Command Palette
Search for a command to run...
Online Tutorial | Up to 4x Faster Generation Speed: DiffusionGemma Can Generate Entire Blocks of Text Simultaneously, With Continuous Optimization Based on multi-round Parallel denoising.

On June 11th, Google officially open-sourced DiffusionGemma, a text generation model built on Discrete Diffusion technology. It leverages the industry-leading intelligence-per-parameter capabilities of the Gemma 4 series and cutting-edge Gemini Diffusion research, integrating a new Diffusion Head to maximize generation speed. Unlike traditional large models that output text token by token, it can generate entire text blocks simultaneously and continuously optimize the results through multiple rounds of parallel denoising.This results in a generation speed increase of up to 4 times.
Official data shows that DiffusionGemma can achieve a generation speed of over 1100 Tokens/s on a single NVIDIA H100 GPU and over 700 Tokens/s on a GeForce RTX 5090, far exceeding autoregressive models of the same level.
From the perspective of architecture,DiffusionGemma employs a 26B parameter-level hybrid expert (MoE) design.The total number of parameters is approximately 25.2 billion, but only 3.8B parameters are activated during inference, significantly reducing computational overhead while maintaining strong inference capabilities. The model is built on an encoder-decoder structure and incorporates a bidirectional attention mechanism, enabling it to process 256 tokens in parallel at once. It also supports tasks that heavily rely on the global context, such as inline text editing, code completion, and mathematical structure generation.
