Command Palette
Search for a command to run...
Le Nouveau Jeu De Données De Référence En Biologie LAB-Bench Est Désormais Open Source ! Couvrant 8 Tâches Principales, Plus De 2,4 000 Questions À Choix Multiples

Lorsqu’un ami étranger vous salue en vous disant « Comment vas-tu ? », quelle est votre première réaction ?
N'est-ce pas le classique « Je vais bien, merci. Et vous » ?
en fait,Ce type de méthode de questions-réponses de manuel existe non seulement dans notre apprentissage et notre communication en anglais, mais également dans la formation et le test de grands modèles linguistiques.
De nos jours, l’utilisation de grands modèles de langage (LLM) et de systèmes améliorés par LLM dans la recherche dans des domaines tels que la biologie, les sciences marines et la science des matériaux pour améliorer l’efficacité et la production de la recherche scientifique est devenue un objectif clé pour de nombreux scientifiques. Par exemple,L'équipe de l'Université du Zhejiang a lancé le grand modèle de langage OceanGPT dans le domaine océanique.Microsoft a développé le grand modèle de langage BioGPT dans le domaine de la biomédecine, et l'Université Jiao Tong de Shanghai a proposé le grand modèle de langage K2 dans le domaine des sciences de la terre.
Il convient de noter queAlors que les LLM deviennent de plus en plus populaires dans le domaine de la recherche scientifique, il devient crucial d’établir un ensemble de critères d’évaluation de haute qualité et professionnels.
Il existe cependant de nombreux critères de référence qui se concentrent sur l’évaluation des connaissances et des capacités de raisonnement des étudiants en LLM sur les problèmes scientifiques des manuels.Il est difficile d'évaluer La performance du LLM dans des tâches de recherche scientifique pratiques telles que la recherche documentaire, la planification de programmes et l'analyse de données,Il en résulte que le modèle présente des lacunes évidentes en termes de flexibilité et de professionnalisme lorsqu’il s’agit de traiter des tâches scientifiques réelles.
Promouvoir le développement efficace des systèmes d’IA en biologie,Les chercheurs de FutureHouse Inc. ont lancé l'ensemble de données Language Agent Biology Benchmark (LAB-Bench).LAB-Bench contient plus de 2 400 questions à choix multiples pour évaluer les performances des systèmes d'IA dans la recherche biologique réelle, telles que la recherche et le raisonnement de la littérature (LitQA2 et SuppQA), l'interprétation graphique (FigQA), l'interprétation de tableaux (TableQA), l'accès à la base de données (DbQA), la rédaction de protocoles (ProtocolQA), la compréhension et le traitement des séquences d'ADN et de protéines (SeqQA) et les scénarios de clonage (CloningScenarios).
La recherche, intitulée « LAB-Bench Measuring Capabilities of Language Models for Biology Research », a été soumise à la conférence de haut niveau NeurlPS 2024.
* Ensemble de données de référence en biologie du modèle de langage LAB Bench :
https://go.hyper.ai/kMe1e
Samuel G. Rodriques, l'auteur correspondant de l'article, a souligné :En tant que premier ensemble d'évaluation visant à évaluer si les modèles et les agents peuvent mener des recherches scientifiques, LAB-Bench utilise une méthode d'évaluation programmatique pour les tâches complexes, ce qui sera très important à l'avenir.
