Command Palette
Search for a command to run...
AI Has Discovered 118 New Exoplanets! A Team From the University of Warwick Proposed RAVEN, Which Allows for one-to-one Comparison of Planetary Scenarios With Each False Positive scenario.

With the continuous advancement of astronomical research, the discovery of exoplanets has entered a phase of rapid development. In particular, the light curve data provided by NASA's Transiting Exoplanet Survey Satellite (TESS) mission allows scientists to obtain a large number of transit signal candidates every day.
However, confirming or disproving the planetary properties of candidates is a lengthy and challenging process. To date, the Exoplanet Archive lists 7,658 TESS (Teleplanetary Objects of Interest) targets (TOIs), of which 5,152 are still designated as candidates.Only 666 have been confirmed as true exoplanets, and another 558 were detected by TESS but were previously confirmed.Meanwhile, 1,185 TESS candidates were identified as "false positives (FPs)," and another 97 were classified as "false alarms (FAs)"—such a high number highlights the difficulty in confirming exoplanet candidates.
Going a step further than candidate selection is the "validation pipelines," which aim to confirm that the candidates are real planets through statistical methods.Traditional verification methods primarily rely on manual analysis and subsequent observations, including radial velocity (RV) measurements and ground-based telescope tracking.While these methods are reliable, they are time-consuming and costly.
In response, a research team from the University of Warwick, building upon the Kepler process proposed by David J. Armstrong et al.,A new screening and validation process for TESS candidates has been further developed—RAVEN (RAnking and Validation of ExoplaNets).The most critical change in the new process is the introduction of synthetic training datasets, which no longer rely solely on threshold out-of-bounds (TCE) event data generated by the task itself. This improvement significantly expands and enhances the parameter space of planetary and false positive scenarios covered by the machine learning model.
The results show thatThe procedure achieved an AUC score of over 971 TP3T in all false positive scenarios, with the exception of one scenario where it exceeded 991 TP3T.On an independent external test set containing 1,361 pre-classified TESS candidates, the workflow achieved an overall accuracy of 91%, demonstrating its effectiveness in automatically ranking TESS candidates.
Researchers also used the process to confirm 118 new exoplanets, while identifying over 2,000 high-quality planet candidates, nearly 1,000 of which had never been discovered before.
The related research findings, titled "RAVEN: RAnking and Validation of ExoplaNets", have been published as a preprint on arXiv.
Research highlights:
* By leveraging synthetic datasets, RAVEN enables one-to-one comparisons between planetary scenarios and each false positive scenario—a capability previously typically found only in validation frameworks that rely on model fitting.
The new process introduces synthetic training datasets, no longer relying solely on TCE data generated by the task itself.
The new process maintains high operational efficiency: processing a typical candidate takes only about one minute, and it has good scalability through multi-process support.
Paper address:https://arxiv.org/abs/2509.17645*
Follow our official WeChat account and reply "TESS" in the background to get the full PDF.
Dataset: The complete construction path from input data to training samples
Input data: Multi-source information fusion with light curves as the core.
The RAVEN workflow currently uses light profiles generated from TESS full-frame imagery (FFI) released by the TESS Science Processing Operations Center. These light profiles are extracted from the FFI data of each observation sector using aperture photometry, with a sampling rate of 30 minutes for sectors 1–27 and 10 minutes for sectors 28–55. The FFI data released by the TESS Second Extension Mission (starting from sector 56) has a sampling rate of 200 seconds. The light profiles used in this study end at sector 55.
Training data: Systematic modeling of planets and false positives
The RAVEN process introduces synthetic light curve data for training machine learning models, instead of relying on existing classified candidate light curve data in the task.
The initial composite event set used simulated transits or eclipses and incorporated them into the SPOC light curves. The simulated events were generated using a modified version of the researchers' PASTIS software and initially included scenarios such as transiting planets (Planet), eclipsing binaries (EB), stratified eclipsing binaries (HEB), stratified transiting planets (HTP), background eclipsing binaries (BEB), and background transiting planets (BTP). To ensure the composite data closely approximates the actual TESS observation population, the primary star in each scenario was randomly selected from a fully characterized TESS Input Catalog (TIC) sample. Ultimately, the target sample contained 1,200,520 SPOC FFI stars.
