crisper cas12a, la collaboration avec Jinsai Pharmaceutical pour améliorer la résistance alcaline des anticorps à domaine unique et la collaboration avec Hanhai New Enzymes pour lancer des innovations enzymatiques.
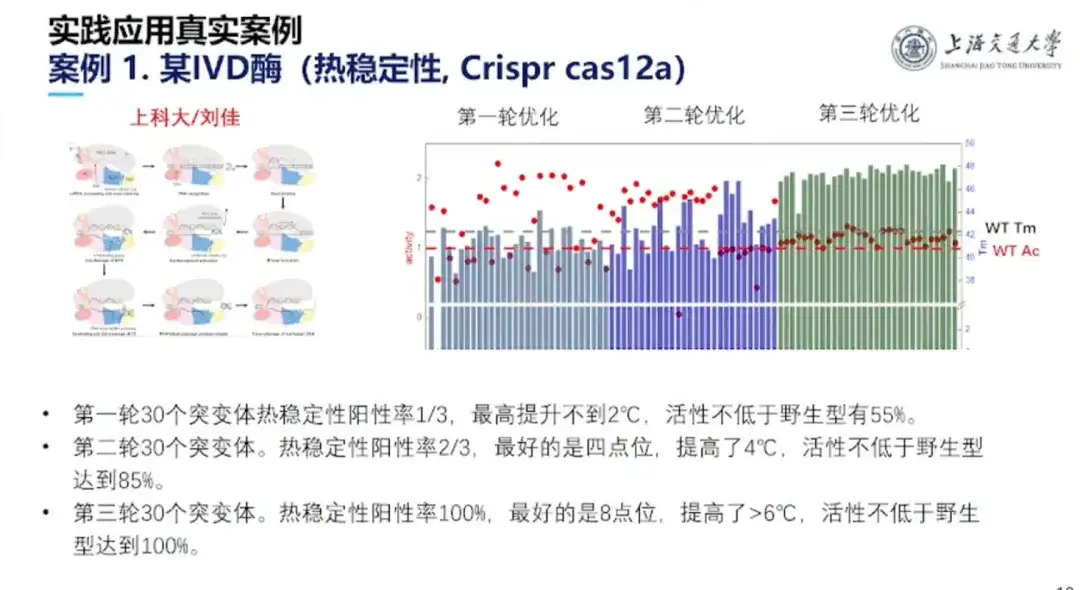
Cas 1 : Amélioration de la stabilité thermique du Crisper cas12a
Ce projet a été réalisé par l'équipe du professeur Hong Liang et le professeur Liu Jia de l'Université ShanghaiTech. Crisper cas12a est composé de 1 300 acides aminés. Le type sauvage a une bonne activité mais une faible stabilité. En tant que kit de diagnostic in vitro, il ne peut pas être utilisé à température ambiante et le coût de réfrigération est élevé. À cette fin, l’équipe de recherche a mené trois séries d’expériences. Finalement, la stabilité du mutant a atteint un état d'augmentation continue et le rapport d'activité protéique non inférieur à celui du type sauvage a atteint 100%.
Le professeur Hong Liang a présenté,Le domaine de l'ingénierie des protéines est celui qui présente le plus de données négatives. L'IA peut combiner des sites négatifs et positifs, élargissant ainsi le champ d'imagination de l'ingénierie des protéines. Cela dépasse le cadre de la conception rationnelle des ingénieurs enzymatiques professionnels. L'IA a pratiquement remplacé l'ancienne méthode de calcul physique.
Il a ensuite présenté la logique sous-jacente de la manière dont l’IA combine les données de mutation négative et positive des protéines, qui est divisée en trois étapes.
La première étape consiste à créer un vocabulaire de langage protéique.Il a comparé le processus de pré-formation des informations sur les séquences protéiques à un test cloze, qui consiste à utiliser un modèle pour bloquer de manière aléatoire n'importe quelle séquence dans une base de données de centaines de millions de séquences protéiques complètes, de manière continue ou discrète, et le modèle peut ensuite remplir les zones bloquées. Cette opération est répétée plusieurs fois pour garantir qu’un modèle puisse pré-entraîner des centaines de millions de séquences de protéines, créant ainsi un vocabulaire du langage des protéines.
