Command Palette
Search for a command to run...
RLDX-1 Technical Report
RLDX-1 Technical Report
Abstract
While Vision-Language-Action models (VLAs) have shown remarkable progress toward human-like generalist robotic policies through the versatile intelligence (i.e. broad scene understanding and language-conditioned generalization) inherited from pre-trained Vision-Language Models, they still struggle with complex real-world tasks requiring broader functional capabilities (e.g. motion awareness, memory-aware decision making, and physical sensing). To address this, we introduce RLDX-1, a general-purpose robotic policy for dexterous manipulation built on the Multi-Stream Action Transformer (MSAT), an architecture that unifies these capabilities by integrating heterogeneous modalities through modality-specific streams with cross-modal joint self-attention. RLDX-1 further combines this architecture with system-level design choices, including synthesizing training data for rare manipulation scenarios, learning procedures specialized for human-like manipulation, and inference optimizations for real-time deployment. Through empirical evaluation, we show that RLDX-1 consistently outperforms recent frontier VLAs (e.g. π0.5 and GR00T N1.6) across both simulation benchmarks and real-world tasks that require broad functional capabilities beyond general versatility. In particular, RLDX-1 shows superiority in ALLEX humanoid tasks by achieving success rates of 86.8% while π0.5 and GR00T N1.6 achieve around 40%, highlighting the ability of RLDX-1 to control a high-DoF humanoid robot under diverse functional demands. Together, these results position RLDX-1 as a promising step toward reliable VLAs for complex, contact-rich, and dynamic real-world dexterous manipulation.
One-sentence Summary
This technical report introduces RLDX-1, a Vision-Language-Action (VLA) model that integrates diverse functional capabilities for dexterous manipulation in real-world deployment.
Key Contributions
- Introduces RLDX-1, a Vision-Language-Action model that unifies motion awareness, long-term memory, and physical sensing into a single end-to-end policy for complex dexterous manipulation.
- Proposes a synthetic data framework that synthesizes visually realistic robot videos annotated with actions, which effectively augments real-world torque-annotated data despite lacking explicit torque signals.
- Validates the framework through real-world deployment on the ALLEX humanoid robot, demonstrating reliable execution of contact-rich tasks such as pot pouring and bulb twisting.
Introduction
Vision-Language-Action models have emerged as a leading framework for developing generalist robotic policies that leverage the broad scene understanding and language conditioning of pre-trained vision-language models. While these systems excel at versatile task generalization, they consistently struggle in complex real-world environments that demand motion awareness, long-term memory, and physical sensing. To bridge this gap, the authors introduce RLDX-1, a unified robotic policy built on the Multi-Stream Action Transformer architecture. The authors leverage modality-specific streams coupled with cross-modal attention to simultaneously process temporal dynamics, historical context, and tactile feedback within a single end-to-end model. They further complement this architecture with a synthetic data pipeline for rare manipulation scenarios, a specialized three-stage training regimen, and inference optimizations that achieve real-time control. Consequently, RLDX-1 delivers substantially higher success rates than existing frontier models on both simulation benchmarks and contact-rich real-world humanoid tasks.
Dataset
Dataset Composition and Sources
- The authors combine real-world and synthetic robot data to build a multi-embodiment training corpus spanning single-arm grippers, dual-arm systems, and humanoid platforms with dexterous hands.
- Real-world sources include widely adopted public benchmarks and two in-house collections gathered on tactile-augmented Franka Research 3 and ALLEX humanoid platforms.
- Synthetic data is generated to supplement specialized manipulation scenarios that are difficult to scale through direct physical collection.
Key Details for Each Subset
- Open-X-Embodiment provides a curated mixture of over one million trajectories across twenty embodiments.
- DROID contributes 92,000 in-the-wild trajectories from a Franka Research 3 platform.
- Galaxea Open-World supplies 100,000 dual-arm trajectories with subtask-level language annotations.
- Agibot World is sampled down to 275,000 episodes focusing on hand manipulation.
- Fourier ActionNet and Humanoid Everyday contribute 30,000 and 10,300 trajectories respectively, covering bimanual and humanoid interaction tasks.