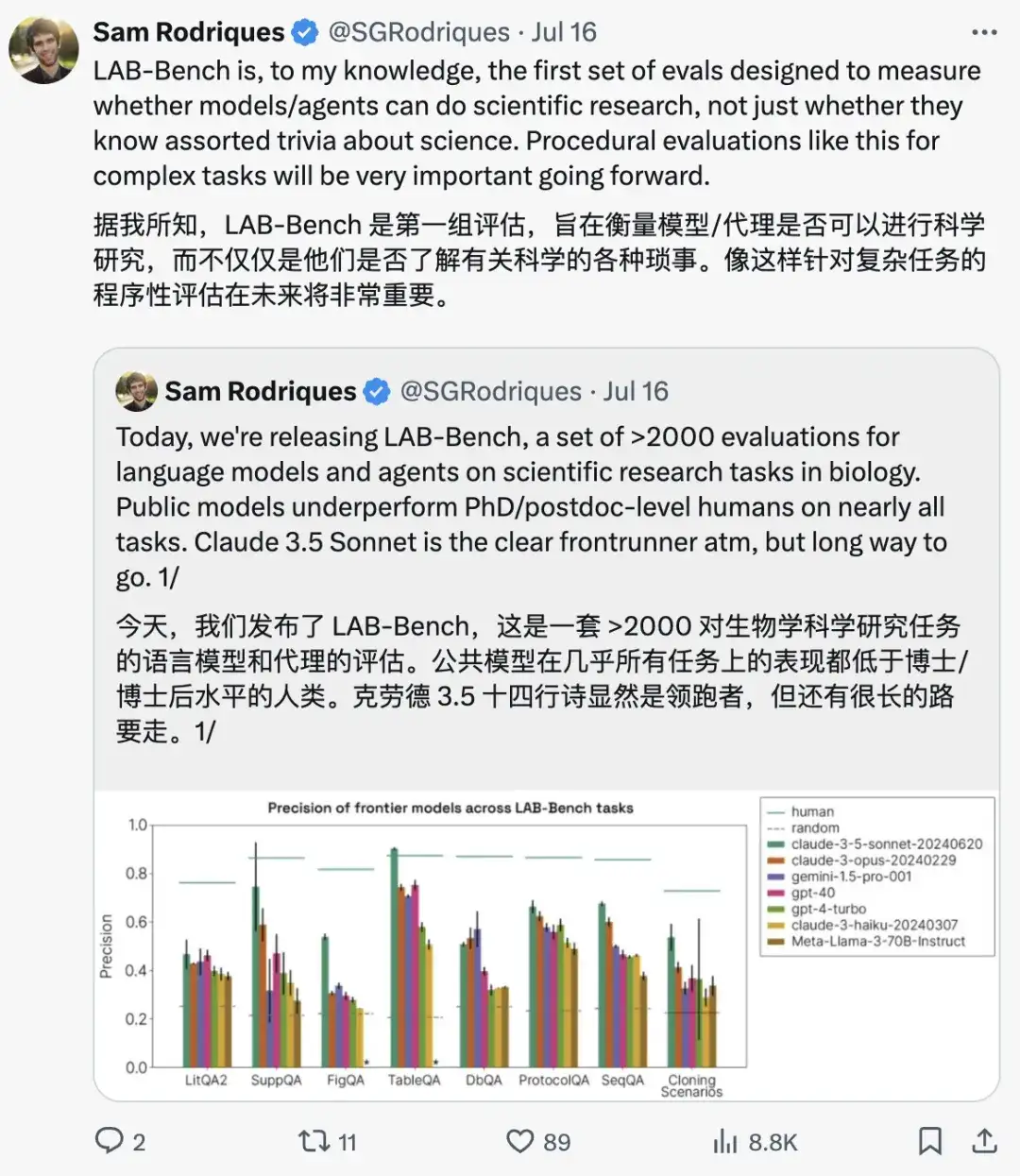
Voici des exemples de questions provenant de différentes catégories de LAB-Bench :
Exploration minière profonde pour évaluer la capacité du modèle à récupérer et à raisonner sur la littérature
Évaluer les capacités de récupération et de raisonnement de différents modèles dans la littérature scientifique,Les sous-ensembles LAB-Bench les plus couramment utilisés correspondent aux tâches LitQA2, SuppQA et DbQA. Ces trois types conviennent à différents aspects de la génération d’amélioration de la recherche scientifique (RAG).
*La génération augmentée par récupération (RAG) est une technique qui utilise des informations provenant de sources de données privées ou propriétaires pour aider à la génération de texte.
