HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

The Devil Behind Moltbook: Anthropic Safety is Always Vanishing in Self-Evolving AI Societies

Towards Autonomous Mathematics Research
























The Devil Behind Moltbook: Anthropic Safety is Always Vanishing in Self-Evolving AI Societies
Towards Autonomous Mathematics Research
When to Memorize and When to Stop: Gated Recurrent Memory for Long-Context Reasoning
ASA: Activation Steering for Tool-Calling Domain Adaptation
PhyCritic: Multimodal Critic Models for Physical AI
GENIUS: Generative Fluid Intelligence Evaluation Suite
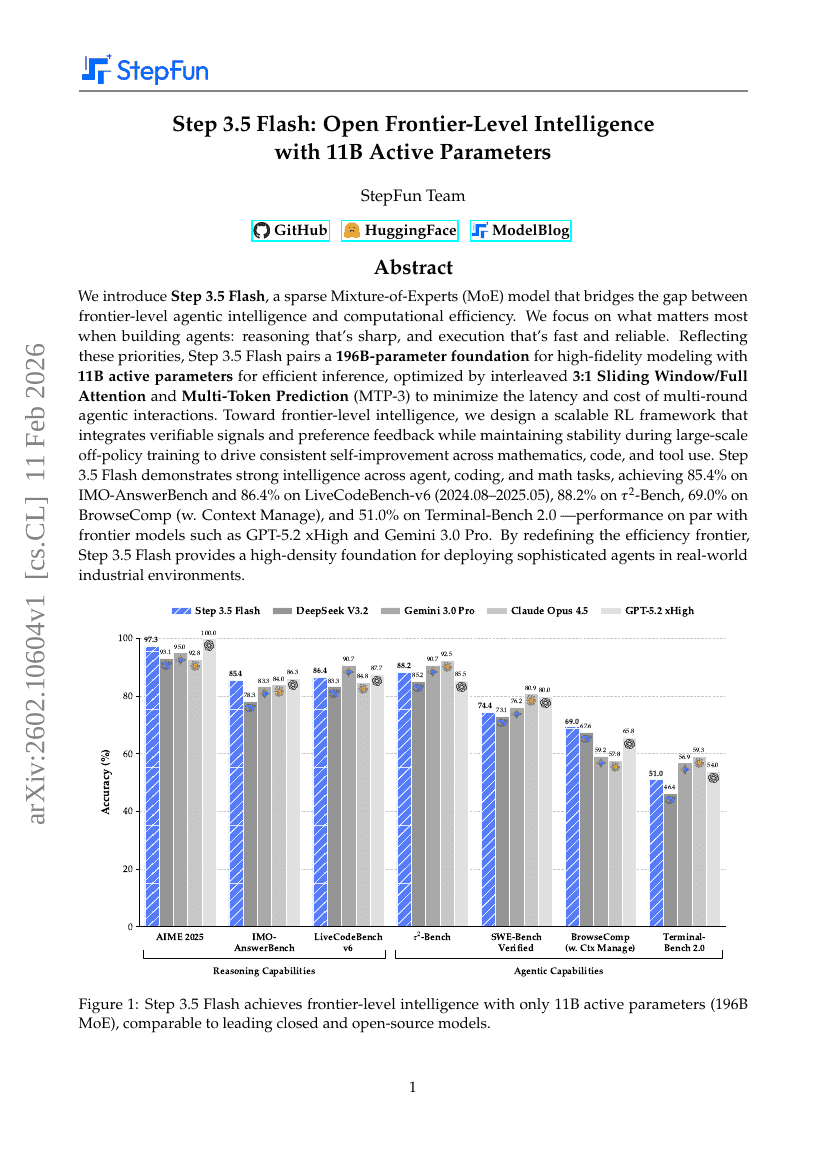
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
World-VLA-Loop: Closed-Loop Learning of Video World Model and VLA Policy
Towards Autonomous Mathematics Research
Agent World Model: Infinity Synthetic Environments for Agentic Reinforcement Learning