- The in-house Franka setup records joint torques and tactile feedback via VR teleoperation, while the ALLEX collection captures full upper-body dexterous control using multi-device VR tracking and current-to-torque estimation.
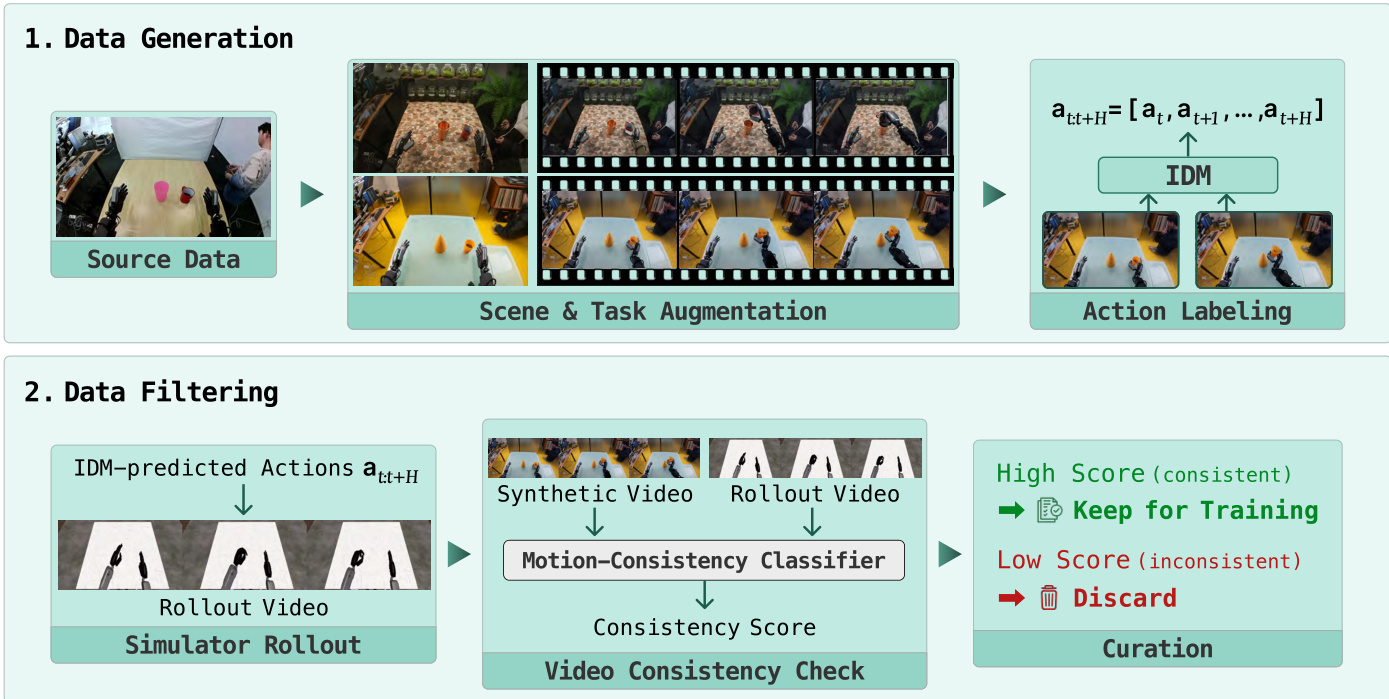
- Synthetic subsets are derived from public GR-1 and in-house ALLEX demonstrations, expanded through task and scene augmentation, and filtered using a two-stage pipeline that evaluates visual plausibility and action consistency.
Data Usage and Training Strategy
- The authors pre-train the model on a heterogeneous mixture of all real and synthetic subsets to learn embodiment-agnostic manipulation policies via a flow-matching objective.
- To address humanoid data scarcity, they integrate 150,000 synthetic GR-1 episodes into the pre-training corpus.
- Mid-training splits data by target platform, combining in-house collections with DROID for Franka and pairing in-house data with synthetic generations for ALLEX.
- The team normalizes proprioceptive states and actions to a [-1, 1] range using per-dataset first and ninety-ninth percentiles.
- The model processes four frames at fixed temporal offsets and routes batches through both embodiment-specific and a shared embodiment-agnostic projection layer.
