Command Palette
Search for a command to run...
Lyft Publie Le Plus Grand Ensemble De Données De Prédiction De Conduite Autonome L5 Et Lance Un Concours De Prédiction De Mouvement
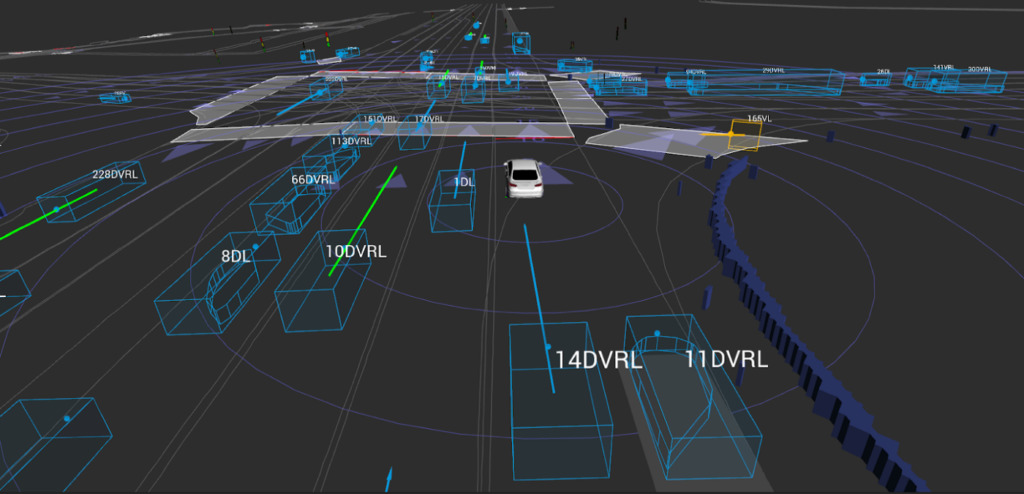
Lyft a récemment publié un ensemble de données de prédiction de conduite autonome de niveau 5 contenant plus de 1 000 heures d'enregistrements de conduite. En outre, la société a lancé un défi de prédiction de mouvement de conduite autonome avec une cagnotte de 30 000 $ US.
Lyft a publié un nouvel ensemble de données.
En juillet dernier, Lyft a publié un ensemble de données de perception de conduite autonome L5 contenant plus de 55 000 images 3D annotées étiquetées par des humains. À l’époque, on l’appelait officiellement le plus grand ensemble de données publiques de ce type.
Un an plus tard seulement, Lyft a publié un ensemble de données de prédiction de conduite autonome L5.

Adresse de téléchargement de l'application : https://www.catalyzex.com/paper/arxiv:2006.14480/dataset
170 000 scènes et plus de 2 500 kilomètres de données routières
L'ensemble de données publié par Lyft se concentre cette fois sur la prédiction de mouvement.Les responsables ont déclaré qu'un problème de recherche de longue date dans le domaine de la conduite autonome est de créer des modèles suffisamment robustes et fiables pour prédire les mouvements de trafic.
Les données ont été collectées sur une période de quatre mois par une flotte de 23 véhicules autonomes sur un itinéraire fixe à Palo Alto, en Californie.Contient les journaux de conduite des voitures, des piétons et d'autres obstacles rencontrés.
L'ensemble de données comprend spécifiquement :
- 1000 heures :Plus de 1 000 heures d’enregistrements de mouvements de véhicules autonomes ;
- 170 000 scènes :Chaque scène dure environ 25 secondes et comprend des feux de circulation, des cartes aériennes, des trottoirs, etc.
- 16 000 milles: 16 000 miles (2 575 kilomètres) de données provenant des routes publiques ;
- 15242 images annotées :Comprend une carte sémantique haute définition des éléments étiquetés et une vue aérienne haute définition de la zone.

Ces données de mouvement sont collectées par un réseau de capteurs monté sur le toit des véhicules Lyft, qui capture les données lidar, caméra et radar lorsque les véhicules parcourent des dizaines de milliers de kilomètres.