P1-VL: Bridging Visual Perception and Scientific Reasoning in Physics Olympiads
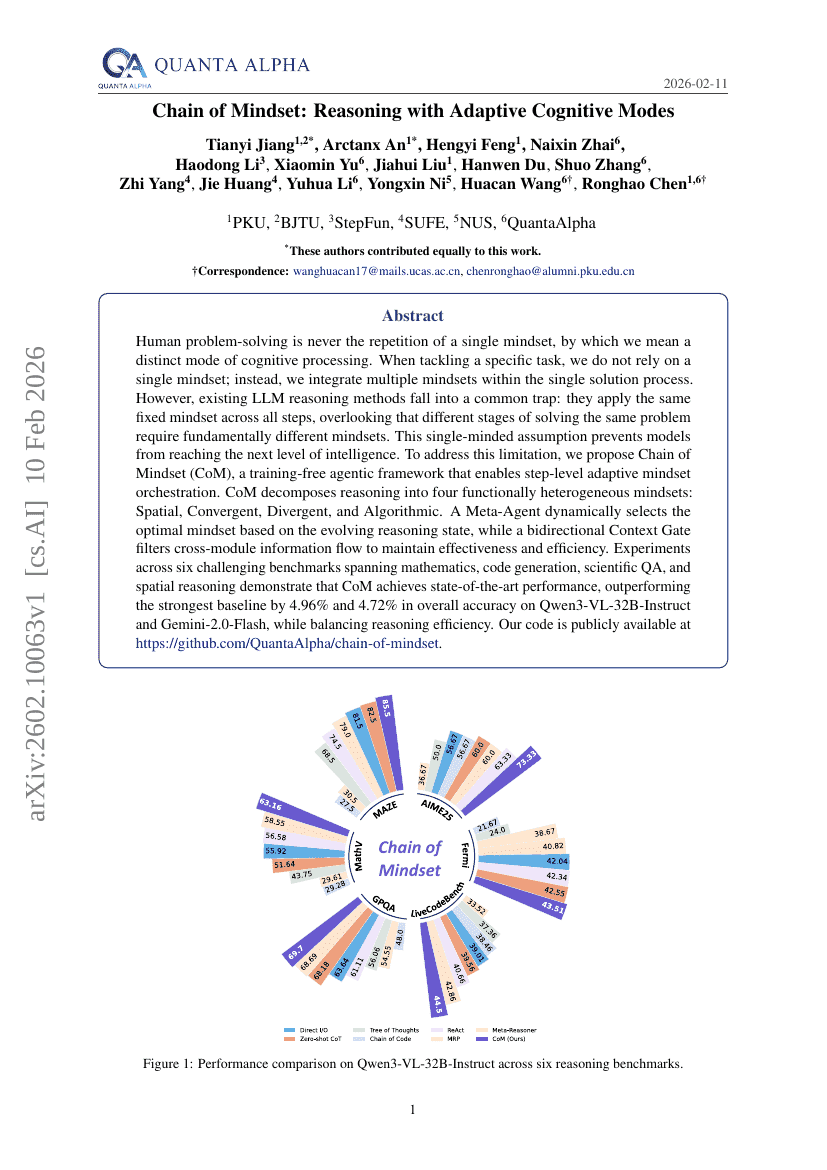
Chain of Mindset: Reasoning with Adaptive Cognitive Modes
UI-Venus-1.5 Technical Report
Code2World: A GUI World Model via Renderable Code Generation
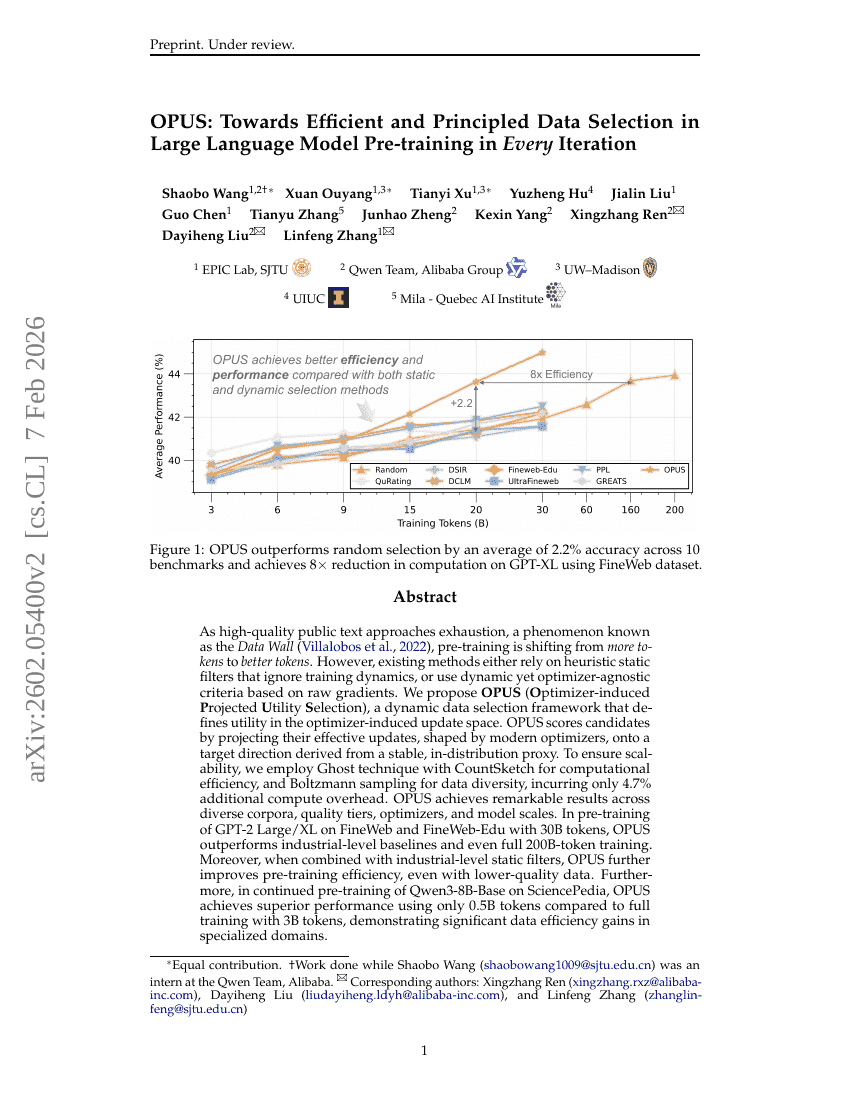
OPUS: Towards Efficient and Principled Data Selection in Large Language Model Pre-training in Every Iteration
BagelVLA: Enhancing Long-Horizon Manipulation via Interleaved Vision-Language-Action Generation
THINGS-data: A multimodal collection of large-scale datasets for investigating object representations in human brain and behavior
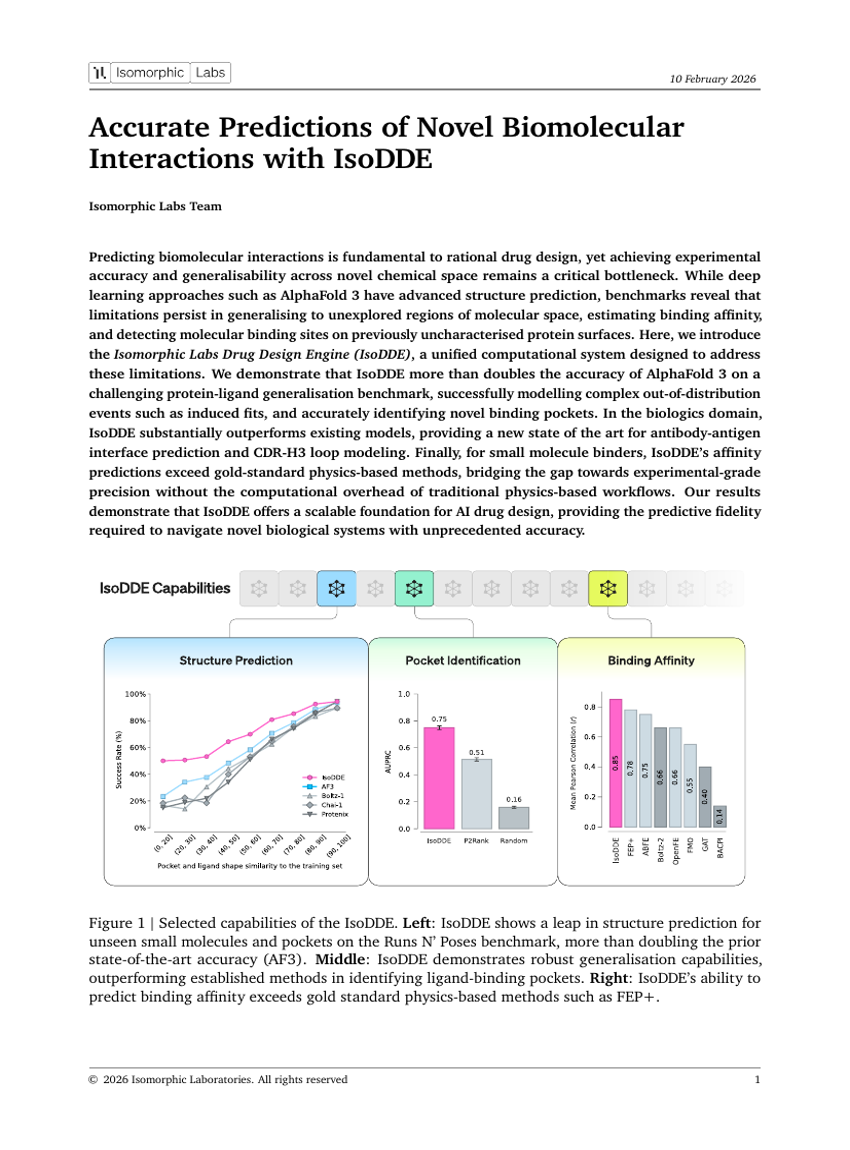
Accurate Predictions of Novel Biomolecular Interactions with IsoDDE
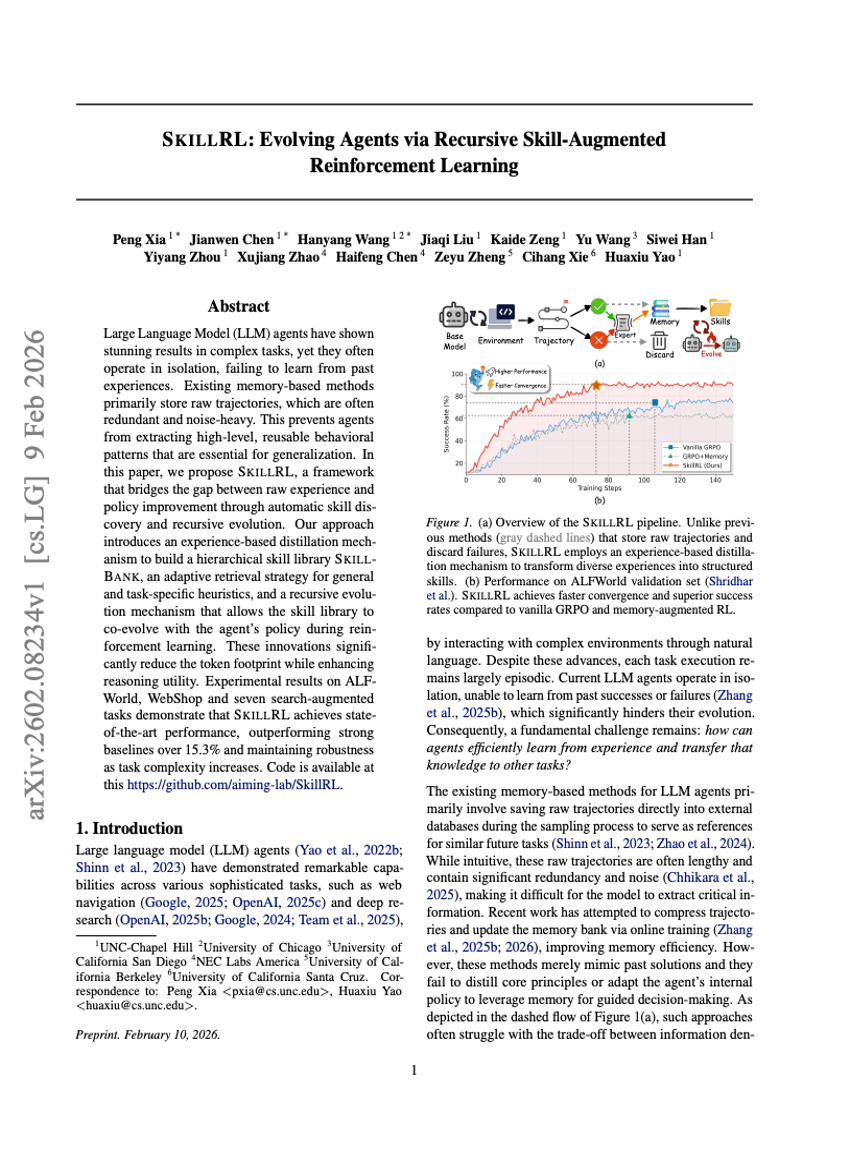
SKILLRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
LLaDA2.1: Speeding Up Text Diffusion via Token Editing
Alleviating Sparse Rewards by Modeling Step-Wise and Long-Term Sampling Effects in Flow-Based GRPO
Recurrent-Depth VLA: Implicit Test-Time Compute Scaling of Vision-Language-Action Models via Latent Iterative Reasoning
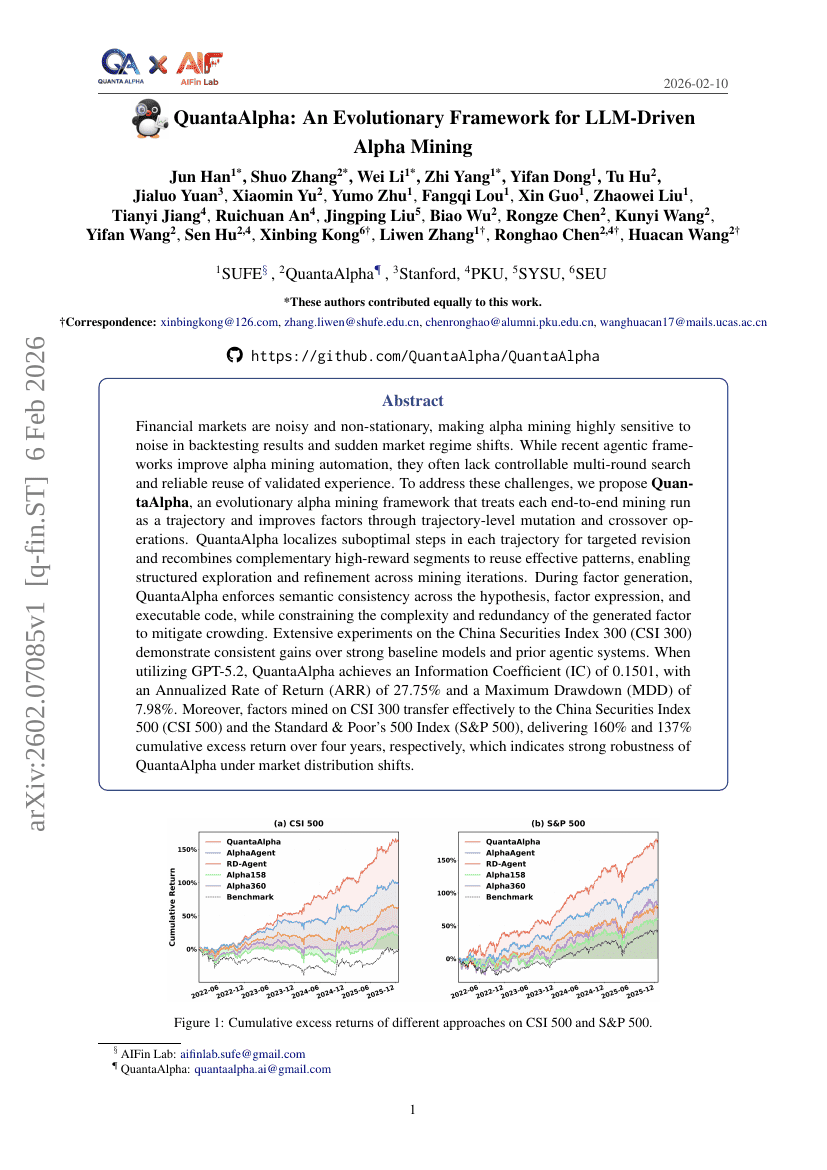
QuantaAlpha: An Evolutionary Framework for LLM-Driven Alpha Mining
Modality Gap-Driven Subspace Alignment Training Paradigm For Multimodal Large Language Models
MOVA: Towards Scalable and Synchronized Video-Audio Generation
MemoryLLM: Plug-n-Play Interpretable Feed-Forward Memory for Transformers
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
F-GRPO: Don't Let Your Policy Learn the Obvious and Forget the Rare
MSign: An Optimizer Preventing Training Instability in Large Language Models via Stable Rank Restoration