Preprocessing, Cropping, and Metadata Construction
- The authors apply a unified visual pipeline that resizes all input frames to fit within a 256 by 256 pixel budget while strictly preserving the original aspect ratio.
- They avoid cropping or padding by leveraging a native-resolution vision encoder that dynamically scales dimensions to multiples of thirty-two, capping each frame at sixty-four vision tokens.
- Synthetic action labels are generated offline using an inverse dynamics model that predicts action sequences from sequential observations.
- Task instructions for augmented videos are synthesized through a vision language model using factorized composition and skill-primitive conditioning.
- The filtering pipeline first applies a vision language model to score instruction alignment and spatial plausibility, then replays predicted actions in a physics simulator to verify motion consistency against a lightweight video encoder probe.
Method
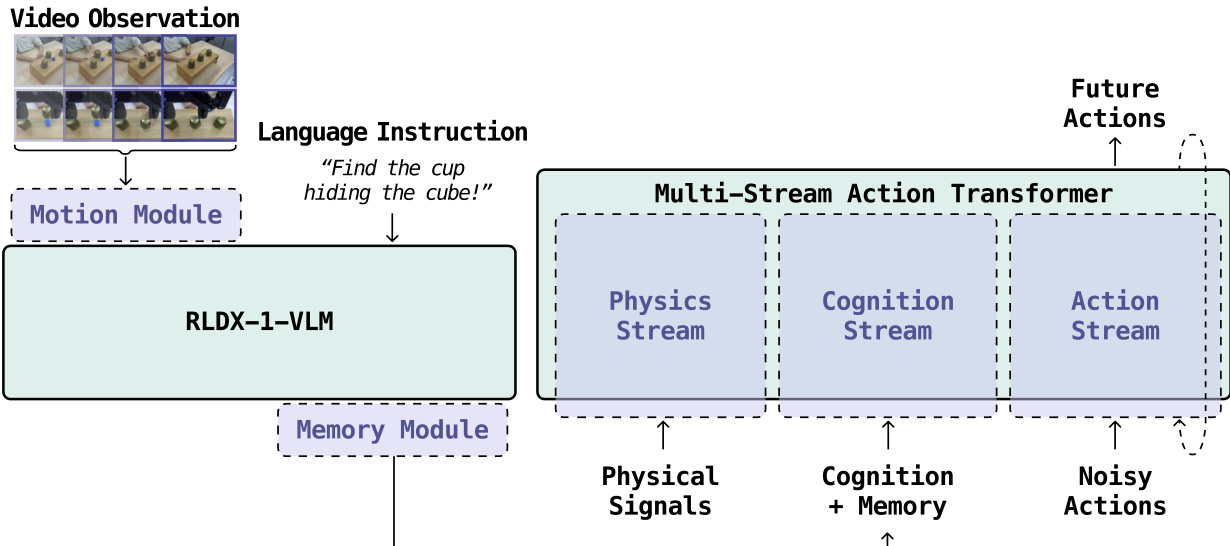
The RLDX-1 model architecture is designed to integrate vision, language, and action capabilities for dexterous manipulation in real-world robotics. It consists of two primary components: a Vision-Language Model (VLM) and a multimodal action model. The VLM processes multimodal inputs, including a sequence of K+1 video frames, a language instruction, and a proprioceptive state, to generate a history-aware cognition feature representation. This representation is augmented with long-term memory features through a memory module and then passed to the action model. The action model generates a sequence of H+1 future actions, conditioned on the memory-augmented cognition features, the current proprioceptive state, and physical sensory signals when available. The overall framework is illustrated in the figure below.

The Vision-Language Model (VLM) is responsible for extracting motion-aware visual-language representations from the input data. It begins by processing the video observations through a vision encoder, which includes a ViT block and a motion extractor to capture temporal dynamics. The language instruction is tokenized and processed through a text tokenizer. These processed visual and textual features are then combined and passed through multiple transformer layers, culminating in a compressed video token representation. The resulting cognition features are passed to the memory module, which maintains a queue of past cognition features to enable long-term memory. The memory module stores and retrieves these features, augmenting the current cognition features with historical context. This augmented representation, along with the current proprioceptive state and physical signals, is then fed into the action model.