La deuxième étape est l’étiquetage.L’équipe de recherche a étiqueté des dizaines de millions de paramètres tels que la température, la pression et le pH.
La troisième étape est l’apprentissage par petits échantillons.Autrement dit, un réglage fin est effectué à l’aide d’une petite quantité de données expérimentales humides pour compléter l’apprentissage par renforcement, résolvant ainsi le problème du petit échantillon en bio-ingénierie.

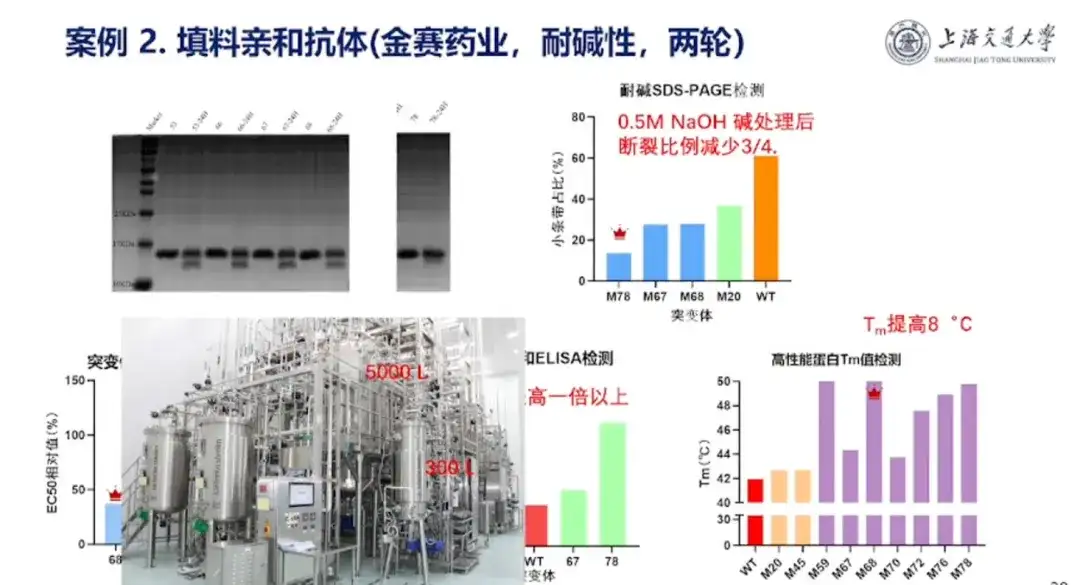
Cas 2 : Collaboration avec Jinsai Pharmaceuticals sur le développement d'anticorps à domaine unique extrêmement résistants aux alcalis
Le professeur Hong Liang a souligné que Jinsai Pharmaceutical purifie souvent l'hormone de croissance en sélectionnant des anticorps à domaine unique à partir de la bibliothèque d'anticorps à domaine unique d'alpaga et en les plaçant sur une colonne d'hydrogène. Cependant, au cours du processus de purification, l'hydrogène et les colonnes seront inévitablement contaminés par certaines impuretés et devront être nettoyés avec un alcali fort avant de pouvoir être utilisés dans la prochaine expérience de purification. Cependant, les organismes ne sont pas résistants aux alcalis forts et il existe un risque de corrosion. Par conséquent, Jinsai Pharmaceutical espère améliorer la résistance alcaline des anticorps à domaine unique.
À cet égard,L'équipe de recherche a traité les anticorps à domaine unique conçus par le grand modèle de la série Pro avec 0,5 M de NaOH pendant 24 heures et a amélioré avec succès la résistance alcaline des anticorps à domaine unique.La protéine résistante aux alcalis conçue dans ce projet a atteint une production de masse de 5 000 L.Il s’agit du premier produit protéique fabriqué à partir d’un grand modèle qui a été industrialisé.
Cas 3 : Améliorer la sélectivité, l'activité et le rendement des glycosyltransférases grâce à l'innovation enzymatique
Le matériau de base pour le dépistage de la pancréatite aiguë et de la sialadénite est le maltoheptaglycoside, qui a une structure très complexe et un coût de production chimique élevé. Il est vendu en Chine pour des centaines de milliers de yuans le kilo. En réponse à cela, l'équipe du professeur Hong Liang et Hanhai New Enzyme ont lancé conjointement une innovation enzymatique, qui consiste à utiliser une glycosyltransférase pour produire du maltoheptaglycoside. L'équipe de recherche doit améliorer quatre indicateurs, à savoir, améliorer la réaction de transglycosylation, améliorer la spécificité de la réaction, réduire l'activité d'hydrolyse et augmenter le rendement.
