Command Palette
Search for a command to run...
Comment Les Praticiens De L’ia font-ils De La Science ? Université Tsinghua AIR Zhou Hao : Exploration Transfrontalière De La Génération De Texte À La Conception De Protéines

Récemment, lors du forum « IA pour la science » de la Conférence Zhiyuan de Pékin,Zhou Hao, chercheur associé à l'Institut des industries intelligentes de l'Université Tsinghua, a prononcé un discours sur le thème « L'intelligence artificielle générative pour la découverte scientifique ».HyperAI a organisé et résumé le partage approfondi du professeur Zhou Hao sans violer l'intention initiale.

Exploration transfrontalière de la génération de texte à la conception moléculaire
Dans ce discours, le professeur Zhou Hao a principalement développé trois aspects : l'intelligence artificielle générative pour les symboles complexes, les défis rencontrés par la génération de micro-échantillons et le contenu de recherche spécifique actuel.
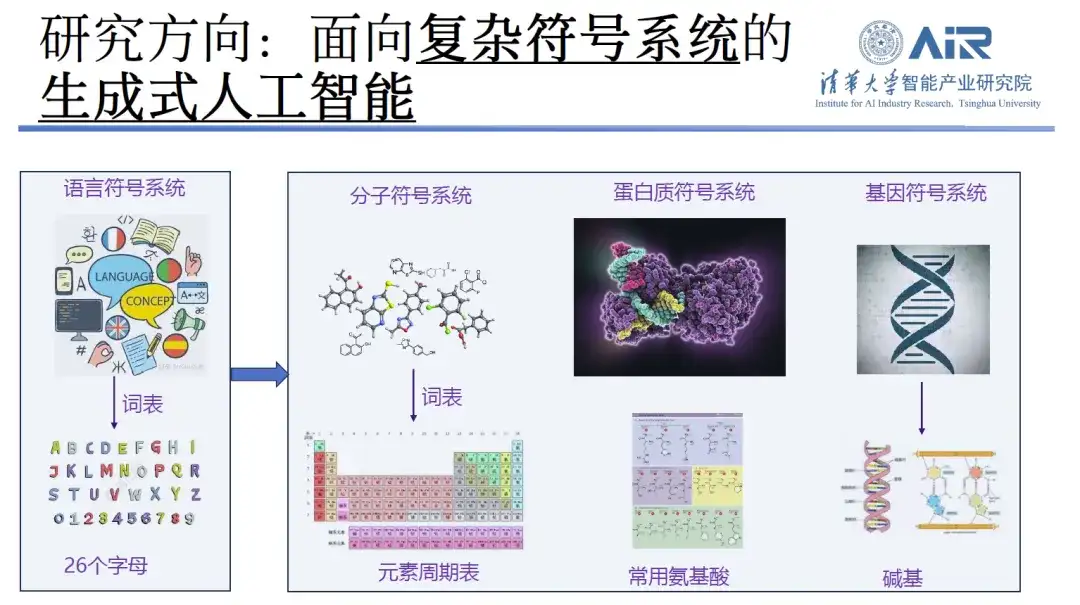
Lors de la présentation de ses axes de recherche, le professeur Zhou Hao a déclaré qu'il s'était engagé dans le traitement du langage naturel, y compris la génération de texte et la traduction automatique, au cours des 10 dernières années. Au cours des deux dernières années,Ses recherches se sont progressivement déplacées de la création de contenu vers la génération de molécules et la conception de protéines.Selon lui, si le travail de traitement de texte du passé est considéré comme un système de symboles linguistiques complexes dans lequel le vocabulaire se compose de 26 lettres, alors le travail actuel équivaut à étendre ces 26 lettres à un plus large éventail de domaines tels que le tableau périodique, les acides aminés, les bases, etc. Son équipe de recherche a accumulé une riche expérience avec ces technologies.

De l'IA centrée sur la création de contenu à l'IA dédiée à la découverte scientifique,Quel est le lien entre les deux ? En fait, l’intelligence artificielle peut générer des images complètes à partir du bruit, et de nombreuses équipes de recherche nord-américaines ont déjà utilisé des méthodes similaires pour concevoir des protéines. En disposant de manière aléatoire les acides aminés d'une protéine dans l'espace, puis en passant par une série de conceptions génératives de 0 à 2 000 étapes, il est possible de concevoir une séquence d'acides aminés qui semble tout à fait raisonnable.
Bien qu'il existe encore certaines limitations quant à la longueur des protéines impliquées dans cette recherche, les résultats de recherches récentes ont considérablement élargi ces limitations et ont également mis en évidence l'énorme potentiel de cette technologie, ce qui peut être une raison importante pour laquelle le professeur Zhou Hao a choisi ce domaine.
Les multiples défis auxquels sont confrontés les praticiens de l'IA lors de la conduite de recherches scientifiques
Par la suite, le professeur Zhou Hao a partagé avec tous les participants les trois principaux défis auxquels est confrontée l'intelligence artificielle (IA pour la science) dans le domaine scientifique du point de vue des praticiens du domaine de l'informatique ou de l'IA.
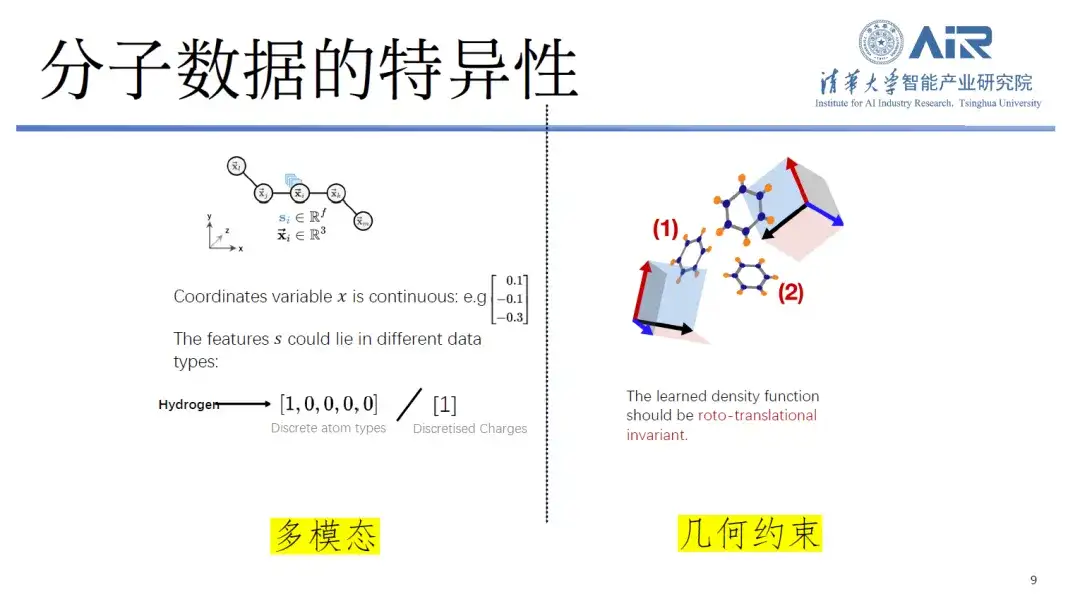
Tout d’abord, la spécificité des données moléculaires.D'une manière générale, le texte et les symboles sont traités comme des éléments discrets et les images sont des signaux continus entre 0 et 1, mais les données moléculaires contiennent à la fois des éléments discrets et continus.