The action model is implemented as a flow-matching Diffusion Transformer (DiT), which learns a denoising velocity field over action trajectories. During training, a noisy action chunk is constructed by sampling a denoising timestep τ and adding noise ϵ to the clean action chunk. The action model, parameterized as a neural vector field uθ, is trained to predict the velocity that moves the noisy sample toward the clean action chunk. This is achieved using a flow-matching objective that minimizes the difference between the predicted velocity and the actual velocity. At inference, the model uses Euler's method to generate action chunks over multiple denoising steps, starting from random noise.
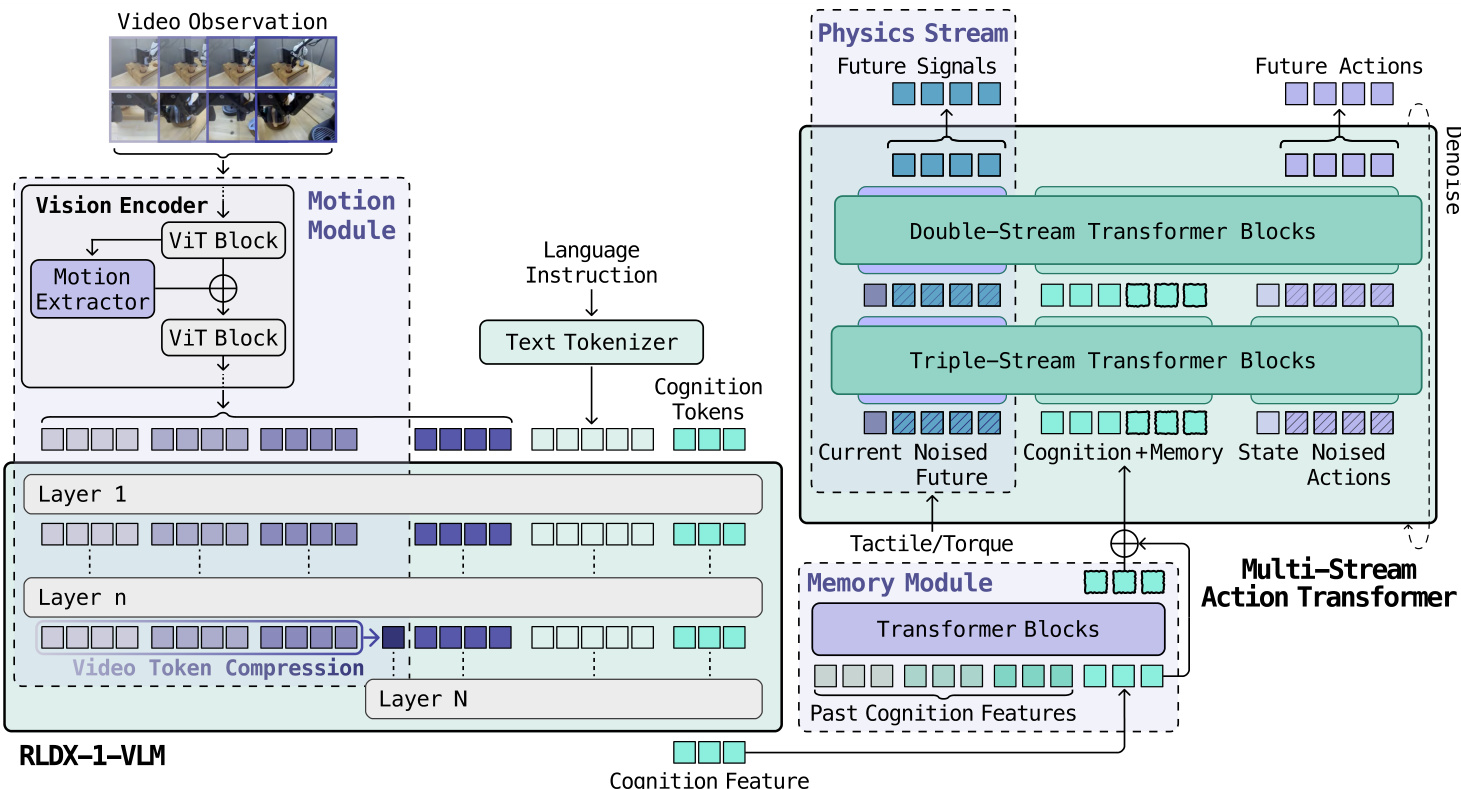
To handle the heterogeneous nature of the inputs—cognition features, proprioceptive states, and physical sensory signals—the model employs a Multi-Stream Action Transformer (MSAT) architecture. This architecture processes each modality through a dedicated stream while enabling cross-modal interaction via joint self-attention. In the early double-stream blocks, the cognition features and proprioceptive states paired with noisy actions are processed through the cognition (C) and action (A) streams, respectively. These streams are then merged into a single sequence for joint processing in the subsequent single-stream blocks. When physical signals are available, an additional physics (P) stream is introduced, allowing the model to incorporate tactile and torque feedback. This extensible design enables cross-modal information exchange while preserving modality-specific parameters. The MSAT architecture is further enhanced with rotary positional embeddings for the action stream to capture temporal structure, an in-context token for the flow-matching timestep, and RMSNorm with SwiGLU activation for improved performance.