Le benchmark LitQA2 mesure la capacité des modèles à récupérer des informations à partir de la littérature scientifique.Il s'agit de questions à choix multiples dont les réponses n'apparaissent généralement qu'une seule fois dans la littérature scientifique et ne peuvent être répondues à partir des informations contenues dans le résumé (c'est-à-dire que la littérature scientifique est relativement nouvelle). Dans ce processus, les chercheurs ont non seulement besoin que le modèle soit capable de répondre aux questions en rappelant les données de formation, mais ils ont également besoin que le modèle ait accès à la littérature et à des capacités de raisonnement.
SuppQA exige que le modèle trouve et interprète les informations contenues dans les documents supplémentaires d'un article.Les chercheurs ont précisé que pour répondre à ces questions, le modèle doit accéder à des informations dans certains fichiers supplémentaires.
Les problèmes DbQA nécessitent des modèles pour accéder et récupérer des informations à partir de bases de données générales spécifiques à la biologie.Ces questions sont conçues pour couvrir un large éventail de sources de données, et il n’est pas possible pour le modèle ou l’agent de répondre à toutes les questions à l’aide d’une seule API.
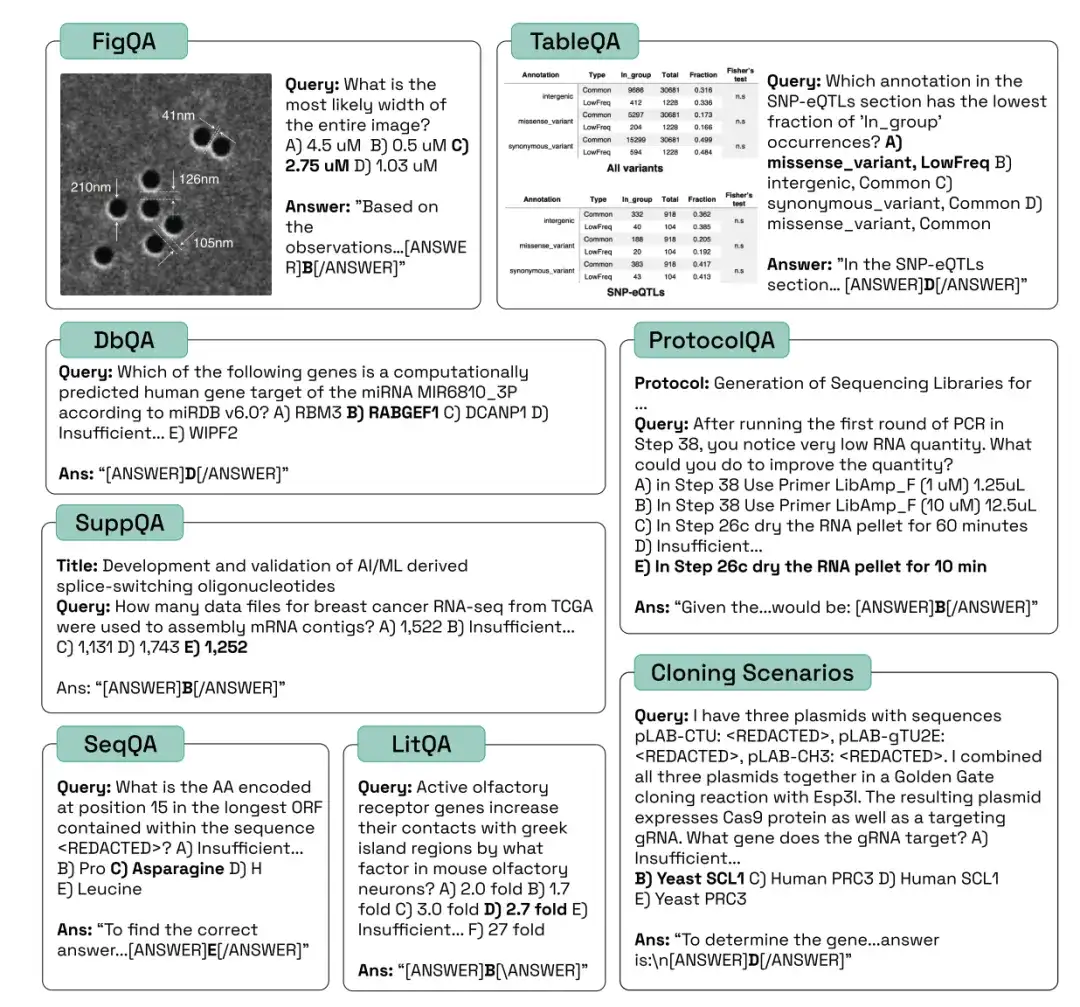
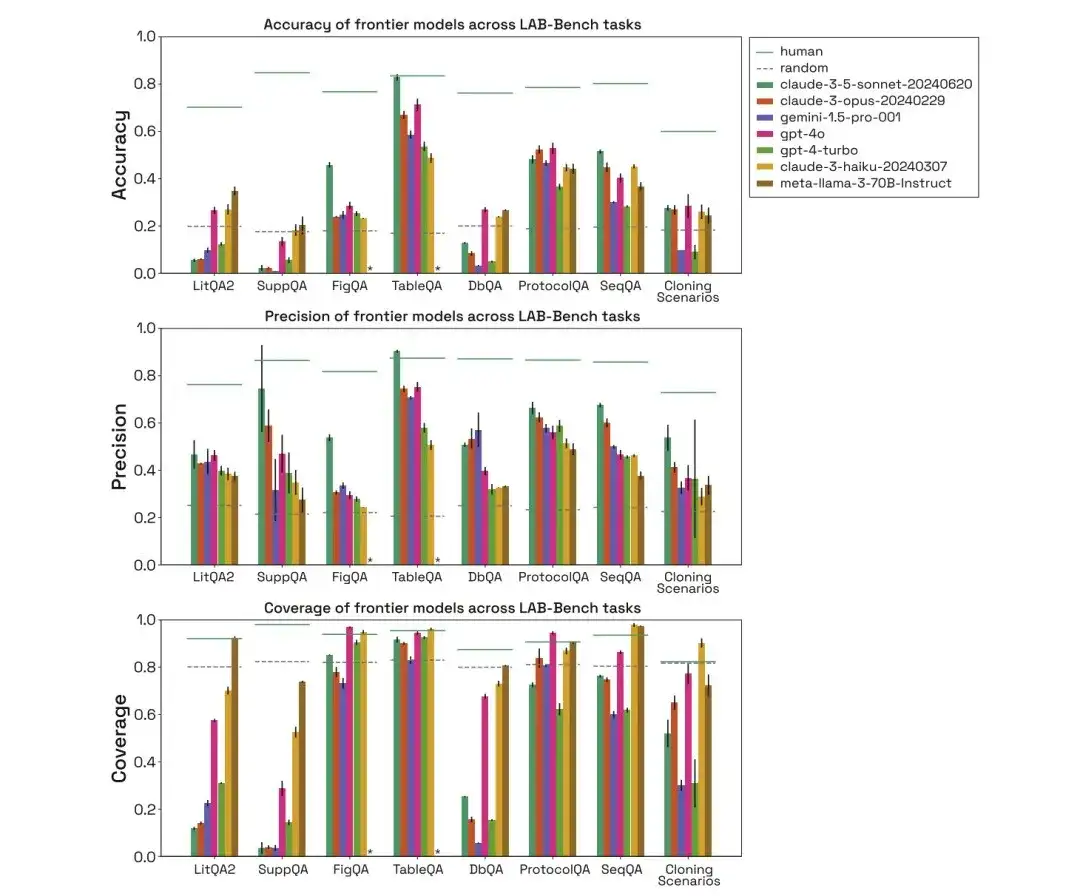
Comme le montre la figure ci-dessous, les chercheurs ont évalué les performances des tâches de référence biologiques humaines, aléatoires, claude-3-5-sonnet-20240620, claude-3-opus-20240229, gemini-1.5-pro-001, gpt-4o, gpt-4-turbo, claude-3-haiku-20240307 et meta-llama-3-70B-Instruct dans les trois catégories ci-dessus, et ont comparé leur exactitude, leur précision et leur couverture.