Par exemple, lors du stockage de molécules dans des ordinateurs, les chercheurs les représentent généralement sous forme de coordonnées atomiques et de types atomiques, où les coordonnées atomiques sont continues et les types atomiques sont discrets, formant un type de données multimodales difficiles à traiter. De plus, les molécules ont également des contraintes géométriques, telles que l’invariance à la rotation et à la translation, qui ne sont pas courantes dans le traitement de texte ou d’image.
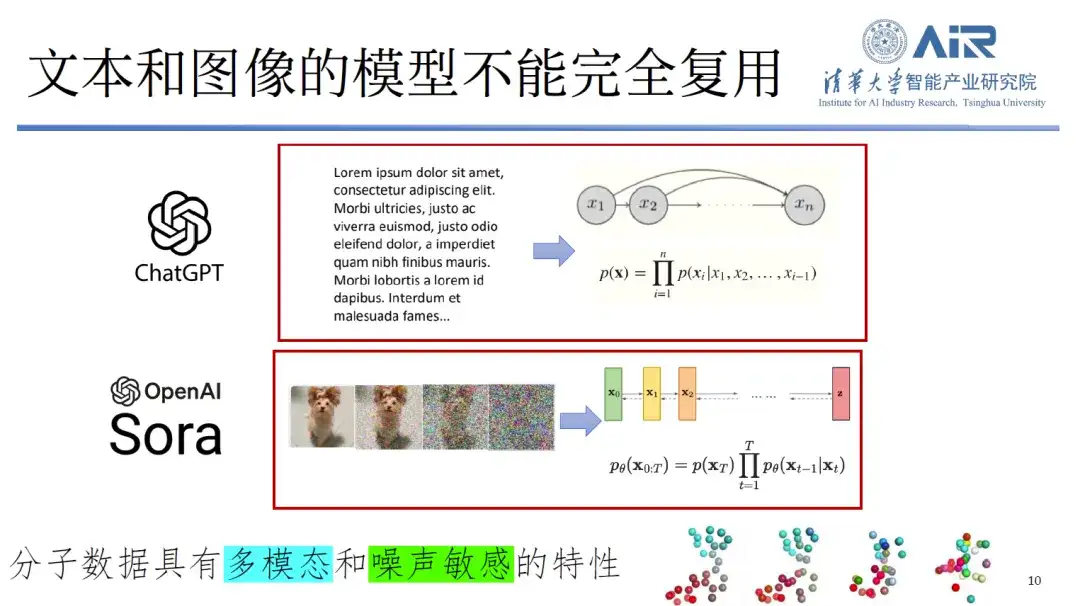
Deuxièmement, les modèles de texte et d’image ne peuvent pas être entièrement réutilisés dans le domaine des protéines.Les données moléculaires ne sont pas seulement multimodales mais également extrêmement sensibles au bruit. Par exemple, si du bruit est ajouté à l’image d’un chien, les gens pourront toujours reconnaître qu’il s’agit d’une image d’un chien. Cependant, si même une petite quantité de bruit est ajoutée aux données moléculaires, il peut être impossible de reconnaître l’identité de la molécule, ce qui entraîne une grande quantité de perte d’informations. Par conséquent, les méthodes de traitement traditionnelles ne sont pas entièrement applicables à ce nouveau type de données.
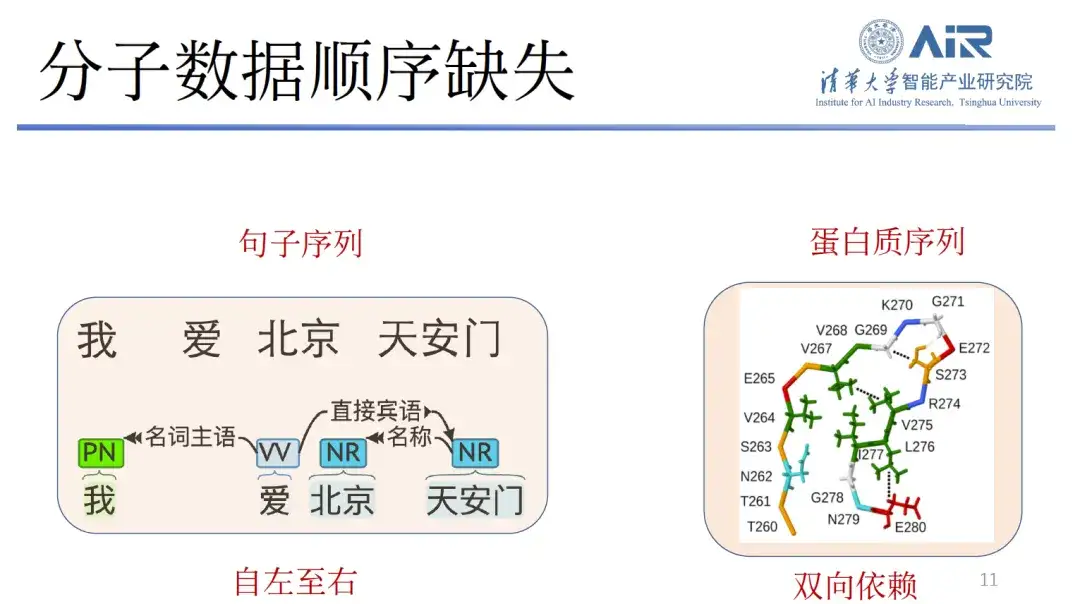
Troisièmement, les données moléculaires manquent dans la séquence.Le texte dépend très peu du sens de gauche à droite, il peut donc générer un nouveau texte de gauche à droite via GPT. Cependant, les protéines ont de très fortes dépendances bidirectionnelles, et leur ordre d’avant en arrière et de gauche à droite est difficile à déterminer. Utiliser directement des modèles de texte ou d’image pour générer des structures moléculaires sera extrêmement difficile.
Afin de répondre aux défis ci-dessus,L'équipe du professeur Zhou Hao a mené des recherches approfondies sur la structure des données, l'algorithme de génération et la construction de base.