The physical sensing capability is integrated through a physics module that processes physical sensory signals separately from the cognition and action streams, allowing for cross-modal interaction through joint self-attention. This module is designed to be disabled when physical signals are unavailable, ensuring flexibility. During training, an auxiliary objective is used to predict future physical signals, encouraging the model to internalize physical interaction dynamics. The action model jointly denoises two sequences: the noised future action chunk in the C stream and the noised future physical signals in the P stream, which enhances the model's ability to utilize physical feedback for action generation.
The training of RLDX-1 is conducted in three stages: pre-training, mid-training, and post-training. Pre-training on large-scale multi-embodiment data enables the model to learn general-purpose manipulation and temporal understanding. Mid-training adapts the model to specific embodiments and introduces new capabilities such as long-term memory and physical sensing. This stage involves fine-tuning on embodiment-specific datasets to enhance motion awareness, long-term memory, and physical sensing. Post-training further refines the model for downstream tasks, optionally using adaptive data collection or reinforcement learning to improve performance on challenging dexterous manipulation tasks. The three-stage training pipeline ensures that RLDX-1 develops both generalist and expert skills, making it suitable for a wide range of real-world applications.
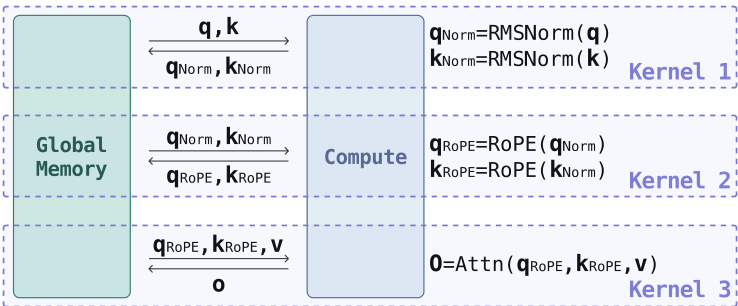
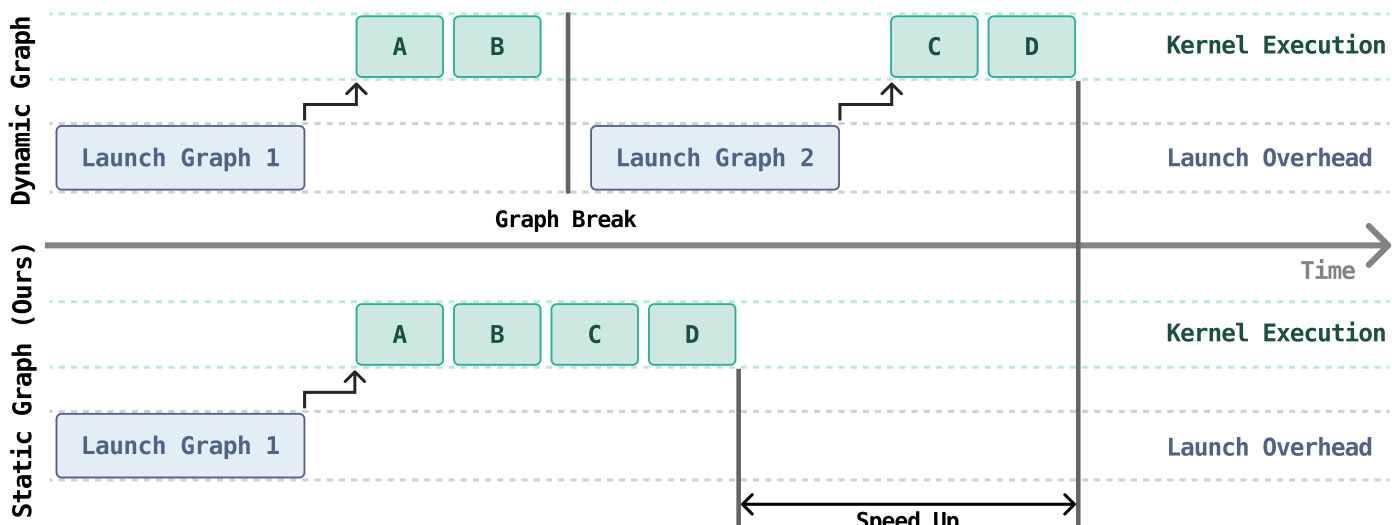
For inference, the model employs an optimization pipeline to reduce latency. This pipeline includes graph capture optimization and kernel optimization. Graph capture optimization eliminates kernel launch overhead by converting the model into a static graph, which allows the forward pass to be captured as a single CUDA Graph. This reduces the fragmentation and launch overhead that occurs in dynamic graph execution. Kernel optimization involves hand-designed kernels tailored to the RLDX-1 workload, which coordinate data movement and computation more efficiently. These optimizations are critical for real-time control, as they ensure that the model can generate actions quickly enough to keep up with the robot's closed-loop perception and actuation cycle.
