Command Palette
Search for a command to run...
CVEvolve, a Zero-code, self-discovery Scientific Image Processing Algorithm Proposed by Argonne National Laboratory, Possesses full-stack Capabilities Including Coding, Result Self-checking, and Strategy optimization.

Reaching an objective and rigorous scientific conclusion is as difficult as panning for gold in a vast desert. This is especially true today, with the widespread availability of advanced scientific instruments and simulation technologies.The data produced by scientific research is massive in volume, loosely structured, and highly unstructured.The process of processing scientific research data is like sifting through sand to find gold; it has become the most crucial and core step in unlocking the value of data and revealing the truth of scientific research.
However, the dilemma lies precisely here: domain scientists often lack the professional skills required for data processing, such as computer vision, image processing, and software engineering; while technical experts who are good at data processing cannot deeply understand the disciplinary background and find it difficult to design adaptive processing workflows that fit real scientific research scenarios.
Addressing the professional knowledge gap arising from scientific data processing,A research team at Argonne National Laboratory (ANL) in the United States has developed a zero-code autonomous agent framework called CVEvolve after systematically analyzing past AI-based automation work.This framework is designed to mine algorithms needed for scientific research data processing. It possesses strong versatility, requiring no pre-defined problem architecture or fixed process templates. It can achieve closed-loop linkage of various elements such as code, data, evaluation metrics, retrieval records, and visualization results. It supports the development of executable algorithms for computer vision, image processing, and other fields. It is not constrained by a single modeling method and has full-stack capabilities including code writing (running), effect evaluation, historical tracing, result self-checking, and strategic iterative optimization.
In short, CVEvolve is capable of developing its own specialized algorithms adapted to various scientific data processing scenarios in real-world situations. This allows scientists in fields that do not understand programming or image processing to quickly get started with intelligent analysis methods without writing a single line of code, and the results are more comprehensive, reliable, and efficient than previous methods.
The related findings, titled "CVEvolve: Autonomous Algorithm Discovery for Unstructured Scientific Data Processing," have been published on the preprint platform arXiv.
Research highlights:* Proposes a general proxy framework for discovering algorithms for autonomous scientific data processing, designed specifically for unstructured problems, eliminating the need for pre-defined problem frameworks and fixed process templates. * CVEvolve introduces a long-field search architecture that combines generate, tune, and evolve mechanisms with source-aware state management and agent-driven retention testing, ensuring the framework's flexibility, autonomy, maturity, and usability. * CVEvolve has been validated on various tasks, including X-ray fluorescence microscopy image registration, Bragg peak detection, and high-energy diffraction microscopy image segmentation, demonstrating its ability to discover practical algorithms and accelerate scientific discovery.

View the paper:
https://hyper.ai/papers/2605.11359
Dedicated validation datasets were built for the three types of tasks.
In this study, all datasets were custom-designed specifically for the control experiment.
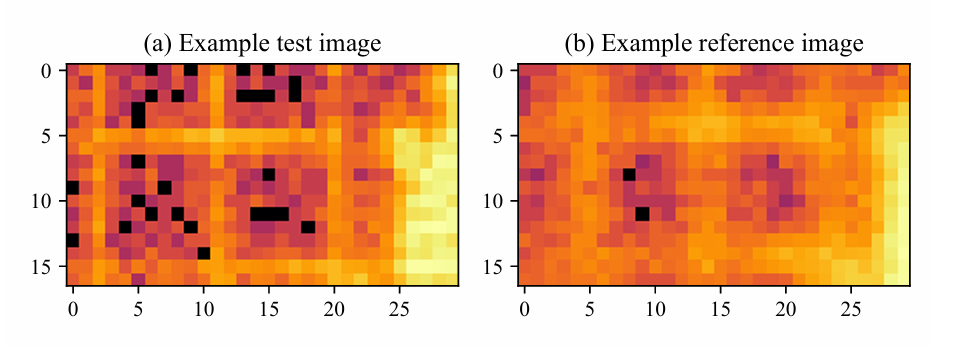
Fluorescence microscopy image registration dataset
Based on real XRF images, translation shift, Poisson noise, scan jitter, and blurring were artificially applied to simulate image differences under real focus drift. Images were drawn using a logarithmic scale and were only 10-30 pixels in size. The dataset consisted of 809 pairs of test/reference images, with 101 TP3T randomly allocated as a holdout set, and the remaining 901 TP3T used for algorithm iteration and development.