Dans le test LitQA2, tous les modèles ont obtenu des résultats similaires dans la catégorie de rappel de la littérature LitQA2, avec des scores bien supérieurs aux attentes aléatoires, atteignant plus de 40%. Cependant, les modèles traditionnels refusent souvent de répondre, et certains répondent même à un rythme inférieur à celui du 20%, ce qui fait que la précision de ces modèles est bien inférieure aux niveaux aléatoires.
*Pour chaque question, le modèle dispose d'une option spécifique pour refuser de répondre en raison d'informations insuffisantes
Lors du test SuppQA, tous les modèles ont obtenu de mauvais résultats et présentaient la couverture globale la plus faible. Cela est dû au fait que les modèles sont invités à récupérer des informations dans les documents supplémentaires, ce qui indique que les informations supplémentaires de l’article peuvent ne pas être aussi représentatives que le texte principal de l’ensemble de formation du modèle.
Dans les questions DbQA, la couverture du modèle est inférieure à l'espérance aléatoire, ce qui signifie que le modèle refuse souvent de répondre aux questions DbQA, ce qui entraîne une faible précision.
SeqQA, une référence pour explorer l'utilité de l'IA dans l'interprétation des séquences biologiques
Pour évaluer la capacité du modèle à interpréter les séquences biologiques,La tâche SeqQA correspondante dans l'ensemble de données de référence LAB-Bench est utilisée. Il couvre diverses propriétés de séquence, des tâches pratiques courantes dans le flux de travail de la biologie moléculaire et la compréhension et l'interprétation des relations entre les séquences d'ADN, d'ARN et de protéines.
Dans la tâche SeqQA, l’évaluation des modèles humains, aléatoires et différents montre que le modèle peut répondre à la plupart des questions SeqQA. La précision de chaque modèle est comprise entre 40% et 50%, ce qui est bien supérieur aux attentes aléatoires. Cela montre que le modèle a la capacité de raisonner sur l’ADN, les séquences de protéines et les tâches de biologie moléculaire.
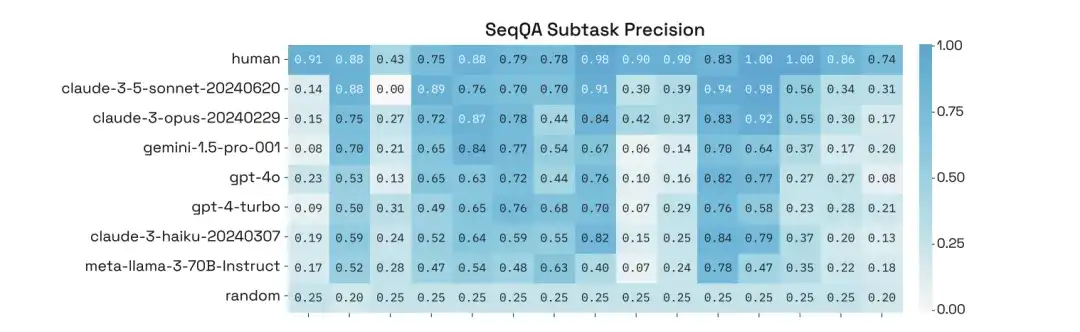
De plus, les chercheurs ont mené une analyse approfondie de leurs performances sur des sous-tâches spécifiques de SeqQA et ont constaté que la précision des modèles sur différentes sous-tâches variait considérablement, certaines tâches atteignant même une précision de plus de 90%.