Experiment
The evaluation encompasses multiple simulated benchmarks and real-world robotic platforms to validate both the versatile intelligence and specialized functional capabilities of RLDX-1. Tests across humanoid and single-arm systems demonstrate that the model successfully navigates complex scenarios requiring motion awareness, long-term memory, and physical sensing, consistently surpassing existing vision-language-action models that typically fail in dynamic or contact-rich environments. Complementary ablation studies further validate that optimized feature extraction, robot-specific visual adaptation, and scalable synthetic data generation substantially improve policy generalization and task-specific performance. Together with reinforcement learning refinement and inference optimizations, these results confirm that RLDX-1 delivers robust, real-time dexterous manipulation across diverse operational settings.
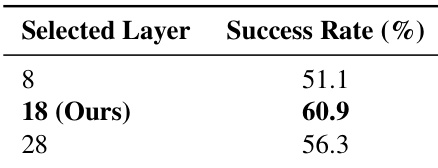
The authors analyze the impact of selecting different layers from the Vision-Language Model (VLM) for feature extraction in a Vision-Language-Action model. The results show that using features from an intermediate layer, specifically layer 18, yields the highest success rate, outperforming both earlier and later layers. This suggests that intermediate representations provide an optimal balance between visual grounding and semantic abstraction for action generation. Using features from layer 18 achieves the highest success rate compared to earlier and later layers. Selecting an intermediate VLM layer provides a better balance between visual grounding and semantic abstraction for action generation. Features from layer 8 result in the lowest success rate, while layer 28 shows a moderate improvement over layer 8 but still underperforms compared to layer 18.