À partir de la structure des données, recherchez l'espace de caractérisation intrinsèque des données
Conserver uniquement les degrés de liberté de l'angle dièdre pour reconstruire la représentation de la structure 3D de la molécule
« Comment déterminer l’espace propre d’une molécule ou d’une structure de données cible est un problème que les informaticiens doivent résoudre. »Le professeur Zhou Hao a déclaré que la représentation de la structure tridimensionnelle des molécules est très importante et que l'on peut dire que la structure est une fonction. Dans le passé, les chercheurs obtenaient principalement les informations nécessaires en enregistrant les coordonnées et les types d’atomes pour construire des modèles moléculaires. Cependant, la structure d’une molécule est grande et contient beaucoup d’informations redondantes. Si l’on modélise cela comme cela a été fait dans le passé, d’un point de vue informatique, ce n’est pas une observation dans l’espace propre de la molécule.
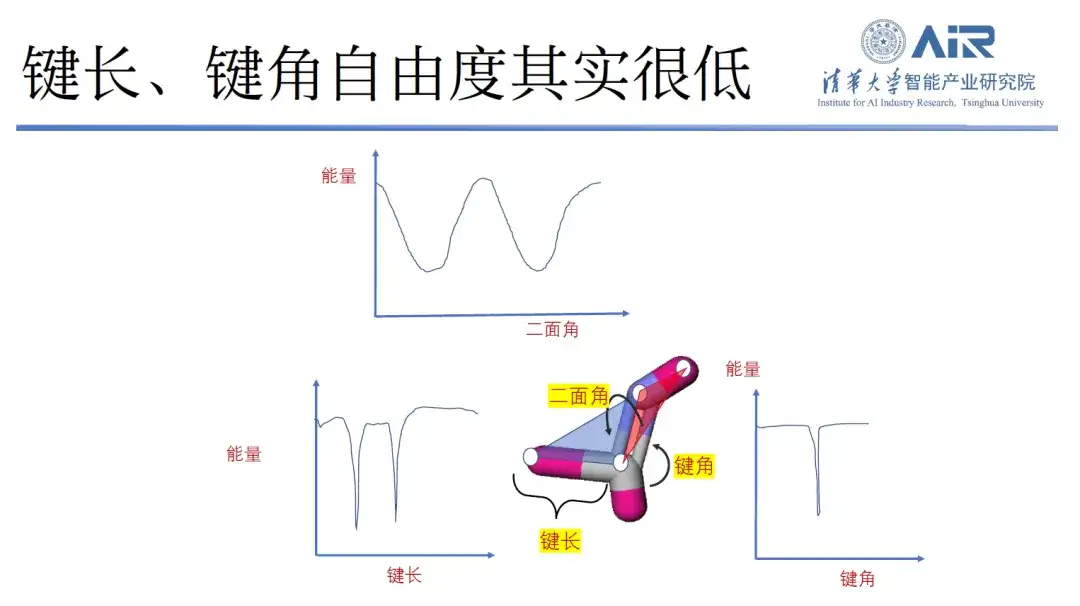
En fait, en analysant la longueur de liaison, l'angle de liaison et l'angle dièdre de la molécule, on peut constater que la longueur de liaison moléculaire et l'angle de liaison ont moins de pics et des degrés de liberté limités, tandis que l'angle dièdre a plus de degrés de liberté. L’équipe du professeur Zhou Hao a donc conçu une nouvelle méthode.Autrement dit, tout en conservant le degré de liberté de l'angle dièdre, les autres degrés de liberté redondants sont supprimés.
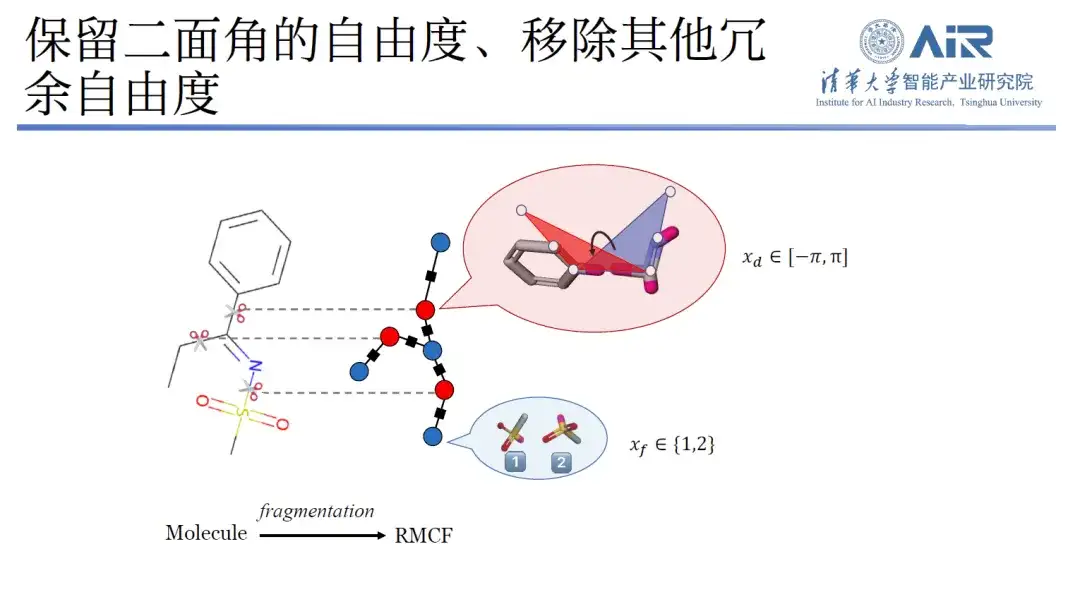
Plus précisément, la recherche peut convertir la structure tridimensionnelle en une représentation bidimensionnelle et, grâce au traitement de fragmentation moléculaire, minimiser les degrés de liberté au sein de chaque molécule et maximiser les degrés de liberté entre les fragments. En utilisant la technologie de programmation dynamique, le problème min-max peut être facilement résolu, puis toutes les molécules peuvent être découpées dans la structure de données cible à l'aide d'un algorithme.