In addition, DiffusionGemma supports long contexts of up to 256K tokens, multimodal graph and text input, and inference modes activated by <|think|>, providing developers with new technology options for exploring next-generation high-efficiency AI applications.
Although Google still emphasizes that the standard Gemma 4 is more suitable for production environments in terms of generated quality, the diffusion-based text generation capabilities demonstrated by DiffusionGemma may be opening up another noteworthy new path for the development of large language models.
To make it easy for developers to experience DiffusionGemma with minimal effort, HyperAI quickly followed up after the model was open-sourced and has now launched an easy-to-deploy Notebook, which can verify the model's powerful capabilities using only a single NVIDIA RTX Pro 6000 graphics card.
Run online:https://go.hyper.ai/879dB
More online tutorials:
Demo Run
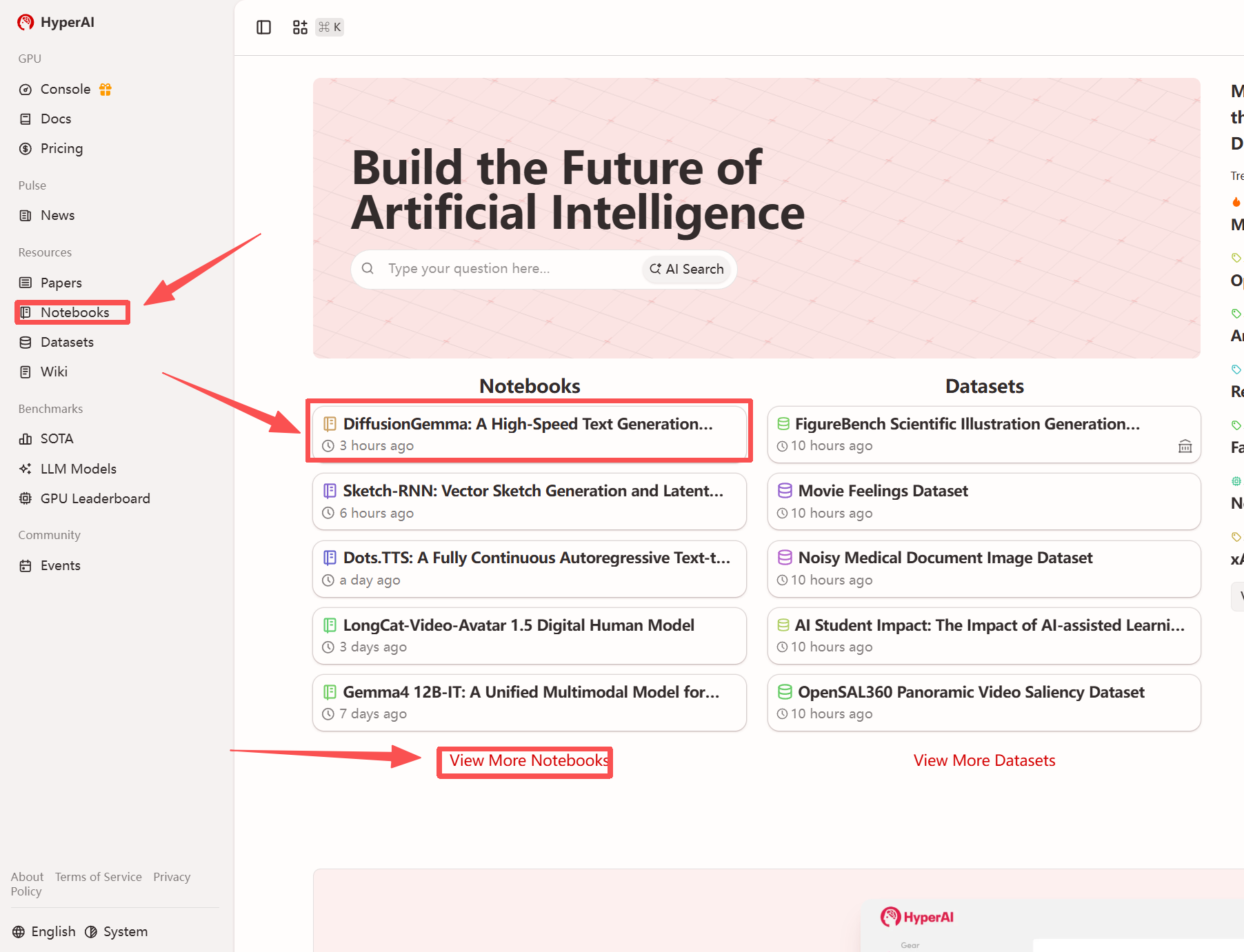
1. After entering the hyper.ai homepage, select the "Tutorials" page, or click "View More Tutorials", select "DiffusionGemma: High-Speed Text Generation Model Based on Discrete Diffusion", and click "Run this tutorial".
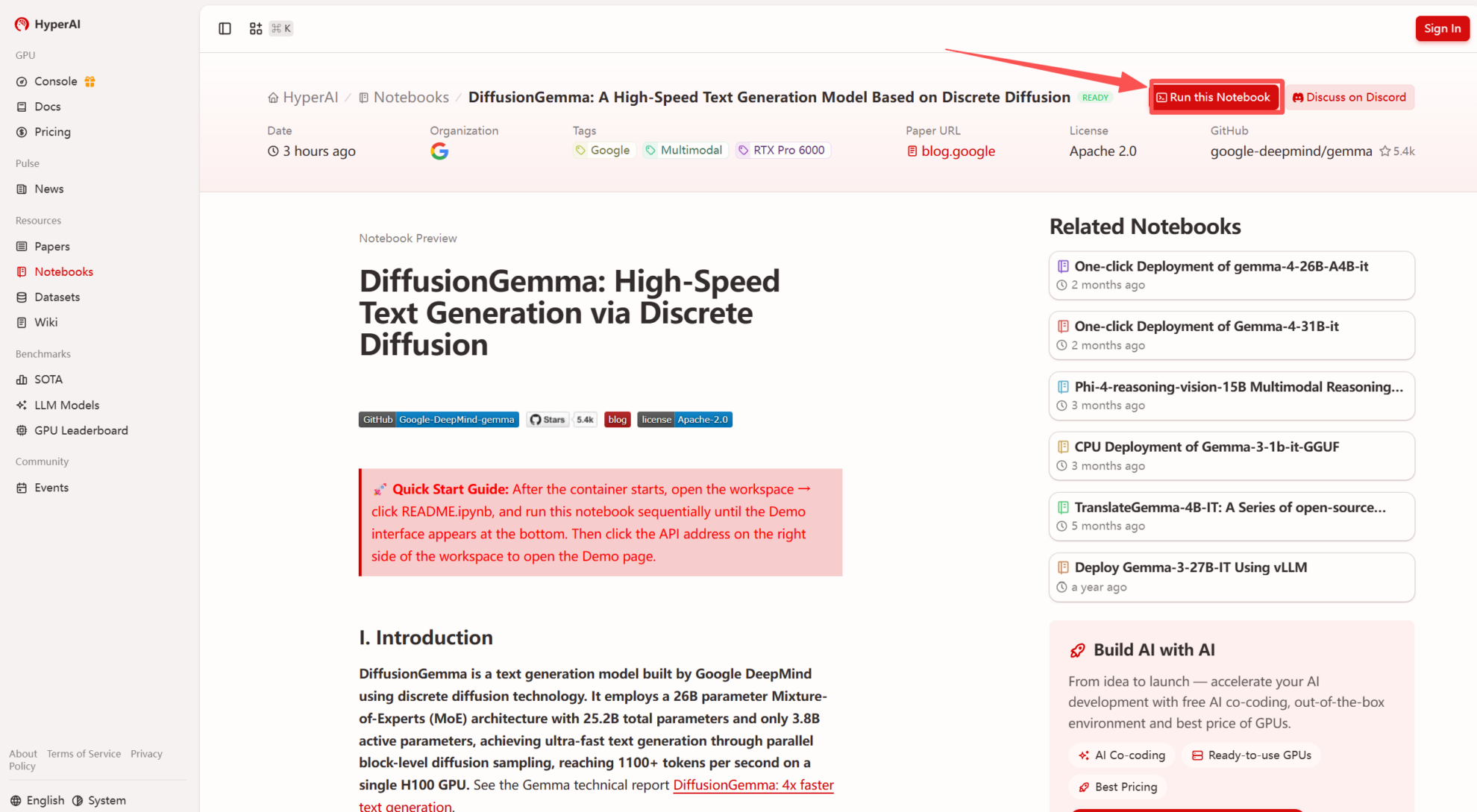
2. After the page redirects, click "Clone" in the upper right corner to clone the tutorial into your own container.
Note: You can switch languages in the upper right corner of the page. Currently, Chinese and English are available. This tutorial will show the steps in English.
