Command Palette
Search for a command to run...
Qwen3-Max Dispose De Plus d'un Billion De Paramètres, Atteignant Le SOTA Sur Plusieurs Benchmarks, Et Une Version Améliorée Par Inférence Prédite Obtenant Un Score Parfait À l'Olympiade mathématique.

Aujourd'hui (24 septembre), la conférence annuelle Yunqi s'est officiellement ouverte. Sur cette scène où Alibaba Cloud démontre sa puissance, l'IA est incontestablement le protagoniste. Des modèles open source aux applications d'agents, en passant par les infrastructures telles que les serveurs et l'écosystème des développeurs, elle a pleinement démontré sa compétitivité technologique lors de cette étape de compétition en IA.Selon la liste Hugging Face, le nombre de modèles dérivés développés sur la base de Tongyi Qianwen a atteint 170 000, dépassant la série American Llama et se classant au premier rang mondial.
Les lecteurs qui suivent Alibaba savent peut-être qu'un jour seulement avant l'ouverture de la conférence Yunqi, l'équipe Tongyi Big Model d'Alibaba avait déjà publié en open source trois modèles hautes performances : le grand modèle omnimodal natif Qwen3-Omni, le modèle de génération vocale Qwen3-TTS et le modèle d'édition d'images Qwen-Image-Edit-2509. Tous ont atteint des performances comparables aux modèles traditionnels, voire au niveau SOTA, dans leurs domaines respectifs.
Il semblerait que ce ne soient que des amuse-gueules. Lors de la cérémonie d'ouverture de la conférence Yunqi qui vient de s'achever, le Qwen3-Max a été officiellement dévoilé. Ce modèle est considéré comme le plus grand et le plus puissant à ce jour. Avec un paramètre total de 1 T, il a raflé de nombreux tests de performance. De plus,La conférence a également présenté des modèles tels que Qwen3-VL et Qwen3-Coder.
Qwen3-Max : le plus grand et le plus puissant à ce jour
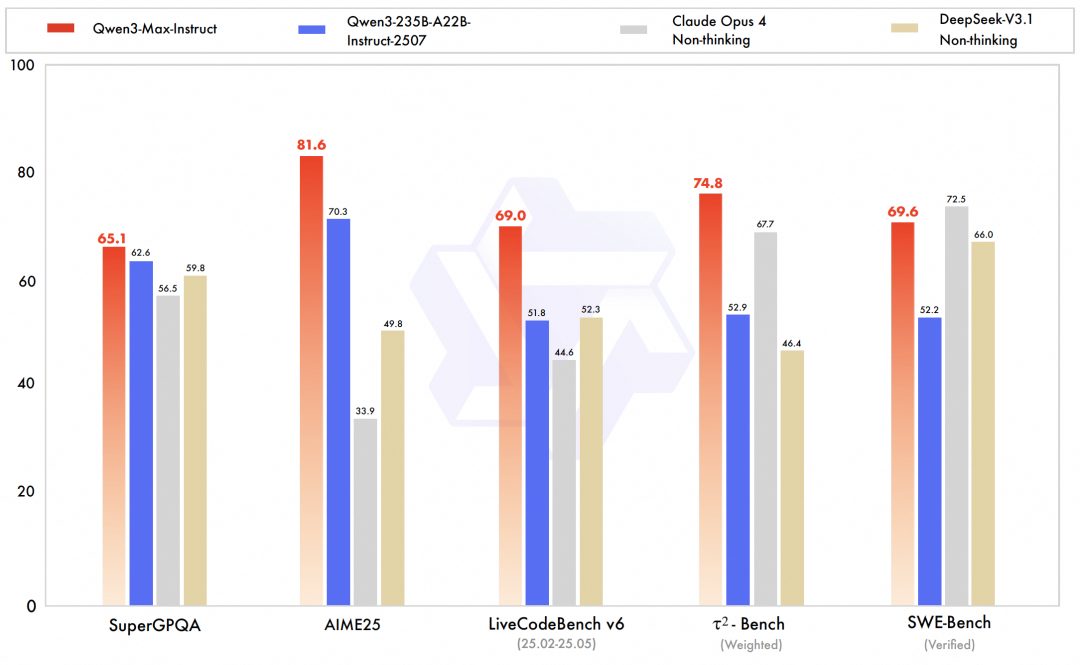
Qwen3-Max est incontestablement le point fort de cette version. Modèle le plus grand et le plus performant de l'équipe à ce jour, la version préliminaire de Qwen3-Max-Instruct s'est classée troisième au classement textuel de LMArena, surpassant GPT-5-Chat.La version officielle améliore encore les capacités de code et les capacités de l'agent, atteignant le niveau SOTA dans des tests de référence complets couvrant les connaissances, le raisonnement, la programmation, le suivi des instructions, l'alignement des préférences humaines, les tâches d'agent intelligent et la compréhension multilingue.Par exemple, Qwen3-Max-Instruct a obtenu un excellent score de 69,6 points lors du benchmark SWE-Bench Verified, qui vise à résoudre des problèmes de programmation concrets. Lors du benchmark Tau2-Bench, qui évalue les capacités d'appel d'outils des agents intelligents, Qwen3-Max-Instruct a surpassé Claude Opus 4 et DeepSeek-V3.1 avec un score de 74,8 points.