Bragg peak detection dataset
The diffraction images were obtained from all scanning points and then divided into two groups. The images from each group were superimposed pixel by pixel to create two images. One image was used for performance evaluation during the algorithm development phase, and the other was used as a holdout set. The Bragg peaks in both images were manually labeled.
High-energy diffraction microscopy image segmentation dataset: The development dataset contains 5 images and their manually created labels, with 2 samples reserved for the test set.
Three major processes and five key tools for building an LLM-based intelligent agent.
In terms of overall architecture,CVEvolve is an autonomous search controller centered around a large language model agent. The agent can use tools to generate, run, and evaluate candidate solutions, while the controller determines the direction of subsequent exploration based on historical data.The iteration strategy is inspired by the Pty-Chi-Evolve framework, involving three types of operation steps: generate, tune, and evolve. It is adapted to more tasks through an expanded toolset and improved state management.
To control the length of the context and reduce computational costs, a completely new context is used in each iteration. Only the system prompts and the task prompts corresponding to the actions performed in this round are retained, and historical dialogue records are not accumulated. In the same round, generate and tune can be executed simultaneously by multiple parallel workers, allowing the system to explore multiple new solutions or make multiple rounds of optimizations and adjustments for different original content before updating the dialogue records.
After each round, the candidate algorithms submitted by the agent are grouped according to their evolutionary lineage, recording parent-child inheritance relationships and preserving excellent design patterns. The candidate sampling architecture is borrowed from the MAP-Elites algorithm and is performed randomly. For the tune and evolve steps, CVEvolve uses random candidate sampling instead of always selecting the current best candidate.
Three-stage workflow
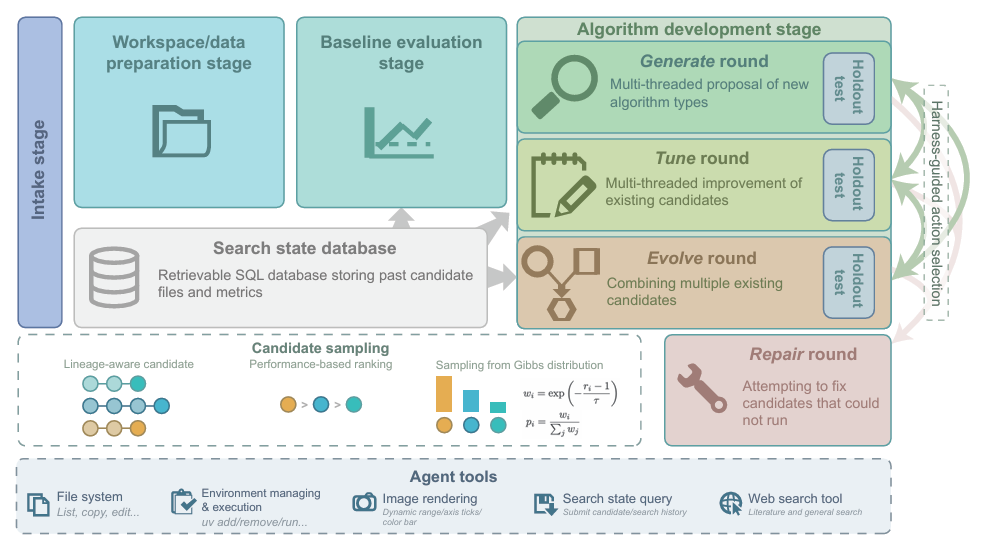
* Workspace preparation phase:Starting with workspace preparation, the runtime environment is set up, and the evaluation metrics from task descriptions or user prompts are automatically written into executable evaluation code.
* Baseline assessment phase:Run and evaluate existing benchmark algorithms to provide a baseline for subsequent comparison work.
* Algorithm Iteration and Development Phase:The algorithm follows the strategies of generate, tune, and evolve to perform multiple rounds of iterative search. The generate strategy is responsible for extensive exploration and designing new algorithms using multiple threads. The tune strategy is responsible for basic optimization, randomly selecting the best candidate algorithms and optimizing their parameters. The evolve strategy is responsible for iterative evolution, combining the advantages of multiple algorithms to generate a new algorithm.
In addition, to ensure the rigor and rationality of the research, the overall process also includes optional repair rounds to fix candidate algorithms that cannot run, independent testing after each round, SQL search of the status database, and recording of candidates, indicators, iteration rounds and evolutionary lineages throughout the process.
Five core supporting tools
* File system tools:Supports listing, reading, writing, editing, copying, moving, and deleting files in the workspace, allowing agents to write candidate codes, helper scripts, and evaluation tools in a session sandbox.