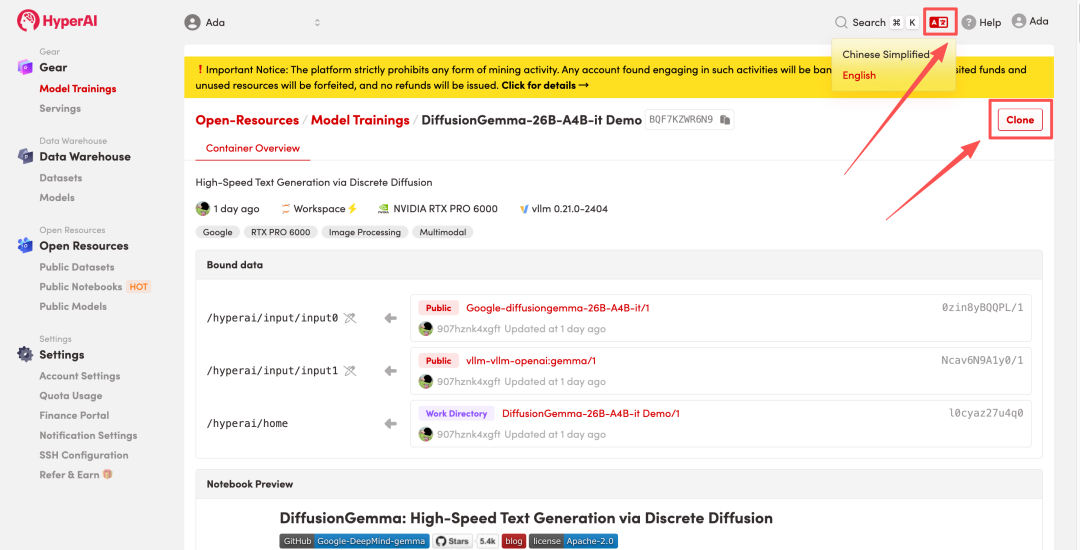
3. Select the "NVIDIA RTX Pro 6000" and "vLLM" images, and click "Continue job execution".
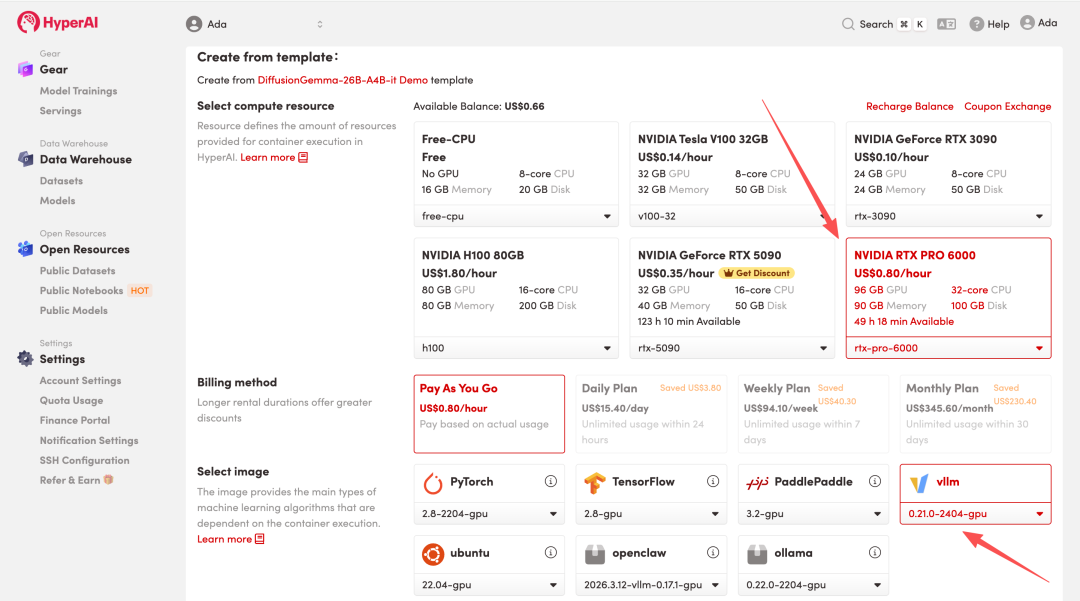