Plus précisément, les paramètres totaux du modèle Qwen3-Max dépassent 1T et 36T de jetons sont utilisés pour la pré-formation.L'architecture du modèle suit la conception du modèle MoE de la série Qwen3 et utilise l'équilibrage de charge global par lots, garantissant une perte pré-apprentissage stable et fluide. L'apprentissage est fluide, sans pics de perte ni ajustements tels que les retours en arrière ou les modifications de la distribution des données.
Selon la présentation officielle, grâce à l'optimisation de la stratégie efficace de pipeline parallèle multi-étapes de PAI-FlashMoE, l'efficacité d'apprentissage de Qwen3-Max-Base a été considérablement améliorée, et son MFU a été amélioré de 30% par rapport à Qwen2.5-Max-Base. Dans le scénario d'apprentissage de séquences longues, l'équipe a également utilisé la stratégie ChunkFlow pour obtenir un gain de débit trois fois supérieur à celui de la solution de séquences parallèles, prenant en charge l'apprentissage de Qwen3-Max avec un contexte long de 1M. Parallèlement, grâce à divers outils tels que SanityCheck, EasyCheckpoint et l'optimisation des liens de planification,La perte de temps causée par une panne matérielle dans Qwen3-Max sur un cluster à grande échelle est réduite à un cinquième de celle de Qwen2.5-Max.
Il convient de mentionner que bien que la version Qwen3-Max-Thinking à raisonnement amélioré n'ait pas été officiellement annoncée, selon les données publiées par l'équipe, ses capacités de raisonnement profond ont atteint un nouveau sommet, obtenant la note maximale sur les critères de raisonnement mathématique extrêmement difficiles AIME 25 et HMMT, et même atteignant la note maximale au concours olympique de mathématiques.
Qwen3-VL-235B : SOTA rafraîchissant et classé premier au monde
Qwen3-VL est une branche du modèle vision-langage (VLM) multimodal de la série Qwen3. Il vise à équilibrer et à révolutionner la compréhension visuelle et la génération de texte. L'équipe le considère comme le modèle vision-langage le plus puissant de la série Qwen à ce jour. Qwen3-VL démontre des améliorations significatives dans la compréhension et la génération de texte pur, la perception et le raisonnement sur le contenu visuel, la prise en charge de la longueur du contexte, la compréhension des relations spatiales et de la vidéo dynamique, et même dans ses performances lors des interactions avec les agents.