Des graphiques aux protocoles, évaluation des capacités de raisonnement de base des modèles
Pour évaluer la capacité de raisonnement de base du modèle,Ceux utilisés sont FigQA, TableQA et ProtocolQA.
dans,FigQA mesure la capacité des LLM à comprendre et à raisonner sur des graphiques scientifiques.Les questions FigQA contiennent uniquement des images de figures, sans autres informations telles que les titres des figures ou le texte du document. La plupart des problèmes nécessitent que le modèle intègre plusieurs éléments d’information dans le graphique, ce qui nécessite que le modèle ait des capacités multimodales.
TableQA mesure la capacité à interpréter les données des tableaux papier.Les questions contiennent uniquement des images de tableaux extraits du document, sans autres informations telles que les légendes des figures, le titre du document, etc. Le problème nécessite que le modèle non seulement trouve des informations dans le tableau, mais également qu'il raisonne ou traite les informations du tableau, ce qui nécessite également que le modèle ait des capacités multimodales.
Les questions ProtocolQA sont conçues sur la base de protocoles publiés.Ces protocoles sont modifiés ou des étapes sont omises pour introduire des erreurs, et les questions posent ensuite des résultats hypothétiques du protocole modifié et demandent quelles étapes doivent être modifiées ou ajoutées pour « corriger » le protocole afin de produire le résultat attendu.
Grâce à l'évaluation de modèles humains, aléatoires et différents, on peut constater que dans le test FigQA, les performances du modèle Claude 3.5 Sonnet sont bien supérieures à celles des autres modèles, indiquant qu'il a une meilleure capacité à expliquer et à raisonner sur le contenu de l'image.
Dans le test TableQA, tous les modèles ont une couverture élevée, ce qui indique que TableQA est la tâche la plus simple. De plus, Claude 3.5 Sonnet fonctionne à nouveau très bien, surpassant même les performances humaines en termes de précision et égalant la précision humaine.
Dans la tâche ProtocolQA, les modèles fonctionnent de manière comparable, avec une précision concentrée autour de 50-60%. Les modèles répondent aux questions de protocole avec une couverture assez élevée car les modèles n'ont pas besoin d'effectuer de recherches explicites mais proposent simplement une solution basée sur les données de formation.
41 scénarios de test de clonage, biologistes assistés par l'IA dans l'exploration future
Pour comparer les performances du modèle avec celles des humains sur des tâches difficiles,Les chercheurs ont introduit un ensemble de tests de 41 scénarios de clonage, comprenant plusieurs plasmides, fragments d’ADN, flux de travail en plusieurs étapes, etc.Ces scénarios sont des problèmes à plusieurs étapes et à choix multiples qui constituent un défi pour les humains.Si un système d’IA atteint une grande précision dans le test du scénario de clonage, on peut considérer que le système d’IA peut devenir un excellent assistant pour les biologistes moléculaires humains.
Grâce à l'évaluation de modèles humains, aléatoires et différents, on peut constater que les performances du modèle dans le scénario de clonage sont également bien inférieures à celles des humains, et que la couverture de Gemini 1.5 Pro et GPT-4-turbo est faible. De plus, même lorsque les modèles sont capables de répondre correctement aux questions, on suppose qu’ils sont arrivés à la bonne réponse en éliminant les éléments de distraction puis en faisant une supposition.
En résumé, dans les tâches LAB-Bench, les différents modèles fonctionnent de manière très différente, refusant souvent de répondre aux questions en raison du manque d'informations, en particulier dans les tâches qui nécessitent explicitement une recherche d'informations. De plus, les modèles sont peu performants dans les tâches qui nécessitent le traitement de séquences d’ADN et de protéines, en particulier de sous-séquences ou de longues séquences. Dans les tâches de recherche réelles, les humains obtiennent de bien meilleurs résultats que les modèles.
* Ensemble de données de référence en biologie du modèle de langage LAB Bench :
Les ensembles de données ci-dessus sont recommandés par HyperAI dans ce numéro. Si vous voyez des ressources de jeux de données de haute qualité, n'hésitez pas à laisser un message ou à soumettre un article pour nous le faire savoir !
Références :