Building on this, the construction of false positive data becomes more complex and crucial. For Nearby False Positives (NFPs), researchers consider the following NFP scenarios: Nearby Transiting Planet (NTP): The planet transits and dilutes the host; Nearby Eclipsing Binary (NEB): The nearby dilution source is an eclipsing binary; Nearby Stratified Eclipsing Binary (NHEB): The nearby dilution source is a stratified eclipsing binary.
Test data: Real-world application scenarios centered around TOI
The performance of this process was finally tested on a set of TOIs (i.e., TESS Interest Targets) with existing prior classifications.The list and classification information of TOIs used in the test came from the NASA Exoplanet Archive, dated February 3, 2025. At that time, there were 2,134 pre-classified TOIs, of which 548 were classified as Known Planets (KP), 485 as TESS Confirmed Planets (CP), 1,113 as FP, and 96 as FA. However, only 1,918 TOIs had associated published SPOC FFI light curves. Ultimately,After applying depth and periodic constraints to the remaining samples, the total number of TOIs to be processed is 1,589.
All TOIs underwent the full pipeline processing steps, except for one FP TOI, whose target star was marked "DUPLICATE" in TIC. In the final results, 68 TOIs were excluded because the target star lacked a stellar radius in TIC; another 87 were excluded because their TESS magnitude exceeded 13.5, and 22 were excluded because their Gaia magnitude exceeded 14.
The training set used in this study did not include events with target stars larger than 13.5 Tmag or 14 Gmag. Furthermore, 28 TOIs were excluded because their calculated MES during feature generation was less than 0.8, and 2 TOIs were discarded due to feature generation failure. Finally, 21 TOIs were excluded from further analysis because their centroid data prevented the generation of position probabilities, and therefore no posterior probabilities were provided.
therefore,The final number of pre-classified TOIs in this test was 1,361, of which 705 were known or confirmed planets, 630 were FPs, and 26 were FAs.
Combining two machine learning models—GBDT+GP
The RAVEN workflow is based on the statistical validation framework (hereinafter referred to as A21) proposed by David J. Armstrong et al. in 2021 for Kepler mission candidates. This framework has been adapted to the Transiting Exoplanet Survey Satellite (TES) data and has also been extended and upgraded. The implementation and operation of the entire workflow is relatively complex, involving multiple steps. A simplified flowchart is shown in the figure below:
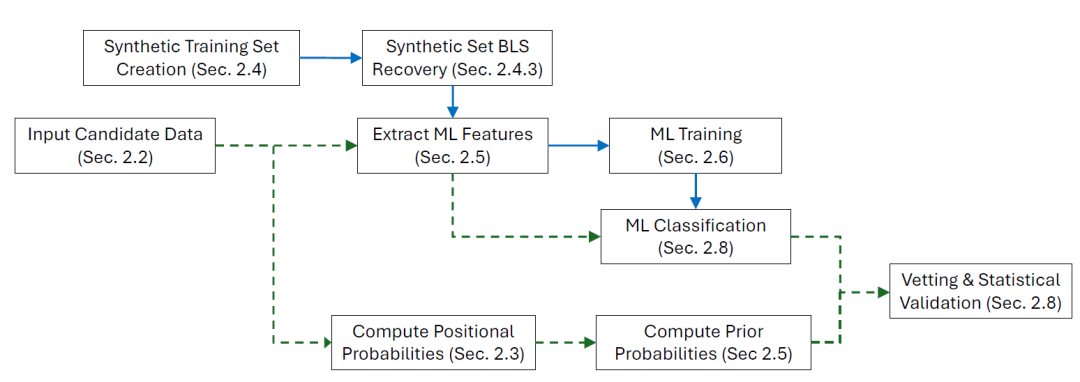
Machine learning training
At its core, RAVEN combines two machine learning models: Gradient Boosted Decision Tree (GBDT) and Gaussian Process (GP).The process generates posterior probabilities for 8 false positive scenarios for each candidate planet, and obtains the RAVEN probability, which is the lowest confidence in the authenticity of the candidate, by taking the minimum value.