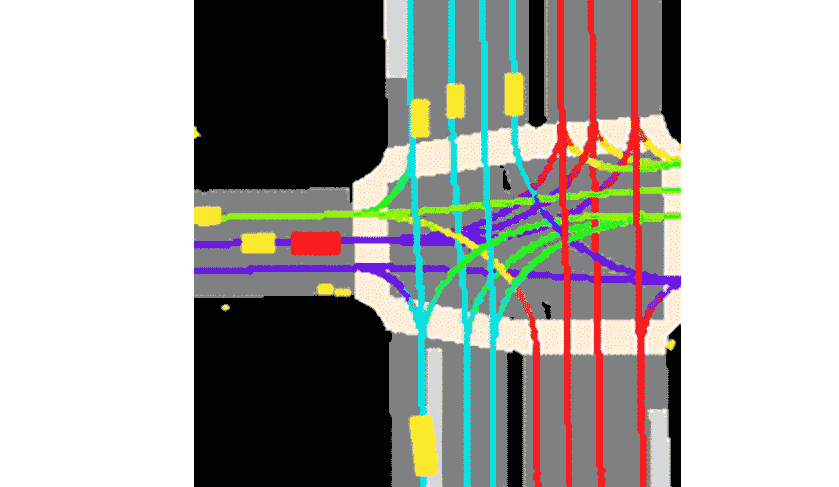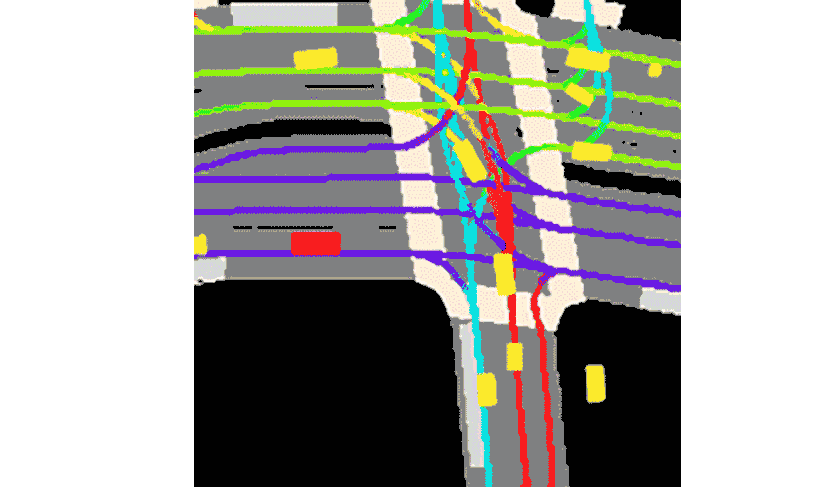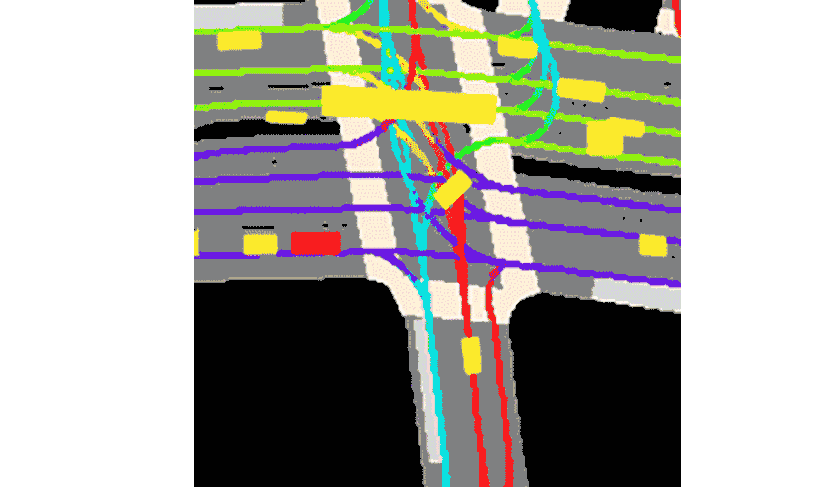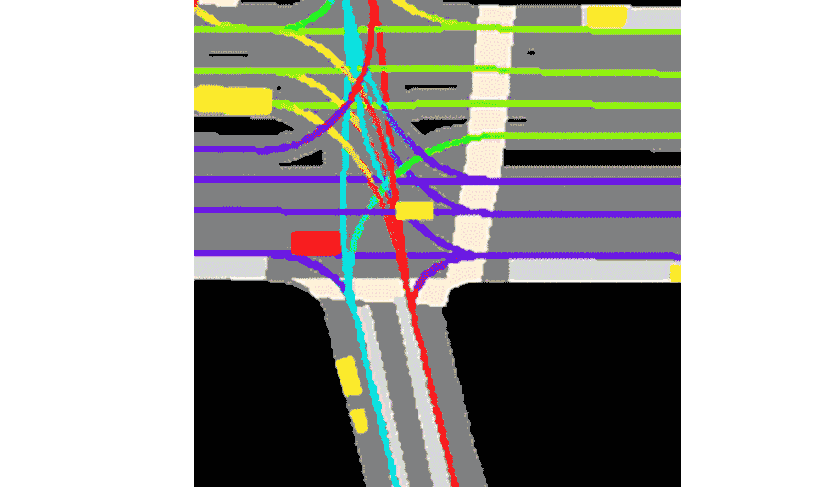
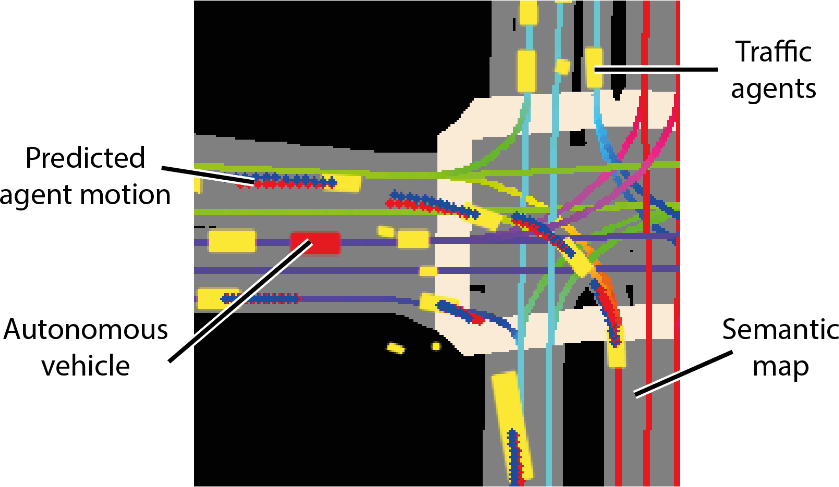
Lyft a déclaré que la collection est livrée avec la boîte à outils fournie.Il s’agit de l’ensemble de données le plus vaste, le plus complet et le plus détaillé à ce jour.Utilisé pour développer la conduite autonome, les tâches d'apprentissage automatique telles que la prédiction de mouvement, la planification et la simulation.
Actuellement, seuls certains sous-ensembles de cet ensemble de données sont disponibles au téléchargement, notamment :
- Exemple de jeu de données (53 Mo)
- Ensemble de données de formation (divisé en trois parties, totalisant 69,4 Go)
- Vue à vol d'oiseau (2 Go)
- Graphe sémantique (2 Mo)
Adresse de téléchargement :
Lancez un défi avec une cagnotte de 30 000 dollars américains
en même temps,Lyft prévoit également de lancer un défi qui débutera en août sur la plateforme Google Kaggle et qui offrira un total de 30 000 $ en prix.

Les points forts de ce défi :
- Conditions de participation au concours :Les concurrents prédisent le mouvement des véhicules ;