Au cours de deux séries d'expériences de transformation, les chercheurs ont amélioré l'indice BUG de 80 mutants, augmenté l'activité totale de transglycosylation de 8 fois, augmenté la pureté du produit cible de 80 à 95, réduit l'indice d'activité d'hydrolyse à 10 et doublé le rendement P3.Ce produit a déjà été mis en production sur une ligne de production de 1 000 kilogrammes à Yichang, Hubei, réduisant considérablement les coûts de production.
Cas 4 : Test d'affinité des anticorps basé sur l'apprentissage sur de petits échantillons dans un test en simple aveugle
« L'IA au service de la science doit résoudre le problème des petits échantillons. La simple publication d'articles n'a guère d'utilité pratique. » Le professeur Hong Liang a développé ce point à travers une démonstration réalisée en coopération avec une société pharmaceutique spécialisée dans les anticorps.
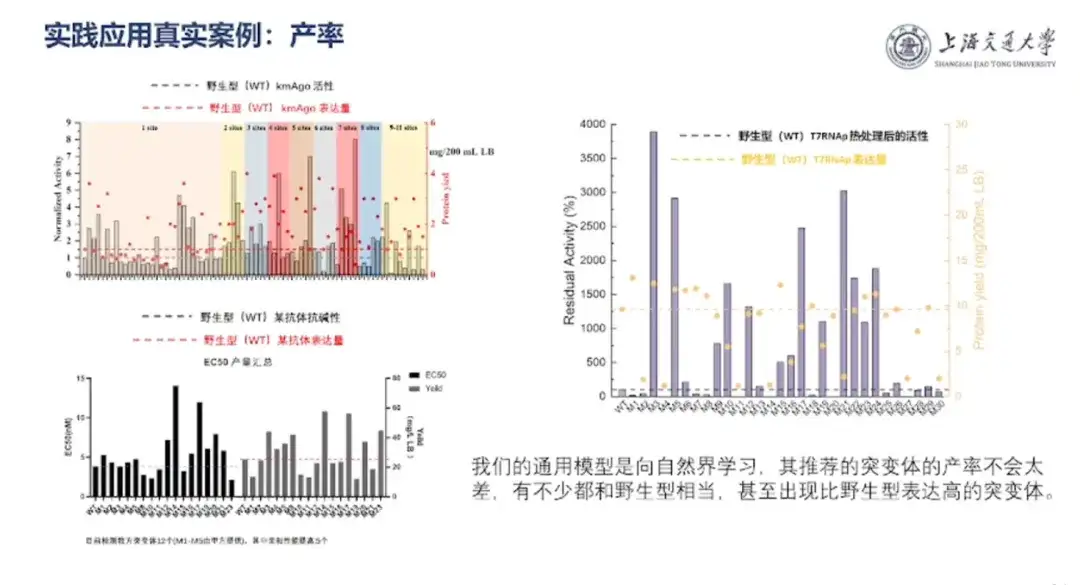
Le professeur Hong Liang a expliqué qu'il s'agit d'un anticorps ScFv d'une longueur totale de 245 acides aminés et de 21 sites de mutation, et que ses séquences de mutation possibles dépassent 10 millions. Cependant, le collaborateur n’a fourni des données d’affinité que pour 33 mutants connus et des données d’affinité pour 14 nouvelles séquences qui étaient censées être inconnues. Sur la base d’un apprentissage sur un petit échantillon, l’équipe a obtenu un coefficient de corrélation de 0,65 dans un test en simple aveugle.