① Gradient Boosting Decision Tree (GBDT)
Decision trees are a simple yet powerful type of machine learning model. A significant advantage is their strong interpretability. However, single decision trees have limitations in robustness and are prone to overfitting when the tree depth is too large. To address these issues, ensemble methods consisting of multiple "weak" trees are typically employed. Gradient Boosting Decision Trees (GBDT) is one such ensemble method, which sequentially builds multiple decision trees to form a stronger final model.
The core features of GBDT are:Each newly generated tree is not trained directly based on the original labels, but rather learns from the residual error generated by the model prediction in the previous round.In other words, the goal of each new model is to minimize the loss function of the overall model, a process essentially similar to gradient descent. During ensemble processing, the outputs of each sub-model are scaled by the learning rate and then summed to obtain the final prediction.
The model loss is calculated using a predefined loss function, and the residuals are determined by the gradient of that loss function. In this study, the GBDT classifier is implemented using XGBoost, as proposed by Chen and Guestrin.
② Gaussian process classifier
A Gaussian process (GP) is a stochastic process that generalizes the Gaussian probability distribution from a "distribution of random variables" to a "distribution of functions." In GP classification, the goal is to output discrete class labels or class probabilities between 0 and 1. To achieve this, a response function is applied to the GP output, mapping the result to the interval 0 to 1. This is then combined with a probability likelihood function (such as Bernoulli likelihood).
This study employs the variational approximation method proposed by James Hensman et al. This method relies on a set of "inducing points," which are representative subsets of the data, to improve the scalability of the model while reducing computational complexity.
Training and Calibration
To train and optimize the two classifiers, an iterative approach was adopted, training the synthetic training set with different hyperparameter combinations and evaluating the performance on the validation set to select the optimal parameters. Parameter tuning primarily focused on three key false positive scenarios: EB, NEB, and NSFP, as these are the most common false positive events. Simultaneously, to avoid over-optimization of a single scenario and resulting overfitting, parameter consistency was maintained across scenarios as much as possible.
All models have enabled the "early stopping" mechanism: training terminates and reverts to the model state at the time of the last improvement in the loss function on the validation set if the loss function on the validation set does not decrease by at least 0.0001 in 20 consecutive iterations.
Statistical validation
The final component of the process involves deriving the posterior probability of the planetary hypothesis by combining the probability of each planet-FP category derived from machine learning with its corresponding scenario-specific prior probability. This posterior probability represents only the probability that the candidate is a planet or a specific FP scenario. Therefore, the researchers' statistical validation method requires that the candidate's posterior probability for each of the eight planet-FP categories exceed 0.99 in order to be considered validated.
RAVEN performs well in screening, ranking, and validating real planetary candidates.
To evaluate RAVEN's performance, the researchers performed the following validations on both the training and test sets:
Researchers first tested its performance on unseen subsets of the training set, consisting of 10% events randomly selected from each scene and isolated independently before training. Model performance was evaluated using four key metrics: accuracy, area under the ROC curve (AUC), precision, and recall. Performance test results are shown in the table below:
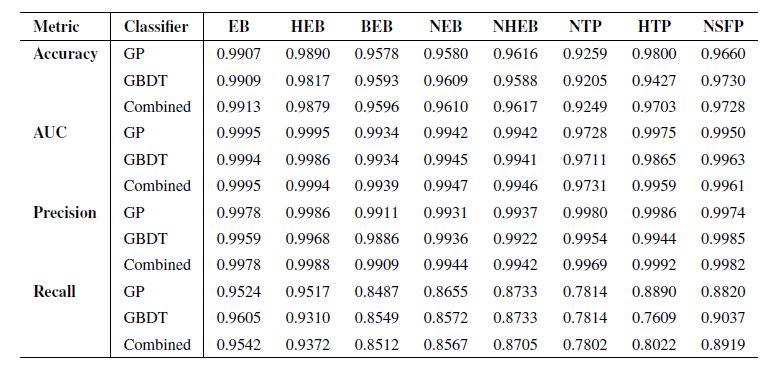
The results show that both classifiers perform excellently in all FP scenarios, especially in terms of accuracy. Since the primary goal of the RAVEN pipeline is to screen and validate real planetary candidates, accuracy is the most important metric, reflecting the pipeline's ability to correctly identify FPs without misclassification.Combining the results of the two classifiers, the accuracy reaches almost 99% in all scenarios.