AudioSAE: Towards Understanding of Audio-Processing Models with Sparse AutoEncoders
On the Entropy Dynamics in Reinforcement Fine-Tuning of Large Language Models
OdysseyArena: Benchmarking Large Language Models For Long-Horizon, Active and Inductive Interactions
When to Memorize and When to Stop: Gated Recurrent Memory for Long-Context Reasoning
ASA: Activation Steering for Tool-Calling Domain Adaptation
PhyCritic: Multimodal Critic Models for Physical AI
GENIUS: Generative Fluid Intelligence Evaluation Suite
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
World-VLA-Loop: Closed-Loop Learning of Video World Model and VLA Policy
Towards Autonomous Mathematics Research
Agent World Model: Infinity Synthetic Environments for Agentic Reinforcement Learning
P1-VL: Bridging Visual Perception and Scientific Reasoning in Physics Olympiads
Chain of Mindset: Reasoning with Adaptive Cognitive Modes
UI-Venus-1.5 Technical Report
Code2World: A GUI World Model via Renderable Code Generation
OPUS: Towards Efficient and Principled Data Selection in Large Language Model Pre-training in Every Iteration
BagelVLA: Enhancing Long-Horizon Manipulation via Interleaved Vision-Language-Action Generation
THINGS-data: A multimodal collection of large-scale datasets for investigating object representations in human brain and behavior
Accurate Predictions of Novel Biomolecular Interactions with IsoDDE
SKILLRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
LLaDA2.1: Speeding Up Text Diffusion via Token Editing
Alleviating Sparse Rewards by Modeling Step-Wise and Long-Term Sampling Effects in Flow-Based GRPO
Recurrent-Depth VLA: Implicit Test-Time Compute Scaling of Vision-Language-Action Models via Latent Iterative Reasoning
QuantaAlpha: An Evolutionary Framework for LLM-Driven Alpha Mining
Modality Gap-Driven Subspace Alignment Training Paradigm For Multimodal Large Language Models
MOVA: Towards Scalable and Synchronized Video-Audio Generation
MemoryLLM: Plug-n-Play Interpretable Feed-Forward Memory for Transformers
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
F-GRPO: Don't Let Your Policy Learn the Obvious and Forget the Rare
MSign: An Optimizer Preventing Training Instability in Large Language Models via Stable Rank Restoration
AudioSAE: Towards Understanding of Audio-Processing Models with Sparse AutoEncoders
On the Entropy Dynamics in Reinforcement Fine-Tuning of Large Language Models
OdysseyArena: Benchmarking Large Language Models For Long-Horizon, Active and Inductive Interactions