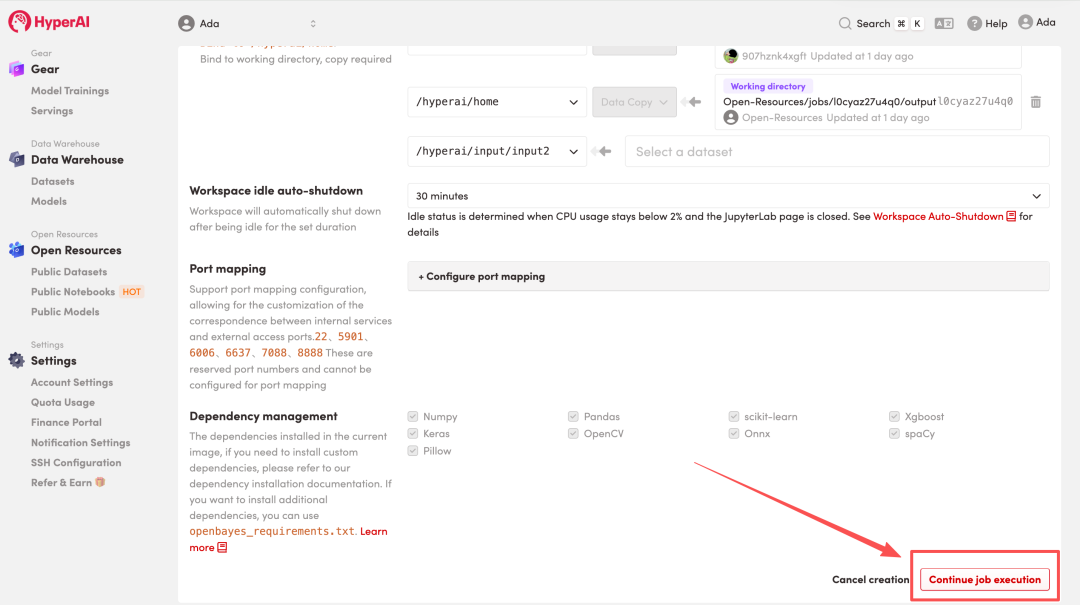
4. Wait for resources to be allocated. Once the status changes to "Running", click "Open Workspace" to enter the Jupyter Workspace.