The performance of the RAVEN process was finally tested on a set of TOIs with prior classification. The RAVEN probabilities for all 1,361 TOIs in the sample are shown in the following figure:
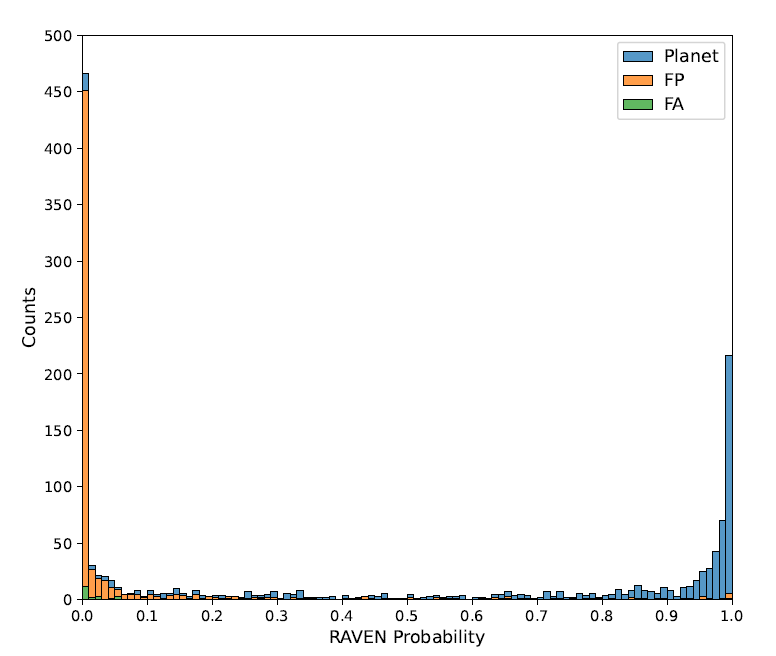
The histogram shows that the probability differences among the three classes are significant, the distribution is good, and the extreme values are obvious.This demonstrates the effectiveness of RAVEN in identifying FP events and assigning them low planetary posterior probabilities.Specifically, the minimum posterior probability of FP events is less than 0.5 for 93.8%, and less than 0.01 for 69.7%. The mean probability of FP events is 0.076, and the median is 0.00022.
Similarly, for the 26 FA TOIs, 23 had a probability below 0.5, with a median of 0.016 for the entire category. Overall, the results for FP and FA TOI confirm the efficiency of the pipeline in screening TESS candidates and can be used to remove most FP events.
Next, the researchers validated RAVEN's ability to identify false positives (FPs), and the table below further lists 12 FP events with a probability greater than 0.9:
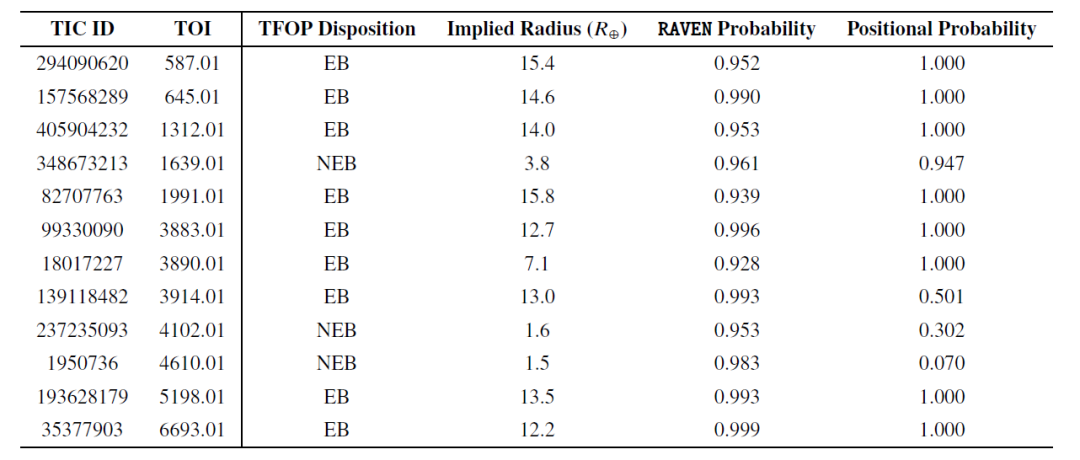
Of these high-probability FP events, most were eclipsing binaries (EB), with only three being near-neighbor eclipsing binaries (NEB). Although NEB was the most common FP type in the sample, this suggests that RAVEN performed effectively in identifying NEB. In fact, for two NEB events (TOI-4102.01 and TOI-4610.01), the RAVEN procedure determined their location information probability to be low and correctly assigned the highest probability to the true host confirmed by follow-up observations.