* Environment management and code execution tools:Installing or removing dependencies in the support workspace, and executing Python scripts.
* Image viewing tools:It supports floating-point image processing, high dynamic range image logarithmic scaling, TIFF to PNG format conversion, and other adjustment functions, enabling the agent to identify subtle structures, brightness variations, and anomalies that are difficult to detect under ordinary linear rendering.
* Search status tool:It supports agents in setting core metrics, recording evaluation results, verifying historical data, analyzing candidate results, and submitting new candidates to the search records in the structured query language.
* Web search tools:Granting access to arXiv, Semantic Scholar, and Tavily facilitates the development of iterative algorithms by leveraging external technical reference information.
Additionally, a multimodal image follow-up middleware was added to the design to compensate for the limitation that large language model interfaces cannot directly transmit images. Specifically, when the tool returns the image path, it automatically re-injects the rendered image as a follow-up message into the dialogue.
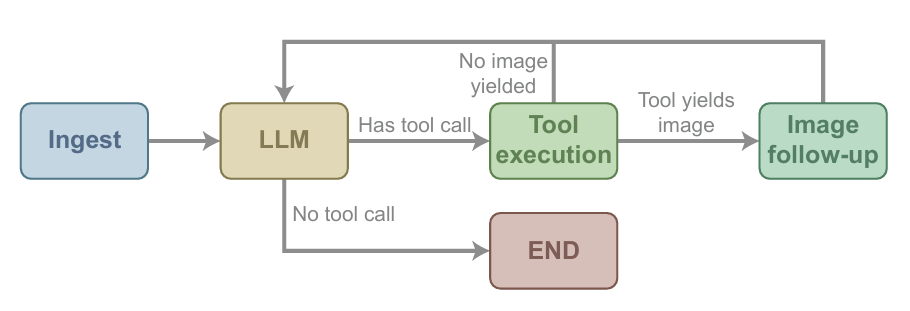
Core underlying execution architecture
CVEvolve is an agent application based on LangGraph. It uses a simplified node graph at runtime and processes data through four core processes: message reception, model inference, tool invocation, and image post-processing. After the tool returns the image path, the image processing node converts it into multimodal observation data and sends it back to the model for use in the next round of inference, as shown in the diagram below.
Verifying the practicality of CVEvolve in three types of scientific image processing scenarios
To demonstrate the practical effectiveness and generalization ability of CVEvolve, the research team specifically designed three sets of real-world scientific image processing experiments to validate it.All experiments were performed using Claude Opus 4.6.
Fluorescence microscopy image registration
The researchers first demonstrated CVEvolve's task in finding a robust algorithm for translational registration of X-ray fluorescence microscopy (XRF) images, which addresses the problem of image offset calibration after microscope focusing.
Baseline algorithms include two types: phase correlation with a Hanning window preprocessor and brute-force error minimization; the performance comparison metric is the average Euclidean distance between calculated and ground-truth shifts.
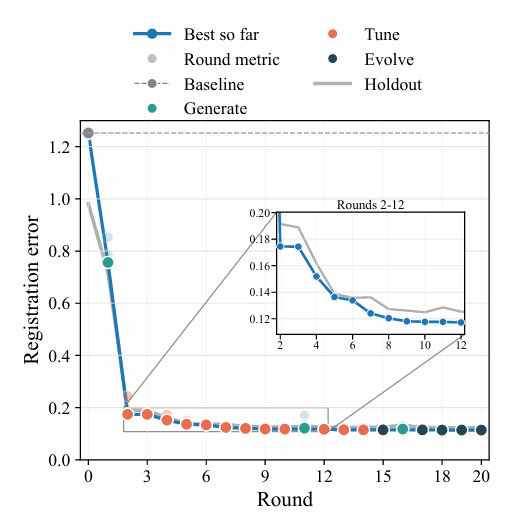
The study, after 20 rounds of searching, demonstrates the error changes and performance characteristics. In the initial baseline rounds, the average Euclidean error of brute-force error minimization was 1.25, while the phase correlation method error after Hanning window preprocessing reached as high as 5.8. After subsequent generate and evolve rounds, the registration error continuously decreased, reaching 0.8 and 0.43 respectively, and the performance stabilized after the 9th round. This is illustrated in the figure below.
To select the optimal registration algorithm, this algorithm adopts a coarse-to-fine image registration approach. The first step is to complete integer pixel-level alignment and positioning through multi-scale normalized cross-correlation. The second step combines various preprocessing methods, including spline functions and optimization algorithms, to improve the accuracy to the sub-pixel level. The third step is to adaptively weight and integrate multiple sets of estimation results according to coordinates to output a stable and reliable final offset.