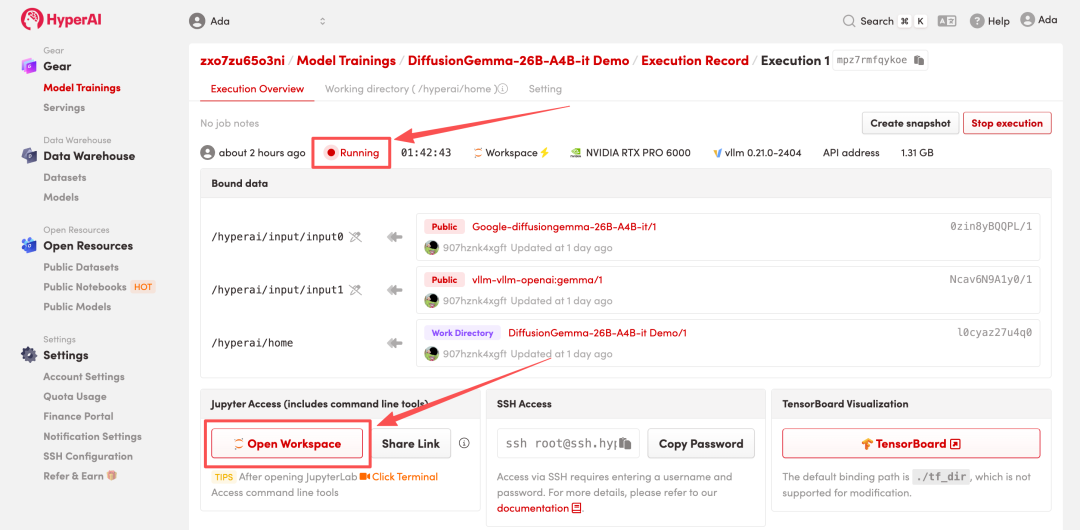
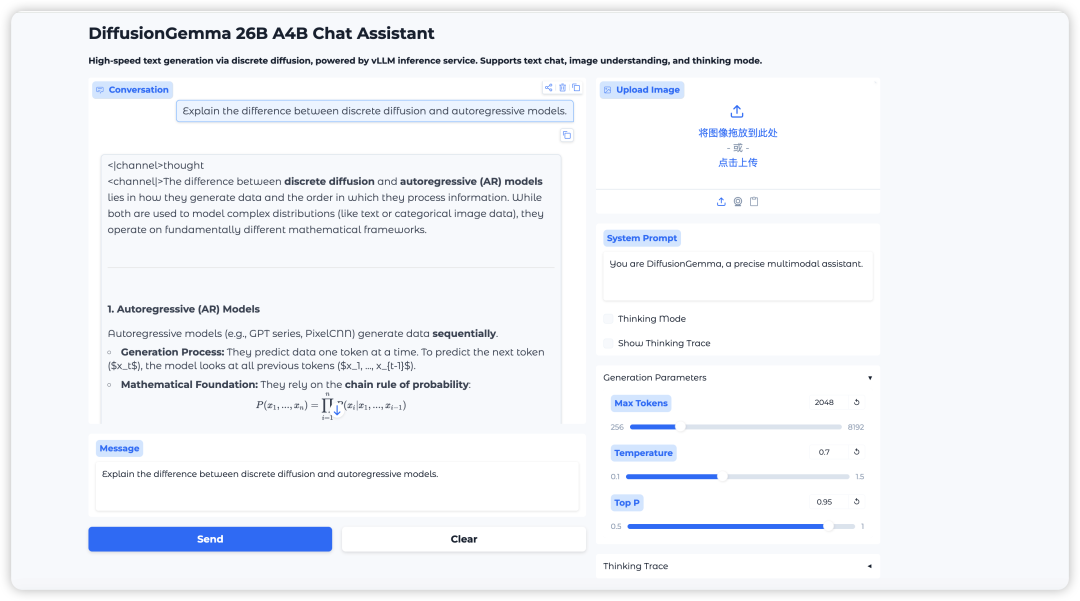
Effect display
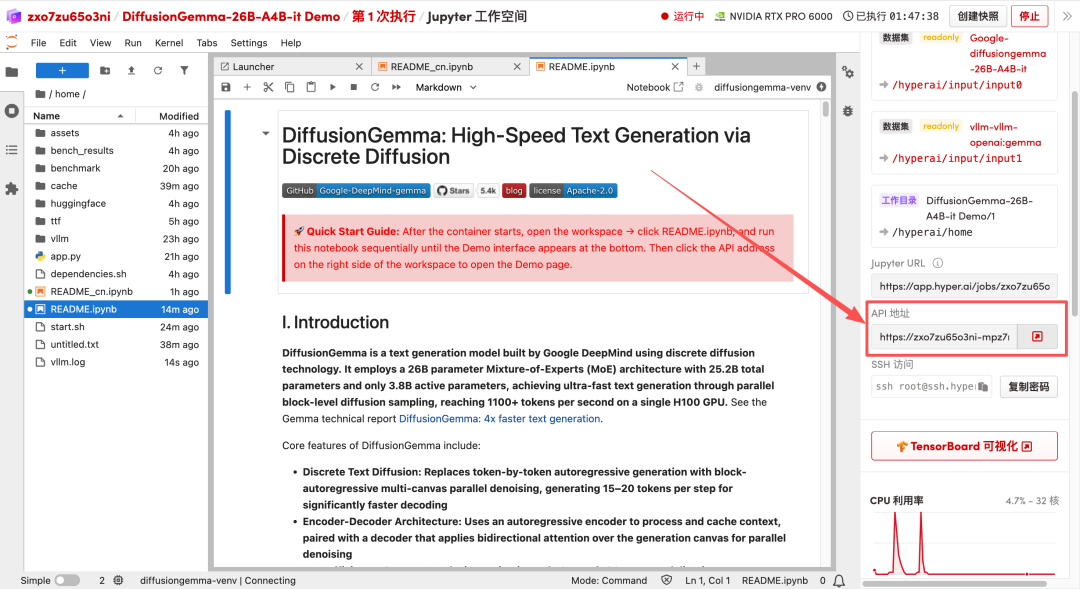