« Qu'il s'agisse de biomédecine ou de biologie synthétique, la mise en œuvre finale doit toujours résoudre le problème du coût, c'est-à-dire que le rendement doit être élevé. »Le professeur Hong Liang a expliqué que « le modèle de conception de protéines par IA de l'équipe s'inspire de la nature, et le rendement des mutants qu'il recommande ne sera pas trop mauvais. Nombre d'entre eux sont comparables au type sauvage, et certains mutants présentent même une expression plus élevée que le type sauvage. »
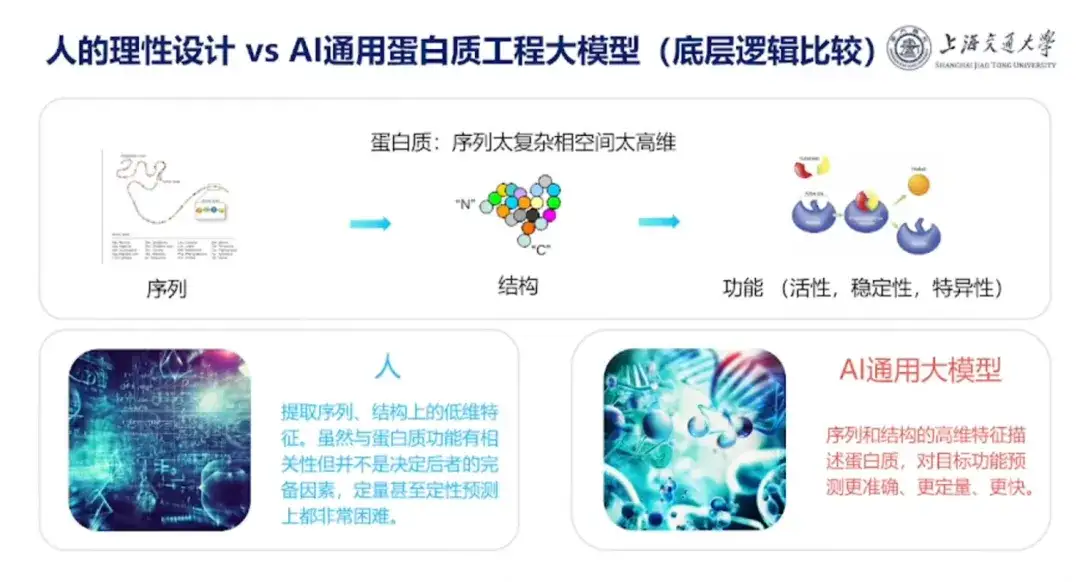
En parlant de la différence entre la conception des protéines dans le cerveau humain et le modèle de conception des protéines de l'IA, le professeur Hong Liang a souligné que la principale différence est que les humains aiment résumer l'expérience, mais l'expérience humaine est généralement de faible dimension, comme les séquences d'extraction de protéines et les caractéristiques structurelles de faible dimension. Bien que ces caractéristiques soient corrélées à la fonction des protéines, elles ne constituent pas des facteurs complets dans la détermination de cette dernière et sont difficiles à prédire à la fois quantitativement et qualitativement.Le modèle de conception de protéines IA peut utiliser des fonctionnalités de grande dimension pour décrire la séquence et la structure des protéines et prédire les fonctions cibles de manière plus précise, quantitative et rapide.
Cas 5 : Conception de séquences protéiques de novo
Pour illustrer davantage ce problème, le professeur Hong Liang a partagé un résultat de son groupe de recherche Cell Discovery. Il a déclaré qu'il s'agit de la plus grande séquence protéique obtenue grâce à une conception de novo, une enzyme d'édition de gènes avec 6 domaines et plus de 700 acides aminés.
Il existe plus de 600 enzymes d’édition connues dans la nature, et l’équipe de recherche a généré 27 nouvelles séquences en utilisant cela comme modèle. Par rapport à la nature, les similitudes de séquence sont toutes inférieures à 65%, la plus faible étant 49%. En d'autres termes, l'équipe de recherche a modifié plus de 300 des plus de 700 séquences d'acides aminés, dont 23 étaient actives, 2/3 étaient plus actives que le type sauvage, et la plus élevée était 8,6 fois celle du type sauvage.