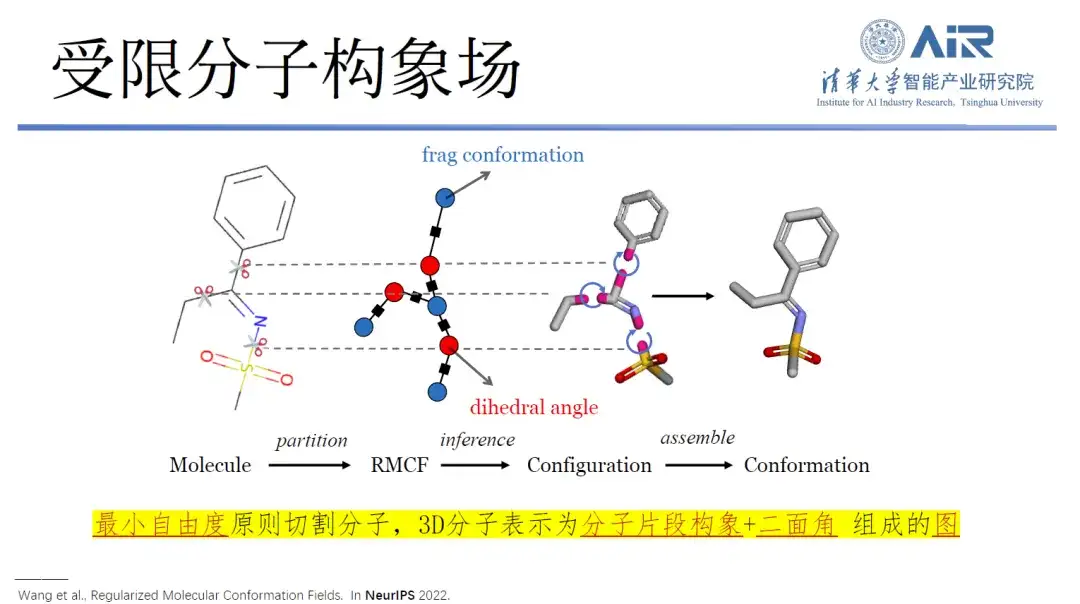
Titre de l'article :Champs de conformation moléculaire régularisés
Lien vers l'article :https://neurips.cc/virtual/2022/poster/53277
« Grâce à cette nouvelle structure de données, si des molécules doivent être générées à l'avenir, la recherche associée permettra de construire l'espace moléculaire avec très peu de données. Cette idée est extrêmement importante ! »
De l'espace réel à l'espace spectral, capture efficace de la géométrie des protéines et des informations chimiques
En plus de la recherche moléculaire, l’équipe du professeur Zhou Hao s’intéresse également à l’étude de la structure et de la fonction des protéines.
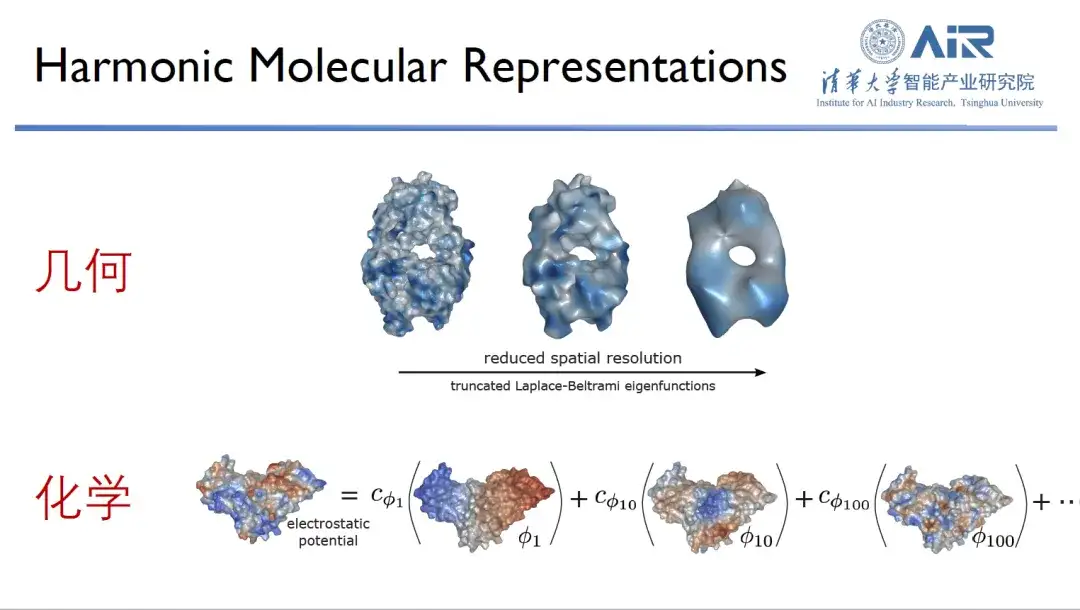
Lorsqu’ils étudient les protéines, les chercheurs les observent généralement sous deux dimensions : les informations géométriques et les informations chimiques. Il est bien connu que la forme et les informations chimiques de surface d’une protéine sont cruciales pour sa fonction, et ce n’est que lorsque les deux se complètent qu’elle peut fonctionner de manière optimale.
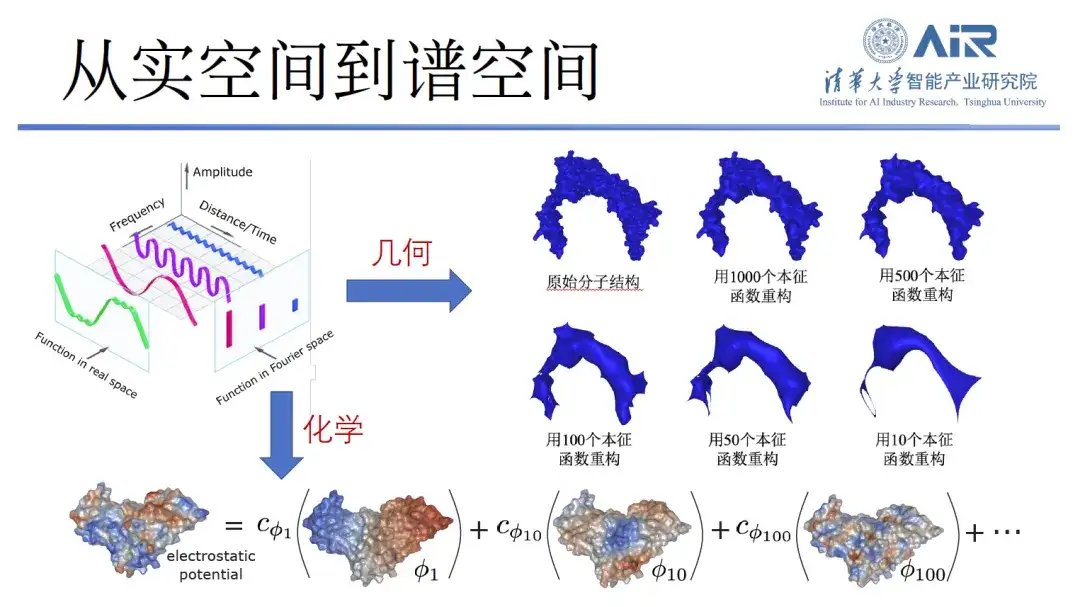
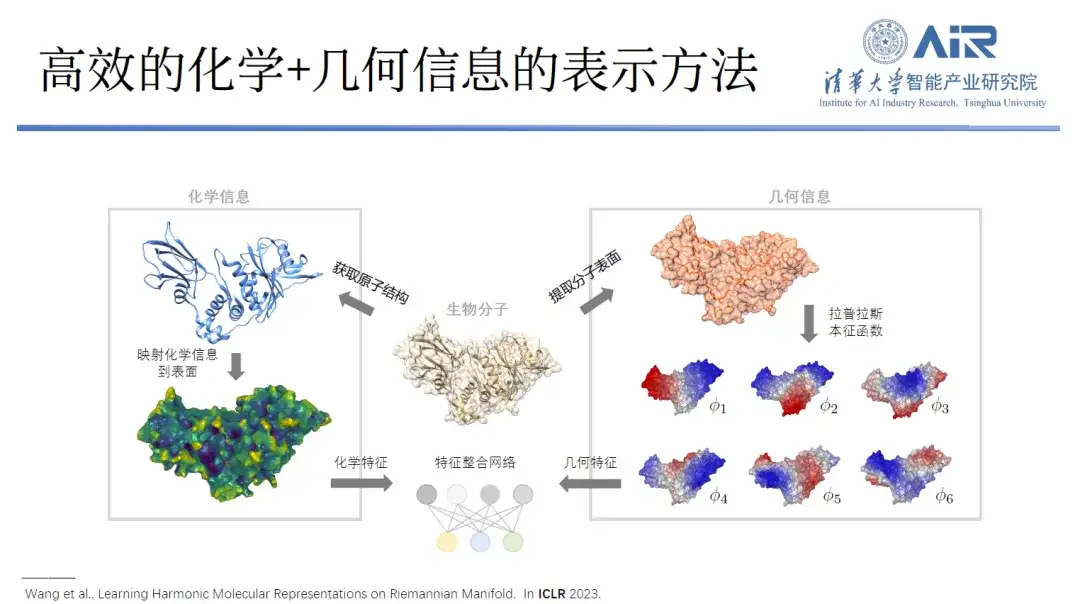
Afin de représenter efficacement les informations chimiques et géométriques des protéines,L'équipe du professeur Zhou Hao a transformé les protéines de l'espace réel vers l'espace spectral, puis a utilisé des fonctions propres pour représenter les protéines. Par exemple, 10 fonctions propres sont utilisées pour capturer les informations basse fréquence d'une protéine, résolvant ainsi son contour général. De plus, davantage de fonctions propres peuvent capturer davantage d’informations à haute fréquence, et en utilisant 1 000 fonctions propres, presque toutes les informations sur les protéines peuvent être capturées.