In addition, TOI-4102.01 was also marked as a problematic event. These two TOIs indicate that when evaluating candidates, especially during validation, the complete output of the RAVEN process should be considered in conjunction with the location information probabilities to identify situations where the posterior probabilities may be invalid.
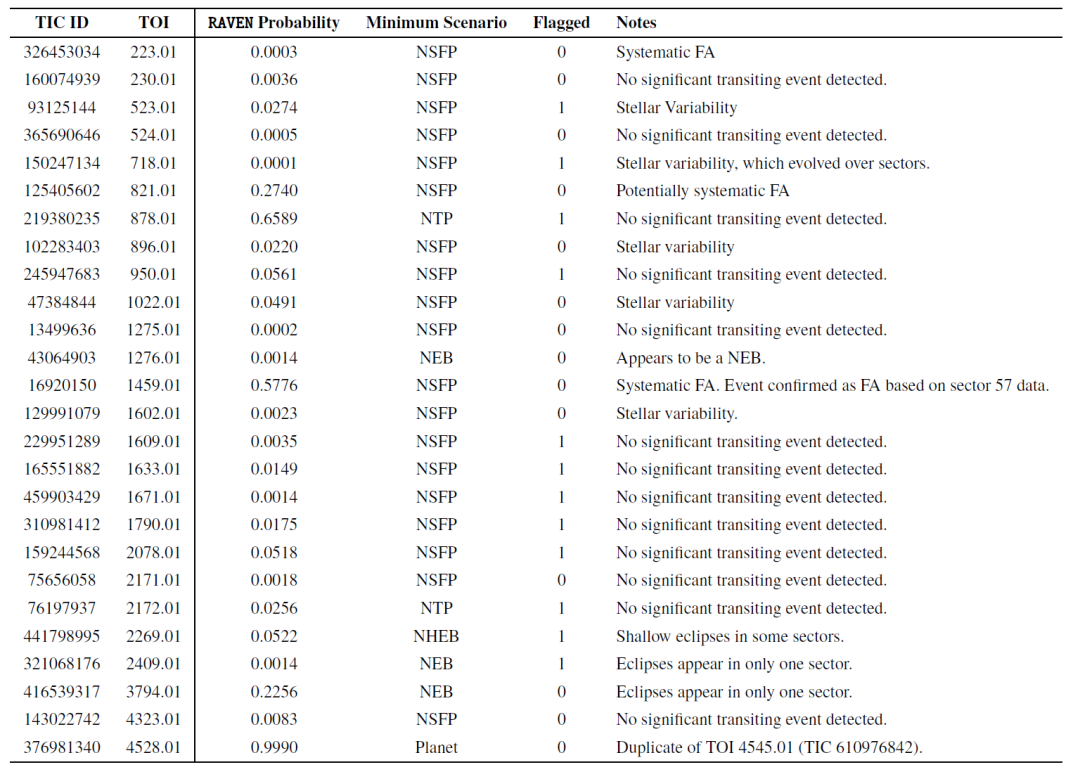
Researchers also evaluated the performance of the RAVEN process on False Alarm (FA) TOIs. The table below shows the lowest posterior probabilities for 26 FA TOIs in the sample, along with the corresponding FP scenarios. The probabilities of almost all FA TOIs were inconsistent with the planetary scenarios, demonstrating that RAVEN effectively identified them.
Finally, after screening the initial TOI sample, the researchers retained 397 known planets and 308 confirmed planets, for a total of 705 planets. The results show that...Most Planet TOIs have high posterior planetary probabilities, with 81% exceeding the 0.5 threshold.