Le professeur Hong Liang a déclaré : « Le modèle de conception de protéines par IA peut réaliser la modification de séquences de 300 acides aminés tout en maintenant une bonne activité et un taux positif élevé. L'IA est déjà bien supérieure aux experts humains dans ce type de tâche de génération de séquences. »
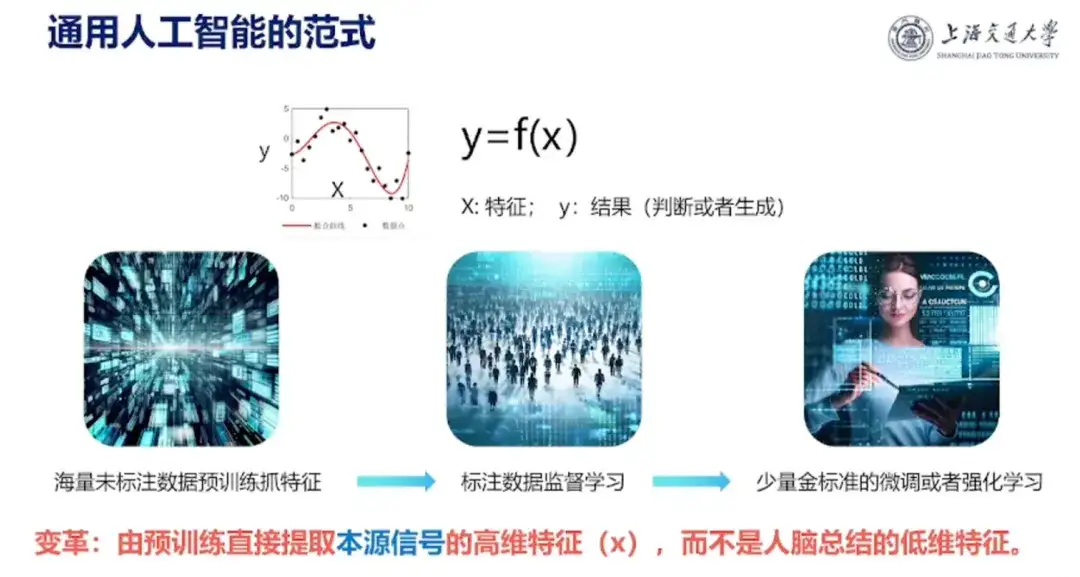
En outre, le professeur Hong Liang a également partagé sa compréhension de l’intelligence artificielle :L'intelligence artificielle est une correspondance de y vers x, où x est la caractéristique d'entrée et y le résultat souhaité, comme la stabilité et l'activité d'une protéine. L'intelligence artificielle effectue désormais un ajustement à haute dimension.
Le grand modèle de conception de protéines par l'IA permet d'améliorer considérablement la productivité
Le professeur Hong Liang a présenté le modèle de conception de protéines d'IA construit par l'équipe et a expliqué que « les chercheurs saisissent une séquence dans le logiciel interne, et la plateforme sélectionnera 30 ou 50 séquences conformes aux lois de la nature pour les expériences, puis entrera dans la phase d'apprentissage sur petits échantillons, qui consiste à affiner le modèle d'IA en fonction des indicateurs requis par les chercheurs. Enfin, les mutants dominants sont produits. »
Il convient de mentionner qu’actuellement, il n’y a que deux chercheurs dans l’équipe qui se concentrent sur la conception de protéines, l’un dans le domaine de la biomédecine et l’autre dans le domaine de la biologie synthétique, mais l’équipe gère plus de 40 projets en même temps.Cela confirme également ce que le professeur Hong a déclaré : « Une fois que l’IA aura la capacité de percer l’ingénierie sous-jacente, elle libérera une productivité énorme. »
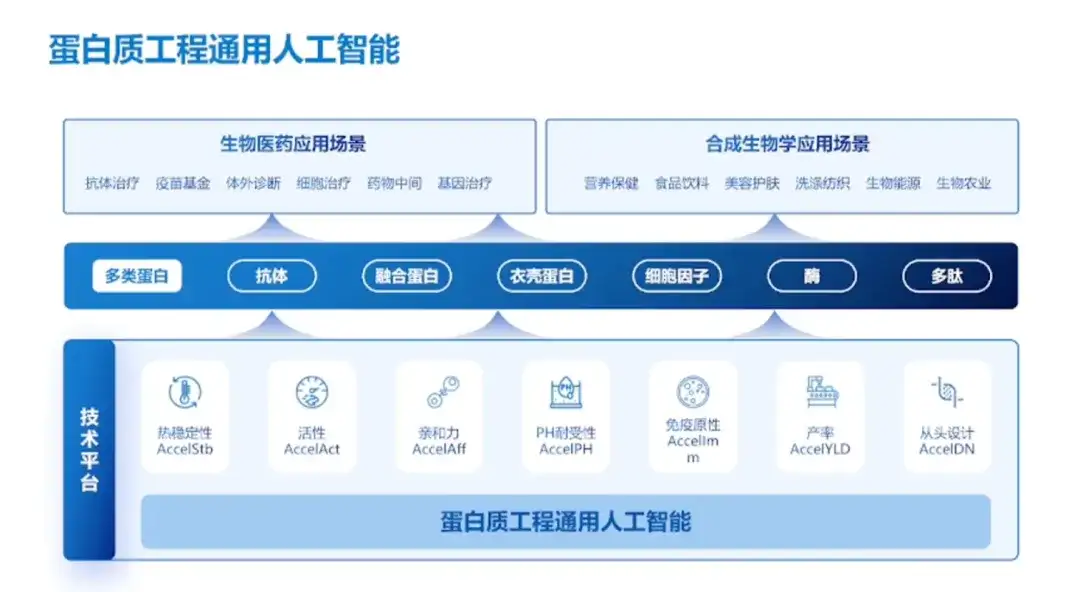
Nous entretenons une coopération approfondie avec de nombreuses universités et entreprises et bénéficions de trois avantages fondamentaux
En outre, le professeur Hong Liang a également démontré les réalisations et les principaux avantages de l’équipe.
En termes de réalisations, l'équipe a mené une coopération approfondie avec des universités/instituts de recherche tels que l'Université Tsinghua et l'Institut d'immunochimie de l'Université ShanghaiTech, ainsi qu'avec des entreprises telles que Jinsai Pharmaceuticals, Hanhai New Enzyme et Corning Jeol.Au cours de l’année écoulée, 20 protéines ont été transformées avec succès avec des résultats fructueux.