Titre de l'article :Apprentissage des représentations moléculaires harmoniques sur les variétés riemanniennes
Lien vers l'article :https://iclr.cc/virtual/2023/poster/10900
« L’avantage de cette approche est qu’elle peut reproduire non seulement les informations géométriques de la protéine, mais aussi ses informations chimiques. »Chaque fonction propre peut être considérée comme un nouvel espace, et les informations chimiques sur la surface de la protéine peuvent être mappées sur cet espace propre. Les informations géométriques et chimiques peuvent être exprimées dans le même espace, et le problème complexe de l'espace réel est converti en un problème simple de l'espace spectral.
Conception d'un modèle génératif d'aptamères basé sur un algorithme génératif
Bien que les espaces moléculaires et protéiques les plus compacts et intrinsèques aient été trouvés, la question suivante après avoir identifié avec succès ces espaces est :Comment utiliser l’intelligence artificielle générative pour obtenir efficacement des molécules cibles.
Titre de l'article :MARS : Échantillonnage moléculaire de Markov pour la découverte de médicaments multi-objectifs
Lien vers l'article :https://iclr.cc/virtual/2021/poster/3352
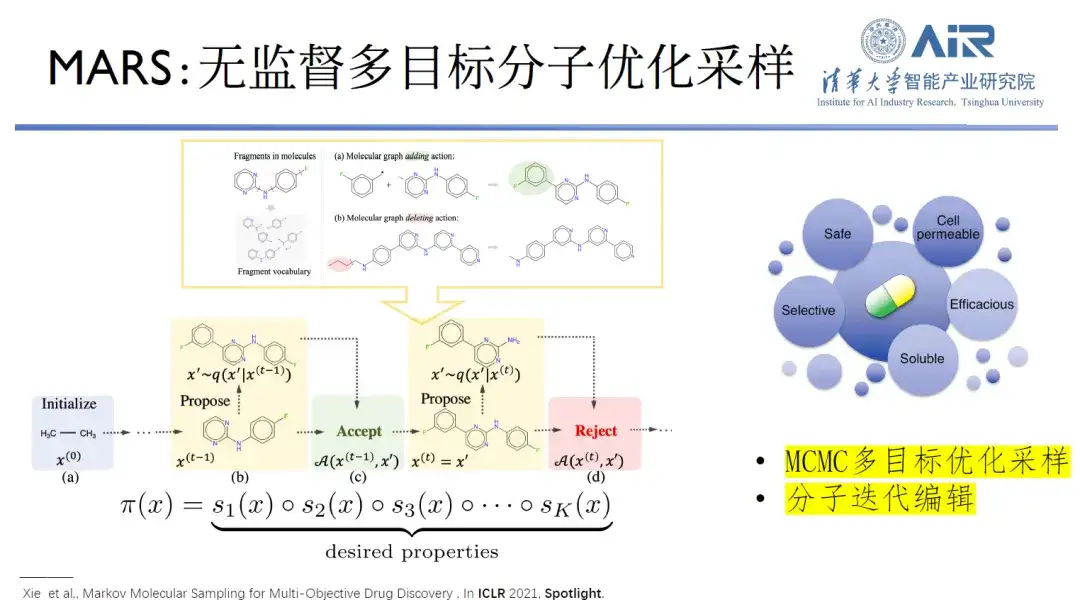
Afin de trouver le modèle de génération moléculaire le plus adapté,L'équipe du professeur Zhou Hao a développé un modèle appelé MARS, qui utilise un échantillonnage d'optimisation moléculaire multi-objectif non supervisé pour effectuer une conception moléculaire 2D. Le processus de conception moléculaire doit répondre à plusieurs objectifs de conception, ce qui constitue un problème d’échantillonnage dans un espace complexe à haute dimension. Le cadre Markov Chain Monte Carlo (MCMC) est utilisé pour éditer des molécules, et n'importe quelle molécule cible peut être générée si des conditions d'équilibre rigoureuses sont respectées.