- Préparation:Rappel officiel : désormais, les chercheurs et les ingénieurs peuvent télécharger des ensembles de données de formation et des progiciels basés sur Python pour expérimenter avec les données. Parce que le kit de test et de validation sera publié dans le cadre du concours ;
- Objectif ultime :Renforcer la communauté de recherche et accélérer l’innovation grâce à des ensembles de données et des concours.
Sacha Arnoud, directeur principal de l'ingénierie de Lyft, et Peter Ondruska, directeur de la recherche audio et vidéo, ont écrit dans un article de blog :« Les données sont la force motrice derrière l’essai des dernières techniques d’apprentissage automatique.Bien que l’accès à des données de conduite autonome à grande échelle et de haute qualité soit limité, cela ne devrait pas nous empêcher d’expérimenter dans ce domaine. "
« Nous pensons que les véhicules autonomes deviendront un élément plus pratique, plus sûr et plus durable du système de transport », ont déclaré Arnoud et Ondruska.« En partageant des données avec la communauté des chercheurs, nous espérons identifier les défis importants et non résolus de la conduite autonome."
CliquezLire l'article original, vous pouvez obtenir davantage d’ensembles de données de haute qualité !
Adresse du blog :
Adresse du document :
https://arxiv.org/pdf/2006.14480.pdf
Adresse GitHub :
https://github.com/lyft/l5kit/
-- sur--