En termes d’avantages pour l’équipe, le professeur Hong Liang a déclaré :L'équipe « dispose d'avantages fondamentaux dans trois domaines : de nouvelles données, des modèles indépendants et des produits inédits sur le marché ».Premièrement, l’équipe dispose de données complètes sur les séquences protéiques, qui sont nettement plus volumineuses que les ensembles de données publics ; deuxièmement, l'équipe dispose de modèles indépendants, d'un vocabulaire protéique auto-construit, de méthodes d'apprentissage sur de petits échantillons et de méthodes de pré-formation séquence + structure, et la précision expérimentale et la vitesse de recherche sont à l'avant-garde mondiale ; enfin, à l’échelle mondiale, l’équipe a pris les devants en réalisant l’application pratique de multiples produits protéiques.

Perspectives de l'IA pour la science : Au cours des trois prochaines années, nous réaliserons le mode de conception standard de l'automatisation des grands modèles d'IA
Le professeur Hong Liang estime que « dans les trois prochaines années, dans les domaines de la conception des protéines, du développement de médicaments, du diagnostic des maladies, de la découverte de nouvelles cibles, de la conception des voies de synthèse chimique et de la conception des matériaux, l'intelligence artificielle générale dans les domaines professionnels entraînera un changement de paradigme clair, transformant le modèle de découverte scientifique qui reposait auparavant sur des essais et des erreurs sporadiques du cerveau humain en un modèle de conception standard automatisé à grand modèle d'IA. »

Les changements spécifiques incluent la création de méthodes d’apprentissage à échantillon nul ou à petit échantillon et la création de modèles technologiques de pré-formation.En l'absence de données, une grande quantité de fausses données avec une précision légèrement inférieure est générée via un simulateur physique pour la pré-formation, puis affinée avec des données réelles et précieuses pour compléter l'apprentissage par renforcement. Le professeur Hong a souligné que « les fausses données désignent des données qui ne proviennent pas du monde réel, mais qui présentent un certain degré de fiabilité. Elles peuvent être générées par l'IA ou obtenues par simulation physique pour améliorer les données. Enfin, les données expérimentales réelles en milieu humide sont les plus précieuses et servent à affiner le modèle. »
À la fin de cette séance de partage, le professeur Hong Liang a une fois de plus résumé les étudiants en arts libéraux de l'IA par rapport aux étudiants en sciences de l'IA. Il croit que Les étudiants en arts libéraux de l'IA sont essentiellement des assistants personnels pour la vie et le travail humains, comme Kimi et ChatGPT, peuvent aider les gens à réduire le travail créatif répétitif ou moins scientifique. Ses caractéristiques sont des données volumineuses, des exigences de faible précision, la capacité de faire des miracles avec beaucoup d'efforts, une forte capacité de généralisation inter-domaines et il peut être utilisé pour construire de grands modèles généraux inter-domaines, mais il devrait appartenir aux grandes entreprises et ne convient pas aux universités et aux instituts de recherche.