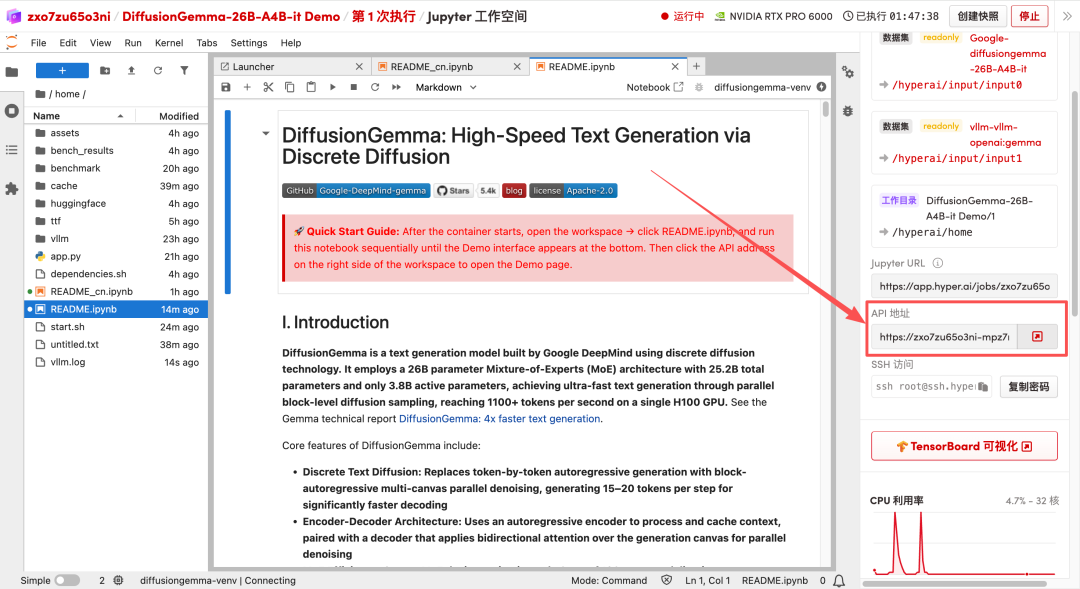
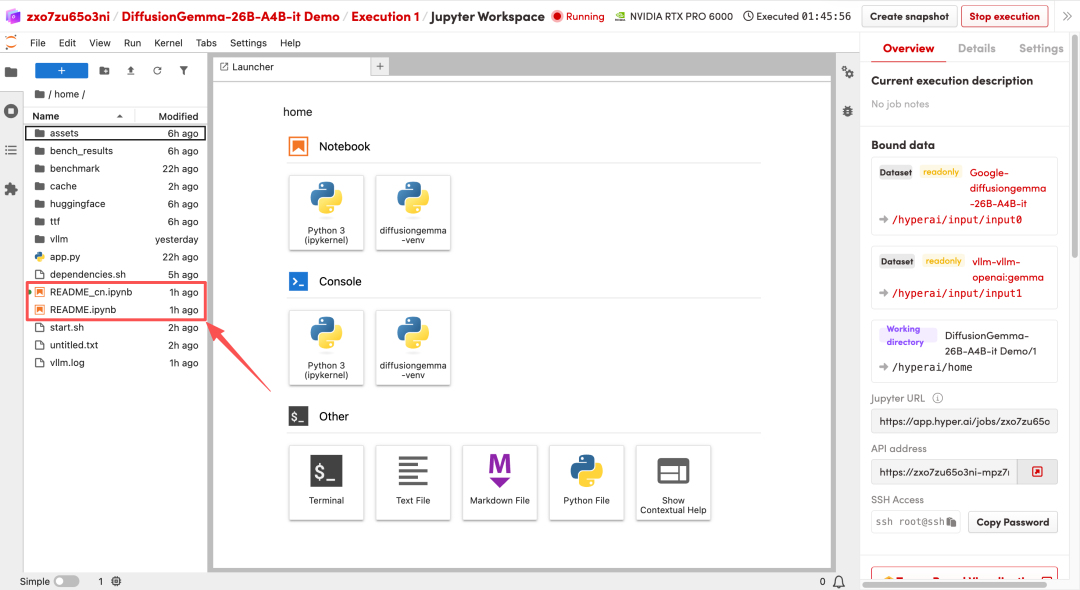
1. After the page redirects, click on the README file on the left, and then click on Run at the top.