Titre de l'article :Correspondance de flux équivariant avec transport de probabilité hybride
Lien vers l'article :https://neurips.cc/virtual/2023/poster/70795
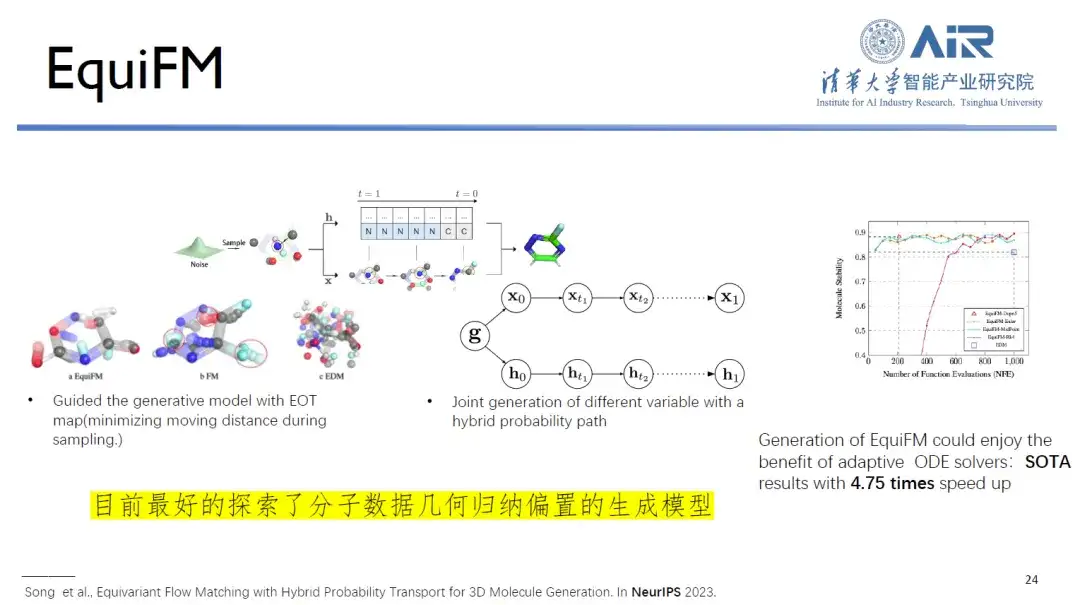
Parallèlement, EquiFM proposé par l’équipe du professeur Zhou Hao est actuellement le meilleur modèle génératif pour explorer le biais inductif géométrique des données moléculaires. Il peut atteindre de bonnes performances dans plusieurs tests de génération moléculaire et la vitesse d'échantillonnage moyenne est augmentée de 4,75 fois.
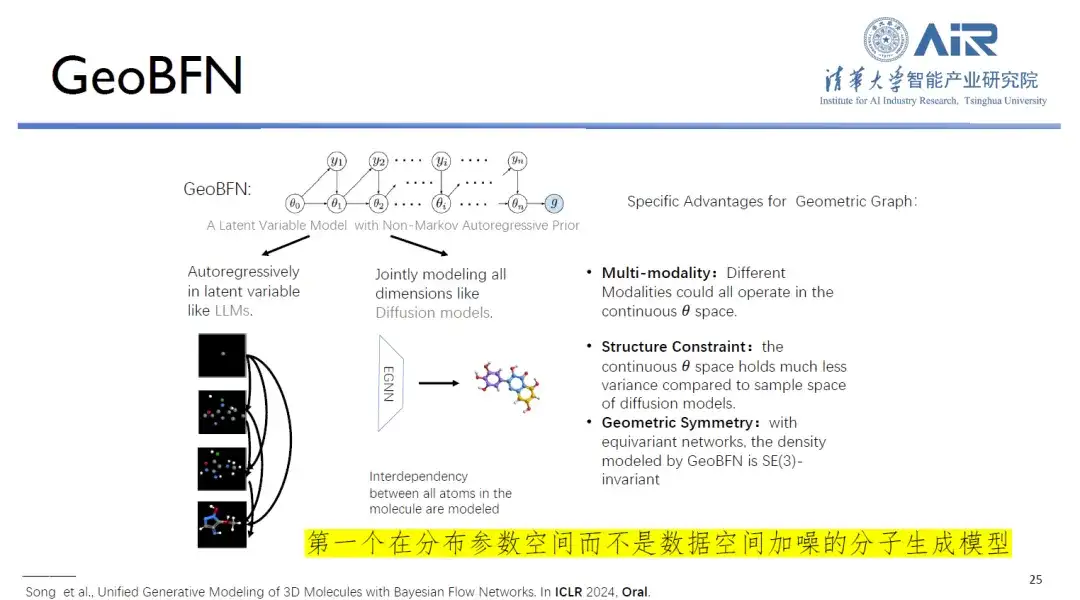
Titre de l'article :Modélisation générative unifiée de molécules 3D via des réseaux de flux bayésiens
Lien vers l'article :https://iclr.cc/virtual/2024/oral/19764
De plus, le cœur du modèle de génération moléculaire GeoBFN est de transformer toutes les données moléculaires de l'espace de données en espace moyenne-variance gaussien, générant ainsi des molécules avec une légitimité élevée et proches de la distribution réelle. À cet égard, le professeur Zhou Hao a déclaré :« Il s’agit actuellement du modèle génératif profond le plus adapté aux molécules et il présente un grand potentiel de développement. »
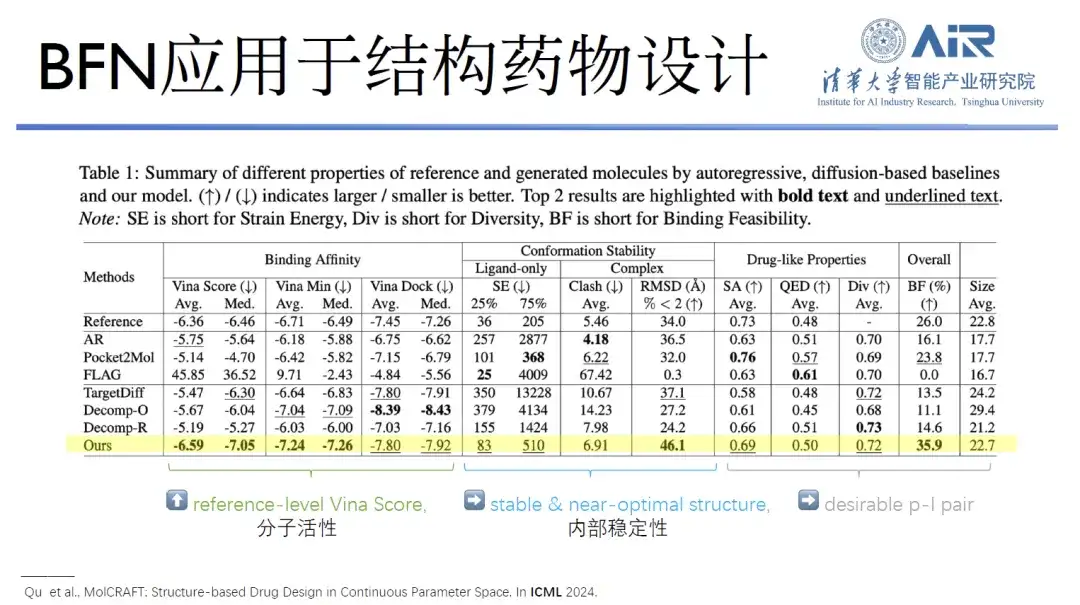
Titre de l'article :MolCRAFT : conception de médicaments basée sur la structure dans un espace paramétrique continu
Lien vers l'article :https://icml.cc/virtual/2024/poster/34336
En plus de ces travaux, l'équipe du professeur Zhou Hao a également publié un article lors de la Conférence internationale sur l'apprentissage automatique (ICML) pour explorer la possibilité d'appliquer GeoBFN à la conception de médicaments basée sur la structure. Les résultats ont montré que les molécules générées à l’aide de ce modèle ont des conformations très stables et une bonne activité.