et Les étudiants en sciences de l’IA doivent résoudre un type de problème scientifique ou d’ingénierie.En remplaçant les cerveaux de R&D des scientifiques des entreprises et des instituts scientifiques, en faisant des choses très créatives, en réduisant considérablement les coûts et en augmentant l'efficacité, et même en développant des produits qui étaient impossibles avec l'expérience scientifique précédente, les équipes des universités et des instituts de recherche peuvent combiner leurs barrières professionnelles uniques pour explorer des solutions d'IA dans des domaines connexes.

À propos du professeur Hong Liang
Le professeur Hong Liang a étudié pour son diplôme de premier cycle au Département de physique de l'Université des sciences et technologies de Chine et pour ses études supérieures à l'Université chinoise de Hong Kong, où sa direction de recherche était la synthèse/caractérisation des nanomatériaux. Il a obtenu son doctorat à l'Université d'Akron aux États-Unis, où ses principales orientations de recherche étaient les propriétés physico-chimiques, la dynamique et les transitions de phase des polymères/protéines.

En 2010,Le professeur Hong Liang a rejoint le laboratoire national d'Oak Ridge aux États-Unis en tant qu'étudiant postdoctoral, se concentrant sur la structure, la dynamique et la fonction des protéines dans le domaine de la biologie computationnelle. En 2015,Le professeur Hong Liang a rejoint l'Université Jiao Tong de Shanghai en tant que chercheur principal indépendant pour mener des recherches en biophysique moléculaire. En 2020,Le professeur Hong Liang combine l’IA, l’informatique et les expériences humides pour mener des recherches sur la conception de protéines. Son passage de la physique à la chimie, de la chimie à la biologie, et enfin des expériences humides à l’informatique et à l’intelligence artificielle est un parcours de recherche interdisciplinaire typique.
Après trois ans, l'équipe du professeur Hong Liang a développé de manière indépendante la série Pro de protéines d'intelligence artificielle générale « de la séquence à la fonction »:De la pré-formation de grands modèles, à l'exploration des listes de vocabulaire sous-jacentes, puis aux méthodes d'apprentissage supervisé, nous avons créé une base de données d'étiquettes de propriétés physiques et chimiques des protéines, et sur cette base, nous avons développé une méthode de réglage fin de petits échantillons, et avons finalement ouvert une solution d'intelligence artificielle pour la conception fonctionnelle de séquences de protéines.
Pour les résultats connexes, veuillez vous référer à la page d'accueil de son groupe de recherche :
https://ins.sjtu.edu.cn/people/lhong/papers.html
Jusqu’à présent, l’équipe de recherche dirigée par le professeur Hong Liang a mené des échanges et une coopération riches et approfondis avec des partenaires universitaires et industriels.Il concerne de nombreux domaines tels que la biomédecine, le diagnostic in vitro, les intermédiaires pharmaceutiques, la nutrition et les soins de santé, l’alimentation et les boissons, la beauté et les soins de la peau, le lavage et les textiles, la bioénergie, la bioagriculture et l’ingénierie environnementale.À une époque où les résultats de la recherche scientifique sont produits à un rythme élevé, voire à un rythme fou, ils adhèrent toujours à l'intention initiale de « mener des recherches pratiques », pratiquent ce qu'ils prêchent et gardent les pieds sur terre, apportant un résultat de recherche scientifique après l'autre du laboratoire à la chaîne de production.
Pour plus d'informations sur le professeur Hong Liang, veuillez visiter :
https://ins.sjtu.edu.cn/people/