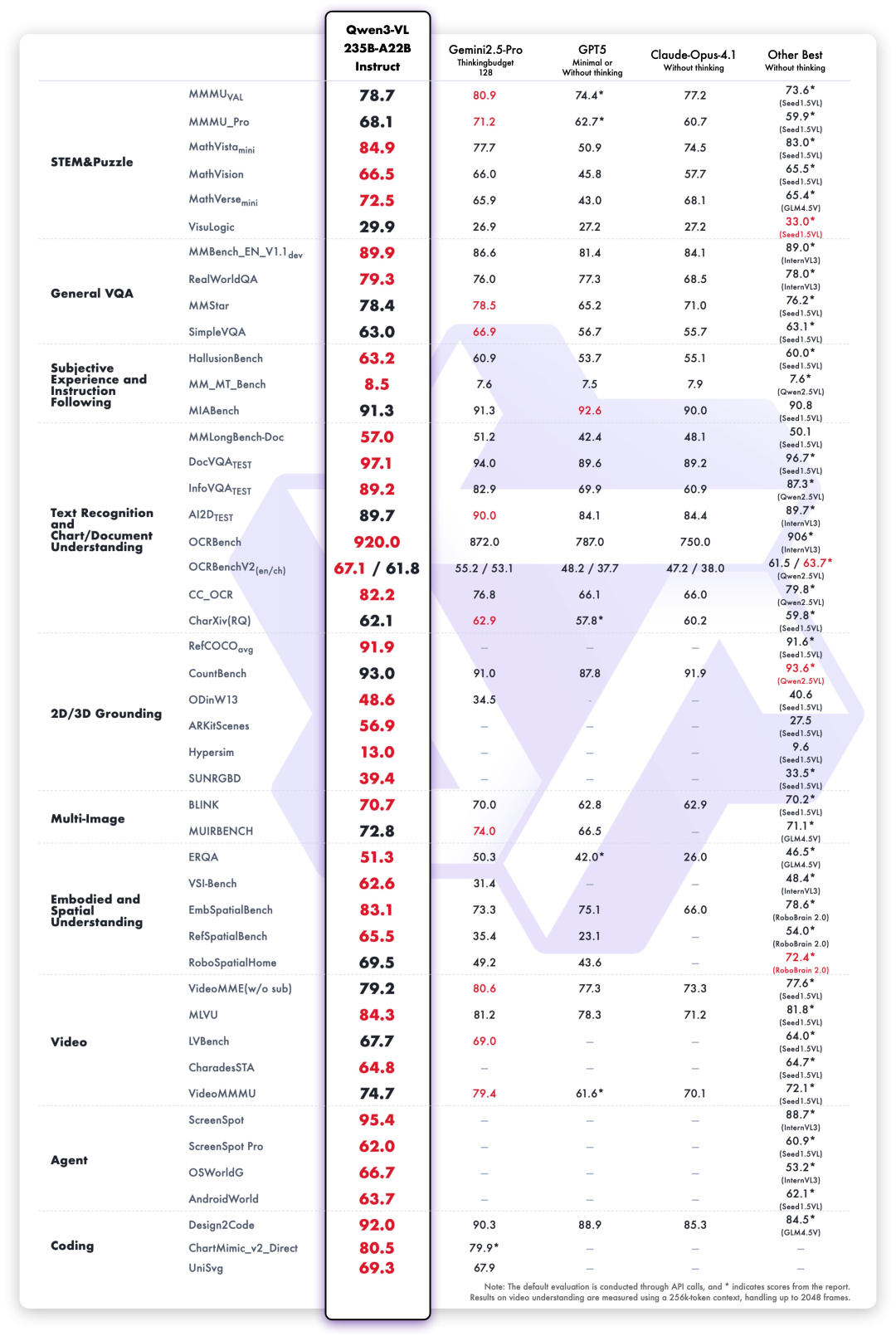
Le nouveau modèle phare open source Qwen3-VL-235B sorti cette fois-ci est classé premier au monde en termes de performances globales et a considérablement amélioré ses performances dans les images complexes haute définition et les scènes de reconnaissance à grain fin.Il comprend les versions Instruction et Réflexion.
Dans le cadre de l'évaluation de 10 dimensions incluant des questions universitaires complètes, le raisonnement mathématique et scientifique, les énigmes logiques, les réponses aux questions visuelles générales, l'expérience subjective et le suivi des instructions, la reconnaissance de texte multilingue et l'analyse de documents graphiques,Qwen3-VL-235B-A22B-Instruct obtient les meilleurs résultats dans la plupart des indicateurs parmi les modèles de non-inférence.Il surpasse considérablement les modèles à source fermée tels que Gemini 2.5 Pro et GPT-5, tout en actualisant les meilleurs résultats des modèles multimodaux open source, démontrant sa forte capacité de généralisation et ses performances complètes dans les tâches visuelles complexes.
Plus précisément, Qwen3-VL a subi des mises à niveau systématiques dans plusieurs dimensions de capacités clés :
Agent visuel :Qwen3-VL peut exploiter les interfaces d'ordinateurs et de téléphones portables, identifier les éléments de l'interface utilisateur graphique (GUI), comprendre les fonctions des boutons, appeler des outils et exécuter des tâches. Il a atteint des niveaux de référence mondiaux lors de benchmarks tels qu'OS World et peut améliorer efficacement ses performances dans les tâches de perception fine en appelant des outils.