In particular, 420 planets have a probability exceeding 0.9, falling into the "Likely Planet" range. Furthermore, 210 planets have a TOI exceeding the statistical validation threshold of 0.99, representing approximately 30% of the total planet sample.These results demonstrate that RAVEN performs well in screening, ranking, and validating real planetary candidates.
AI is gradually becoming an important infrastructure for astronomical research.
From a broader perspective of technological evolution, artificial intelligence is gradually becoming a crucial infrastructure for astronomical research. Its significance extends beyond simply "improving data processing efficiency"; it is beginning to reshape the overall paradigm of scientific discovery. For a long time, astronomy has relied on analytical methods based on physical models and artificial rules. However, with the improvement of observational capabilities, the scale and complexity of data have continued to rise. From light curves to high-resolution images, and then to multidimensional spectra and star catalog information, traditional methods are gradually approaching their limits when processing high-dimensional, nonlinear, and highly noisy data. Against this backdrop,AI technologies, with machine learning and deep learning at their core, are becoming a key bridge connecting "massive observational data" with "effective scientific understanding".
With the advancement of observational methods, astronomical data is no longer limited to a single modality. Multiple sources of data, such as images, spectra, time-series light curves, and star catalog parameters, coexist, and traditional deep learning models are beginning to show new limitations at this stage. In fact, some studies have attempted to construct multimodal astronomical models, but these attempts still have significant limitations:Most studies focus on single phenomena such as supernova explosions and rely on "contrastive objectives" as the core technology. This makes it difficult for the models to flexibly cope with arbitrary modal combinations and to capture key scientific information between modalities beyond superficial correlations.
To overcome this bottleneck,Teams from more than ten research institutions around the world, including the University of California, Berkeley, the University of Cambridge, and the University of Oxford, have collaborated to launch AION-1 (Astronomical Omni-modal Network), the first large-scale multimodal basic model family for astronomy.By integrating and modeling heterogeneous observational information such as images, spectra, and star catalog data through a unified early fusion backbone network, it not only performs well in zero-shot scenarios, but its linear detection accuracy is also comparable to models specifically trained for specific tasks.
Paper Title: AION-1: Omnimodal Foundation Model for Astronomical Sciences
Paper address:https://openreview.net/forum?id=6gJ2ZykQ5W
Meanwhile, at the level of specific scientific questions, AI is also pushing the boundaries of traditional observational methods. For example, in modern astronomy, the strong gravitational lens is an important tool for studying the large-scale structure of the universe and the co-evolution of black holes and galaxies. Quasars, which act as strong gravitational lenses, provide extremely rare observational opportunities to study the evolution of the scaling relationship (especially the MBH–Mhost relationship) between supermassive black holes and their host galaxies with redshift.
However, quasars are extremely rare, and their identification has always been a huge challenge for astronomers—among the nearly 300,000 quasars cataloged in the Sloan Digital Sky Survey (SDSS), only 12 candidates were found, and only 3 were ultimately confirmed.Against this backdrop, a team comprised of numerous research institutions, including Stanford University, SLAC National Accelerator Laboratory, Peking University, Brera Observatory of the Italian National Institute for Astrophysics, University College London, and the University of California, Berkeley, developed a data-driven workflow for identifying quasars that act as strong gravitational lenses in the spectral data of DESI DR1. Using this workflow, researchers identified seven high-quality (Class A) quasar lensing candidates.
Paper Title: Quasars acting as Strong Lenses Found in DESI DR1
Paper address:https://arxiv.org/abs/2511.02009
It is foreseeable that with the advancement of future observation missions (such as larger-scale sky surveys), astronomy will enter a phase of further data explosion, and the role of AI will deepen accordingly. From assisting analysis to leading discovery, from single-task models to general foundational models, AI is reshaping our understanding of the universe—it is not only changing "how we see," but also "what we are able to discover."
References:
1.https://arxiv.org/abs/2509.17645
2.https://phys.org/news/2026-03-ai-approach-uncovers-dozens-hidden.html
3.https://openreview.net/forum?id=6gJ2ZykQ5W