En commençant par la construction des fondations, établissez une base de pré-formation riche en vastes connaissances sur les données
Enfin, le professeur Zhou Hao a partagé avec tout le monde comment construire une base de pré-formation riche en vastes connaissances de données à partir de la construction de la base.
Dans les recherches existantes, les données expérimentales sur la génération de petites molécules sont très rares, et essayer d’utiliser des méthodes informatiques pour résoudre ce problème est une idée importante.
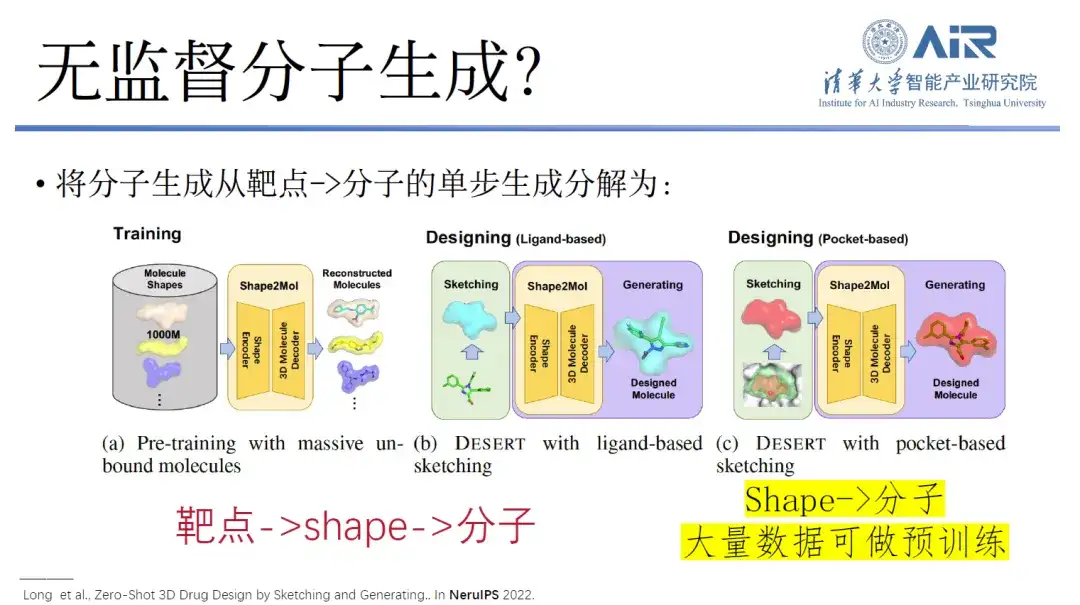
Titre de l'article :Conception de médicaments 3D Zero-Shot par esquisse et génération
Lien vers l'article :https://neurips.cc/virtual/2022/poster/54457
À cet égard, l’équipe du professeur Zhou Hao a proposé une nouvelle idée.Autrement dit, la génération en une seule étape de molécules de la cible à la molécule est décomposée en un processus de la cible à la forme, puis de la forme à la molécule.En fait, bien que la quantité de données allant directement de la cible à la molécule soit faible, la quantité de données allant de la forme à la molécule est très importante. Ces données sont suffisantes pour collecter différentes formes de la cible, puis créer un modèle de pré-formation à très grande échelle, de la forme à la molécule. Enfin, nous pouvons rapidement réaliser la transition de la cible à la molécule, et même parvenir à une conception de molécules médicamenteuses non supervisée ou peu supervisée.
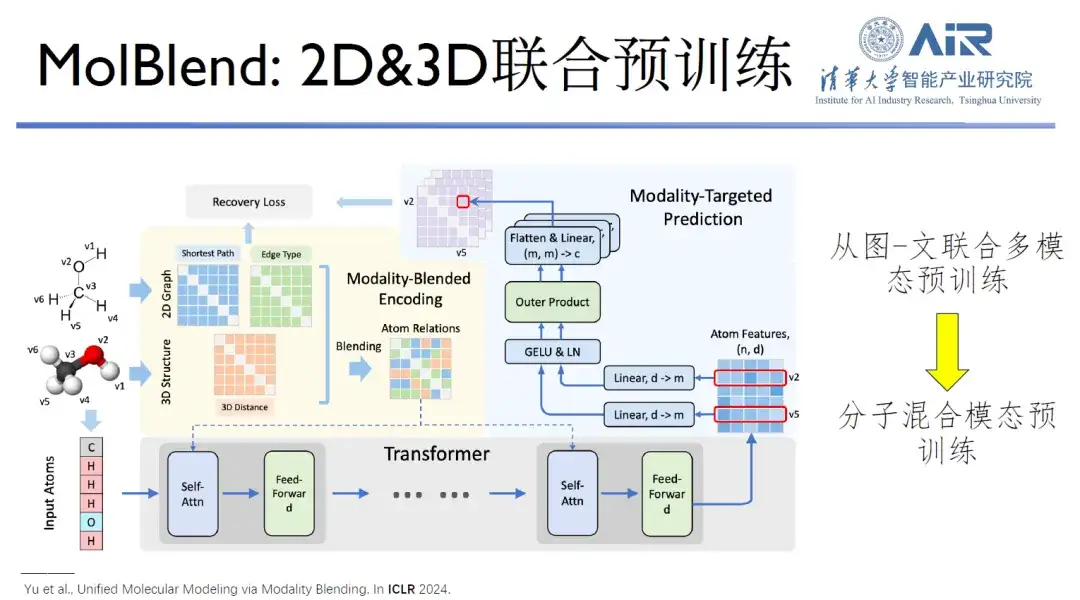
Titre de l'article :Pré-entraînement moléculaire multimodal via le mélange de modalités
Lien vers l'article :https://iclr.cc/virtual/2024/poster/17824
De plus, le modèle MolBlend qu'ils ont proposé réalise le pré-entraînement conjoint de molécules bidimensionnelles et tridimensionnelles, ce qui est un cas typique d'extension du pré-entraînement d'image et de texte au pré-entraînement moléculaire.