Les capacités de texte brut rivalisent avec celles des meilleurs modèles de langage :Qwen3-VL utilise des modalités mixtes textuelles et visuelles pour un entraînement collaboratif dès les premières phases de pré-apprentissage, renforçant ainsi continuellement ses capacités textuelles. Ses performances sur les tâches textuelles pures sont comparables à celles du modèle phare Qwen3-235B-A22B-2507. Il s'agit d'un modèle de langage visuel de nouvelle génération, doté d'une base textuelle solide et d'une polyvalence multimodale.
Les capacités de codage visuel ont été grandement améliorées :Implémentez du code de génération d'images et de vidéos. Par exemple, lorsque vous visualisez un dessin, le code génère du code Draw.io/HTML/CSS/JS, appliquant ainsi la programmation visuelle « ce que vous voyez est ce que vous obtenez ».
La capacité de perception spatiale est grandement améliorée :L'ancrage 2D passe des coordonnées absolues aux coordonnées relatives, facilitant ainsi l'évaluation de l'orientation des objets, les changements de perspective et les relations d'occlusion. Il permet d'obtenir un ancrage 3D et de poser les bases du raisonnement spatial et de la représentation de scènes incarnées dans des scénarios complexes.
Prise en charge du contexte long et compréhension de la vidéo longue :L'ensemble de la famille de modèles prend en charge nativement une longueur de contexte de 256 000 jetons et est extensible jusqu'à 1 million de jetons. Ainsi, qu'il s'agisse d'un document technique de plusieurs centaines de pages, d'un manuel complet ou d'une vidéo de deux heures, il peut être saisi, mémorisé et récupéré avec précision, permettant une localisation vidéo précise à la seconde près.
La capacité de réflexion multimodale est considérablement améliorée :Le modèle de réflexion privilégie les compétences STEM et le raisonnement mathématique. Face à des questions spécialisées, le modèle saisit les détails, décrypte les complexités, analyse les relations de cause à effet et fournit des réponses logiques et fondées. Il a obtenu des résultats exceptionnels lors d'évaluations de référence telles que MathVision, MMMU et MathVista.
Les capacités de perception et de reconnaissance visuelles ont été considérablement améliorées : en optimisant la qualité et l'étendue des données de pré-formation, le modèle peut désormais reconnaître une gamme plus riche de catégories d'objets, des célébrités, des personnages d'anime, des produits de base, des monuments, des plantes et des animaux, couvrant ainsi les besoins de « reconnaissance de tout » de la vie quotidienne et des domaines professionnels.
L'OCR prend en charge davantage de langues et de scénarios complexes :Le nombre de langues prises en charge autres que le chinois et l'anglais a été étendu de 10 à 32, couvrant davantage de pays et de régions ; les performances sont plus stables dans des scénarios de prise de vue réels difficiles tels que l'éclairage complexe, le flou et l'inclinaison ; la précision de reconnaissance des caractères rares, des caractères anciens et des termes professionnels a également été considérablement améliorée ; et la capacité à comprendre des documents ultra-longs et à restaurer des structures fines a été encore améliorée.
Qwen3 Coder Plus :Efficacité de la programmationPlus haut et plus précis
Modèle de codage exclusif de la série Qwen3, Qwen3 Coder est une mise à niveau complète de la génération précédente. Il adopte une API fermée pour une programmation plus efficace et plus précise. Il est devenu l'un des modèles de programmation les plus populaires au monde et est très apprécié des développeurs.
Le Qwen3 Coder Plus sorti cette fois est une version propriétaire du Qwen3 Coder 480B A35B open source d'Alibaba.En tant que modèle d'agent de codage puissant, il excelle dans la programmation autonome via des appels d'outils et des interactions environnementales, combinant des capacités de codage avec une variété de capacités générales.
Points forts techniques :
* La formation conjointe avec les systèmes Qwen Code et Claude Code améliore considérablement les performances des applications CLI
* Vitesse de raisonnement plus rapide et exécution des tâches plus efficace * Sécurité du code améliorée, évoluant vers une IA responsable
Le site officiel d'HyperAI Hyperneural (hyper.ai) propose plusieurs tutoriels de modèles open source de haute qualité, conçus par l'équipe Tongyi Qianwen. Découvrez le tutoriel de déploiement en un clic : https://hyper.ai/tutorials