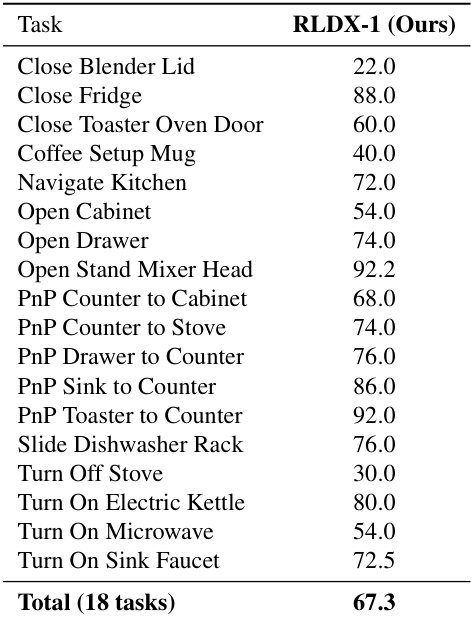
The authors evaluate the performance of RLDX-1 on a set of 18 kitchen manipulation tasks, reporting success rates for each task and an overall average. The results show that RLDX-1 achieves a total success rate of 67.3% across these tasks, with varying performance depending on the specific manipulation required. The model demonstrates consistent success on tasks involving object manipulation and navigation, but lower performance on tasks requiring precise control of appliances. RLDX-1 achieves an overall success rate of 67.3% across 18 kitchen manipulation tasks. The model performs well on tasks involving object manipulation and navigation, such as opening drawers and moving objects between surfaces. Performance varies significantly across tasks, with lower success rates observed on tasks requiring precise control of appliances.
The authors evaluate the performance of RLDX-1 on the SIMPLER benchmark, comparing it to baseline models across multiple tasks. Results show that RLDX-1 achieves the highest average success rate among all models on both the Google-VM and Google-VA sub-benchmarks, with particularly strong performance on tasks like Pick Coke Can and Close Drawer. RLDX-1 also outperforms baselines on the WidowX benchmark, demonstrating consistent superiority across different robotic platforms and task types. RLDX-1 achieves the highest average success rate on both Google-VM and Google-VA sub-benchmarks. RLDX-1 shows strong performance on challenging tasks such as Pick Coke Can and Close Drawer. RLDX-1 outperforms baselines on the WidowX benchmark, indicating consistent effectiveness across different robotic platforms.

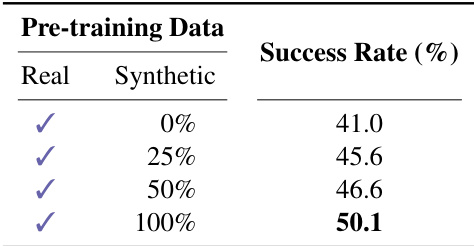
The the the table presents the success rates of a model trained with varying proportions of synthetic data during pre-training, showing an improvement in performance as the synthetic data ratio increases. The results indicate that incorporating synthetic data enhances the model's effectiveness, with the highest success rate achieved when the pre-training data is entirely synthetic. Success rates increase as the proportion of synthetic data in pre-training increases. The model achieves the highest success rate with 100% synthetic data. The use of synthetic data during pre-training improves the model's performance compared to using only real data.
The authors evaluate the impact of synthetic data on the performance of RLDX-1 in the Pot-to-Cup Pouring task, comparing fine-tuning with real data alone versus a combination of real and synthetic data. Results show that incorporating synthetic data significantly improves the overall success rate and reduces failure cases, indicating enhanced spatial generalization and robustness in grasping tasks. The improvement is primarily driven by an increase in full successes and a decrease in failures, suggesting that synthetic data effectively augments the training distribution. Incorporating synthetic data improves the overall success rate from 66.7% to 83.3% in the Pot-to-Cup Pouring task. The performance gain is driven by a reduction in failures and an increase in full successes, enhancing spatial generalization. Synthetic data effectively augments the training distribution, leading to more robust grasping behavior across diverse object positions.

The experiments evaluate the model's architecture and training strategy by testing feature extraction across different VLM layers, assessing performance on diverse kitchen and benchmark manipulation tasks, and measuring the impact of synthetic data during pre-training and fine-tuning. The findings demonstrate that intermediate VLM layers offer the optimal balance between visual grounding and semantic abstraction, while the model consistently outperforms baselines across varied robotic platforms and task complexities. Additionally, integrating synthetic data significantly enhances overall performance and spatial generalization, with fully synthetic pre-training yielding the most robust outcomes. Collectively, these results validate that strategic representation selection and synthetic data augmentation are essential for developing effective and adaptable vision-language-action systems.