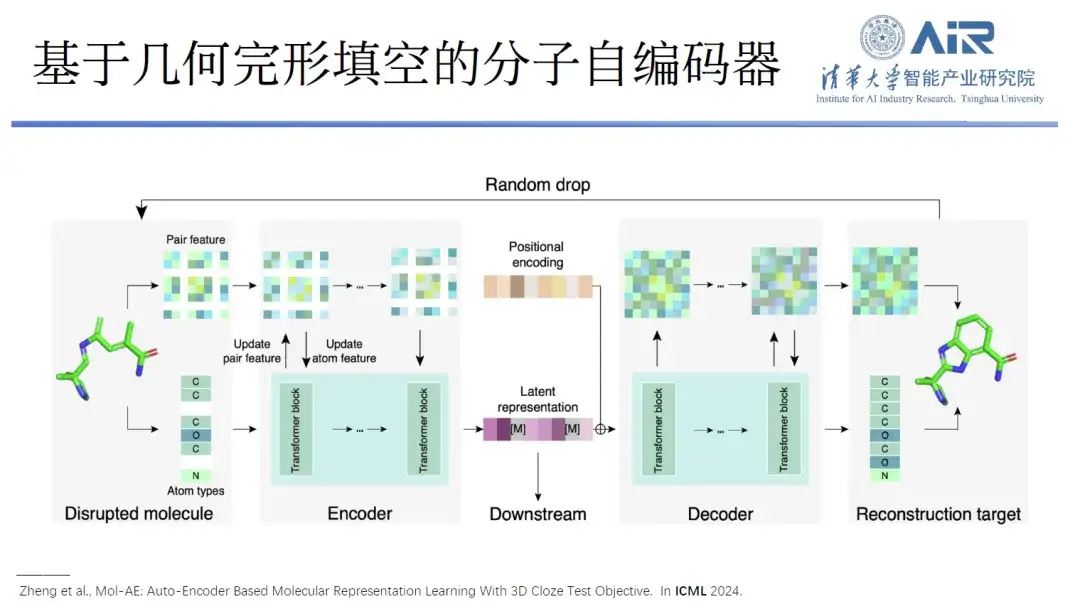
Titre de l'article :Mol-AE : Apprentissage de la représentation moléculaire basé sur un encodeur automatique avec test de fermeture 3D Objectif
Lien vers l'article :https://icml.cc/virtual/2024/poster/33340
en outre,Ils ont également proposé un autoencodeur moléculaire Mol-AE basé sur le cloze géométrique.Grâce aux nouveaux objectifs de formation du test 3D Cloze, le modèle proposé peut mieux apprendre les relations spatiales des atomes dans les structures moléculaires réelles. Comparé aux méthodes de modélisation moléculaire 3D les plus avancées, Mol-AE permet une amélioration significative des performances.

La recherche sur le pré-entraînement universel des protéines est également une direction qu’ils ont choisie. Il est entendu que la pré-formation générale actuelle des protéines est principalement divisée en trois catégories : la série DeepMind Alphafold, la série RoseTTAFold de David Baker et la série Meta ESM.L’équipe du professeur Zhou Hao a actuellement développé le modèle ESM-AA.
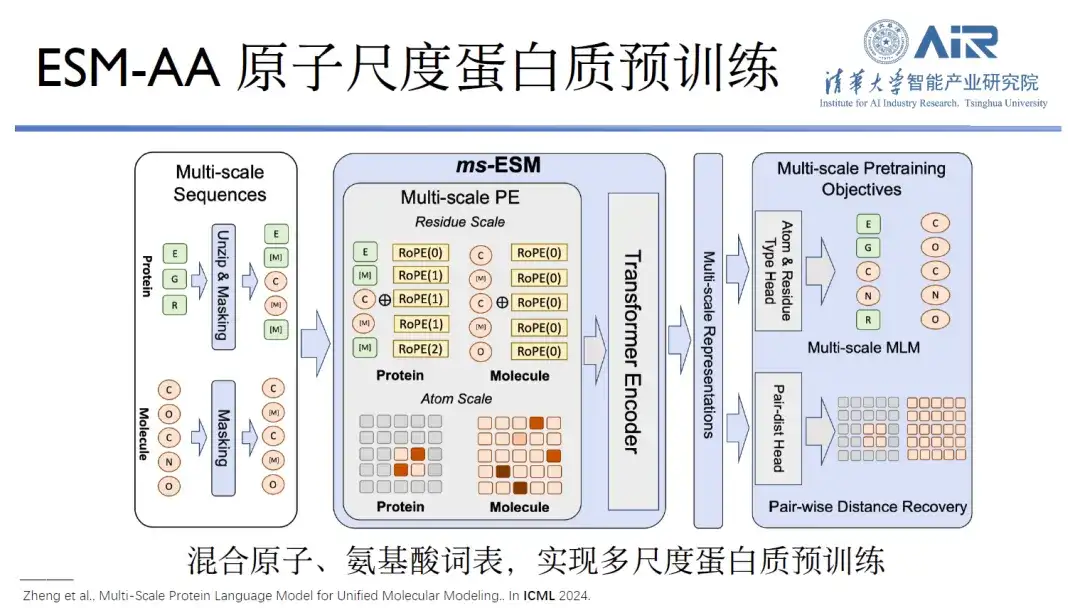
Titre de l'article :Modèle de langage protéique multi-échelle pour une modélisation moléculaire unifiée
Lien vers l'article :https://icml.cc/virtual/2024/poster/35119
C'est parce que la mise à niveau d'Alphafold2 vers Alphafold3 a construit une base entièrement atomique, et il en va de même pour la série RoseTTAFold. Seule la série ESM ne possède pas encore de base entièrement atomique. L’équipe du professeur Zhou Hao travaille sur ce projet depuis septembre de l’année dernière. En combinant les vocabulaires atomiques et d’acides aminés, la formation des protéines peut être réalisée à plusieurs échelles. Dans la tâche conjointe des protéines et des petites molécules, l'ESM-AA fonctionne mieux que les bases de pré-entraînement individuelles telles que l'ESM, d'autres bases de pré-entraînement de protéines ou de petites molécules.
Le dock pré-entraîné a également reçu de nombreux éloges sur Twitter. En tant que représentant de la base de séquence, ESM-AA sera en compétition avec RoseTTAFold et Alphafold3, représentants de la base de structure. « Je pense que c’est aussi notre objectif futur », a déclaré le professeur Zhou Hao.
À propos du professeur Zhou Hao
Zhou Hao, né en 1990, docteur, chercheur associé à l'Université Tsinghua. Sa direction de recherche est l'intelligence artificielle générative pour les systèmes symboliques complexes. Ses principales applications comprennent les modèles de langage à très grande échelle, la génération moléculaire, la conception de protéines, la découverte de nouveaux matériaux, etc.

Il était chercheur scientifique et directeur adjoint chez ByteDance, où il a dirigé les équipes de R&D pour la plateforme de génération de texte et la conception de médicaments assistée par l'IA de ByteDance. Ses produits de R&D sont utilisés dans plus de 20 pays à travers le monde, avec une base d’utilisateurs de plus d’un milliard. Il a longtemps été président de plusieurs conférences de premier plan sur l’intelligence artificielle telles que l’ICML, le NeurIPS, l’ICLR et l’ACL, et a publié plus de 80 articles lors d’importantes conférences internationales sur l’intelligence artificielle. Il a remporté le prix de la meilleure thèse de doctorat 2019 de la China Artificial Intelligence Society, le prix du meilleur article (1/3350) de l'ACL 2021, la plus grande conférence internationale dans le domaine du traitement du langage naturel, et le prix NLPCC Young Emerging Scholar 2021 de la China Computer Society.