Tests on the holdout set and comparisons with various baseline algorithms showed that the optimal registration algorithm had an error of 0.12, nearly 8 times lower than the better-performing brute-force error minimization algorithm. Meanwhile,The researchers further compared the candidates discovered by CVEvolve with those discovered by OpenEvolve. After 500 iterations, the error stabilized at 0.23, which was significantly higher than that of the candidate algorithm discovered by CVEvolve.As shown in the following table:

Bragg peak detection
The objective of this experiment is to find an algorithm for detecting Bragg peaks in X-ray diffraction images. The goal is to develop a method to identify and locate Bragg peaks within and around corresponding annular regions of a given lattice plane. Evaluation metrics include F1 score, Precision, and Recall.
Since the development dataset contains only one image, the algorithm is highly susceptible to overfitting, so holdout must be used to monitor generalization performance. The results are shown in the figure below. The F1 score for the development set image continues to rise, eventually approaching the perfect score of 1, while the F1 score for the reserved test set peaks around the 5th round and then begins to decline sharply after the 9th round.
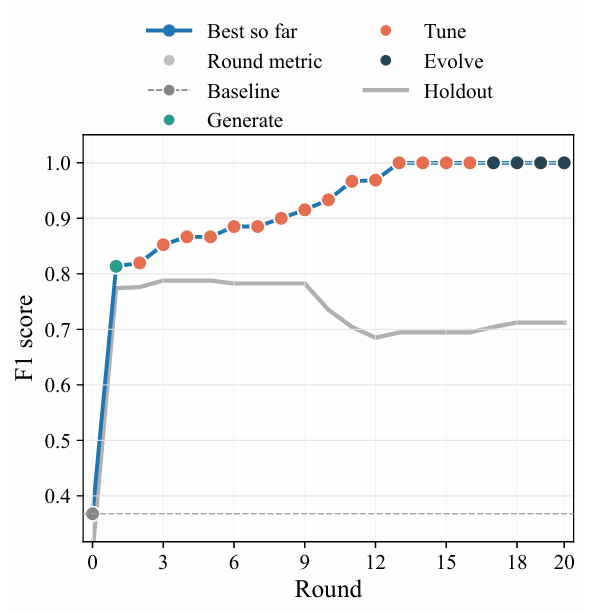
Next, we select the optimal candidate in the 5th round. First, we mask the invalid region, and then generate a signal-to-noise ratio map by subtracting the background with arc-shaped polar coordinates and normalizing the local noise. Then, we use a multi-round complementary algorithm to find the peak value. Finally, we merge, verify, and optimize the center point to output the final peak coordinates.
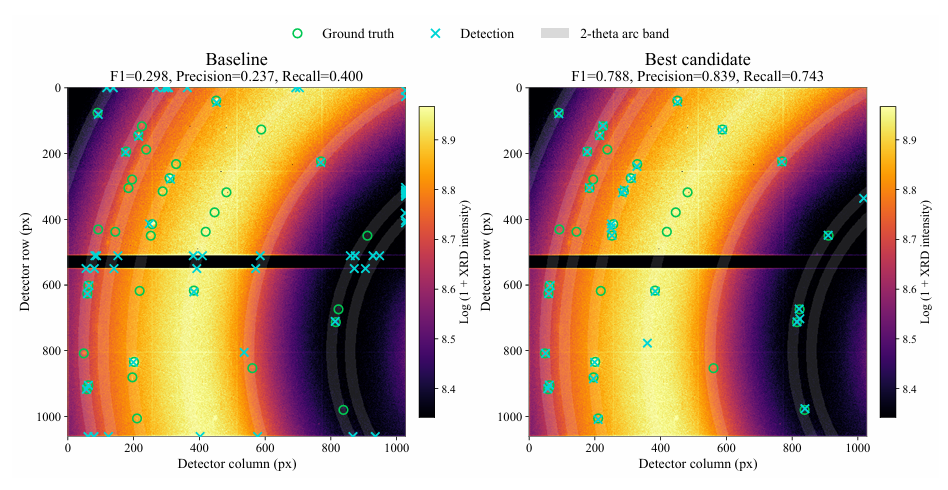
The results show thatThe optimal candidate solution can effectively alleviate false detections, while also reducing the number of missed detections and identifying more labeled peaks.The best candidate achieved performance improvements over the baseline across all metrics: F1 score increased from 0.298 to 0.788, Precision score increased from 0.237 to 0.839, and Recall score increased from 0.400 to 0.743 (corresponding to missed detections). See the figure below.