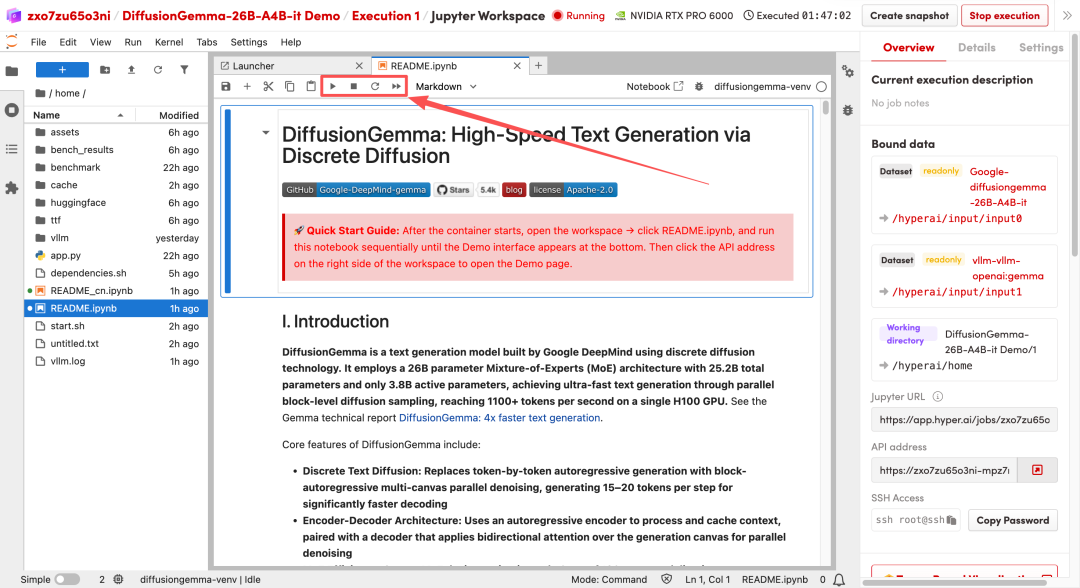
2. After the process is complete, click the API address on the right to open the Demo interface.