Diffraction image segmentation
The task of this study was polycrystalline diffraction image segmentation, the challenge of which lay in accurately distinguishing diffraction rings and Bragg peaks. The experiment used the weighted intersection-to-union (IoU) index and conducted 40 rounds of observations. The results showed...The initial baseline candidates created by the agent, through background subtraction and threshold segmentation to identify features, ultimately had an intersection-union ratio of only 0.37, which is low in accuracy.As shown in the figure below.
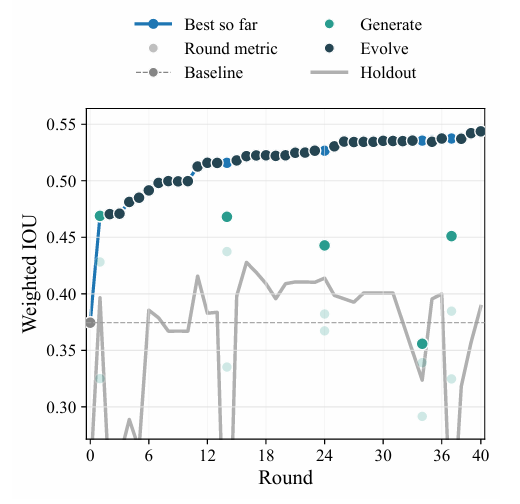
Then, by tracking retention test metrics, the optimal candidate algorithm was selected in the 16th round. The candidate algorithm was transformed into a logarithmic diffraction image, the beam center and radial background parameters were calculated, and then the annular results were identified and verified through radial and azimuth consistency checks. Pixels were divided based on the background threshold, and finally the diffraction peaks were purified and a segmentation mask was generated.
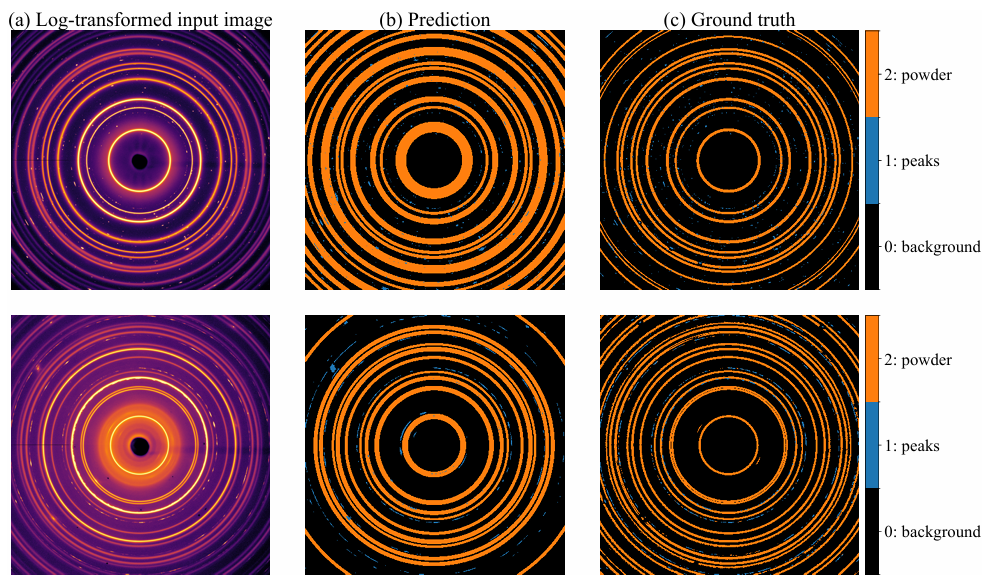
The results showed that in the first demonstration, the predicted annular mask was wider and thicker than the actual baseline contour, but after careful verification, it was confirmed that most of the annular structures were successfully detected, and various Bragg peaks were also well segmented. The predicted mask had a high degree of fit with the actual baseline contour. In the second demonstration, a small number of annular structures in the outer region failed to be identified and detected.
Final Thoughts
In summary, CVEvolve's zero-code development significantly lowers the barrier to entry for computational imaging technology, providing a shortcut for scientists in the field to perform customized scientific data processing. In the future, CVEvolve is expected to further enhance its capabilities, as described in the paper, by expanding into high-level data processing and real-time workflow optimization. This will propel autonomous scientific discovery workflows into an era driven by both intelligence and technology.








